
Die Wahl der richtigen Datenmanagementstrategie ist für den Erfolg Ihrer Projekte unerlässlich. Die Effektivität Ihrer Anwendungen hängt oft davon ab, wie gut Sie Daten verwalten und abrufen können.
In diesem Artikel werden wir uns mit den wichtigsten Unterschieden und Vorteilen von GraphQL und SQL befassen, zwei leistungsstarken Ansätzen, die auf unterschiedliche Datenanforderungen zugeschnitten sind. Indem Sie ihre einzigartigen Funktionen verstehen, können Sie fundierte Entscheidungen treffen, die mit den Anforderungen Ihrer Anwendung übereinstimmen und ihre Leistung verbessern. Begleiten Sie uns, während wir die Komplexität jeder Methode aufschlüsseln und so den Weg für ein intelligenteres, effizienteres Datenmanagement ebnen!
Klicken Sie auf die Schaltfläche Download und verwandeln Sie noch heute Ihre SQL Server-Konnektivität! 🚀🌟
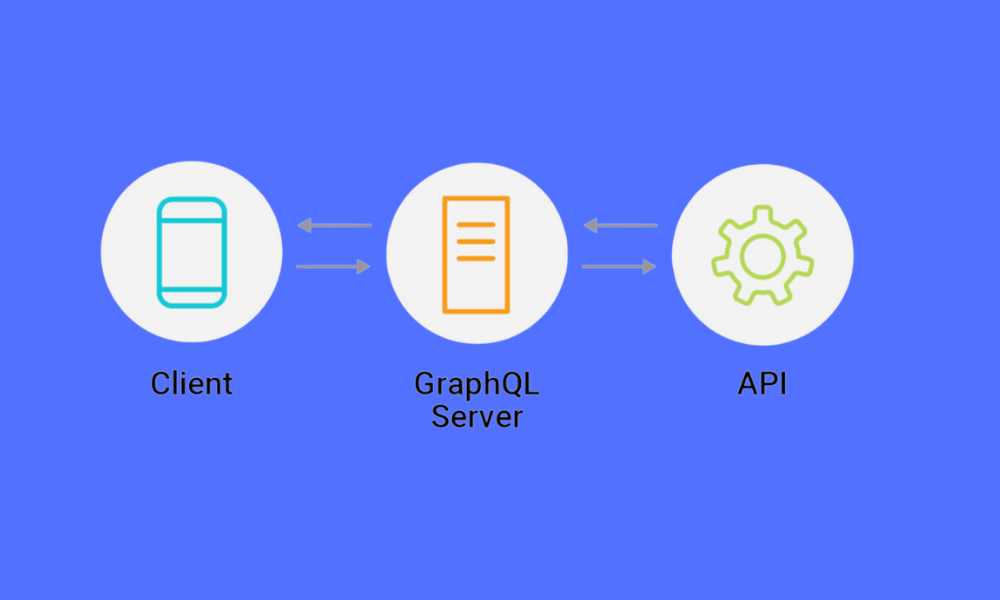
Was ist GraphQL?
GraphQL ist eine von Facebook für APIs entwickelte Abfragesprache sowie eine Laufzeitumgebung für die Ausführung dieser Abfragen unter Verwendung eines für Ihre Daten definierten Typsystems. Es ist keine Datenbanktechnologie, sondern eine Möglichkeit, über APIs mit Daten zu interagieren.
type Query {
user(id: ID!): User
}
type User {
id: ID!
name: String
email: String
}
# Query
{
user(id: "123") {
name
email
}
}
Hauptmerkmale von GraphQL
- Client-spezifische Abfragen: Ermöglicht Clients, genau die Daten anzufordern, die sie benötigen, auch mit tief verschachtelten Strukturen.
- Einzelner Endpunkt: Verwendet einen einzelnen API-Endpunkt und nutzt Abfragen, um verschiedene Datenformen abzurufen.
- Echtzeitdaten mit Abonnements: Unterstützt Echtzeit-Datenaktualisierungen über Abonnements.
- Reduziertes Overfetching: Reduziert unnötige Datenübertragungen, indem Clients genau angeben können, was sie benötigen.
Warum GraphQL in Ihrer Anwendung verwenden?
Die Verwendung von GraphQL in einer Anwendung kann eine Vielzahl von Vorteilen bieten, insbesondere für datengesteuerte Anwendungen, die auf effizientes und flexibles Datenabrufen angewiesen sind. Lassen Sie uns ein Beispiel für eine Blogging-Plattform verwenden, um die Vorteile von GraphQL zu veranschaulichen.
Szenario: Erstellen einer Blog-API
Stellen Sie sich vor, Sie entwickeln eine Blog-Anwendung mit den folgenden Entitäten:
- User: Autor der Blog-Beiträge.
- Post: Der Blog-Beitrag, einschließlich Titel, Inhalt und Veröffentlichungsdatum.
- Comments: Kommentare zu jedem Beitrag von Lesern.
