Was wäre, wenn Ihr KI-Assistent jede architektonische Entscheidung, Fehlerbehebung und Refactoring-Sitzung über Wochen der Entwicklung hinweg speichern würde? Claude-mem beseitigt die Reibung durch verlorenen Kontext, indem es automatisch Beobachtungen zur Tool-Nutzung erfasst, diese in semantische Zusammenfassungen komprimiert und relevante Historie in jede neue Claude Code-Sitzung injiziert.
Das Problem: Kontext-Amnesie in der KI-gestützten Entwicklung
Jede Claude Code-Sitzung beginnt als leeres Blatt. Wenn Sie Ihr Terminal schließen oder die Verbindung zu einer Sitzung trennen, vergisst Claude alles: Ihre Projektstruktur, aktuelle Refactoring-Entscheidungen, Debugging-Erkenntnisse und architektonische Muster. Dies zwingt Sie dazu, Ihre Codebasis wiederholt zu erklären, Tokens für redundanten Kontext zu verbrennen und die Kontinuität des Workflows zu unterbrechen.
Entwickler umgehen dies derzeit, indem sie CLAUDE.md-Dateien manuell pflegen, Notizen in separaten Dokumenten machen oder den Projektkontext zu Beginn jeder Sitzung neu erklären. Diese Ansätze sind anfällig, zeitaufwendig und erfassen nie den gesamten Reichtum Ihrer Entwicklungshistorie. Claude-mem löst dies, indem es automatisch jeden Tool-Aufruf beobachtet, die Ausgabe in durchsuchbare semantische Erinnerungen komprimiert und intelligent relevante Kontextinformationen abruft, wenn Sie sie benötigen.
Möchten Sie eine integrierte All-in-One-Plattform für Ihr Entwicklerteam, um mit maximaler Produktivität zusammenzuarbeiten?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!
Die Architektur von Claude-mem verstehen
Claude-mem fungiert als persistentes Speicherkompressionssystem, das sich in den Lebenszyklus von Claude Code einklinkt. Es erfasst Tool-Ausgaben – typischerweise 1.000 bis 10.000 Tokens – und komprimiert sie mithilfe des Claude Agent SDK in etwa 500 Tokens umfassende semantische Beobachtungen. Diese Beobachtungen werden nach Typ (Entscheidung, Fehlerbehebung, Feature, Refactoring, Entdeckung, Änderung) kategorisiert und mit relevanten Konzepten und Dateireferenzen versehen, dann in einer lokalen SQLite-Datenbank mit Volltextsuchfunktionen gespeichert.
Das System verwendet fünf Lebenszyklus-Hooks zur Kontextaufnahme:
- SessionStart: Fügt Kontext aus früheren Sitzungen ein, wenn Sie beginnen
- UserPromptSubmit: Erfasst Ihre Abfragen zur Mustererkennung
- PostToolUse: Beobachtet jede Tool-Ausführung und ihre Ausgabe
- Stop: Generiert Sitzungszusammenfassungen, wenn Claude die Antwort beendet
- SessionEnd: Schließt die Sitzungsspeicherung und Bereinigung ab
Diese Architektur ermöglicht eine progressive Offenlegung – ein geschichtetes Speicherabrufsystem, das Abdeckung mit Token-Effizienz in Einklang bringt. Anstatt Ihre gesamte Historie in den Kontext zu werfen, ruft Claude-mem Beobachtungen in Schichten ab, wodurch pro Sitzung etwa 2.250 Tokens im Vergleich zur manuellen Kontextverwaltung eingespart werden.
Installation und Systemanforderungen
Claude-mem erfordert Node.js 18.0.0 oder höher, das neueste Claude Code mit Plugin-Unterstützung und Bun als JavaScript-Laufzeitumgebung und Prozessmanager (wird automatisch installiert, falls fehlend). SQLite 3 ist für die persistente Speicherung gebündelt. Das Plugin funktioniert plattformübergreifend unter Windows, macOS und Linux.
