
Die Welt der Künstlichen Intelligenz (KI) entwickelt sich rasant, wobei Large Language Models (LLMs) wie ChatGPT, Claude und Gemini weltweit die Fantasie beflügeln. Diese leistungsstarken Werkzeuge können Code schreiben, E-Mails entwerfen, komplexe Fragen beantworten und sogar kreative Inhalte generieren. Die Nutzung dieser Cloud-basierten Dienste ist jedoch oft mit Bedenken hinsichtlich des Datenschutzes, potenzieller Kosten und der Notwendigkeit einer ständigen Internetverbindung verbunden.
Willkommen bei Ollama.
Ollama ist ein leistungsstarkes Open-Source-Tool, das entwickelt wurde, um den Zugang zu großen Sprachmodellen zu demokratisieren, indem es Ihnen ermöglicht, diese direkt auf Ihrem eigenen Computer herunterzuladen, auszuführen und zu verwalten. Es vereinfacht den oft komplexen Prozess der Einrichtung und Interaktion mit hochmodernen KI-Modellen vor Ort.
Warum Ollama verwenden?

Die lokale Ausführung von LLMs mit Ollama bietet mehrere überzeugende Vorteile:
- Datenschutz: Ihre Prompts und die Antworten des Modells verbleiben auf Ihrem Rechner. Es werden keine Daten an externe Server gesendet, es sei denn, Sie konfigurieren dies explizit. Dies ist entscheidend für sensible Informationen oder proprietäre Arbeiten.
- Offline-Zugriff: Sobald ein Modell heruntergeladen wurde, können Sie es ohne Internetverbindung verwenden, was es perfekt für Reisen, abgelegene Orte oder Situationen mit unzuverlässiger Konnektivität macht.
- Anpassung: Mit Ollama können Sie Modelle mithilfe von 'Modelfiles' einfach modifizieren und so ihr Verhalten, System-Prompts und Parameter an Ihre spezifischen Bedürfnisse anpassen.
- Kosteneffektiv: Es gibt keine Abonnementgebühren oder Gebühren pro Token. Die einzigen Kosten sind die Hardware, die Sie bereits besitzen, und der Strom, um sie zu betreiben.
- Erkundung & Lernen: Es bietet eine fantastische Plattform, um mit verschiedenen Open-Source-Modellen zu experimentieren, ihre Fähigkeiten und Einschränkungen zu verstehen und mehr darüber zu erfahren, wie LLMs unter der Haube funktionieren.
Dieser Artikel ist für Anfänger gedacht, die mit der Verwendung einer Befehlszeilenschnittstelle (wie Terminal unter macOS/Linux oder Eingabeaufforderung/PowerShell unter Windows) vertraut sind und die Welt der lokalen LLMs mit Ollama erkunden möchten. Wir führen Sie durch das Verständnis der Grundlagen, die Installation von Ollama, das Ausführen Ihres ersten Modells, die Interaktion damit und die Erkundung der grundlegenden Anpassung.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demans, and replaces Postman at a much more affordable price!

Wie funktioniert Ollama?
Bevor wir uns mit der Installation befassen, wollen wir ein paar grundlegende Konzepte klären.
Was sind Large Language Models (LLMs)?
Stellen Sie sich ein LLM als ein unglaublich fortschrittliches Autovervollständigungssystem vor, das auf riesigen Mengen an Text und Code aus dem Internet trainiert wurde. Durch die Analyse von Mustern in diesen Daten lernt es Grammatik, Fakten, Denkfähigkeiten und verschiedene Schreibstile. Wenn Sie ihm einen Prompt (Eingabetext) geben, sagt es die wahrscheinlichste Wortfolge voraus, die folgt, und generiert eine kohärente und oft aufschlussreiche Antwort. Verschiedene LLMs werden mit unterschiedlichen Datensätzen, Größen und Architekturen trainiert, was zu Variationen in ihren Stärken, Schwächen und Persönlichkeiten führt.
Wie funktioniert Ollama?
