
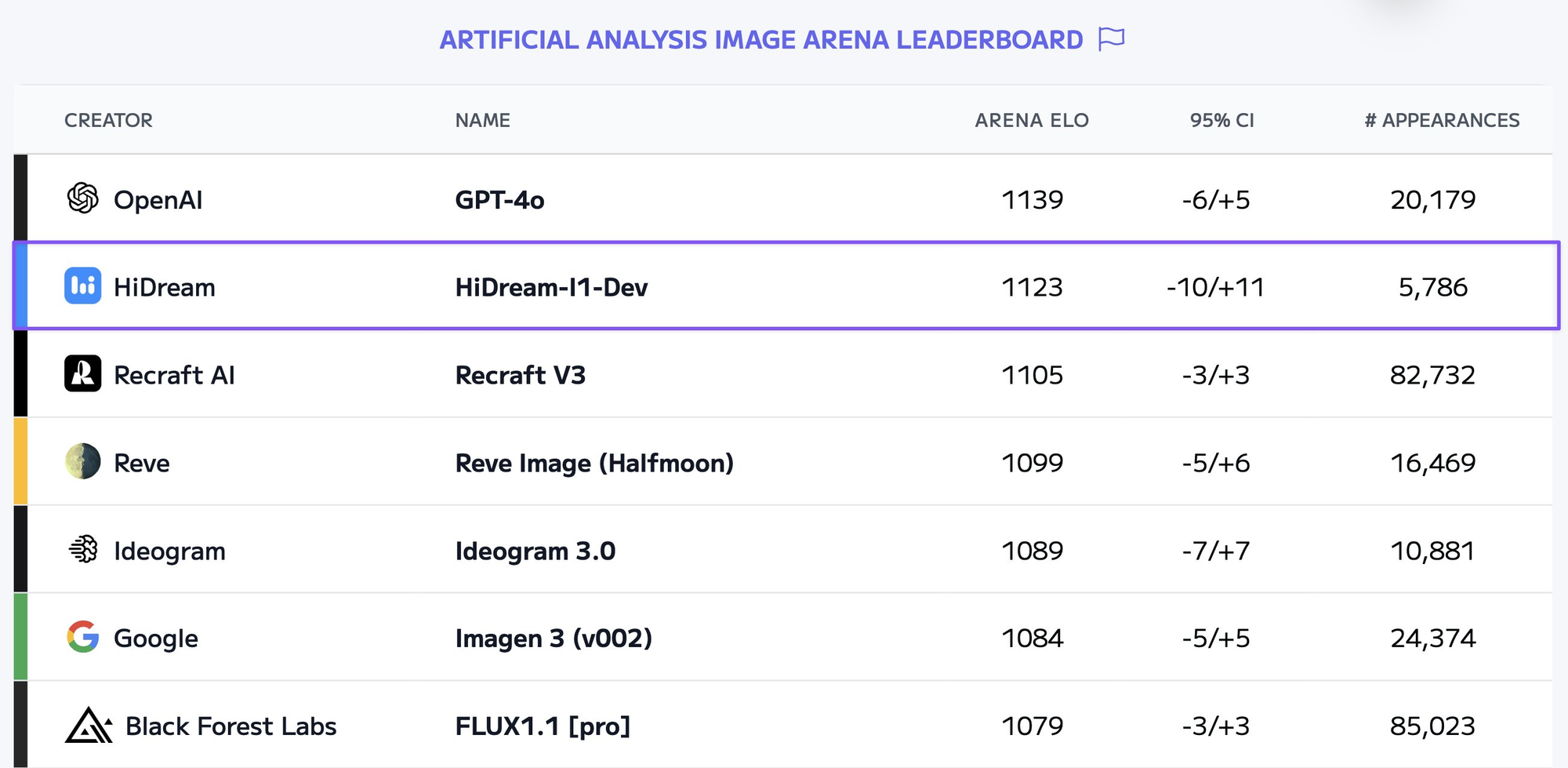
Es scheint, als ob wir jede Woche neue KI-Bildgenerierungsmodelle bekommen, die in der Lage sind, atemberaubende Visualisierungen zu erstellen. Ein solches leistungsstarkes Modell ist HiDream-I1-Full. Während das lokale Ausführen dieser Modelle ressourcenintensiv sein kann, bietet die Nutzung von APIs eine bequeme und skalierbare Möglichkeit, diese Technologie in Ihre Anwendungen oder Workflows zu integrieren.