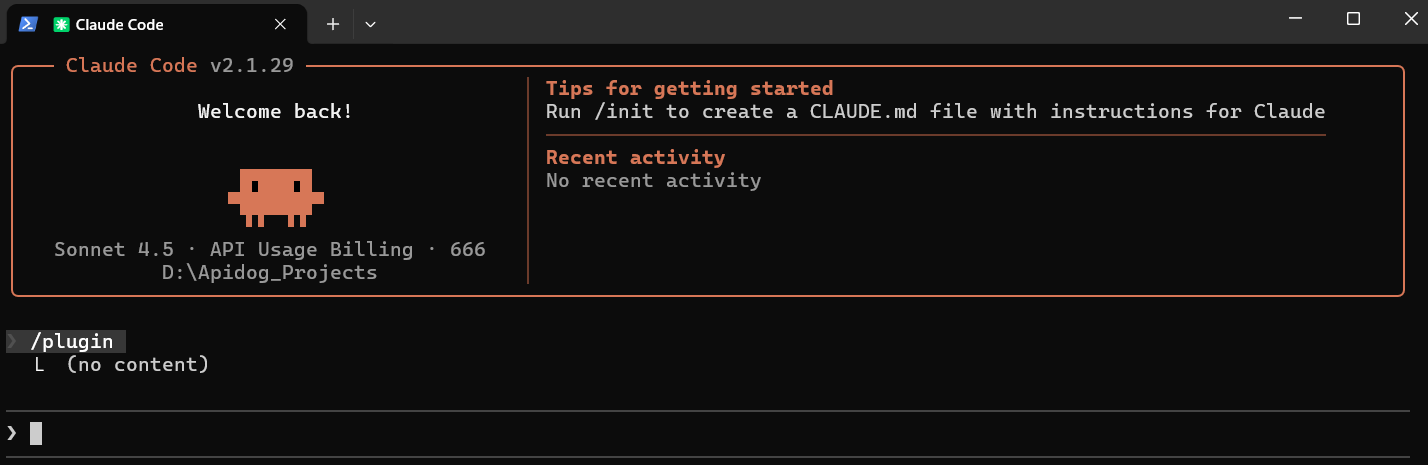
Schnellstart-Installation
Installieren Sie Claude-mem direkt über den Plugin-Marktplatz mit zwei Befehlen:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
Starten Sie Claude Code nach der Installation neu. Das Plugin lädt automatisch vorkompilierte Binärdateien herunter, installiert Abhängigkeiten einschließlich Bun und SQLite, konfiguriert Hooks für das Sitzungslebenszyklus-Management und startet den Worker-Dienst bei Ihrer ersten Sitzung automatisch.
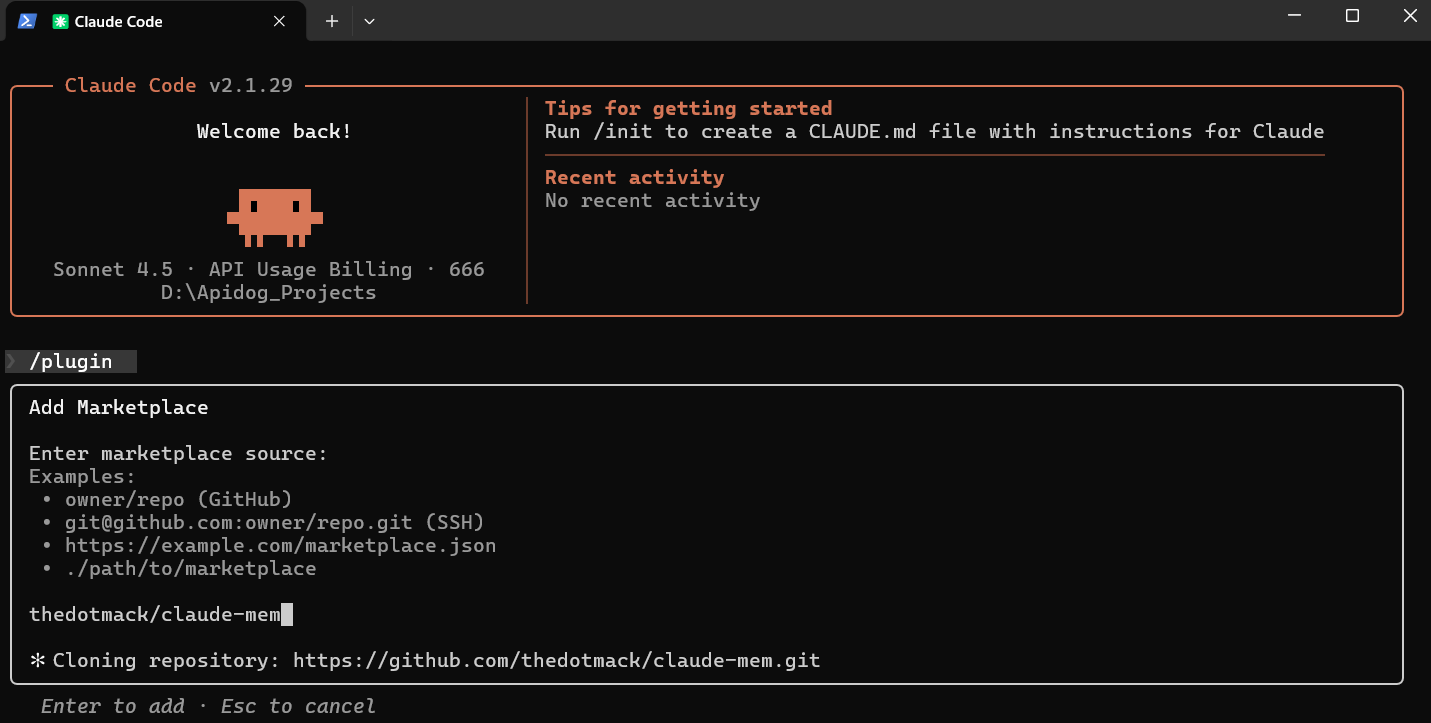
Fortgeschrittene Installation aus dem Quellcode
Für Entwicklung oder Tests klonen und kompilieren Sie von Quelle auf github:
git clone https://github.com/thedotmack/claude-mem.git
cd claude-mem
npm install
npm run build
npm run worker:start
Dieser Ansatz ist nützlich, wenn Sie das Plugin ändern oder Beta-Funktionen wie den Endlosmodus ausführen müssen.

Überprüfung nach der Installation
Überprüfen Sie nach der Installation, ob alles funktioniert:
- Überprüfen Sie die Plugin-Installation:
cat plugin/hooks/hooks.json
- Überprüfen Sie, ob der Worker-Dienst läuft:
curl http://localhost:37777/api/health
- Zeigen Sie die letzten Worker-Protokolle an:
npm run worker:logs
Testen Sie den Kontextabruf, indem Sie eine neue Claude Code-Sitzung starten. Sie sollten sehen, dass der Kontext aus früheren Sitzungen automatisch in der anfänglichen Aufforderung geladen wird.
Datenspeicherung und Konfiguration
Claude-mem speichert alle Daten lokal unter ~/.claude-mem/:
- Datenbank:
~/.claude-mem/claude-mem.db(SQLite mit FTS5-Suche) - PID-Datei:
~/.claude-mem/.worker.pid - Port-Datei:
~/.claude-mem/.worker.port - Protokolle:
~/.claude-mem/logs/worker-JJJJ-MM-TT.log - Einstellungen:
