

Wollten Sie schon immer anspruchsvolle KI-Vision-Modelle direkt auf Ihrem eigenen Rechner ausführen, ohne auf teure Cloud-Dienste angewiesen zu sein oder sich um den Datenschutz sorgen zu müssen? Nun, Sie haben Glück! Heute tauchen wir tief in die Ausführung von **Qwen 3 VL (Vision Language) Modellen lokal mit Ollama** ein, und glauben Sie mir, das wird Ihren KI-Entwicklungs-Workflow revolutionieren.
Bevor wir uns nun den technischen Details widmen, lassen Sie mich Sie etwas fragen: Sind Sie es leid, auf API-Ratenbegrenzungen zu stoßen, horrende Kosten für Cloud-Inferenz zu zahlen oder einfach mehr Kontrolle über Ihre KI-Modelle zu wünschen? Wenn Sie mit Ja genickt haben, dann ist dieser Leitfaden speziell für Sie konzipiert. Wenn Sie außerdem ein leistungsstarkes Tool zum Testen und Debuggen Ihrer lokalen KI-APIs suchen, empfehle ich Ihnen dringend, **Apidog kostenlos herunterzuladen** – es ist eine ausgezeichnete API-Testplattform, die nahtlos mit Ollamas lokalen Endpunkten zusammenarbeitet.
In diesem Leitfaden führen wir Sie durch alles, was Sie benötigen, um Qwen 3 VL-Modelle lokal mit Ollama auszuführen – von der Installation über die Inferenz und Fehlerbehebung bis hin zur Integration mit Tools wie Apidog. Am Ende dieses umfassenden Leitfadens werden Sie ein voll funktionsfähiges, privates und reaktionsschnelles Vision-Language Qwen3-VL reibungslos auf Ihrem lokalen Rechner laufen haben, und Sie werden mit allem Wissen ausgestattet sein, das Sie benötigen, um es in Ihre Projekte zu integrieren.
Also, schnallen Sie sich an, schnappen Sie sich Ihr Lieblingsgetränk und begeben wir uns gemeinsam auf diese spannende Reise.
Qwen3-VL verstehen: Das revolutionäre Vision-Language-Modell

Warum Qwen 3 VL? Und warum lokal ausführen?
Bevor wir uns den technischen Schritten widmen, sprechen wir darüber, **warum Qwen 3 VL wichtig ist** und warum die lokale Ausführung einen Wendepunkt darstellt.
Qwen 3 VL ist Teil von Alibabas Qwen-Serie, wurde aber speziell für **Vision-Language-Aufgaben** entwickelt. Im Gegensatz zu traditionellen LLMs, die nur Text verstehen, kann Qwen 3 VL:
- Bilder analysieren und Fragen dazu beantworten („Was ist auf diesem Foto zu sehen?“)
- Detaillierte Bildunterschriften generieren
- Strukturierte Daten aus Diagrammen, Schaubildern oder Dokumenten extrahieren
- Multimodale RAG (Retrieval-Augmented Generation) mit visuellem Kontext unterstützen
Und da es Open-Weight ist (unter der Tongyi Qianwen-Lizenz), können Entwickler es **frei verwenden, modifizieren und bereitstellen**, solange sie die Lizenzbedingungen einhalten.
Nun, warum **lokal** ausführen?
- **Datenschutz**: Ihre Bilder und Prompts verlassen niemals Ihren Rechner.
- **Kosten**: Keine API-Gebühren oder Nutzungslimits.
- **Anpassung**: Feinabstimmung, Quantisierung oder Integration in Ihre eigenen Pipelines.
- **Offline-Zugriff**: Perfekt für sichere oder luftdichte Umgebungen.
Doch die lokale Bereitstellung bedeutete früher, sich mit CUDA-Versionen, Python-Umgebungen und riesigen Dockerfiles herumzuschlagen. Hier kommt **Ollama** ins Spiel.
Modellvarianten: Für jeden Anwendungsfall etwas dabei
Qwen3-VL ist in verschiedenen Größen erhältlich, um unterschiedlichen Hardwarekonfigurationen und Anwendungsfällen gerecht zu werden. Egal, ob Sie an einem leichten Laptop arbeiten oder Zugang zu einer leistungsstarken Workstation haben, es gibt ein Qwen3-VL-Modell, das perfekt zu Ihren Anforderungen passt.