In einer REST-API haben Sie möglicherweise die folgenden Endpunkte:
/users/{id}, um Benutzerdetails abzurufen./posts/{id}, um Beitragsdetails abzurufen./posts/{id}/comments, um Kommentare zu einem Beitrag abzurufen.
Um eine detaillierte Blog-Beitragsseite zu erstellen, möchten Sie Folgendes anzeigen:
- Den Beitragsinhalt.
- Den Namen und das Profil des Autors.
- Alle Kommentare zusammen mit dem Namen jedes Kommentators.
REST-Ansatz
- Erste Anfrage:
/posts/123– Ruft den Beitragsinhalt und die Metadaten ab. - Zweite Anfrage:
/users/45– Ruft Details des Autors ab (unter der Annahme, dass die Autoren-ID 45 ist). - Dritte Anfrage:
/posts/123/comments– Ruft alle Kommentare zum Beitrag ab. - Zusätzliche Anfragen: Möglicherweise benötigen Sie weitere Anfragen, wenn jeder Kommentar Daten von verschiedenen Benutzern benötigt und das Profil jedes Kommentators separat abgerufen wird.
Mit REST kann dies zu Over-Fetching (Abrufen von mehr Informationen als nötig, z. B. zusätzliche Felder in jedem Endpunkt) und Under-Fetching (Nicht-Abrufen verschachtelter Beziehungen wie Kommentare und Benutzerdetails in einer einzigen Abfrage) führen.
GraphQL-Ansatz
Mit GraphQL können Sie eine einzelne Abfrage erstellen, um alle erforderlichen Daten abzurufen:
query {
post(id: "123") {
title
content
publishedDate
author {
name
profilePicture
}
comments {
text
commenter {
name
}
}
}
}
In dieser einzelnen Abfrage:
- Beitragsdaten: Sie erhalten den
title,contentundpublishedDatedes Beitrags. - Autorendaten: Verschachtelt unter dem Feld
author, sodass Sie nur dennameundprofilePictureerhalten, die Sie benötigen. - Kommentare: Jeder Kommentar enthält nur den
textund dennamedes Kommentators.
Hauptvorteile in diesem Beispiel
- Reduzierte Netzwerkanfragen: Anstatt mehrere Anfragen an verschiedene Endpunkte zu senden, rufen Sie alle erforderlichen Daten mit einer einzigen Anfrage ab. Dies reduziert die Netzwerklast und beschleunigt die Antwortzeit.
- Vermeidet Over-Fetching/Under-Fetching: Sie erhalten nur die spezifischen Felder, die Sie angefordert haben, ohne überschüssige Daten oder fehlende Felder. Dies macht das Datenabrufen effizienter, insbesondere in mobilen Netzwerken oder Netzwerken mit geringer Bandbreite.
- Single Source of Truth: Das GraphQL-Schema definiert die Datenstruktur und macht es sowohl für Frontend- als auch für Backend-Teams klar, welche Daten verfügbar sind und wie sie abgefragt werden können.
- Vereinfachte Versionierung: Da jeder Client die benötigten Daten angibt, können Backend-Teams das Schema sicher weiterentwickeln, ohne die vorhandene Funktionalität zu beeinträchtigen.
Auf diese Weise können Sie mit der Abfrageflexibilität von GraphQL das Datenabrufen optimieren und Ihre Anwendung schneller und effizienter machen, insbesondere beim Umgang mit komplexen oder tief verschachtelten Daten.
Was ist SQL?
SQL (Structured Query Language) ist eine domänenspezifische Sprache, die in der Programmierung verwendet und für die Verwaltung von Daten in relationalen Datenbankverwaltungssystemen (RDBMS) entwickelt wurde. Sie ist besonders effektiv für die Verarbeitung strukturierter Daten, bei denen Beziehungen zwischen verschiedenen Entitäten klar definiert sind.

SELECT name, email FROM users WHERE id = 123;
Hauptmerkmale von SQL
- Standardisierte Abfragesprache: Ein weithin akzeptierter Standard für das Abfragen und Bearbeiten von Daten in relationalen Datenbanken.
- Tabellarische Datenrepräsentation: Daten werden in Tabellen organisiert, und Beziehungen können mithilfe von Primär- und Fremdschlüsseln gebildet werden.
- Komplexe Abfragen: Unterstützt komplexe Abfragen mit JOIN-Operationen, Aggregationen und Unterabfragen.
- Transaktionskontrolle: Bietet eine robuste Transaktionskontrolle, um die Datenintegrität sicherzustellen.
Warum SQL in Ihrer Anwendung verwenden?
Die Verwendung von SQL (Structured Query Language) in Ihrer Anwendung bietet mehrere Vorteile, insbesondere beim Umgang mit strukturierten Daten und komplexen Abfrageanforderungen. SQL-Datenbanken, auch bekannt als relationale Datenbanken, werden in Anwendungen in vielen Branchen aufgrund ihrer Zuverlässigkeit, robusten Datenintegrität und Benutzerfreundlichkeit häufig verwendet. Lassen Sie uns ein Beispiel für eine E-Commerce-Anwendung verwenden, um die Vorteile von SQL zu veranschaulichen.