~/.claude-mem/settings.json
Überschreiben Sie das Standard-Datenverzeichnis mit einer Umgebungsvariable:
export CLAUDE_MEM_DATA_DIR=/eigener/pfad
Konfigurationsoptionen
Einstellungen werden in ~/.claude-mem/settings.json verwaltet (wird beim ersten Start automatisch erstellt). Zu den wichtigsten Konfigurationen gehören:
CLAUDE_MEM_CONTEXT_OBSERVATIONS: Anzahl der beim Sitzungsstart injizierten Beobachtungen (Standard: 50)CLAUDE_MEM_FOLDER_INDEX_ENABLED: Aktivieren/Deaktivieren automatisch generierter CLAUDE.md-Dateien in Ordnern- Modellauswahl für KI-gestützte Komprimierung
- Worker-Port- und Host-Einstellungen
- Protokollstufenkonfiguration
Wie Claude-mem Kontext erfasst und verarbeitet
Wenn Sie Claude Code mit aktiviertem claude-mem verwenden, erfasst das System automatisch jeden Tool-Aufruf. Ob Claude eine Datei liest, einen Bash-Befehl ausführt, mit Glob-Mustern sucht oder Code bearbeitet, claude-mem beobachtet die Eingabe und Ausgabe.
Der Worker-Dienst verarbeitet diese Beobachtungen und extrahiert:
- Titel: Kurze Beschreibung des Geschehens
- Untertitel: Zusätzlicher Kontext
- Erzählung: Detaillierte Erklärung der Aktivität
- Fakten: Wichtige Erkenntnisse als Stichpunkte
- Konzepte: Relevante Tags und Kategorien für die Suche
- Typ: Klassifizierung (Entscheidung, Fehlerbehebung, Feature, Refactoring, Entdeckung, Änderung)
- Dateien: Welche Dateien gelesen oder geändert wurden
Diese Komprimierung erfolgt automatisch ohne manuelles Eingreifen. Die rohe Tool-Ausgabe kann 5.000 Tokens betragen, aber die in der Datenbank gespeicherte semantische Beobachtung beträgt etwa 500 Tokens – sie bewahrt die Bedeutung und eliminiert gleichzeitig Rauschen.
