
Meta’s Llama 3.2 hat sich als bahnbrechendes Sprachmodell in der Landschaft der künstlichen Intelligenz erwiesen und bietet beeindruckende Fähigkeiten für die Text- und Bildverarbeitung. Für Entwickler und KI-Enthusiasten, die die Leistung dieses fortschrittlichen Modells auf ihren lokalen Maschinen nutzen möchten, ist Ollama die ideale Lösung. Diese umfassende Anleitung führt Sie durch den Prozess der lokalen Ausführung von Llama 3.2 mit diesen leistungsstarken Plattformen und ermöglicht es Ihnen, modernste KI-Technologie zu nutzen, ohne sich auf Cloud-Dienste verlassen zu müssen.
Was ist Llama 3.2: Das Neueste in der KI-Innovation
Bevor wir uns mit dem Installationsprozess befassen, wollen wir kurz untersuchen, was Llama 3.2 so besonders macht:
- Multimodale Fähigkeiten: Llama 3.2 kann sowohl Text als auch Bilder verarbeiten und eröffnet neue Möglichkeiten für KI-Anwendungen.
- Verbesserte Effizienz: Entwickelt für eine bessere Leistung mit reduzierter Latenz, was es ideal für den lokalen Einsatz macht.
- Verschiedene Modellgrößen: Erhältlich in mehreren Größen, von leichten 1B- und 3B-Modellen, die für Edge-Geräte geeignet sind, bis hin zu leistungsstarken 11B- und 90B-Versionen für komplexere Aufgaben.
- Erweiterter Kontext: Unterstützt eine Kontextlänge von 128K, was ein umfassenderes Verständnis und die Generierung von Inhalten ermöglicht.
Lassen Sie uns nun untersuchen, wie Sie Llama 3.2 lokal mit Ollama ausführen können
Llama 3.2 mit Ollama ausführen
Ollama ist ein leistungsstarkes, entwicklerfreundliches Tool zum lokalen Ausführen großer Sprachmodelle. Hier ist eine Schritt-für-Schritt-Anleitung, um Llama 3.2 zum Laufen zu bringen:
Schritt 1: Ollama installieren
Zuerst müssen Sie Ollama herunterladen und auf Ihrem System installieren:
- Besuchen Sie die offizielle Ollama-Website.
- Laden Sie die entsprechende Version für Ihr Betriebssystem (Windows, macOS oder Linux) herunter.
- Befolgen Sie die auf der Website bereitgestellten Installationsanweisungen.
Schritt 2: Das Llama 3.2-Modell abrufen
Sobald Ollama installiert ist, öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung und führen Sie Folgendes aus:
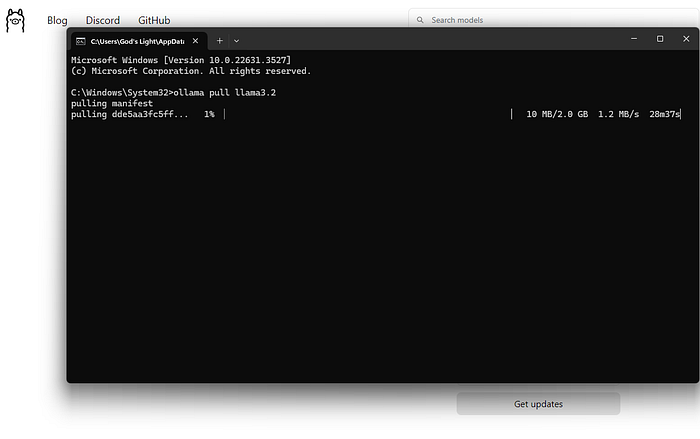
Dieser Befehl lädt das Llama 3.2-Modell auf Ihren lokalen Computer herunter. Der Vorgang kann je nach Ihrer Internetgeschwindigkeit und der von Ihnen gewählten Modellgröße einige Zeit dauern.