Dieses Tutorial führt Sie durch:
- Verständnis von HiDream-I1-Full: Was es ist und welche Fähigkeiten es hat.
- API-Optionen: Erkundung von zwei beliebten Plattformen, die HiDream-I1-Full über API anbieten: Replicate und Fal.ai.
- Testen mit Apidog: Eine Schritt-für-Schritt-Anleitung, wie Sie mit diesen APIs mithilfe des Apidog-Tools interagieren und sie testen können.
Möchten Sie eine integrierte All-in-One-Plattform für Ihr Entwicklerteam, um mit maximaler Produktivität zusammenzuarbeiten?
Apidog liefert alle Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!
Zielgruppe: Entwickler, Designer, KI-Enthusiasten und alle, die daran interessiert sind, fortschrittliche KI-Bildgenerierung ohne komplexe lokale Setups zu nutzen.
Voraussetzungen:
- Grundlegendes Verständnis von APIs (HTTP-Anfragen, JSON).
- Ein Konto auf Replicate und/oder Fal.ai, um API-Schlüssel zu erhalten.
- Apidog installiert (oder Zugriff auf die Webversion).
Was ist HiDream-I1-Full?

HiDream-I1-Full ist ein fortschrittliches Text-zu-Bild-Diffusionsmodell, das von HiDream AI entwickelt wurde. Es gehört zur Familie der Modelle, die entwickelt wurden, um hochwertige, kohärente und ästhetisch ansprechende Bilder basierend auf Textbeschreibungen (Prompts) zu generieren.

Model Details: You can find the official model card and more technical information on Hugging Face: https://huggingface.co/HiDream-ai/HiDream-I1-Full
Key Capabilities (Typical for models of this class):
- Text-to-Image Generation: Erstellt Bilder aus detaillierten Text-Prompts.
- High Resolution: Kann Bilder in relativ hohen Auflösungen generieren, die für verschiedene Anwendungen geeignet sind.
- Style Adherence: Kann oft stilistische Hinweise innerhalb des Prompts interpretieren (z. B. "im Stil von Van Gogh", "fotorealistisch", "Anime").
- Complex Scene Composition: Fähigkeit, Bilder mit mehreren Objekten, Interaktionen und detaillierten Hintergründen basierend auf der Komplexität des Prompts zu generieren.
- Control Parameters: Ermöglicht oft Feinabstimmung durch Parameter wie negative Prompts (Dinge, die vermieden werden sollen), Seeds (für Reproduzierbarkeit), Guidance Scale (wie stark dem Prompt gefolgt werden soll) und potenziell Image-to-Image-Variationen oder Steuerungseingaben (abhängig von der spezifischen API-Implementierung).
Warum eine API verwenden?
Das lokale Ausführen großer KI-Modelle wie HiDream-I1-Full erfordert erhebliche Rechenressourcen (leistungsstarke GPUs, ausreichend RAM und Speicher) und technisches Setup (Verwaltung von Abhängigkeiten, Modellgewichten, Umgebungskonfigurationen). Die Verwendung einer API bietet mehrere Vorteile:
- Keine Hardwareanforderungen: Verlagerung der Berechnung auf eine leistungsstarke Cloud-Infrastruktur.
- Skalierbarkeit: Einfache Handhabung unterschiedlicher Lasten ohne Verwaltung der Infrastruktur.
- Einfache Integration: Integrieren Sie Bildgenerierungsfunktionen in Websites, Apps oder Skripte mithilfe von Standard-HTTP-Anfragen.
- Wartungsfrei: Der API-Anbieter kümmert sich um Modellaktualisierungen, Wartung und Backend-Management.
- Pay-as-you-go: Oft zahlen Sie nur für die von Ihnen genutzte Rechenzeit.
Wie man HiDream-I1-Full über API verwendet
Mehrere Plattformen hosten KI-Modelle und bieten API-Zugriff. Wir konzentrieren uns auf zwei beliebte Optionen für HiDream-I1-Full:
Option 1: Verwenden Sie die HiDream-API von Replicate
Replicate ist eine Plattform, die es einfach macht, Machine-Learning-Modelle über eine einfache API auszuführen, ohne die Infrastruktur verwalten zu müssen. Sie hosten eine riesige Bibliothek von von der Community veröffentlichten Modellen.