**Dense Modelle (Traditionelle Architektur):**
- **Qwen3-VL-2B**: Perfekt für Edge-Geräte und mobile Anwendungen
- **Qwen3-VL-4B**: Gutes Gleichgewicht zwischen Leistung und Ressourcenverbrauch
- **Qwen3-VL-8B**: Exzellent für allgemeine Aufgaben mit moderatem Denkvermögen
- **Qwen3-VL-32B**: High-End-Aufgaben, die starkes Denkvermögen und umfangreichen Kontext erfordern
**Mixture-of-Experts (MoE) Modelle (Effiziente Architektur):**
- **Qwen3-VL-30B-A3B**: Effiziente Leistung mit nur 3 Milliarden aktiven Parametern
- **Qwen3-VL-235B-A22B**: Anwendungen im massiven Maßstab mit insgesamt 235 Milliarden Parametern, aber nur 22 Milliarden aktiven
Das Schöne an MoE-Modellen ist, dass sie für jede Inferenz nur eine Teilmenge von „Experten“-neuronalen Netzen aktivieren, was massive Parameterzahlen ermöglicht, während die Rechenkosten überschaubar bleiben.
Ollama: Ihr Tor zur lokalen KI-Exzellenz
Nachdem wir nun verstanden haben, was Qwen3-VL zu bieten hat, sprechen wir darüber, warum Ollama die ideale Plattform ist, um diese Modelle lokal auszuführen. Stellen Sie sich Ollama als den Dirigenten eines Orchesters vor – es orchestriert alle komplexen Prozesse im Hintergrund, damit Sie sich auf das Wichtigste konzentrieren können: die Nutzung Ihrer KI-Modelle.
Was ist Ollama und warum ist es perfekt für Qwen 3 VL?
Ollama ist ein Open-Source-Tool, mit dem Sie **große Sprachmodelle (und jetzt auch multimodale Modelle) lokal mit einem einzigen Befehl ausführen können**. Stellen Sie es sich wie „Docker für LLMs“ vor, aber noch einfacher.
Hauptmerkmale:
- Automatische GPU-Beschleunigung (über Metal unter macOS, CUDA unter Linux)
- Integrierte Modellbibliothek (einschließlich Llama 3, Mistral, Gemma und jetzt Qwen)
- REST-API für einfache Integration
- Leichtgewichtig und anfängerfreundlich
Das Beste daran ist, dass **Ollama jetzt Qwen 3 VL-Modelle unterstützt**, einschließlich Varianten wie qwen3-vl:4b und qwen3-vl:8b. Dies sind quantisierte Versionen, die für lokale Hardware optimiert sind, was bedeutet, dass Sie sie auf Consumer-GPUs oder sogar leistungsstarken Laptops ausführen können.
Die technische Magie hinter Ollama
Was passiert im Hintergrund, wenn Sie einen Ollama-Befehl ausführen? Es ist wie ein gut choreografierter Tanz technologischer Prozesse:
1. **Modell-Download & Caching**: Ollama lädt Modellgewichte intelligent herunter und speichert sie im Cache, was schnelle Startzeiten für häufig verwendete Modelle gewährleistet.
2. **Quantisierungsoptimierung**: Modelle werden automatisch für Ihre Hardwarekonfiguration optimiert, wobei die beste Quantisierungsmethode (4-Bit, 8-Bit usw.) für Ihre GPU und Ihren RAM ausgewählt wird.
3. **Speicherverwaltung**: Fortschrittliche Speicherzuordnungstechniken gewährleisten eine effiziente GPU-Speichernutzung bei gleichzeitig hoher Leistung.
4. **Parallelverarbeitung**: Ollama nutzt mehrere CPU-Kerne und GPU-Streams für maximalen Durchsatz.
Voraussetzungen: Was Sie vor der Installation benötigen
Bevor wir etwas installieren, stellen wir sicher, dass Ihr System bereit ist.
Hardware-Anforderungen
- **RAM**: Mindestens 16 GB (32 GB empfohlen für 8B-Modelle)
- **GPU**: NVIDIA GPU mit 8 GB+ VRAM (für Linux) oder Apple Silicon Mac (M1/M2/M3 mit 16 GB+ Unified Memory)
- **Speicherplatz**: 10–20 GB freier Speicherplatz (Modelle sind groß!)