Szenario: Erstellen einer E-Commerce-Anwendung mit SQL
Stellen Sie sich vor, Sie entwickeln einen Online-Shop mit den folgenden Funktionen:
- Users: Kunden, die Konten erstellen, Bestellungen aufgeben und Bewertungen schreiben können.
- Products: Artikel zum Verkauf, jeweils mit spezifischen Details (Name, Preis, Lagerbestand).
- Orders: Transaktionen, die ein oder mehrere von einem Benutzer gekaufte Produkte enthalten.
- Reviews: Feedback von Benutzern zu verschiedenen Produkten.
In SQL können diese Funktionen durch verwandte Tabellen dargestellt werden:
- Users Table: Speichert Benutzerinformationen (Benutzer-ID, Name, E-Mail).
- Products Table: Speichert Produktinformationen (Produkt-ID, Name, Preis, Lagerbestand).
- Orders Table: Speichert die Metadaten jeder Bestellung (Bestell-ID, Benutzer-ID, Bestelldatum).
- OrderItems Table: Speichert Details zu jedem Artikel in einer Bestellung (Bestellartikel-ID, Bestell-ID, Produkt-ID, Menge).
- Reviews Table: Speichert Bewertungen von Benutzern (Bewertungs-ID, Benutzer-ID, Produkt-ID, Bewertung, Kommentar).
Wie SQL dies effizient macht
Datenintegrität mit Fremdschlüsseln
- Die Tabelle
OrderItemsenthält eineproduct_id, die mit der TabelleProductsverknüpft ist, um sicherzustellen, dass jeder Bestellartikel auf ein gültiges Produkt verweist. In ähnlicher Weise enthält die TabelleOrdersein Felduser_id, das mit der TabelleUsersverknüpft ist, um sicherzustellen, dass jede Bestellung mit einem vorhandenen Benutzer verknüpft ist. - Diese Einrichtung erzwingt die Datenintegrität und verhindert, dass Bestellungen Produkte oder Benutzer enthalten, die nicht existieren.
Komplexe Abfragen für Berichte
- Angenommen, Sie möchten einen Bericht über den Gesamtumsatz für jedes Produkt. In SQL können Sie eine Abfrage mit Joins und Aggregationsfunktionen verwenden, um diese Daten effizient abzurufen:
SELECT
Products.name,
SUM(OrderItems.quantity) AS total_quantity_sold,
SUM(OrderItems.quantity * Products.price) AS total_revenue
FROM
OrderItems
JOIN
Products ON OrderItems.product_id = Products.product_id
GROUP BY
Products.name;
Diese Abfrage berechnet sowohl die Menge als auch den Umsatz jedes Produkts, was andernfalls mehrere Schritte in weniger strukturierten Datenbanken erfordern würde.Sicherstellung der Transaktionskonsistenz
- Wenn ein Benutzer eine Bestellung aufgibt, muss die Anwendung mehrere Tabellen aktualisieren:
- Fügen Sie einen Eintrag in die Tabelle
Ordersfür die Transaktion ein. - Fügen Sie Einträge in die Tabelle
OrderItemsfür jeden gekauften Artikel ein. - Reduzieren Sie die Lagerbestandsmenge in der Tabelle
Products. - Mithilfe von SQL-Transaktionen werden diese Aktionen zusammengefasst. Wenn ein Schritt fehlschlägt (z. B. ein Produkt nicht mehr vorrätig ist), kann die gesamte Transaktion zurückgesetzt werden, um sicherzustellen, dass die Datenbank in einem konsistenten Zustand bleibt. So könnte diese Transaktion in SQL aussehen:
BEGIN TRANSACTION;
-- Add a new order
INSERT INTO Orders (user_id, order_date)
VALUES (1, CURRENT_DATE);
-- Add order items
INSERT INTO OrderItems (order_id, product_id, quantity)
VALUES (LAST_INSERT_ID(), 2, 3);
-- Deduct stock
UPDATE Products
SET stock = stock - 3
WHERE product_id = 2;
COMMIT;
Wenn die Lagerbestandsaktualisierung aufgrund unzureichender Menge fehlschlägt, setzt SQL die Transaktion zurück, um sicherzustellen, dass die Bestellung und die Bestellartikel nicht teilweise gespeichert werden, wodurch die Datengenauigkeit erhalten bleibt.Datenanalyse und Kundeneinblicke
- Mit SQL können Sie Einblicke in das Kundenverhalten und die Produktleistung generieren. Beispielsweise möchten Sie möglicherweise die am häufigsten gekauften Produkte finden:
SELECT
product_id, COUNT(*) AS purchase_count
FROM
OrderItems
GROUP BY
product_id
ORDER BY
purchase_count DESC
LIMIT 5;
- Diese Abfrage findet die fünf besten Produkte nach Kaufanzahl, eine wertvolle Metrik zum Verständnis beliebter Produkte und zur Planung des Inventars.