- Replicate Page for HiDream-I1-Full: https://replicate.com/prunaai/hidream-l1-full (Hinweis: Die URL erwähnt
l1-full, aber es ist der relevante Link, der im Prompt für das HiDream-Modell auf Replicate bereitgestellt wird. Gehen Sie davon aus, dass er dem für dieses Tutorial vorgesehenen Modell entspricht).
Wie Replicate funktioniert:
- Authentifizierung: Sie benötigen ein Replicate-API-Token, das Sie in Ihren Kontoeinstellungen finden können. Dieses Token wird im
Authorization-Header übergeben. - Starten einer Vorhersage: Sie senden eine POST-Anfrage an den Replicate-API-Endpunkt für Vorhersagen. Der Anfragetext enthält die Modellversion und die Eingabeparameter (wie
prompt,negative_prompt,seedusw.). - Asynchroner Betrieb: Replicate arbeitet typischerweise asynchron. Die erste POST-Anfrage gibt sofort eine Vorhersage-ID und URLs zurück, um den Status zu überprüfen.
- Erhalten von Ergebnissen: Sie müssen die Status-URL (in der ersten Antwort bereitgestellt) mithilfe von GET-Anfragen abfragen, bis der Status
succeeded(oderfailed) ist. Die endgültige erfolgreiche Antwort enthält die URL(s) der generierten Bilder.
Konzeptionelles Python-Beispiel (mit requests):
import requests
import time
import os
REPLICATE_API_TOKEN = "YOUR_REPLICATE_API_TOKEN" # Verwenden Sie Umgebungsvariablen in der Produktion
MODEL_VERSION = "TARGET_MODEL_VERSION_FROM_REPLICATE_PAGE" # z. B. "9a0b4534..."
# 1. Start Prediction
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "Eine majestätische Cyberpunk-Stadtlandschaft bei Sonnenuntergang, Neonlichter, die sich auf nassen Straßen spiegeln, detaillierte Illustration",
"negative_prompt": "hässlich, deformiert, verschwommen, geringe Qualität, Text, Wasserzeichen",
"width": 1024,
"height": 1024,
"seed": 12345
# Fügen Sie andere Parameter nach Bedarf basierend auf der Replicate-Modellseite hinzu
}
}
start_response = requests.post("<https://api.replicate.com/v1/predictions>", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"Fehler beim Starten der Vorhersage: {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"Vorhersage gestartet mit ID: {prediction_id}")
print(f"Status-URL: {status_url}")
# 2. Ergebnisse abfragen
output_image_url = None
while True:
print("Status wird überprüft...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # Normalerweise eine Liste von URLs
print("Vorhersage erfolgreich!")
print(f"Ausgabe: {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"Vorhersage fehlgeschlagen oder abgebrochen: {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# Warten, bevor erneut abgefragt wird
time.sleep(5) # Passen Sie das Abfrageintervall nach Bedarf an
else:
print(f"Unbekannter Status: {status}")
print(status_response_json)
break
# Jetzt können Sie die output_image_url verwenden
Preisgestaltung: Replicate berechnet basierend auf der Ausführungszeit des Modells auf ihrer Hardware. Überprüfen Sie die Preisübersicht für Details.
Option 2: Fal.ai
Fal.ai ist eine weitere Plattform, die sich auf die Bereitstellung schneller, skalierbarer und kostengünstiger Inferenz für KI-Modelle über APIs konzentriert. Sie betonen oft die Echtzeitleistung.
Wie Fal.ai funktioniert:
- Authentifizierung: Sie benötigen Fal-API-Anmeldeinformationen (Key ID und Key Secret, oft kombiniert als
KeyID:KeySecret). Diese werden imAuthorization-Header übergeben, typischerweise alsKey YourKeyID:YourKeySecret. - API-Endpunkt: Fal.ai stellt eine direkte Endpunkt-URL für die spezifische Modellfunktion bereit.