Software-Anforderungen
- **Betriebssystem**: macOS (12+) oder Linux (Ubuntu 20.04+ empfohlen)
- **Ollama**: Neueste Version (v0.1.40+ für Qwen 3 VL-Unterstützung)
- **Optional**: Docker (falls Sie eine containerisierte Bereitstellung bevorzugen), Python (für fortgeschrittene Skripte)
Schritt-für-Schritt-Installationsanleitung: Ihr Weg zur lokalen KI-Meisterschaft
Schritt 1: Ollama installieren – Das Fundament
Beginnen wir mit dem Fundament unseres gesamten Setups. Die Installation von Ollama ist überraschend einfach – es wurde so konzipiert, dass es für jeden zugänglich ist, vom KI-Neuling bis zum erfahrenen Entwickler.
**Für macOS-Benutzer:**
1. Besuchen Sie ollama.com/download
2. Laden Sie das macOS-Installationsprogramm herunter
3. Öffnen Sie die heruntergeladene Datei und ziehen Sie Ollama in Ihren Anwendungen-Ordner
4. Starten Sie Ollama aus Ihrem Anwendungen-Ordner oder über die Spotlight-Suche
Der Installationsprozess ist unter macOS unglaublich reibungslos, und Sie werden das Ollama-Symbol in Ihrer Menüleiste sehen, sobald die Installation abgeschlossen ist.
**Für Windows-Benutzer:**
1. Navigieren Sie zu ollama.com/download
2. Laden Sie das Windows-Installationsprogramm (.exe-Datei) herunter
3. Führen Sie das Installationsprogramm mit Administratorrechten aus
4. Befolgen Sie den Installationsassistenten (er ist recht intuitiv)
5. Nach der Installation startet Ollama automatisch im Hintergrund
Windows-Benutzer sehen möglicherweise eine Windows Defender-Benachrichtigung – keine Sorge, das ist beim ersten Start normal. Klicken Sie einfach auf „Zulassen“, und Ollama wird perfekt funktionieren.
**Für Linux-Benutzer:**
Linux-Benutzer haben zwei Optionen:
**Option A: Installationsskript (Empfohlen)**
bash
curl -fsSL <https://ollama.com/install.sh> | sh
**Option B: Manuelle Installation**
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
Schritt 2: Überprüfung Ihrer Installation
Nachdem Ollama nun installiert ist, stellen wir sicher, dass alles korrekt funktioniert. Betrachten Sie dies als einen Rauchtest, um sicherzustellen, dass unser Fundament solide ist.