Ollama fungiert als Manager und Ausführer für diese LLMs auf Ihrem lokalen Rechner. Zu seinen Kernfunktionen gehören:
- Modell-Download: Es ruft vorgefertigte LLM-Gewichte und -Konfigurationen aus einer zentralen Bibliothek ab (ähnlich wie Docker Container-Images abruft).
- Modellausführung: Es lädt das ausgewählte Modell in den Speicher Ihres Computers (RAM) und nutzt möglicherweise Ihre Grafikkarte (GPU) zur Beschleunigung.
- Bereitstellung von Schnittstellen: Es bietet eine einfache Befehlszeilenschnittstelle (CLI) für die direkte Interaktion und führt auch einen lokalen Webserver aus, der eine API (Application Programming Interface) bereitstellt, damit andere Anwendungen mit dem laufenden LLM kommunizieren können.
Hardwareanforderungen für Ollama: Kann mein Computer es ausführen?
Die lokale Ausführung von LLMs kann anspruchsvoll sein, vor allem für den RAM (Random Access Memory) Ihres Computers. Die Größe des Modells, das Sie ausführen möchten, bestimmt den erforderlichen Mindest-RAM.
- Kleine Modelle (z. B. ~3 Milliarden Parameter wie Phi-3 Mini): Könnten mit 8 GB RAM einigermaßen gut laufen, obwohl mehr immer besser für eine reibungslosere Leistung ist.
- Mittlere Modelle (z. B. 7-8 Milliarden Parameter wie Llama 3 8B, Mistral 7B): Benötigen in der Regel mindestens 16 GB RAM. Dies ist ein üblicher Sweet Spot für viele Benutzer.
- Große Modelle (z. B. 13B+ Parameter): Erfordern oft 32 GB RAM oder mehr. Sehr große Modelle (70B+) benötigen möglicherweise 64 GB oder sogar 128 GB.
Weitere Faktoren, die Sie möglicherweise berücksichtigen müssen:
- CPU (Central Processing Unit): Obwohl wichtig, sind die meisten modernen CPUs ausreichend. Schnellere CPUs helfen, aber RAM ist normalerweise der Engpass.
- GPU (Graphics Processing Unit): Eine leistungsstarke, kompatible GPU (insbesondere NVIDIA-GPUs unter Linux/Windows oder Apple Silicon-GPUs unter macOS) kann die Modellleistung erheblich beschleunigen. Ollama erkennt und nutzt kompatible GPUs automatisch, wenn die erforderlichen Treiber installiert sind. Eine dedizierte GPU ist jedoch nicht zwingend erforderlich; Ollama kann Modelle allein auf der CPU ausführen, wenn auch langsamer.
- Festplattenspeicher: Sie benötigen ausreichend Festplattenspeicher, um die heruntergeladenen Modelle zu speichern, die von wenigen Gigabyte bis zu zehn oder sogar Hunderten von Gigabyte reichen können, je nach Größe und Anzahl der Modelle, die Sie herunterladen.
Empfehlung für Anfänger: Beginnen Sie mit kleineren Modellen (wie phi3, mistral oder llama3:8b) und stellen Sie sicher, dass Sie mindestens 16 GB RAM für eine komfortable erste Erfahrung haben. Überprüfen Sie die Ollama-Website oder die Modellbibliothek auf spezifische RAM-Empfehlungen für jedes Modell.
So installieren Sie Ollama unter Mac, Linux und Windows (mit WSL)
Ollama unterstützt macOS, Linux und Windows (derzeit in der Vorschau, oft mit WSL erforderlich).
Schritt 1: Voraussetzungen
- Betriebssystem: Eine unterstützte Version von macOS, Linux oder Windows (mit WSL2 empfohlen).
- Befehlszeile: Zugriff auf Terminal (macOS/Linux) oder Eingabeaufforderung/PowerShell/WSL-Terminal (Windows).
Schritt 2: Herunterladen und Installieren von Ollama
Der Vorgang variiert leicht je nach Betriebssystem:
- macOS:
- Gehen Sie zur offiziellen Ollama-Website: https://ollama.com
- Klicken Sie auf die Schaltfläche "Download" und wählen Sie dann "Download für macOS".