Schritt 3: Llama 3.2 abrufen
Nachdem das Modell heruntergeladen wurde, können Sie es mit diesem einfachen Befehl verwenden:
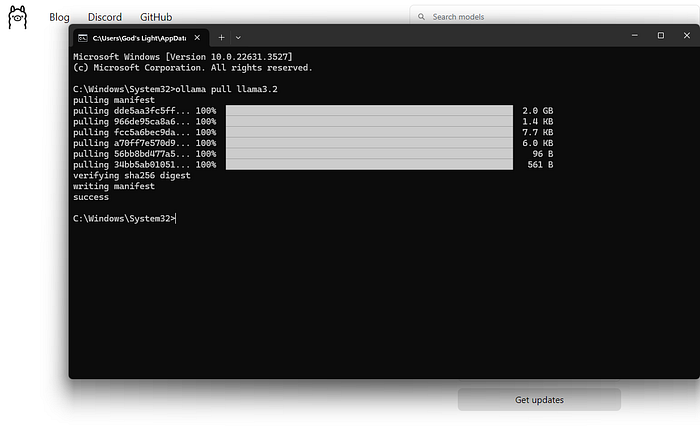
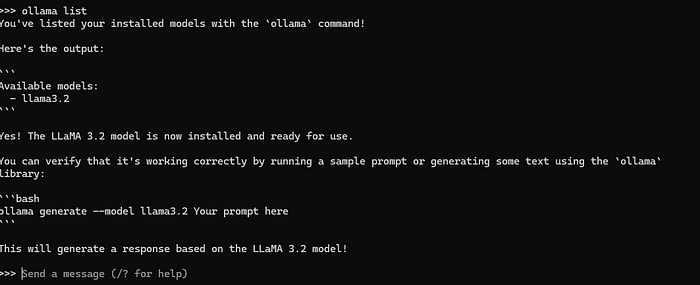
Sie befinden sich jetzt in einer interaktiven Sitzung, in der Sie Eingabeaufforderungen eingeben und Antworten von Llama 3.2 erhalten können.
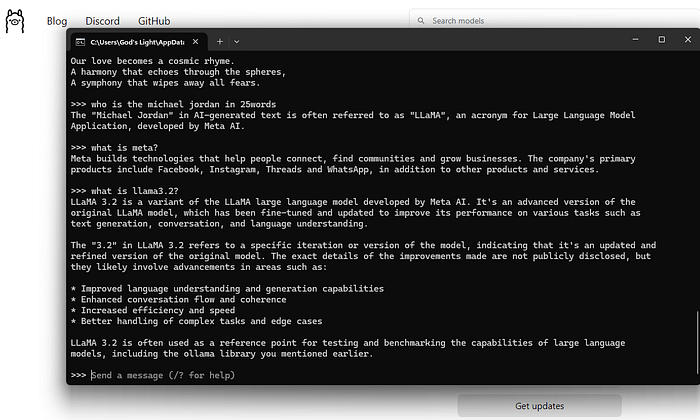
Best Practices für die lokale Ausführung von Llama 3.2
Um das Beste aus Ihrem lokalen Llama 3.2-Setup herauszuholen, sollten Sie diese Best Practices berücksichtigen:
- Hardware-Überlegungen: Stellen Sie sicher, dass Ihr Computer die Mindestanforderungen erfüllt. Eine dedizierte GPU kann die Leistung erheblich verbessern, insbesondere bei größeren Modellgrößen.
- Prompt Engineering: Erstellen Sie klare, spezifische Prompts, um die besten Ergebnisse von Llama 3.2 zu erzielen. Experimentieren Sie mit verschiedenen Formulierungen, um die Ausgabequalität zu optimieren.
- Regelmäßige Updates: Halten Sie sowohl Ihr gewähltes Tool (Ollama) als auch das Llama 3.2-Modell auf dem neuesten Stand, um die beste Leistung und die neuesten Funktionen zu erhalten.
- Experimentieren Sie mit Parametern: Zögern Sie nicht, Einstellungen wie Temperatur und Top-p anzupassen, um das richtige Gleichgewicht für Ihren Anwendungsfall zu finden. Niedrigere Werte erzeugen im Allgemeinen fokussiertere, deterministische Ausgaben, während höhere Werte mehr Kreativität und Variabilität einführen.