- Anfrageformat: Sie senden eine POST-Anfrage an die Endpunkt-URL des Modells. Der Anfragetext ist typischerweise JSON, der die vom Modell benötigten Eingabeparameter enthält (ähnlich wie bei Replicate:
promptusw.). - Synchron vs. Asynchron: Fal.ai kann beides anbieten. Für potenziell lange Aufgaben wie die Bilderzeugung könnten sie Folgendes verwenden:
- Serverless Functions: Ein Standard-Anfrage/Antwort-Zyklus, möglicherweise mit längeren Timeouts.
- Queues: Ein asynchrones Muster ähnlich wie Replicate, bei dem Sie einen Job einreichen und die Ergebnisse mithilfe einer Anforderungs-ID abfragen. Die verknüpfte spezifische API-Seite beschreibt das erwartete Interaktionsmuster im Detail.
Konzeptionelles Python-Beispiel (mit requests - unter der Annahme einer asynchronen Warteschlange):
import requests
import time
import os
FAL_API_KEY = "YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET" # Verwenden Sie Umgebungsvariablen
MODEL_ENDPOINT_URL = "<https://fal.run/fal-ai/hidream-i1-full>" # Überprüfen Sie die genaue URL auf Fal.ai
# 1. Anfrage an die Warteschlange senden (Beispiel - überprüfen Sie die Fal-Dokumente auf die genaue Struktur)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# Parameter befinden sich oft direkt im Payload für Fal.ai Serverless Functions
# oder innerhalb eines 'input'-Objekts, abhängig vom Setup. Überprüfen Sie die Dokumente!
"prompt": "Ein hyperrealistisches Porträt eines Astronauten, der im Weltraum schwebt, die Erde spiegelt sich im Helmvisier",
"negative_prompt": "Cartoon, Zeichnung, Illustration, Skizze, Text, Buchstaben",
"seed": 98765
# Fügen Sie andere Parameter hinzu, die von der Fal.ai-Implementierung unterstützt werden
}
# Fal.ai erfordert möglicherweise das Hinzufügen von '/queue' oder spezifischen Abfrageparametern für Async
# Beispiel: POST <https://fal.run/fal-ai/hidream-i1-full/queue>
# Überprüfen Sie deren Dokumentation! Unter der Annahme eines Endpunkts, der eine Status-URL zurückgibt:
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "OPTIONAL_WEBHOOK_URL"}) # Überprüfen Sie die Dokumente auf Abfrageparameter wie Webhook
if submit_response.status_code >= 300:
print(f"Fehler beim Senden der Anfrage: {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# Die asynchrone Antwort von Fal.ai kann abweichen - sie könnte eine request_id oder eine direkte Status-URL zurückgeben
# Unter der Annahme, dass sie eine Status-URL ähnlich wie Replicate für dieses konzeptionelle Beispiel zurückgibt
status_url = submit_response_json.get('status_url') # Oder von request_id konstruieren, Dokumente prüfen
request_id = submit_response_json.get('request_id') # Alternative Kennung
if not status_url and request_id:
# Möglicherweise müssen Sie die Status-URL erstellen, z. B. <https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status>
# Oder einen generischen Status-Endpunkt abfragen: <https://fal.run/requests/{request_id}/status>
print("Müssen Status-URL erstellen oder request_id verwenden, überprüfen Sie die Fal.ai-Dokumentation.")
exit() # Benötigt eine spezifische Implementierung basierend auf den Fal-Dokumenten
print(f"Anfrage gesendet. Status-URL: {status_url}")
# 2. Ergebnisse abfragen (falls asynchron)
output_data = None
while status_url: # Nur abfragen, wenn wir eine Status-URL haben
print("Status wird überprüft...")
# Abfragen erfordert möglicherweise auch eine Authentifizierung
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Überprüfen Sie die Fal.ai-Dokumente auf Status-Schlüssel ('COMPLETED', 'FAILED' usw.)
if status == 'COMPLETED': # Beispielstatus
output_data = status_response_json.get('response') # Oder 'result', 'output', Dokumente prüfen
print("Anfrage abgeschlossen!")
print(f"Ausgabe: {output_data}") # Die Ausgabestruktur hängt vom Modell auf Fal.ai ab
break
elif status == 'FAILED': # Beispielstatus
print(f"Anfrage fehlgeschlagen: {status_response_json.get('error')}") # Überprüfen Sie das Fehlerfeld
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # Beispielstatus
# Warten, bevor erneut abgefragt wird
time.sleep(3) # Passen Sie das Abfrageintervall an
else:
print(f"Unbekannter Status: {status}")
print(status_response_json)
break
# Verwenden Sie die output_data (die möglicherweise Bild-URLs oder andere Informationen enthält)
Preisgestaltung: Fal.ai berechnet typischerweise basierend auf der Ausführungszeit, oft mit sekundengenauer Abrechnung. Überprüfen Sie die Preisdetails für das spezifische Modell und die Rechenressourcen.
