
Die gpt-oss-safeguard-Modelle von OpenAI erfüllen diesen Bedarf, indem sie eine richtlinienbasierte Argumentation für Klassifizierungsaufgaben ermöglichen. Ingenieure integrieren diese Modelle, um benutzergenerierte Inhalte zu klassifizieren, Verstöße zu erkennen und die Plattformintegrität aufrechtzuerhalten.
GPT-OSS-Safeguard verstehen: Funktionen und Fähigkeiten
OpenAI-Ingenieure entwickelten gpt-oss-safeguard als Open-Weight-Argumentationsmodelle, die speziell für die Sicherheitsklassifizierung entwickelt wurden. Sie optimieren diese Modelle auf Basis von gpt-oss und veröffentlichen sie unter der Apache 2.0-Lizenz. Entwickler laden die Modelle von Hugging Face herunter und stellen sie frei bereit. Die Palette umfasst gpt-oss-safeguard-20b und gpt-oss-safeguard-120b, wobei die Zahlen die Parameterskalen angeben.
Diese Modelle verarbeiten zwei primäre Eingaben: eine vom Entwickler definierte Richtlinie und den zu bewertenden Inhalt. Das System wendet eine Chain-of-Thought-Argumentation an, um die Richtlinie zu interpretieren und den Inhalt zu klassifizieren. Zum Beispiel bestimmt es, ob eine Benutzernachricht gegen Regeln zum Cheaten in Gaming-Foren verstößt. Dieser Ansatz ermöglicht dynamische Richtlinienaktualisierungen ohne erneutes Training, was traditionelle Klassifikatoren erfordern.
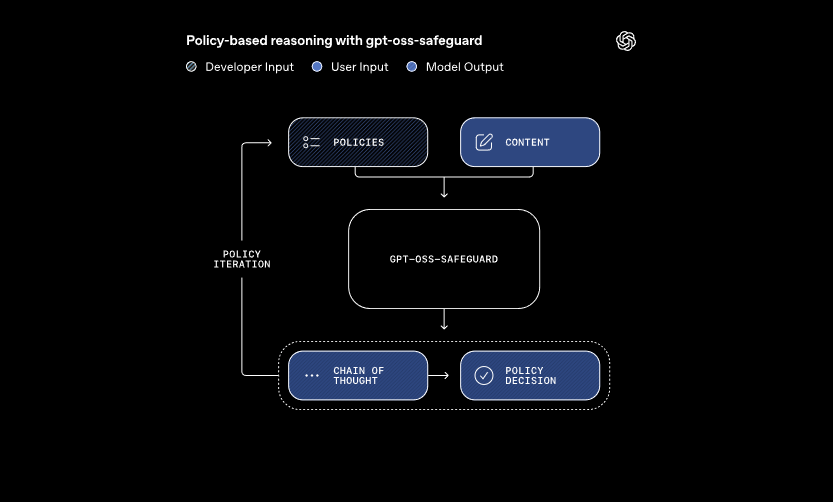
Darüber hinaus unterstützt gpt-oss-safeguard mehrere Richtlinien gleichzeitig. Entwickler speisen mehrere Regeln in einen einzigen Inferenzaufruf ein, und das Modell bewertet den Inhalt anhand all dieser Regeln. Diese Fähigkeit optimiert Arbeitsabläufe für Plattformen, die vielfältige Risiken wie Fehlinformationen oder schädliche Äußerungen handhaben. Die Leistung kann jedoch bei zusätzlichen Richtlinien leicht abnehmen, daher testen Teams die Konfigurationen gründlich.
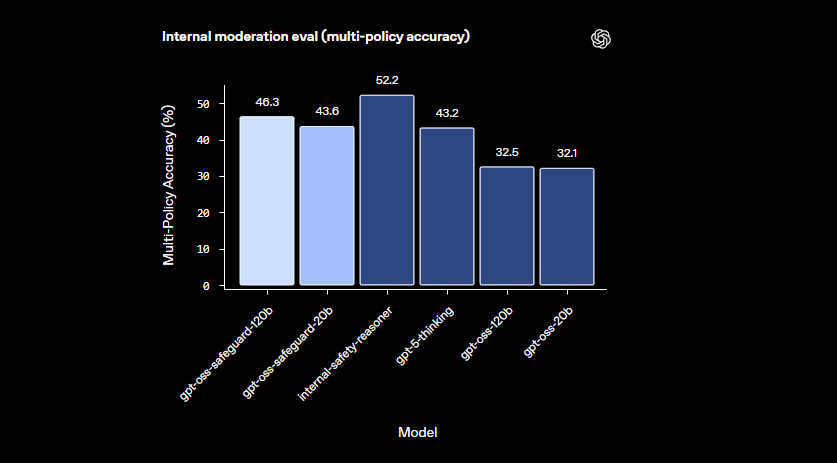
Die Modelle zeichnen sich in nuancierten Bereichen aus, in denen kleinere Klassifikatoren versagen. Sie bewältigen aufkommende Schäden, indem sie sich schnell an überarbeitete Richtlinien anpassen. Darüber hinaus bietet die Chain-of-Thought-Ausgabe Transparenz – Entwickler überprüfen die Argumentationsspur, um Entscheidungen zu überprüfen. Diese Funktion erweist sich als unschätzbar wertvoll für Compliance-Teams, die erklärbare KI benötigen.