Öffnen Sie Ihr Terminal (oder die Eingabeaufforderung unter Windows) und führen Sie aus:
bash
ollama --version
Sie sollten eine Ausgabe ähnlich der folgenden sehen:
ollama version is 0.1.0
Als Nächstes testen wir die grundlegende Funktionalität:
bash
ollama serve
Dieser Befehl startet den Ollama-Server. Sie sollten eine Ausgabe sehen, die anzeigt, dass der Server unter `http://localhost:11434` läuft. Lassen Sie den Server laufen – wir werden ihn verwenden, um unsere Qwen3-VL-Installation zu testen.
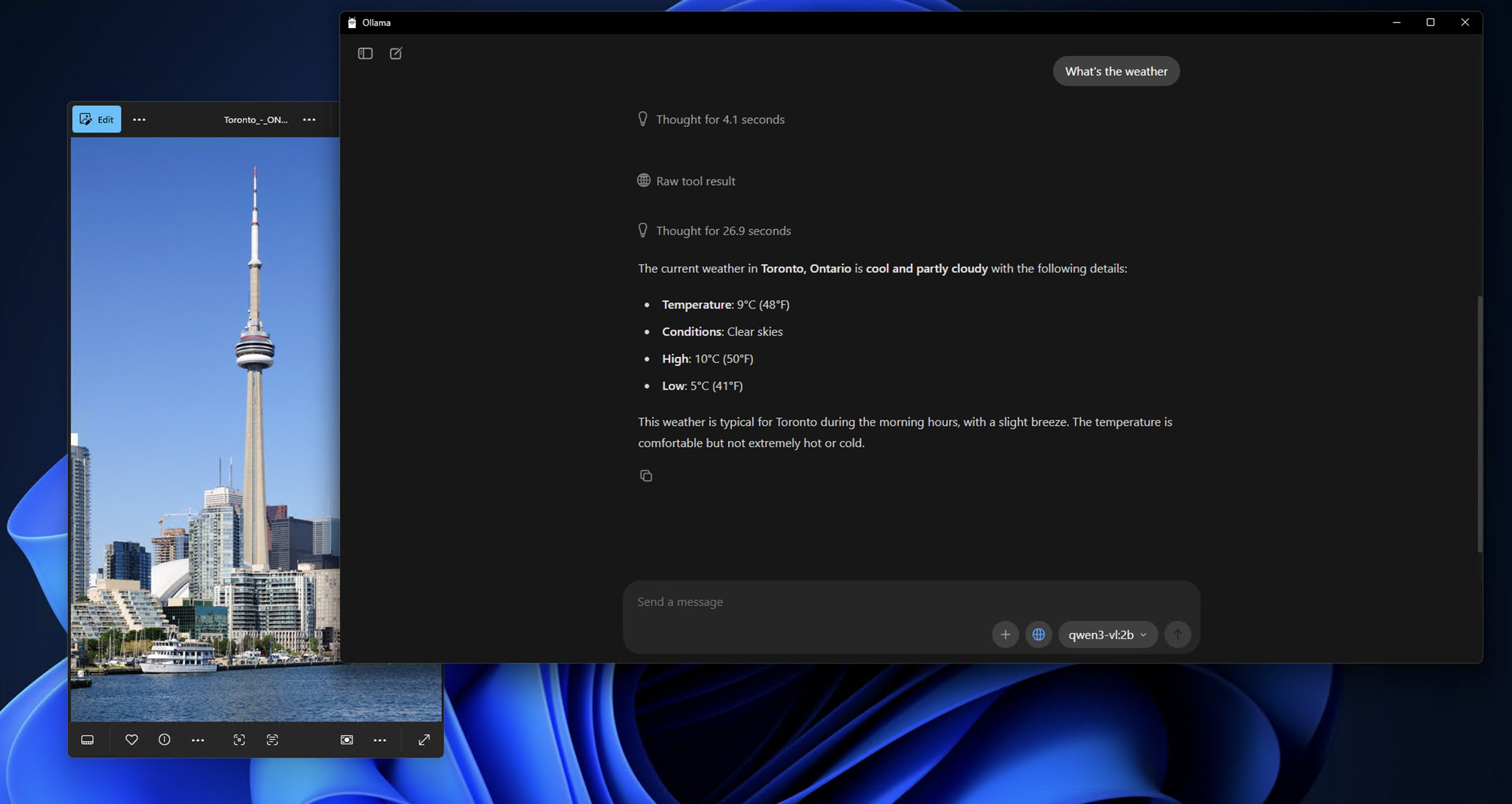
**Schritt 3: Qwen3-VL-Modelle herunterladen und ausführen**
Nun zum spannenden Teil! Laden wir unser erstes Qwen3-VL-Modell herunter und führen es aus. Wir beginnen mit einem kleineren Modell, um uns heranzutasten, und gehen dann zu leistungsstärkeren Varianten über.
**Testen mit Qwen3-VL-4B (Guter Ausgangspunkt):**
bash
ollama run qwen3-vl:4b
Dieser Befehl wird:
1. Das Qwen3-VL-4B-Modell herunterladen (ca. 2,8 GB)
2. Es für Ihre Hardware optimieren
3. Eine interaktive Chatsitzung starten
**Andere Modellvarianten ausführen:**
Wenn Sie leistungsfähigere Hardware haben, versuchen Sie diese Alternativen:
bash
# Für Systeme mit 8GB+ GPUollama run qwen3-vl:8b
# Für Systeme mit 16GB+ RAMollama run qwen3-vl:32b
# Für High-End-Systeme mit mehreren GPUsollama run qwen3-vl:30b-a3b
# Für maximale Leistung (erfordert ernsthafte Hardware)ollama run qwen3-vl:235b-a22b
**Schritt 4: Erste Interaktion mit Ihrem lokalen Qwen3-VL**
Sobald das Modell heruntergeladen und ausgeführt wird, sehen Sie eine Eingabeaufforderung wie diese:
Send a message (type /? for help)
Testen wir die Fähigkeiten des Modells mit einer einfachen Bildanalyse:
**Ein Testbild vorbereiten:**
Suchen Sie ein beliebiges Bild auf Ihrem Computer – es könnte ein Foto, ein Screenshot oder eine Illustration sein. Für dieses Beispiel gehe ich davon aus, dass Sie ein Bild namens test_image.jpg in Ihrem aktuellen Verzeichnis haben.