Testen Sie die HiDream-API mit Apidog
Apidog ist ein leistungsstarkes Tool für API-Design, -Entwicklung und -Tests. Es bietet eine benutzerfreundliche Oberfläche zum Senden von HTTP-Anfragen, zum Untersuchen von Antworten und zum Verwalten von API-Details, wodurch es sich ideal zum Testen der Replicate- und Fal.ai-APIs eignet, bevor sie in Code integriert werden.
Schritte zum Testen der HiDream-I1-Full-API mit Apidog:
Schritt 1. Installieren und Öffnen von Apidog: Laden Sie Apidog herunter und installieren Sie es oder verwenden Sie die Webversion. Erstellen Sie bei Bedarf ein Konto.

Schritt 2. Erstellen Sie eine neue Anfrage:
- Erstellen Sie in Apidog ein neues Projekt oder öffnen Sie ein vorhandenes.
- Klicken Sie auf die Schaltfläche "+", um eine neue HTTP-Anfrage hinzuzufügen.
Schritt 3. HTTP-Methode und URL festlegen:
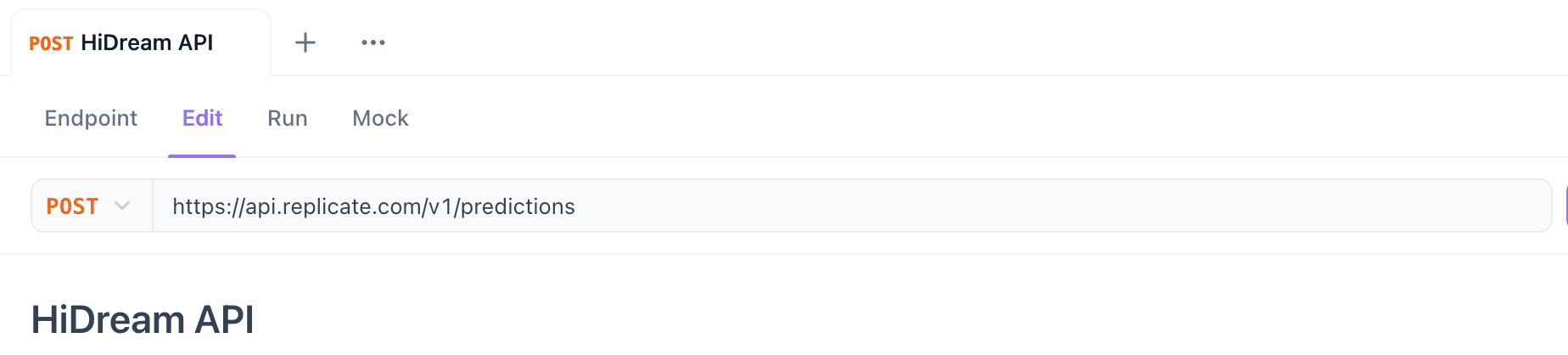
- Methode: Wählen Sie
POST. - URL: Geben Sie die API-Endpunkt-URL ein.
- Für Replicate (Starten der Vorhersage):
https://api.replicate.com/v1/predictions - Für Fal.ai (Senden der Anfrage): Verwenden Sie die spezifische Modell-Endpunkt-URL, die auf deren Seite bereitgestellt wird (z. B.
https://fal.run/fal-ai/hidream-i1-full- überprüfen Sie, ob/queueoder Abfrageparameter für Async benötigt werden).