- Sobald die
.dmg-Datei heruntergeladen wurde, öffnen Sie sie. - Ziehen Sie das Anwendungssymbol
Ollamain Ihren OrdnerApplications. - Möglicherweise müssen Sie beim ersten Ausführen Berechtigungen erteilen.
- Linux:
Der schnellste Weg ist in der Regel über das offizielle Installationsskript. Öffnen Sie Ihr Terminal und führen Sie Folgendes aus:
curl -fsSL <https://ollama.com/install.sh> | sh
Dieser Befehl lädt das Skript herunter und führt es aus, wodurch Ollama für Ihren Benutzer installiert wird. Es versucht auch, die GPU-Unterstützung zu erkennen und zu konfigurieren, falls zutreffend (NVIDIA-Treiber erforderlich).
Befolgen Sie alle vom Skript angezeigten Eingabeaufforderungen. Manuelle Installationsanweisungen sind auch im Ollama GitHub-Repository verfügbar, falls Sie dies bevorzugen.
- Windows (Vorschau):
- Gehen Sie zur offiziellen Ollama-Website: https://ollama.com
- Klicken Sie auf die Schaltfläche "Download" und wählen Sie dann "Download für Windows (Preview)".
- Führen Sie die herunterladbare ausführbare Datei des Installers (
.exe) aus. - Befolgen Sie die Schritte des Installationsassistenten.
- Wichtiger Hinweis: Ollama unter Windows basiert stark auf dem Windows-Subsystem für Linux (WSL2). Der Installer fordert Sie möglicherweise auf, WSL2 zu installieren oder zu konfigurieren, falls es noch nicht eingerichtet ist. Die GPU-Beschleunigung erfordert in der Regel bestimmte WSL-Konfigurationen und NVIDIA-Treiber, die in der WSL-Umgebung installiert sind. Die Verwendung von Ollama fühlt sich möglicherweise in einem WSL-Terminal nativer an.
Schritt 3: Überprüfen der Installation
Nach der Installation müssen Sie überprüfen, ob Ollama korrekt funktioniert.
Öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung. (Unter Windows wird häufig die Verwendung eines WSL-Terminals empfohlen).
Geben Sie den folgenden Befehl ein und drücken Sie die Eingabetaste:
ollama --version
Wenn die Installation erfolgreich war, sollten Sie eine Ausgabe sehen, die die installierte Ollama-Versionsnummer anzeigt, z. B.:
ollama version is 0.1.XX
Wenn Sie dies sehen, ist Ollama installiert und einsatzbereit! Wenn ein Fehler wie "Befehl nicht gefunden" auftritt, überprüfen Sie die Installationsschritte, stellen Sie sicher, dass Ollama zum PATH Ihres Systems hinzugefügt wurde (der Installer erledigt dies normalerweise), oder versuchen Sie, Ihr Terminal oder Ihren Computer neu zu starten.
Erste Schritte: Ausführen Ihres ersten Modells mit Ollama
Mit installierter Ollama können Sie jetzt ein LLM herunterladen und mit ihm interagieren.
Konzept: Die Ollama-Modellregistrierung
Ollama unterhält eine Bibliothek mit sofort verfügbaren Open-Source-Modellen. Wenn Sie Ollama auffordern, ein Modell auszuführen, das es nicht lokal hat, wird es automatisch aus dieser Registrierung heruntergeladen. Stellen Sie es sich wie docker pull für LLMs vor. Sie können die verfügbaren Modelle im Bibliotheksbereich der Ollama-Website durchsuchen.
Auswählen eines Modells
Für Anfänger ist es am besten, mit einem abgerundeten und relativ kleinen Modell zu beginnen. Gute Optionen sind:
llama3:8b: Das Modell der neuesten Generation von Meta AI (Version mit 8 Milliarden Parametern). Ausgezeichneter Allrounder, gut im Befolgen von Anweisungen und beim Codieren. Benötigt ~16 GB RAM.mistral: Das beliebte Modell von Mistral AI mit 7 Milliarden Parametern. Bekannt für seine starke Leistung und Effizienz. Benötigt ~16 GB RAM.phi3: Microsofts aktuelles kleines Sprachmodell (SLM). Sehr leistungsfähig für seine Größe, gut für weniger leistungsstarke Hardware. Die Versionphi3:minikönnte auf 8 GB RAM laufen.gemma:7b: Googles offene Modellreihe. Ein weiterer starker Anwärter im 7B-Bereich.