Zusammenfassung der SQL-Vorteile in diesem Beispiel
- Strukturierte Daten und Beziehungen: Tabellen und Fremdschlüssel tragen dazu bei, strukturierte, relationale Daten zu erzwingen, was ideal für organisierte Anwendungen wie E-Commerce ist.
- Datenintegrität und ACID-Konformität: SQL-Transaktionen stellen sicher, dass Operationen vollständig oder gar nicht abgeschlossen werden, was für die Bearbeitung von Bestellungen von entscheidender Bedeutung ist.
- Leistungsstarke Abfragefunktionen: SQLs Joins, Aggregationen und Gruppierungen ermöglichen eine effiziente Datenanalyse und Berichterstellung und vereinfachen so Einblicke in Umsatz und Kundenverhalten. SQL eignet sich daher gut für diese E-Commerce-Anwendung, da es eine effiziente Datenorganisation, zuverlässige Datenintegrität und leistungsstarke Abfragen ermöglicht, wodurch es einfacher wird, Daten in Echtzeit zu verwalten und zu analysieren.
Hauptunterschiede zwischen GraphQL und SQL
GraphQL und SQL bieten jeweils unterschiedliche Vorteile für die Verwaltung und das Abrufen von Daten. Die flexiblen Abfragefunktionen, Echtzeitfunktionalitäten und das effiziente Datenabrufen von GraphQL machen es ideal für moderne Anwendungen mit unterschiedlichen Datenanforderungen.
Im Gegensatz dazu ist SQL hervorragend in der Verwaltung strukturierter Daten, der Navigation durch komplexe Beziehungen und der Aufrechterhaltung der Transaktionsintegrität. Details sind wie folgt:
Zweck und Umfang:
- GraphQL ist eine Abfragesprache, die speziell für Client-Server-Interaktionen entwickelt wurde und hauptsächlich für Web-APIs verwendet wird.
- SQL ist eine Sprache zum Verwalten und Bearbeiten von Daten in einer relationalen Datenbank.
Datenabruf:
- GraphQL ermöglicht es Clients, genau anzugeben, welche Daten sie in einer einzigen Anfrage benötigen.
- SQL-Abfragen konzentrieren sich stärker auf das Abrufen von Daten aus einer Datenbank über SELECT-Abfragen, Joins und andere Operationen.
Echtzeitdaten:
- GraphQL kann Echtzeitdaten mit Abonnements verarbeiten.
- SQL unterstützt Echtzeit-Datenaktualisierungen nicht nativ auf die gleiche Weise.
Flexibilität beim Abfragen:
- GraphQL bietet hohe Flexibilität und ermöglicht angepasste Abfragen, die auf die Anforderungen des Clients zugeschnitten sind.
- SQL folgt einem stärker strukturierten Ansatz mit vordefinierten Schemata und starren Abfrageformaten.
Umgang mit Overfetching:
- GraphQL reduziert Overfetching effektiv, indem es spezifische Abfragen zulässt.
- SQL kann zu Overfetching führen, wenn die Abfrage nicht gut strukturiert oder zu breit gefasst ist.
Komplexität und Lernkurve:
- GraphQL hat möglicherweise eine steilere Lernkurve aufgrund seines einzigartigen Ansatzes zum Datenabruf.
- SQL wird weithin gelehrt und verwendet, mit einer großen Menge an Ressourcen und einem standardisierten Ansatz.
Unterschiede zwischen GraphQL vs. SQL
| Aspekt | GraphQL | SQL |
|---|---|---|
| Grundlegende Definition | Eine Abfragesprache für APIs, mit der Clients bestimmte Daten anfordern können. | Eine Sprache zum Verwalten und Abfragen von Daten in relationalen Datenbanken. |
| Datenabrufansatz | Ermöglicht Clients, genau das anzufordern, was sie benötigen, wodurch Overfetching reduziert wird. | Verwendet vordefinierte Abfragen, um Daten abzurufen, was zu Overfetching führen kann. |
| Echtzeit-Datenunterstützung | Unterstützt Echtzeit-Updates mit Abonnements. | Unterstützt in der Regel keine Echtzeit-Updates nativ. |
| Art der Kommunikation | Funktioniert typischerweise über HTTP/HTTPS mit einem einzigen Endpunkt. | Funktioniert über Datenbankverbindungen unter Verwendung verschiedener Protokolle, die auf dem Datenbanksystem basieren. |
| Abfrageflexibilität | Hochflexibel; Clients können Anfragen an ihre genauen Bedürfnisse anpassen. | Stärker strukturiert; basiert auf vordefinierten Schemata und Abfrageformaten. |
| Datenstruktur | Funktioniert gut mit hierarchischen und verschachtelten Datenstrukturen. | Am besten geeignet für tabellarische Daten in normalisierten Formen. |
| Anwendungsfälle | Ideal für komplexe, sich entwickelnde APIs und Anwendungen mit unterschiedlichen Datenanforderungen. | Geeignet für Anwendungen, die komplexe Transaktionen und Datenintegrität in Datenbanken erfordern. |
| Komplexität | Kann komplex sein, um die Leistung einzurichten und zu optimieren. | Weit verbreitet mit vielen Bildungsressourcen, aber komplexe Abfragen können eine Herausforderung sein. |
| Transaktionskontrolle | Verarbeitet keine Transaktionen; konzentriert sich auf das Datenabrufen. | Bietet eine robuste Transaktionskontrolle für die Datenintegrität. |
| Community und Ökosystem | Wächst rasant, besonders beliebt in der Web- und Mobile-Anwendungsentwicklung. | Ausgereift, mit umfangreichen Tools, Ressourcen und einer riesigen Community von Benutzern. |
| Typische Verwendungsumgebung | Wird häufig in Web- und mobilen Anwendungen für flexibles Datenabrufen verwendet. | Wird in Systemen verwendet, in denen Datenintegrität, komplexe Abfragen und Berichte von entscheidender Bedeutung sind. |
So stellen Sie in Apidog eine Verbindung zu SQL Server her
Das Herstellen einer Verbindung zu einem SQL Server in Apidog ist ein Prozess, der dem Herstellen einer Verbindung zu einer Oracle-Datenbank ähnelt, jedoch mit einigen spezifischen Unterschieden, die auf SQL Server zugeschnitten sind. Hier ist eine prägnante Anleitung, die Ihnen hilft, diese Verbindung einzurichten:
Schritt 1: Apidog installieren
- Apidog herunterladen: Besuchen Sie die offizielle Website von Apidog und laden Sie die Anwendung herunter. Stellen Sie sicher, dass sie mit Ihrem Betriebssystem (Windows oder Linux) kompatibel ist.