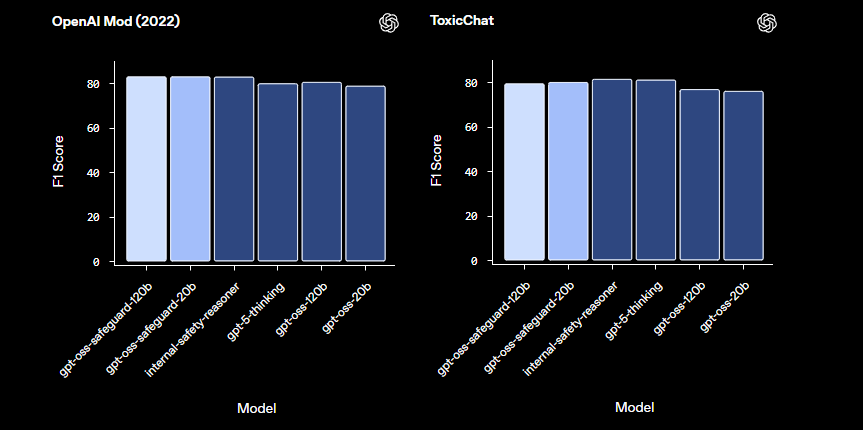
Im Vergleich zu vorgefertigten Sicherheitsmodellen wie LlamaGuard bietet gpt-oss-safeguard eine größere Anpassbarkeit. Es vermeidet feste Taxonomien und ermöglicht es Organisationen, ihre eigenen Schwellenwerte zu definieren. Folglich eignet sich die Integration für Trust & Safety-Ingenieure, die skalierbare Moderationspipelines aufbauen. Nachdem wir die Grundlagen verstanden haben, fahren wir mit der Einrichtung der Umgebung fort.
Einrichtung Ihrer Umgebung für den GPT-OSS-Safeguard API-Zugriff
Entwickler beginnen mit der Vorbereitung ihrer Systeme zur Ausführung von gpt-oss-safeguard. Da die Modelle Open-Weight sind, können Sie sie lokal oder über gehostete Anbieter bereitstellen. Diese Flexibilität ermöglicht verschiedene Hardware-Setups, von persönlichen Maschinen bis hin zu Cloud-Servern.
Installieren Sie zunächst die notwendigen Abhängigkeiten. Python 3.10 oder höher dient als Basis. Verwenden Sie pip, um Bibliotheken wie Hugging Face Transformers hinzuzufügen: pip install transformers. Für eine beschleunigte Inferenz fügen Sie torch mit CUDA-Unterstützung hinzu, wenn Sie eine kompatible GPU besitzen. Ingenieure mit NVIDIA-Hardware aktivieren dies für eine schnellere Verarbeitung.
Laden Sie als Nächstes die Modelle von Hugging Face herunter. Greifen Sie auf die Sammlung zu. Wählen Sie gpt-oss-safeguard-20b für geringeren Ressourcenbedarf oder gpt-oss-safeguard-120b für überlegene Genauigkeit. Der Befehl transformers-cli download openai/gpt-oss-safeguard-20b ruft die Dateien ab.
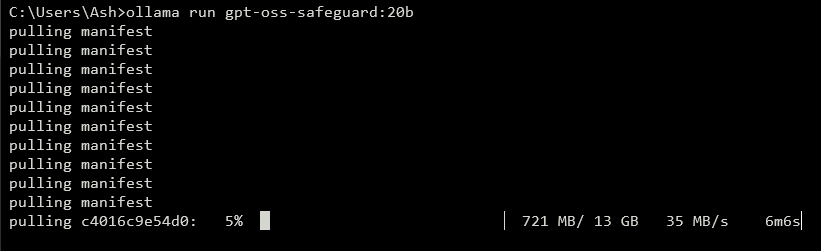
Um eine API bereitzustellen, starten Sie einen lokalen Server. Tools wie vLLM erledigen dies effizient. Installieren Sie vLLM mit pip install vllm. Starten Sie dann den Server: vllm serve openai/gpt-oss-safeguard-20b. Dieser Befehl startet einen OpenAI-kompatiblen Endpunkt unter http://localhost:8000/v1. Ähnlich vereinfacht Ollama die Bereitstellung: ollama run gpt-oss-safeguard:20b. Es bietet REST-APIs für die Integration.