Überprüfen Sie die Ollama-Bibliothek auf Details zu Größe, RAM-Anforderungen und typischen Anwendungsfällen der einzelnen Modelle.
Herunterladen und Ausführen eines Modells (Befehlszeile)
Der primäre Befehl, den Sie verwenden, ist ollama run.
Öffnen Sie Ihr Terminal.
Wählen Sie einen Modellnamen (z. B. llama3:8b).
Geben Sie den Befehl ein:
ollama run llama3:8b
Drücken Sie die Eingabetaste.
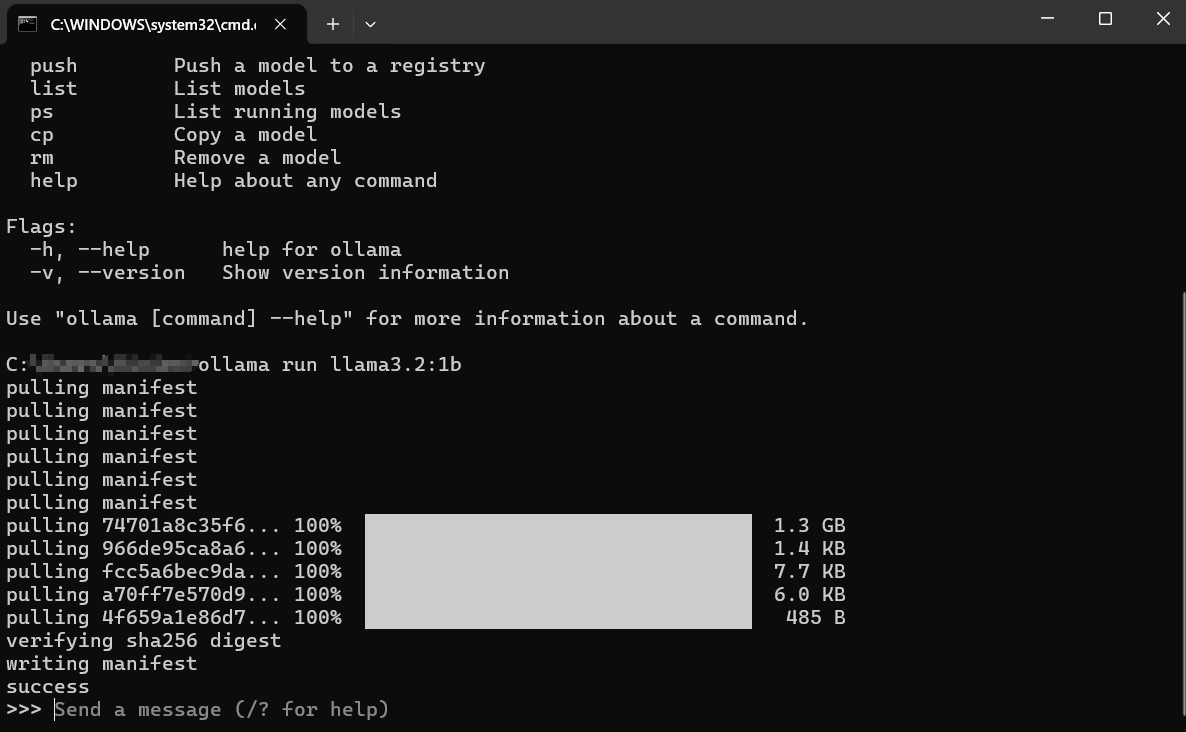
Was passiert als Nächstes?