**Interaktives Chat-Testen:**
bash
What do you see in this image? /path/to/your/image.jpg
**Alternative: Verwendung der API zum Testen**
Wenn Sie lieber programmatisch testen möchten, können Sie die Ollama API verwenden. Hier ist ein einfacher Test mit curl:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

**Schritt 5: Erweiterte Konfigurationsoptionen**
Nachdem Sie nun eine funktionierende Installation haben, lassen Sie uns einige erweiterte Konfigurationsoptionen erkunden, um Ihr Setup für Ihre spezifische Hardware und Ihren Anwendungsfall zu optimieren.
**Speicheroptimierung:**
Wenn Sie auf Speicherprobleme stoßen, können Sie das Modellladeverhalten anpassen:
bash
# Set maximum memory usage (adjust based on your RAM)export OLLAMA_MAX_LOADED_MODELS=1
# Enable GPU offloadingexport OLLAMA_GPU=1
# Set custom port (if 11434 is already in use)export OLLAMA_HOST=0.0.0.0:11435
**Quantisierungsoptionen:**
Für Systeme mit begrenztem VRAM können Sie bestimmte Quantisierungsstufen erzwingen:
bash
# Load model with 4-bit quantization (more compatible, slower)ollama run qwen3-vl:4b --format json
# Load with 8-bit quantization (balanced)ollama run qwen3-vl:8b --format json
**Multi-GPU-Konfiguration:**
Wenn Sie mehrere GPUs haben, können Sie angeben, welche verwendet werden sollen:
bash
# Use specific GPU IDs (Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# On macOS with multiple Apple Silicon GPUsexport CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Testen und Integration mit Apidog: Qualität und Leistung sicherstellen

Nachdem Sie Qwen3-VL nun lokal ausführen, sprechen wir darüber, wie Sie es richtig testen und in Ihren Entwicklungs-Workflow integrieren können. Hier glänzt Apidog wirklich als unverzichtbares Tool für KI-Entwickler.
Apidog ist nicht nur ein weiteres API-Testtool – es ist eine umfassende Plattform, die speziell für moderne API-Entwicklungs-Workflows entwickelt wurde. Wenn Sie mit lokalen KI-Modellen wie Qwen3-VL arbeiten, benötigen Sie ein Tool, das Folgendes kann:
1. **Komplexe JSON-Strukturen verarbeiten**: KI-Modellantworten enthalten oft verschachteltes JSON mit unterschiedlichen Inhaltstypen
2. **Dateiuploads unterstützen**: Viele KI-Modelle benötigen Bild-, Video- oder Dokumenteingaben
3. **Authentifizierung verwalten**: Sicheres Testen von Endpunkten mit korrekter Authentifizierungsbehandlung
4. **Automatisierte Tests erstellen**: Regressionstests für die Konsistenz der Modellleistung
5. **Dokumentation generieren**: Automatische Erstellung von API-Dokumentation aus Ihren Testfällen
Fehlerbehebung bei häufigen Problemen
Selbst mit der Einfachheit von Ollama können Sie auf Probleme stoßen. Hier sind Lösungen für häufige Probleme.
**❌** „Modell nicht gefunden“ oder „Nicht unterstütztes Modell“
- Stellen Sie sicher, dass Sie Ollama **v0.1.40 oder neuer** verwenden
- Führen Sie
ollama pull qwen3-vl:4berneut aus – manchmal schlägt der Download stillschweigend fehl
**❌** „Speicher voll“ auf der GPU
- Versuchen Sie die **4B-Version** anstelle der 8B-Version
- Schließen Sie andere GPU-intensive Anwendungen (Chrome, Spiele usw.)