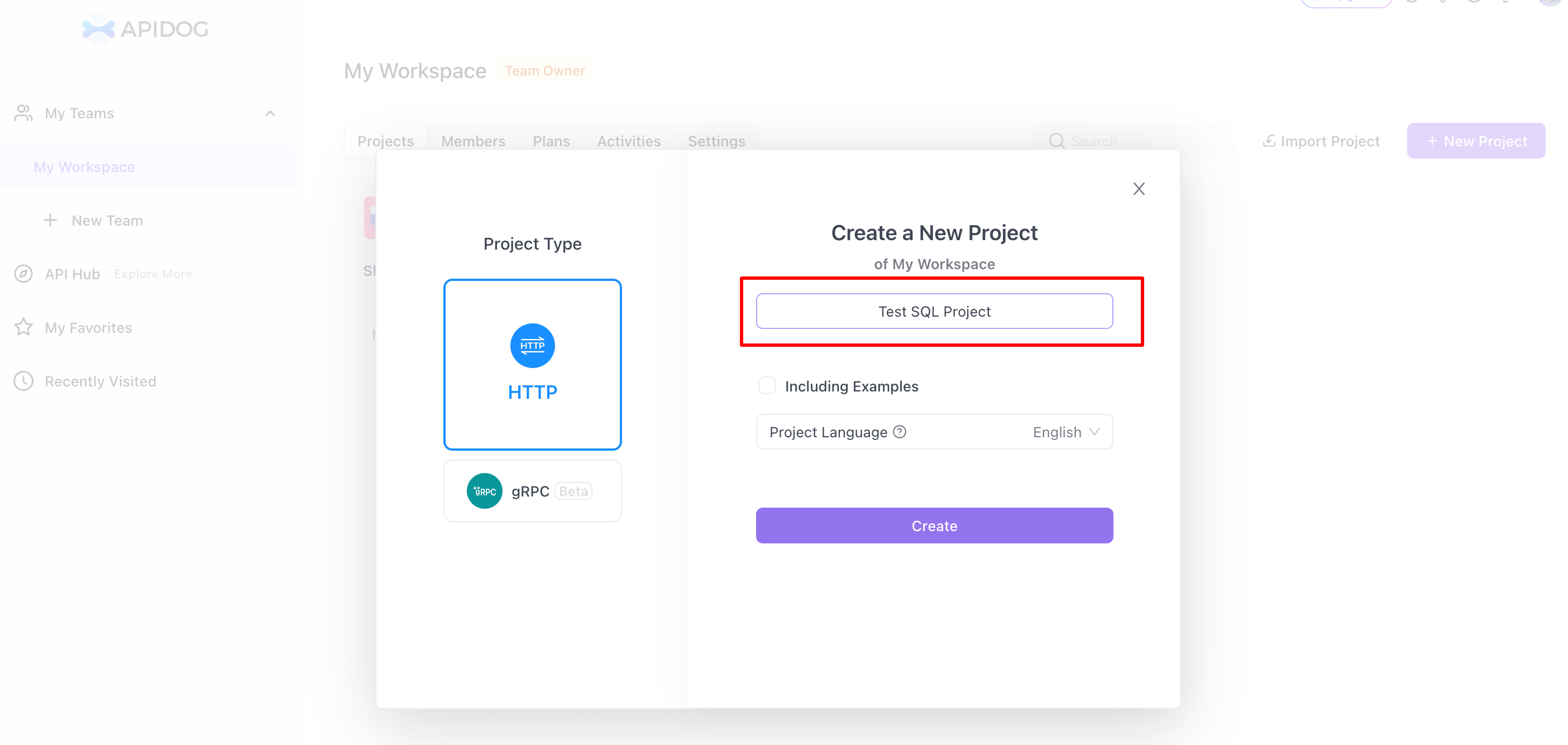
Schritt 2: Ein neues Projekt erstellen
- Neues Projekt: Gehen Sie in Apidog zum Abschnitt "Mein Arbeitsbereich", wählen Sie "Neues Projekt" und wählen Sie "HTTP" als Typ aus. Geben Sie einen Namen für Ihr Projekt ein.