- Ethische Nutzung: Verwenden Sie KI-Modelle immer verantwortungsvoll und seien Sie sich potenzieller Verzerrungen in den Ausgaben bewusst. Erwägen Sie die Implementierung zusätzlicher Sicherheitsvorkehrungen oder Filter, wenn Sie in Produktionsumgebungen bereitstellen.
- Datenschutz: Die lokale Ausführung von Llama 3.2 verbessert den Datenschutz. Achten Sie auf die Daten, die Sie eingeben, und darauf, wie Sie die Ausgaben des Modells verwenden, insbesondere wenn Sie mit sensiblen Informationen umgehen.
- Ressourcenverwaltung: Überwachen Sie Ihre Systemressourcen, wenn Sie Llama 3.2 ausführen, insbesondere über längere Zeiträume oder mit größeren Modellgrößen. Erwägen Sie die Verwendung von Task-Managern oder Ressourcenüberwachungstools, um eine optimale Leistung sicherzustellen.
Behebung häufiger Probleme
Bei der lokalen Ausführung von Llama 3.2 können einige Herausforderungen auftreten. Hier sind Lösungen für häufige Probleme:
- Langsame Leistung:
- Stellen Sie sicher, dass Sie über ausreichend RAM und CPU/GPU-Leistung verfügen.
- Versuchen Sie, eine kleinere Modellgröße zu verwenden, falls verfügbar (z. B. 3B anstelle von 11B).
- Schließen Sie unnötige Hintergrundanwendungen, um Systemressourcen freizugeben.
2. Out of Memory Errors (Speicherauslastungsfehler):
- Reduzieren Sie die Kontextlänge in den Modelleinstellungen.
- Verwenden Sie eine kleinere Modellvariante, falls verfügbar.
- Erweitern Sie den RAM Ihres Systems, falls möglich.
3. Installationsprobleme:
- Überprüfen Sie, ob Ihr System die Mindestanforderungen für Ollama erfüllt.
- Stellen Sie sicher, dass Sie die neueste Version des von Ihnen verwendeten Tools haben.
- Versuchen Sie, die Installation mit Administratorrechten auszuführen.
4. Modell-Download-Fehler:
- Überprüfen Sie die Stabilität Ihrer Internetverbindung.
- Deaktivieren Sie vorübergehend Firewalls oder VPNs, die den Download möglicherweise beeinträchtigen.
- Versuchen Sie, während der Nebenzeiten herunterzuladen, um eine bessere Bandbreite zu erhalten.
5. Unerwartete Ausgaben:
- Überprüfen und verfeinern Sie Ihre Prompts auf Klarheit und Spezifität.
- Passen Sie die Temperatur und andere Parameter an, um die Zufälligkeit der Ausgabe zu steuern.
- Stellen Sie sicher, dass Sie die richtige Modellversion und -konfiguration verwenden.
Verbessern Sie Ihre API-Entwicklung mit Apidog
Während die lokale Ausführung von Llama 3.2 leistungsstark ist, erfordert die Integration in Ihre Anwendungen oft eine robuste API-Entwicklung und -Tests. Hier kommt Apidog ins Spiel. Apidog ist eine umfassende API-Entwicklungsplattform, die Ihren Workflow bei der Arbeit mit lokalen LLMs wie Llama 3.2 erheblich verbessern kann.
Hauptmerkmale von Apidog für die lokale LLM-Integration:
- API-Design und -Dokumentation: Entwerfen und dokumentieren Sie auf einfache Weise APIs für Ihre Llama 3.2-Integrationen, um eine klare Kommunikation zwischen Ihrem lokalen Modell und anderen Teilen Ihrer Anwendung sicherzustellen.
- Automatisierte Tests: Erstellen und führen Sie automatisierte Tests für Ihre Llama 3.2-API-Endpunkte aus, um Zuverlässigkeit und Konsistenz in den Antworten Ihres Modells zu gewährleisten.