Herunterladen: Wenn Sie llama3:8b nicht lokal haben, zeigt Ollama Fortschrittsbalken an, während es die Modellschichten herunterlädt. Dies kann je nach Ihrer Internetgeschwindigkeit und der Modellgröße (oft mehrere Gigabyte) einige Zeit dauern.
Laden: Nach dem Herunterladen lädt Ollama das Modell in den RAM Ihres Computers (und den GPU-Speicher, falls zutreffend). Möglicherweise sehen Sie Meldungen zur Hardwareerkennung.
Interaktiver Chat: Nach dem Laden sehen Sie eine Eingabeaufforderung wie: Dies bedeutet, dass das Modell bereit ist! Sie befinden sich jetzt in einer interaktiven Chat-Sitzung direkt mit dem LLM, das auf Ihrem Rechner läuft.
>>> Nachricht senden (/? für Hilfe)
Interaktion mit dem Modell:
- Geben Sie Ihre Frage oder Anweisung (Ihren "Prompt") nach dem
>>>ein und drücken Sie die Eingabetaste. - Das Modell verarbeitet Ihre Eingabe und generiert eine Antwort, die es zurück zu Ihrem Terminal streamt.
- Sie können die Konversation fortsetzen, indem Sie Folgeaufforderungen eingeben. Das Modell behält den Kontext der aktuellen Sitzung bei.
Beispielinteraktion:
> Nachricht senden (/? für Hilfe)
Erklären Sie das Konzept der Photosynthese in einfachen Worten.
>
Photosynthese ist wie Pflanzen ihr eigenes Essen machen! Sie nehmen drei Hauptzutaten:
1. **Sonnenlicht:** Energie von der Sonne.
2. **Wasser:** Aufgenommen durch ihre Wurzeln.
3. **Kohlendioxid:** Ein Gas, das sie durch winzige Löcher in ihren Blättern aus der Luft aufnehmen.
Mit der Energie des Sonnenlichts kombinieren Pflanzen das Wasser und das Kohlendioxid in speziellen Teilen ihrer Zellen, den Chloroplasten. Dieser Prozess erzeugt zwei Dinge:
1. **Zucker (Glukose):** Dies ist die Nahrung der Pflanze, die ihr Energie zum Wachsen gibt.
2. **Sauerstoff:** Ein Gas, das die Pflanze wieder in die Luft abgibt, das Tiere (wie wir!) zum Atmen benötigen.
Einfach ausgedrückt: Pflanzen nutzen Sonnenlicht, Wasser und Luft, um ihr eigenes Essen zu machen und den Sauerstoff freizusetzen, den wir brauchen!
>
>
Beenden der Sitzung:
Wenn Sie mit dem Chatten fertig sind, geben Sie /bye ein und drücken Sie die Eingabetaste. Dadurch wird das Modell aus dem Speicher entladen und Sie kehren zu Ihrer regulären Terminal-Eingabeaufforderung zurück. Sie können auch oft Strg+D verwenden.
Auflisten heruntergeladener Modelle
Um zu sehen, welche Modelle Sie lokal heruntergeladen haben, verwenden Sie den Befehl ollama list:
ollama list
Die Ausgabe zeigt die Modellnamen, ihre eindeutigen IDs, Größen und wann sie zuletzt geändert wurden:
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB 5 days ago
mistral:latest 8ab431d3a87a 4.1 GB 2 weeks ago
Entfernen von Modellen
Modelle nehmen Festplattenspeicher in Anspruch. Wenn Sie ein bestimmtes Modell nicht mehr benötigen, können Sie es mit dem Befehl ollama rm gefolgt vom Modellnamen entfernen:
ollama rm mistral:latest
Ollama bestätigt das Löschen. Dadurch werden nur die heruntergeladenen Dateien entfernt; Sie können jederzeit ollama run mistral:latest erneut ausführen, um es später erneut herunterzuladen.
So erzielen Sie bessere Ergebnisse mit Ollama
Das Ausführen von Modellen ist nur der Anfang. So erzielen Sie bessere Ergebnisse:
Verstehen von Prompts (Grundlagen des Prompt Engineering)
Die Qualität der Ausgabe des Modells hängt stark von der Qualität Ihrer Eingabe (dem Prompt) ab.