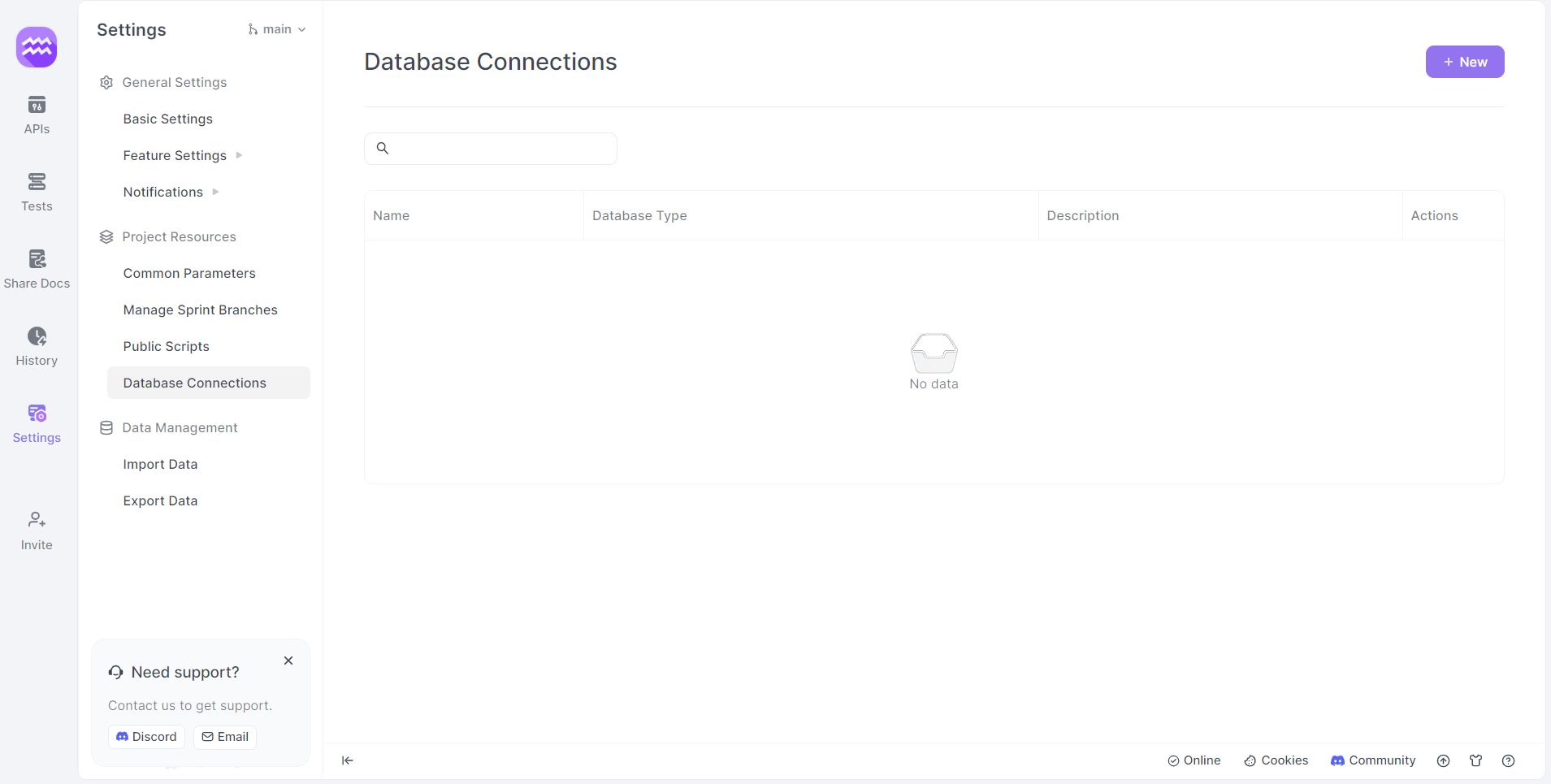
Schritt 3: Auf Datenbankverbindungen zugreifen
- Einstellungen: Klicken Sie im Seitenmenü auf die Option "Einstellungen".
- Datenbankverbindungen: Navigieren Sie zum Menü "Datenbankverbindungen".