Sitzungszusammenfassungen
Wenn Claude die Antwort beendet (wodurch der Stop-Hook ausgelöst wird), generiert claude-mem automatisch eine Sitzungszusammenfassung, die Folgendes enthält:
- Anfrage: Was Sie gefragt haben
- Untersucht: Was Claude zur Beantwortung erforscht hat
- Gelernt: Wichtige Entdeckungen und Erkenntnisse
- Abgeschlossen: Was erreicht wurde
- Nächste Schritte: Empfohlene Folgemaßnahmen
Diese Zusammenfassungen werden zusammen mit einzelnen Beobachtungen in zukünftige Sitzungen eingefügt und bieten sowohl detaillierte als auch übergeordnete narrative Kontextinformationen.
Verwenden von MCP-Suchtools zur Abfrage Ihres Speichers
Claude-mem bietet vier MCP-Tools, die einem token-effizienten 3-Schicht-Workflow-Muster folgen. Dieses Design ruft den Kontext progressiv ab, wodurch die Token-Nutzung minimiert und die Relevanz maximiert wird.
Der 3-Schicht-Workflow
search: Rufen Sie einen kompakten Index mit IDs ab (ca. 50-100 Tokens pro Ergebnis)timeline: Erhalten Sie chronologischen Kontext um interessante Ergebnisseget_observations: Rufen Sie die vollständigen Details NUR für gefilterte IDs ab (ca. 500-1.000 Tokens pro Ergebnis)
Dieser Ansatz erzielt etwa 10-fache Token-Einsparungen, indem er vor dem Abrufen der vollständigen Details filtert.
Verfügbare MCP-Tools
search: Durchsuchen Sie den Speicherindex mit Volltextabfragen. Filtern Sie nach Typ, Datum oder Projekt.timeline: Rufen Sie chronologischen Kontext zu einer bestimmten Beobachtung oder Abfrage ab. Nützlich, um zu verstehen, was zu einer bestimmten Entscheidung oder Fehlerbehebung geführt hat.get_observations: Rufen Sie vollständige Beobachtungsdetails anhand von IDs ab. Fassen Sie immer mehrere IDs in einem einzigen Aufruf zusammen, um den Overhead zu minimieren.__IMPORTANT: Workflow-Dokumentation, die Claude immer sichtbar ist und erklärt, wie das Speichersystem effektiv genutzt wird.
Beispiel für Nutzungsmuster
Finden Sie eine bestimmte Fehlerbehebung:
// Schritt 1: Suchen Sie nach dem Fehler
search(query="Authentifizierungsfehler", type="bugfix", limit=10)
// Schritt 2: Überprüfen Sie den Index, identifizieren Sie relevante IDs (z.B. #123, #456)
// Schritt 3: Rufen Sie die vollständigen Details für relevante Beobachtungen ab
get_observations(ids=[123, 456])
Erkunden Sie aktuelle architektonische Entscheidungen:
search(query="Datenbankschema", type="decision", limit=5)
Finden Sie alles, was mit einer bestimmten Datei zusammenhängt:
search(query="worker-service.ts", limit=20)
Abfragen in natürlicher Sprache
Sie können Claude auf natürliche Weise nach Ihrer Projekthistorie fragen:
- "Was haben wir bezüglich der Fehlerbehandlung entschieden?"
- "Wie haben wir die Authentifizierung implementiert?"
- "Welche Fehler haben wir in der API-Ebene behoben?"
- "Zeig mir Änderungen am Datenbankschema"
Claude ruft automatisch die entsprechenden MCP-Tools auf, um relevante Kontextinformationen abzurufen, und präsentiert die Ergebnisse mit claude-mem:// URI-Zitaten, die auf spezifische Beobachtungen verweisen.
Ordnerkontextdateien und automatische CLAUDE.md-Generierung
Claude-mem generiert automatisch CLAUDE.md-Dateien in Projektordnern und erstellt Aktivitätszeitachsen, die die globale Speicherdatenbank ergänzen.