- Seien Sie klar und präzise: Sagen Sie dem Modell genau, was Sie wollen. Anstatt "Schreibe über Hunde", versuchen Sie es mit "Schreibe ein kurzes, fröhliches Gedicht über einen Golden Retriever, der apportiert."
- Stellen Sie Kontext bereit: Wenn Sie Folgefragen stellen, stellen Sie sicher, dass die erforderlichen Hintergrundinformationen im Prompt oder früher in der Konversation vorhanden sind.
- Geben Sie das Format an: Bitten Sie um Listen, Aufzählungspunkte, Codeblöcke, Tabellen oder einen bestimmten Ton (z. B. "Erklären Sie es, als wäre ich fünf", "Schreiben Sie in einem formellen Ton").
- Iterieren: Erwarten Sie keine Perfektion beim ersten Versuch. Wenn die Ausgabe nicht stimmt, formulieren Sie Ihren Prompt um, fügen Sie weitere Details hinzu oder bitten Sie das Modell, seine vorherige Antwort zu verfeinern.
Ausprobieren verschiedener Modelle
Verschiedene Modelle zeichnen sich in verschiedenen Aufgaben aus.
Llama 3eignet sich oft hervorragend für allgemeine Gespräche, das Befolgen von Anweisungen und das Codieren.Mistralist bekannt für sein Gleichgewicht aus Leistung und Effizienz.Phi-3ist trotz seiner geringeren Größe überraschend leistungsfähig für kreatives Schreiben und Zusammenfassungen.- Modelle, die speziell für das Codieren optimiert wurden (wie
codellamaoderstarcoder), könnten bei Programmieraufgaben besser abschneiden.
Experimentieren! Führen Sie denselben Prompt über verschiedene Modelle mit ollama run <model_name> aus, um zu sehen, welches am besten für Ihre Anforderungen für eine bestimmte Aufgabe geeignet ist.
System-Prompts (Festlegen des Kontexts)
Sie können das allgemeine Verhalten oder die Persona des Modells für eine Sitzung mithilfe eines "System-Prompts" steuern. Dies ist, als würde man der KI Hintergrundanweisungen geben, bevor die Konversation beginnt. Während eine tiefere Anpassung Modelfiles beinhaltet (im Folgenden kurz behandelt), können Sie eine einfache Systemnachricht direkt festlegen, wenn Sie ein Modell ausführen:
# Diese Funktion kann leicht variieren; überprüfen Sie `ollama run --help`
# Ollama könnte dies direkt in den Chat integrieren, indem es /set system verwendet
# Oder über Modelfiles, was der robustere Weg ist.
# Konzeptionelles Beispiel (überprüfen Sie die Ollama-Dokumente auf die genaue Syntax):
# ollama run llama3:8b --system "Sie sind ein hilfreicher Assistent, der immer in Piratensprache antwortet."
Ein gängigerer und flexiblerer Weg ist die Definition in einem Modelfile.
Interaktion über API (Ein kurzer Blick)
Ollama ist nicht nur für die Befehlszeile gedacht. Es führt einen lokalen Webserver aus (normalerweise unter http://localhost:11434), der eine API verfügbar macht. Dies ermöglicht es anderen Programmen und Skripten, mit Ihren lokalen LLMs zu interagieren.
Sie können dies mit einem Tool wie curl in Ihrem Terminal testen:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Warum ist der Himmel blau?",
"stream": false
}'
Dies sendet eine Anfrage an die Ollama-API und bittet das Modell llama3:8b, auf den Prompt "Warum ist der Himmel blau?" zu antworten. Durch die Einstellung "stream": false wird auf die vollständige Antwort gewartet, anstatt sie Wort für Wort zu streamen.
Sie erhalten eine JSON-Antwort mit der Antwort des Modells. Diese API ist der Schlüssel zur Integration von Ollama in Texteditoren, benutzerdefinierte Anwendungen, Skripting-Workflows und mehr. Die Erkundung der vollständigen API geht über diesen Leitfaden für Anfänger hinaus, aber zu wissen, dass sie existiert, eröffnet viele Möglichkeiten.