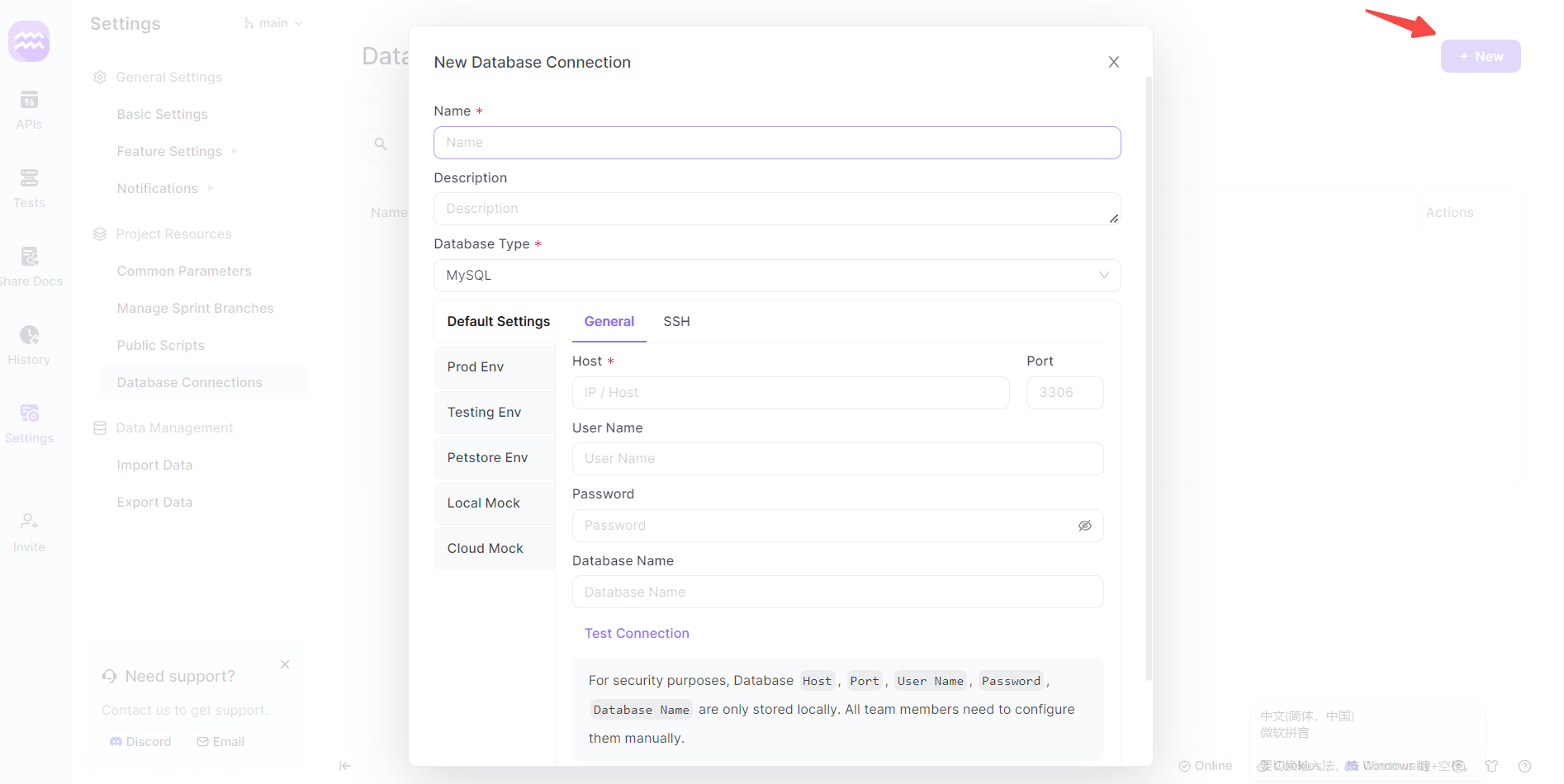
Schritt 4: Eine neue Verbindung einrichten
- Verbindung hinzufügen: Klicken Sie auf "+ Neu", um eine neue Datenbankverbindung zu erstellen. Ein neues Fenster wird für die Einrichtung angezeigt.
Schritt 5: SQL Server-Verbindung konfigurieren
- Verbindungsdetails: Geben Sie einen Namen für Ihre Datenbankverbindung ein und wählen Sie "SQL Server" als Datenbanktyp aus.
- Serverdetails: Geben Sie den Host, den Port und andere relevante Details ein, die für Ihre SQL Server-Instanz spezifisch sind.
- Authentifizierung: Verwenden Sie den entsprechenden SQL Server-Benutzernamen und das Kennwort. Typischerweise könnte dies ein Administratorkonto wie "sa" oder ein benutzerspezifisches Konto sein.
- Verbindung testen: Klicken Sie auf die Schaltfläche "Verbindung testen", um zu überprüfen, ob die Einrichtung erfolgreich ist.