Wie Ordnerkontext funktioniert
Wenn Sie mit Dateien in einem Ordner arbeiten, macht claude-mem Folgendes:
- Identifiziert eindeutige Ordnerpfade aus berührten Dateien
- Fragt aktuelle Beobachtungen ab, die für jeden Ordner relevant sind
- Generiert eine formatierte Zeitachse der Aktivität
- Schreibt sie in die CLAUDE.md-Datei in diesem Ordner (innerhalb der Tags
<claude-mem-context>)
Die CLAUDE.md-Datei jedes Ordners enthält einen Abschnitt "Kürzliche Aktivität", der Beobachtungs-IDs, Zeitstempel, Typindikatoren (Fehlerbehebungen, Features, Entdeckungen), kurze Titel und geschätzte Token-Anzahlen anzeigt.
Erhaltung von Benutzerinhalten
Der automatisch generierte Inhalt wird in <claude-mem-context>-Tags eingeschlossen. Jeglicher Inhalt, den Sie außerhalb dieser Tags schreiben, bleibt erhalten, wenn die Datei neu generiert wird. Dies ermöglicht Ihnen:
- Ihre eigene Dokumentation oberhalb oder unterhalb des generierten Abschnitts hinzuzufügen
- Ordnerspezifische Anweisungen für Claude zu schreiben
- Architektonische Notizen oder Konventionen einzuschließen
Beispiel für die CLAUDE.md-Struktur:
# Authentifizierungsmodul
Dieser Ordner enthält den gesamten authentifizierungsbezogenen Code.
Befolgen Sie die etablierten Muster für neue Authentifizierungsanbieter.
<claude-mem-context>
# Kürzliche Aktivität
| ID | Zeit | Typ | Titel | Tokens |
|----|------|------|-------|--------|
| #1234 | 16:30 Uhr | 🔵 | Benutzerauthentifizierung implementiert | ~250 |
| #1235 | 16:45 Uhr | 🔴 | Login-Weiterleitungsfehler behoben | ~180 |
</claude-mem-context>
## Manuelle Notizen
- OAuth-Anbieter gehören in /providers/
- Die Sitzungsverwaltung verwendet Redis
Datenschutzkontrollen und Sicherheit
Claude-mem bietet granulare Datenschutzkontrollen, um zu verhindern, dass sensible Daten in das Speichersystem gelangen.
Private Inhalts-Tags
Umschließen Sie sensible Inhalte in <private>-Tags, um sie von der Speicherung auszuschließen:
<private>
API_KEY=sk-live-abc123xyz789
DATABASE_PASSWORD=supersecret456
</private>
Die Edge-Verarbeitung stellt sicher, dass private Inhalte niemals die Datenbank erreichen. Dies ist entscheidend für API-Schlüssel, Anmeldeinformationen und proprietäre Logik.
Dual-Tag-Datenschutzsystem
Claude-mem verwendet einen Dual-Tag-Ansatz:
<private>: Benutzergesteuerte Privatsphäre für sensible Inhalte<claude-mem-context>: Systemseitige Tags verhindern die rekursive Speicherung von Beobachtungen
Web-Viewer-Benutzeroberfläche und Echtzeitüberwachung
Claude-mem betreibt einen Web-Viewer unter http://localhost:37777 zur Echtzeit-Visualisierung des Speicherstroms. Die Benutzeroberfläche zeigt:
- Live-Beobachtungsstream mit Emoji-Indikatoren für Wichtigkeit
- Sitzungszeitachse mit chronologischen Markierungen
- Suchoberfläche zum Abfragen von Erinnerungen
- Einstellungsfeld für Konfigurationsanpassungen
- Versionswechsel zwischen stabilen und Beta-Kanälen
Diese Benutzeroberfläche ist für die grundlegende Nutzung optional, aber von unschätzbarem Wert, um zu verstehen, was claude-mem erfasst und wie es Ihre Entwicklungshistorie organisiert.
Beta-Funktionen: Endlosmodus
Der Beta-Kanal bietet den Endlosmodus, eine biomimetische Speicherarchitektur für längere Sitzungen. Anstatt nach 50 Tool-Verwendungen an Kontextgrenzen zu stoßen, verspricht der Endlosmodus etwa 1.000 Verwendungen – eine 20-fache Steigerung. Dies wird erreicht, indem Tool-Ausgaben in Echtzeit komprimiert werden, wodurch Tokens um etwa 95 % reduziert werden und die Skalierung von O(N²) quadratisch auf O(N) linear geändert wird.