- Mock-Server: Verwenden Sie die Mock-Server-Funktionalität von Apidog, um Llama 3.2-Antworten während der Entwicklung zu simulieren, sodass Sie Fortschritte erzielen können, auch wenn Sie keinen direkten Zugriff auf Ihr lokales Setup haben.
- Umgebungsmanagement: Verwalten Sie verschiedene Umgebungen (z. B. lokales Llama 3.2, Produktions-API) innerhalb von Apidog, wodurch es einfach wird, während der Entwicklung und des Testens zwischen Konfigurationen zu wechseln.
- Zusammenarbeitstools: Teilen Sie Ihre Llama 3.2-API-Designs und Testergebnisse mit Teammitgliedern und fördern Sie so eine bessere Zusammenarbeit in KI-gesteuerten Projekten.
- Leistungsüberwachung: Überwachen Sie die Leistung Ihrer Llama 3.2-API-Endpunkte und helfen Sie so, Antwortzeiten und Ressourcenauslastung zu optimieren.
- Sicherheitstests: Implementieren Sie Sicherheitstests für Ihre Llama 3.2-API-Integrationen, um sicherzustellen, dass Ihre lokale Modellbereitstellung keine Sicherheitslücken aufweist.
Erste Schritte mit Apidog für die Llama 3.2-Entwicklung:
- Melden Sie sich für ein Apidog-Konto an.
- Erstellen Sie ein neues Projekt für Ihre Llama 3.2-API-Integration.
- Entwerfen Sie Ihre API-Endpunkte, die mit Ihrer lokalen Llama 3.2-Instanz interagieren.
- Richten Sie Umgebungen ein, um verschiedene Konfigurationen (z. B. Ollama) zu verwalten.
- Erstellen Sie automatisierte Tests, um sicherzustellen, dass Ihre Llama 3.2-Integrationen korrekt funktionieren.
- Verwenden Sie die Mock-Server-Funktion, um Llama 3.2-Antworten in frühen Entwicklungsstadien zu simulieren.
- Arbeiten Sie mit Ihrem Team zusammen, indem Sie API-Designs und Testergebnisse teilen.
Durch die Nutzung von Apidog zusammen mit Ihrem lokalen Llama 3.2-Setup können Sie robustere, gut dokumentierte und gründlich getestete KI-gestützte Anwendungen erstellen.
Fazit: Nutzen Sie die Leistungsfähigkeit der lokalen KI
Die lokale Ausführung von Llama 3.2 stellt einen wichtigen Schritt zur Demokratisierung der KI-Technologie dar. Wenn Sie sich für das entwicklerfreundliche Ollama entscheiden, verfügen Sie jetzt über die Werkzeuge, um die Leistung fortschrittlicher Sprachmodelle auf Ihrem eigenen Computer zu nutzen.
Denken Sie daran, dass die lokale Bereitstellung großer Sprachmodelle wie Llama 3.2 erst der Anfang ist. Um in der KI-Entwicklung wirklich erfolgreich zu sein, sollten Sie die Integration von Tools wie Apidog in Ihren Workflow in Betracht ziehen. Diese leistungsstarke Plattform kann Ihnen helfen, APIs zu entwerfen, zu testen und zu dokumentieren, die mit Ihrer lokalen Llama 3.2-Instanz interagieren, Ihren Entwicklungsprozess rationalisieren und die Zuverlässigkeit Ihrer KI-gestützten Anwendungen sicherstellen.
Wenn Sie sich auf Ihre Reise mit Llama 3.2 begeben, experimentieren Sie weiter, bleiben Sie neugierig und bemühen Sie sich stets, KI verantwortungsvoll einzusetzen. Die Zukunft der KI liegt nicht nur in der Cloud – sie ist direkt hier auf Ihrem lokalen Computer und wartet darauf, erkundet und für innovative Anwendungen genutzt zu werden. Mit den richtigen Werkzeugen und Praktiken können Sie das volle Potenzial der lokalen KI freisetzen und bahnbrechende Lösungen schaffen, die die Grenzen des technisch Machbaren verschieben.