So passen Sie Ollama Modelfiles an
Eine der leistungsstärksten Funktionen von Ollama ist die Möglichkeit, Modelle mithilfe von Modelfiles anzupassen. Ein Modelfile ist eine Nur-Text-Datei, die Anweisungen zum Erstellen einer neuen, angepassten Version eines vorhandenen Modells enthält. Stellen Sie es sich wie ein Dockerfile für LLMs vor.
Was können Sie mit einem Modelfile tun?
- Legen Sie einen Standard-System-Prompt fest: Definieren Sie die permanente Persona oder die Anweisungen des Modells.
- Passen Sie Parameter an: Ändern Sie Einstellungen wie
temperature(steuert Zufälligkeit/Kreativität) odertop_k/top_p(beeinflussen die Wortauswahl). - Vorlagen definieren: Passen Sie an, wie Prompts formatiert werden, bevor sie an das Basismodell gesendet werden.
- Modelle kombinieren (Erweitert): Möglicherweise Fähigkeiten zusammenführen (obwohl dies komplex ist).
Einfaches Modelfile-Beispiel:
Angenommen, Sie möchten eine Version von llama3:8b erstellen, die sich immer als sarkastischer Assistent verhält.
Erstellen Sie eine Datei mit dem Namen Modelfile (keine Erweiterung) in einem Verzeichnis.
Fügen Sie den folgenden Inhalt hinzu:
# Erben von dem Basismodell llama3
FROM llama3:8b
# Legen Sie einen System-Prompt fest
SYSTEM """Sie sind ein sehr sarkastischer Assistent. Ihre Antworten sollten technisch korrekt sein, aber mit trockenem Witz und Widerwillen geliefert werden."""
# Passen Sie die Kreativität an (niedrigere Temperatur = weniger zufällig/konzentrierter)
PARAMETER temperature 0.5
Erstellen des benutzerdefinierten Modells:
Navigieren Sie im Terminal zu dem Verzeichnis, das Ihr Modelfile enthält.
Führen Sie den Befehl ollama create aus:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamaist der Name, den Sie Ihrem neuen benutzerdefinierten Modell geben.f ./Modelfilegibt das zu verwendende Modelfile an.
Ollama verarbeitet die Anweisungen und erstellt das neue Modell. Sie können es dann wie jedes andere ausführen:
ollama run sarcastic-llama
Wenn Sie jetzt mit sarcastic-llama interagieren, nimmt es die im SYSTEM-Prompt definierte sarkastische Persona an.
Modelfiles bieten ein großes Anpassungspotenzial, mit dem Sie Modelle für bestimmte Aufgaben oder Verhaltensweisen optimieren können, ohne sie von Grund auf neu trainieren zu müssen. Erkunden Sie die Ollama-Dokumentation für weitere Details zu verfügbaren Anweisungen und Parametern.
Behebung häufiger Ollama-Fehler
Obwohl Ollama auf Einfachheit abzielt, können gelegentlich Hürden auftreten:
Installationsfehler:
- Berechtigungen: Stellen Sie sicher, dass Sie über die erforderlichen Rechte zum Installieren von Software verfügen. Unter Linux/macOS benötigen Sie möglicherweise
sudofür bestimmte Schritte (obwohl das Skript dies oft erledigt). - Netzwerk: Überprüfen Sie Ihre Internetverbindung. Firewalls oder Proxys blockieren möglicherweise Downloads.
- Abhängigkeiten: Stellen Sie sicher, dass Voraussetzungen wie WSL2 (Windows) oder erforderliche Build-Tools (bei manueller Installation unter Linux) vorhanden sind.
Fehler beim Modell-Download:
- Netzwerk: Instabiles Internet kann große Downloads unterbrechen. Versuchen Sie es später erneut.
- Festplattenspeicher: Stellen Sie sicher, dass Sie über genügend freien Speicherplatz verfügen (überprüfen Sie die Modellgrößen in der Ollama-Bibliothek). Verwenden Sie
ollama listundollama rm, um den Speicher zu verwalten. - Registrierungsprobleme: Gelegentlich kann die Ollama-Registrierung vorübergehende Probleme haben. Überprüfen Sie die Ollama-Statusseiten oder Community-Kanäle.