- Unter Linux überprüfen Sie den VRAM mit
nvidia-smi
**❌** Bild nicht erkannt
- Bestätigen Sie, dass das Bild **kleiner als 4 MB** ist
- Verwenden Sie **PNG oder JPG** (vermeiden Sie HEIC, BMP)
- Stellen Sie sicher, dass die Base64-Zeichenkette **keine Zeilenumbrüche** enthält (verwenden Sie
base64 -w 0unter Linux)
**❌** Langsame Inferenz auf der CPU
- Qwen 3 VL ist selbst quantisiert groß. Erwarten Sie 1–5 Tokens/Sek. auf der CPU
- Rüsten Sie auf Apple Silicon oder NVIDIA GPU auf, um eine 10-fache Beschleunigung zu erzielen
Praktische Anwendungsfälle für lokales Qwen 3 VL
Warum all dieser Aufwand? Hier sind praktische Anwendungen:
- **Dokumentenintelligenz**: Extrahieren Sie Tabellen, Signaturen oder Klauseln aus gescannten PDFs
- **Barrierefreiheitstools**: Beschreiben Sie Bilder für sehbehinderte Benutzer
- **Interne Wissensbots**: Beantworten Sie Fragen zu internen Diagrammen oder Dashboards
- **Bildung**: Erstellen Sie einen Tutor, der mathematische Probleme anhand von Fotos erklärt
- **Sicherheitsanalyse**: Analysieren Sie Netzwerkdiagramme oder Screenshots von Systemarchitekturen
Da es **lokal** ist, vermeiden Sie das Senden sensibler visueller Daten an Drittanbieter-APIs – ein großer Vorteil für Unternehmen und datenschutzbewusste Entwickler.
Fazit: Ihre Reise zur lokalen KI-Exzellenz
Herzlichen Glückwunsch! Sie haben gerade eine epische Reise in die Welt der lokalen KI mit Qwen3-VL und Ollama abgeschlossen. Inzwischen sollten Sie Folgendes haben:
- Eine voll funktionsfähige Qwen3-VL-Installation, die lokal läuft
- Umfassendes Test-Setup mit Apidog
- Tiefes Verständnis der Fähigkeiten und Einschränkungen des Modells
- Praktisches Wissen zur Integration dieser Modelle in reale Anwendungen
- Fähigkeiten zur Fehlerbehebung bei häufigen Problemen
- Zukunftssichere Strategien für anhaltenden Erfolg
Die Tatsache, dass Sie es so weit geschafft haben, zeigt Ihr Engagement, modernste KI-Technologie zu verstehen und zu nutzen. Sie haben nicht nur ein Modell installiert – Sie haben Fachwissen in einer Technologie erworben, die die Art und Weise, wie wir mit visuellen und textuellen Informationen interagieren, neu gestaltet.
Die Zukunft ist lokale KI
Was wir hier erreicht haben, ist mehr als nur ein technisches Setup – es ist ein Schritt in eine Zukunft, in der KI zugänglich, privat und unter individueller Kontrolle ist. Da sich diese Modelle ständig verbessern und effizienter werden, bewegen wir uns auf eine Welt zu, in der ausgeklügelte KI-Fähigkeiten jedem zur Verfügung stehen, unabhängig von Budget oder technischem Fachwissen.
Denken Sie daran, die Reise endet hier nicht. Die KI-Technologie entwickelt sich rasant weiter, und neugierig, anpassungsfähig und engagiert in der Community zu bleiben, wird sicherstellen, dass Sie diese leistungsstarken Tools weiterhin effektiv nutzen.
Abschließende Gedanken
Qwen 3 VL lokal mit Ollama auszuführen, ist nicht nur eine technische Demonstration oder Bequemlichkeit oder Kostenersparnis – es ist ein Einblick in die Zukunft der KI auf dem Gerät. Da Modelle effizienter und Hardware leistungsfähiger werden, werden wir sehen, wie mehr Entwickler private, multimodale Funktionen direkt in ihren Apps bereitstellen. Sie verfügen nun über die Tools, um KI-Technologie ohne Einschränkungen zu erkunden, frei zu experimentieren und Anwendungen zu erstellen, die für Sie und Ihre Organisation wichtig sind.
Die Kombination der beeindruckenden multimodalen Fähigkeiten von Qwen3-VL und der benutzerfreundlichen Oberfläche von Ollama schafft Innovationsmöglichkeiten, die zuvor nur großen Unternehmen mit massiven Ressourcen zur Verfügung standen. Sie sind jetzt Teil einer wachsenden Gemeinschaft von Entwicklern, die die KI-Technologie demokratisieren.
Und mit Tools wie **Ollama**, die die Bereitstellung vereinfachen, und **Apidog**, das die API-Entwicklung optimiert, war die Einstiegshürde noch nie so niedrig.
Egal, ob Sie ein Solo-Hacker, ein Startup-Gründer oder ein Unternehmensingenieur sind, jetzt ist der perfekte Zeitpunkt, um mit Vision-Language-Modellen sicher, erschwinglich und lokal zu experimentieren.