Kompromiss: Die Generierung von Beobachtungen fügt pro Tool-Aufruf 60-90 Sekunden hinzu. Für tiefe, durchdachte Code-Sitzungen, die sich über Tage oder Wochen erstrecken, könnte diese Latenz akzeptabel sein. Für eine schnelle Tool-Nutzung könnte sie hinderlich sein.
Aktivieren Sie Beta-Funktionen über die Web-Viewer-Benutzeroberfläche unter http://localhost:37777 → Einstellungen → Versionskanal.
Fehlerbehebung bei häufigen Problemen
Worker-Dienst startet nicht
Wenn der Worker nicht auf Port 37777 startet:
- Überprüfen Sie, ob der Port bereits belegt ist:
lsof -i :37777
- Konfigurieren Sie einen alternativen Port:
export CLAUDE_MEM_WORKER_PORT=8080
- Starten Sie den Worker manuell:
bun plugin/scripts/worker-service.cjs
Speicher wird nicht gesichert
Wenn Claude sich nicht an frühere Sitzungen erinnert:
- Überprüfen Sie, ob der Worker läuft:
npm run worker:status
- Überprüfen Sie, ob die Datenbankdatei existiert:
ls -la ~/.claude-mem/claude-mem.db
- Überprüfen Sie die Worker-Protokolle auf Fehler:
npm run worker:logs
Probleme bei der Kontextinjektion
Wenn zu viel oder zu wenig Kontext zu Beginn der Sitzung angezeigt wird:
Passen Sie das Beobachtungslimit an:
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=10 # Reduzieren
export CLAUDE_MEM_CONTEXT_OBSERVATIONS=100 # Erhöhen
Leere CLAUDE.md-Dateien
Wenn claude-mem leere CLAUDE.md-Dateien in Ihrem Projekt erstellt, ist dies ein bekanntes Problem in v9.0.5. Aktuelle Workarounds umfassen das manuelle Löschen erstellter Verzeichnisse, das Hinzufügen von Mustern zu .gitignore oder das Warten auf die Behebung in einer späteren Version.
Claude Desktop Integration
Claude-mem funktioniert mit Claude Desktop über die MCP-Serverkonfiguration. Fügen Sie den mcp-search-Server Ihrer Claude Desktop-Konfiguration hinzu, verweisen Sie auf das MCP-Server-Skript in der claude-mem-Installation und starten Sie Claude Desktop neu.
Einmal konfiguriert, fragen Sie natürlich nach vergangener Arbeit:
- "Was haben wir in der letzten Sitzung gemacht?"
- "Haben wir diesen Fehler schon einmal behoben?"
- "Wie haben wir die Authentifizierung implementiert?"
Verwenden Sie den Web-Viewer unter localhost:37777, um zu überprüfen, ob Erinnerungen erfasst werden, und überprüfen Sie die Claude Desktop-Protokolle, wenn die Verbindung fehlschlägt.
Befehle zur manuellen Worker-Verwaltung
Aus dem claude-mem-Verzeichnis können Sie den Worker-Dienst verwalten:
npm run worker:start # Worker-Dienst starten
npm run worker:stop # Worker-Dienst stoppen
npm run worker:restart # Worker-Dienst neu starten
npm run worker:logs # Worker-Protokolle anzeigen
npm run worker:status # Worker-Status prüfen
Fazit
Claude-mem verwandelt Claude Code von einem zustandslosen Assistenten in einen persistenten Entwicklungspartner, der über die Zeit Wissen über Ihre Codebasis ansammelt. Durch die automatische Erfassung der Tool-Nutzung, die Komprimierung von Beobachtungen in durchsuchbare Erinnerungen und den intelligenten Abruf relevanter Kontextinformationen eliminiert es den wiederholten Kontextaufbau, der die KI-gestützte Entwicklung verlangsamt.
Die Architektur des Systems mit progressiver Offenlegung – geschichteter Abruf mit MCP-Tools, ordnerbasierten CLAUDE.md-Dateien und Datenschutzkontrollen – bietet eine etwa 10-fache Token-Effizienz im Vergleich zur manuellen Kontextverwaltung, während gleichzeitig vollständige Datenlokalität und Sicherheit gewährleistet sind.
Wenn Sie APIs erstellen oder mit externen Diensten in Ihrem Claude-mem-verbesserten Workflow arbeiten, optimieren Sie Ihr Testen mit Apidog. Es bietet visuelles API-Testen, automatische Dokumentationsgenerierung und kollaboratives Debugging, die Ihre persistente Speicherumgebung ergänzen.