Schritt 4. Header konfigurieren:
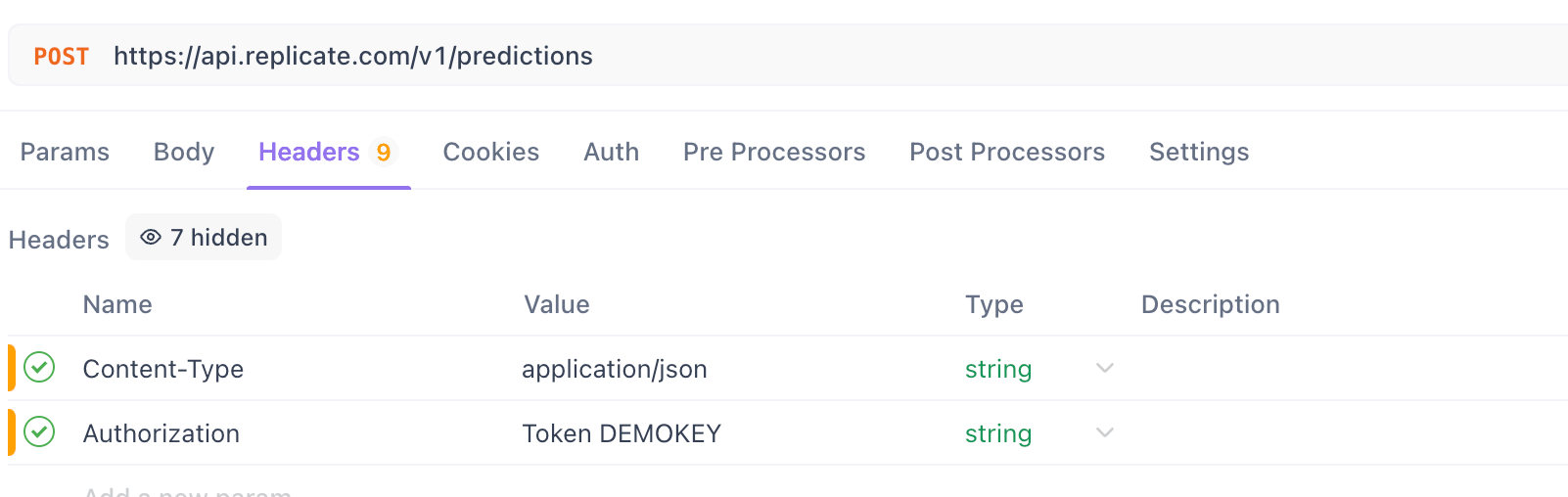
- Gehen Sie zur Registerkarte
Headers.
Fügen Sie den Header Content-Type hinzu:
- Schlüssel:
Content-Type - Wert:
application/json
Fügen Sie den Header Authorization hinzu:
Für Replicate:
- Schlüssel:
Authorization - Wert:
Token YOUR_REPLICATE_API_TOKEN(Ersetzen Sie dies durch Ihr tatsächliches Token)
Für Fal.ai:
- Schlüssel:
Authorization - Wert:
Key YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET(Ersetzen Sie dies durch Ihre tatsächlichen Anmeldeinformationen) - Profi-Tipp: Verwenden Sie die Umgebungsvariablen von Apidog, um Ihre API-Schlüssel sicher zu speichern, anstatt sie direkt in der Anfrage fest zu codieren. Erstellen Sie eine Umgebung (z. B. "Replicate Dev", "Fal Dev") und definieren Sie Variablen wie
REPLICATE_TOKENoderFAL_API_KEY. Verwenden Sie dann im Header-WertToken {{REPLICATE_TOKEN}}oderKey {{FAL_API_KEY}}.
Schritt 5. Anfragetext konfigurieren:
Gehen Sie zur Registerkarte Body.
Wählen Sie das Format raw und wählen Sie JSON aus der Dropdown-Liste.
Fügen Sie den JSON-Payload gemäß den Anforderungen der Plattform ein.