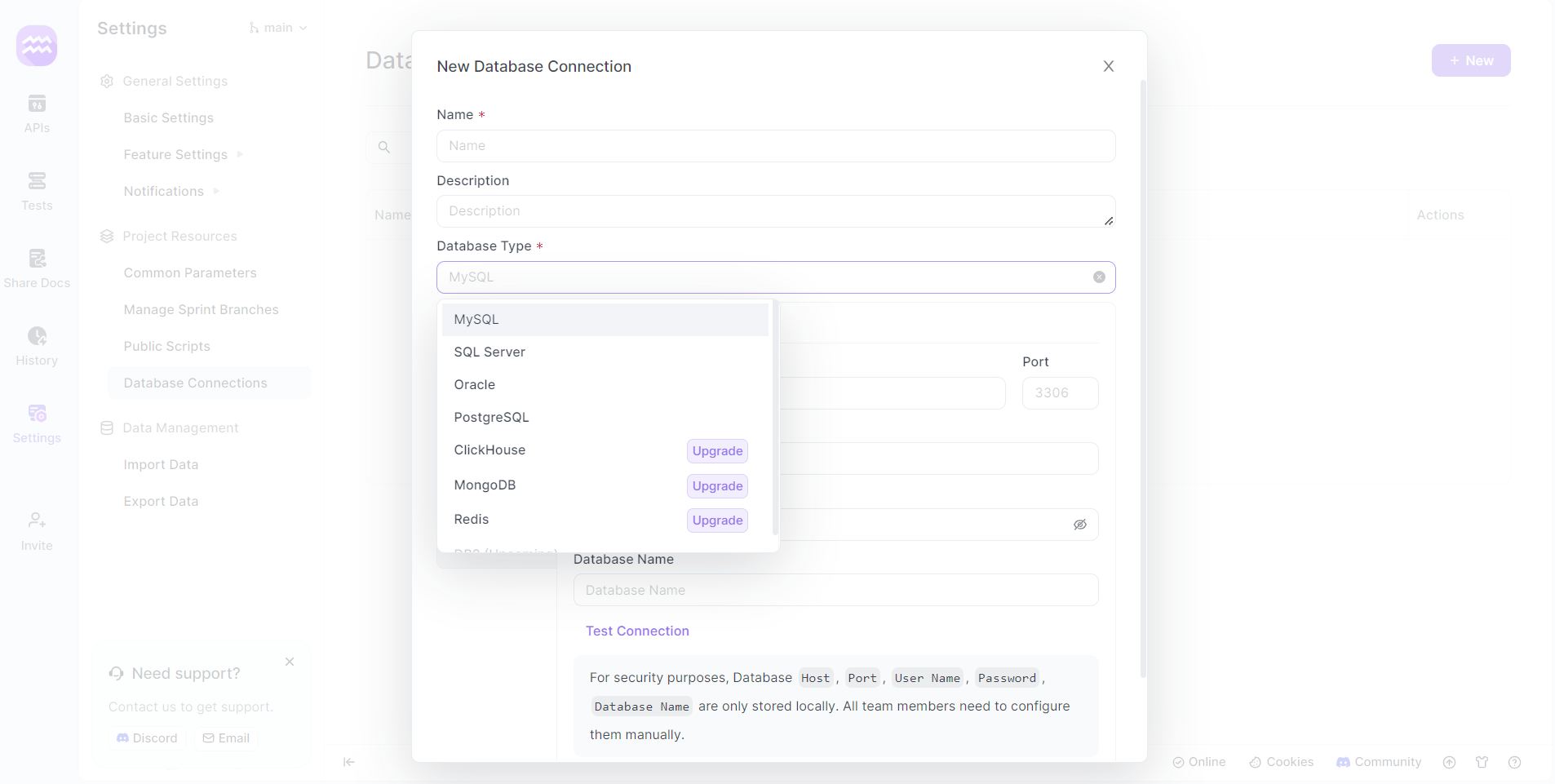
Schritt 6: API-Endpunkte definieren
- Endpunkte festlegen: Geben Sie URLs für Daten-Sende-/Empfangsvorgänge Ihrer App an und markieren Sie den Operationstyp (GET, POST, PUT, DELETE).
- Prozessoren konfigurieren: Definieren Sie alle Vor- oder Nachprozessoren für verschiedene Datenbankoperationen.
Schritt 7: Testen und Validieren
- API-Tests: Verwenden Sie die Tools von Apidog, um jeden Endpunkt zu testen. Der Editor hebt alle Fehler hervor.
- Debuggen und erneut testen: Untersuchen Sie alle Probleme, nehmen Sie Korrekturen vor und testen Sie erneut, bis die APIs wie erwartet funktionieren.
Fazit
Zusammenfassend lässt sich sagen, dass GraphQL und SQL unterschiedliche Aspekte der Datenverarbeitung und -abfrage abdecken. GraphQL zeichnet sich in Szenarien aus, die flexible, client-spezifische Abfragen und Echtzeitdaten erfordern, was es zu einer beliebten Wahl für moderne Web-APIs macht.
SQL hingegen bleibt der Eckpfeiler für die strukturierte Datenmanipulation in relationalen Datenbanken und zeichnet sich durch komplexe Datenabfragen und Transaktionsintegrität aus. Das Verständnis ihrer unterschiedlichen Eigenschaften hilft bei der Auswahl der richtigen Technologie basierend auf den spezifischen Anforderungen eines Projekts.