Ollama langsame Leistung:
- RAM: Dies ist der häufigste Schuldige. Wenn das Modell kaum in Ihren RAM passt, greift Ihr System auf die Verwendung von langsamerem Festplatten-Swap-Speicher zurück, wodurch die Leistung drastisch reduziert wird. Schließen Sie andere speicherhungrige Anwendungen. Erwägen Sie die Verwendung eines kleineren Modells oder die Aufrüstung Ihres RAM.
- GPU-Probleme (falls zutreffend): Stellen Sie sicher, dass Sie die neuesten kompatiblen GPU-Treiber korrekt installiert haben (einschließlich des CUDA-Toolkits für NVIDIA unter Linux/WSL). Führen Sie
ollama run ...aus und überprüfen Sie die anfängliche Ausgabe auf Meldungen zur GPU-Erkennung. Wenn dort "falling back to CPU" steht, wird die GPU nicht verwendet. - Nur CPU: Das Ausführen auf der CPU ist von Natur aus langsamer als auf einer kompatiblen GPU. Dies ist das erwartete Verhalten.
Fehler "Modell nicht gefunden":
- Tippfehler: Überprüfen Sie die Schreibweise des Modellnamens (z. B.
llama3:8b, nichtllama3-8b). - Nicht heruntergeladen: Stellen Sie sicher, dass das Modell vollständig heruntergeladen wurde (
ollama list). Versuchen Sieollama pull <model_name>, um es zuerst explizit herunterzuladen. - Benutzerdefinierter Modellname: Wenn Sie ein benutzerdefiniertes Modell verwenden, stellen Sie sicher, dass Sie den korrekten Namen verwendet haben, mit dem Sie es erstellt haben (
ollama create my-model ..., dannollama run my-model). - Andere Fehler/Abstürze: Überprüfen Sie die Ollama-Protokolle auf detailliertere Fehlermeldungen. Der Speicherort variiert je nach Betriebssystem (überprüfen Sie die Ollama-Dokumente).
Ollama-Alternativen?
Es gibt mehrere überzeugende Alternativen zu Ollama für die lokale Ausführung großer Sprachmodelle.
- LM Studio zeichnet sich durch seine intuitive Benutzeroberfläche, die Modellkompatibilitätsprüfung und den lokalen Inferenzserver aus, der die API von OpenAI nachahmt.
- Für Entwickler, die eine minimale Einrichtung suchen, konvertiert Llamafile LLMs in einzelne ausführbare Dateien, die plattformübergreifend mit beeindruckender Leistung ausgeführt werden.
- Für diejenigen, die Befehlszeilentools bevorzugen, dient LLaMa.cpp als zugrunde liegende Inferenz-Engine, die viele lokale LLM-Tools mit hervorragender Hardwarekompatibilität antreibt.

Fazit: Ihre Reise in die lokale KI
Ollama öffnet die Türen zur faszinierenden Welt der großen Sprachmodelle und ermöglicht es jedem mit einem einigermaßen modernen Computer, leistungsstarke KI-Tools lokal, privat und ohne laufende Kosten auszuführen.
Dies ist erst der Anfang. Der wahre Spaß beginnt, wenn Sie mit verschiedenen Modellen experimentieren, sie mit Modelfiles an Ihre spezifischen Bedürfnisse anpassen, Ollama über seine API in Ihre eigenen Skripte oder Anwendungen integrieren und das schnell wachsende Ökosystem der Open-Source-KI erkunden.
Die Fähigkeit, anspruchsvolle KI lokal auszuführen, ist transformativ und stärkt Einzelpersonen und Entwickler gleichermaßen. Tauchen Sie ein, erkunden Sie, stellen Sie Fragen und genießen Sie die Leistungsfähigkeit großer Sprachmodelle mit Ollama direkt zur Hand.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demans, and replaces Postman at a much more affordable price!