Beispiel-JSON-Text für Replicate:
{
"version": "PASTE_MODEL_VERSION_FROM_REPLICATE_PAGE_HERE",
"input": {
"prompt": "Ein Aquarellgemälde einer gemütlichen Bibliotheksecke mit einer schlafenden Katze",
"negative_prompt": "fotorealistisch, 3D-Rendering, schlechte Kunst, deformiert",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Beispiel-JSON-Text für Fal.ai
{
"prompt": "Ein Aquarellgemälde einer gemütlichen Bibliotheksecke mit einer schlafenden Katze",
"negative_prompt": "fotorealistisch, 3D-Rendering, schlechte Kunst, deformiert",
"width": 1024,
"height": 1024,
"seed": 55555
// Andere Parameter wie 'model_name' könnten je nach Fal.ai-Setup benötigt werden
}
Wichtig: Beachten Sie die spezifische Dokumentation auf den Replicate- oder Fal.ai-Seiten für die genauen erforderlichen und optionalen Parameter für die von Ihnen verwendete HiDream-I1-Full-Modellversion. Parameter wie guidance_scale, num_inference_steps usw. sind möglicherweise verfügbar.
Schritt 6. Senden Sie die Anfrage:
- Klicken Sie auf die Schaltfläche "Senden".
- Apidog zeigt den Antwortstatuscode, die Header und den Text an.
- Für Replicate: Sie sollten einen Status
201 Createderhalten. Der Antworttext enthält dieidder Vorhersage und eineurls.get-URL. Kopieren Sie dieseget-URL. - Für Fal.ai (Async): Sie erhalten möglicherweise einen
200 OK- oder202 Accepted-Status. Der Antworttext enthält möglicherweise einerequest_id, eine direktestatus_urloder andere Details basierend auf deren Implementierung. Kopieren Sie die relevante URL oder ID, die für das Abfragen benötigt wird. Wenn es synchron ist, erhalten Sie das Ergebnis möglicherweise direkt nach der Verarbeitung (weniger wahrscheinlich für die Bilderzeugung).
Ergebnisse abfragen (für asynchrone APIs):
- Erstellen Sie eine weitere neue Anfrage in Apidog.
- Methode: Wählen Sie
GET. - URL: Fügen Sie die
Status-URLein, die Sie aus der ersten Antwort kopiert haben (z. B. dieurls.getvon Replicate oder die Status-URL von Fal.ai). Wenn Fal.ai einerequest_idangegeben hat, erstellen Sie die Status-URL gemäß deren Dokumentation (z. B.https://fal.run/requests/{request_id}/status). - Header konfigurieren: Fügen Sie denselben
Authorization-Header wie in der POST-Anfrage hinzu. (Content-Type wird normalerweise für GET nicht benötigt). - Senden Sie die Anfrage: Klicken Sie auf "Senden".
- Antwort untersuchen: Überprüfen Sie das Feld
statusin der JSON-Antwort. - Wenn
processing,starting,IN_PROGRESS,IN_QUEUEusw. ist, warten Sie ein paar Sekunden und klicken Sie erneut auf "Senden". - Wenn
succeededoderCOMPLETEDist, suchen Sie nach dem Feldoutput(Replicate) oder dem Feldresponse/result(Fal.ai), das die URL(s) Ihrer generierten Bilder enthalten sollte. - Wenn
failedoderFAILEDist, überprüfen Sie das Felderrorauf Details.
Das Bild anzeigen: Kopieren Sie die Bild-URL aus der endgültigen erfolgreichen Antwort und fügen Sie sie in Ihren Webbrowser ein, um das generierte Bild anzuzeigen.
Möchten Sie eine integrierte All-in-One-Plattform für Ihr Entwicklerteam, um mit maximaler Produktivität zusammenzuarbeiten?
Apidog liefert alle Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!

Fazit
HiDream-I1-Full bietet leistungsstarke Bildgenerierungsfunktionen, und die Verwendung von APIs von Plattformen wie Replicate oder Fal.ai macht diese Technologie zugänglich, ohne komplexe Infrastruktur verwalten zu müssen. Durch das Verständnis des API-Workflows (Anfrage, potenzielles Abfragen, Antwort) und die Verwendung von Tools wie Apidog zum Testen können Sie auf einfache Weise mit der hochmodernen KI-Bildgenerierung experimentieren und diese in Ihre Projekte integrieren.
Denken Sie daran, immer die spezifische Dokumentation auf Replicate und Fal.ai zu konsultieren, um die aktuellsten Endpunkt-URLs, erforderlichen Parameter, Authentifizierungsmethoden und Preisdetails zu erhalten, da sich diese im Laufe der Zeit ändern können. Viel Spaß beim Generieren!