Für lokale Tests bietet LM Studio eine benutzerfreundliche Oberfläche. Führen Sie lms get openai/gpt-oss-safeguard-20b aus, um das Modell abzurufen. Die Software emuliert die Chat Completions API von OpenAI und ermöglicht nahtlose Codeübergänge zur Produktion.
Gehostete Optionen eliminieren Hardware-Bedenken. Anbieter wie Groq unterstützen gpt-oss-safeguard-20b über ihre API. Melden Sie sich unter https://console.groq.com an, generieren Sie einen API-Schlüssel und richten Sie das Modell in Anfragen aus. Die Preise beginnen bei 0,075 $ pro Million Eingabe-Tokens. OpenRouter hostet es ebenfalls.
Überprüfen Sie nach der Einrichtung die Installation. Senden Sie eine Testanfrage per curl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'. Eine erfolgreiche Antwort bestätigt die Bereitschaft. Mit der konfigurierten Umgebung erstellen Sie als Nächstes Richtlinien.
Effektive Richtlinien für GPT-OSS-Safeguard erstellen
Richtlinien bilden das Rückgrat der gpt-oss-safeguard-Operationen. Entwickler schreiben sie als strukturierte Prompts, die die Klassifizierung leiten. Eine gut gestaltete Richtlinie maximiert die Argumentationskraft des Modells und gewährleistet genaue und erklärbare Ergebnisse.
Strukturieren Sie Ihre Richtlinie mit verschiedenen Abschnitten. Beginnen Sie mit Anweisungen, die die Aufgaben des Modells spezifizieren. Weisen Sie es beispielsweise an, Inhalte als verletzend (1) oder sicher (0) zu klassifizieren. Fahren Sie mit Definitionen fort, die Schlüsselbegriffe wie „entmenschlichende Sprache“ klären. Skizzieren Sie dann Kriterien für Verstöße und sichere Inhalte. Fügen Sie schließlich Beispiele hinzu – stellen Sie 4-6 Grenzfälle entsprechend gekennzeichnet bereit.
Verwenden Sie in Richtlinien die aktive Stimme: „Inhalte kennzeichnen, die Gewalt fördern“ anstelle passiver Alternativen. Halten Sie die Sprache präzise; vermeiden Sie Mehrdeutigkeiten wie „allgemein unsicher“. Wenn Konflikte zwischen Regeln auftreten, definieren Sie die Präzedenz explizit. Für Multi-Policy-Szenarien verketten Sie sie in der Systemnachricht.
Steuern Sie die Argumentationstiefe über den Parameter „reasoning_effort“: Setzen Sie ihn auf „high“ für komplexe Fälle oder „low“ für Geschwindigkeit. Das in gpt-oss-safeguard integrierte Harmonie-Format trennt die Argumentation von der endgültigen Ausgabe. Dies gewährleistet saubere API-Antworten und bewahrt gleichzeitig Audit-Trails.
Optimieren Sie die Richtlinienlänge auf etwa 400-600 Token. Kürzere Richtlinien bergen das Risiko einer übermäßigen Vereinfachung, während längere das Modell verwirren können. Testen Sie iterativ: Klassifizieren Sie Beispielinhalte und verfeinern Sie sie basierend auf den Ausgaben. Tools wie Token-Zähler in Hugging Face helfen hierbei.
Wählen Sie für Ausgabeformate binär zur Vereinfachung: Return exactly 0 or 1. Fügen Sie eine Begründung für die Tiefe hinzu: {"violation": 1, "rationale": "Erklärung hier"}. Diese JSON-Struktur lässt sich leicht in nachgelagerte Systeme integrieren. Während Sie Richtlinien verfeinern, wechseln Sie zur API-Implementierung.
Implementierung von API-Aufrufen mit GPT-OSS-Safeguard
Entwickler interagieren mit gpt-oss-safeguard über OpenAI-kompatible Endpunkte. Ob lokal oder gehostet, der Prozess folgt standardmäßigen Chat-Completion-Mustern.
Bereiten Sie Ihren Client vor. Importieren Sie in Python OpenAI: from openai import OpenAI. Initialisieren Sie mit der Basis-URL und dem Schlüssel: client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy") für lokal oder anbieterspezifische Werte.
Nachrichten erstellen. Die Systemrolle enthält die Richtlinie: {"role": "system", "content": "Ihre detaillierte Richtlinie hier"}. Die Benutzerrolle enthält den Inhalt: {"role": "user", "content": "Zu klassifizierender Inhalt"}.
Rufen Sie die API auf: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0). Eine Temperatur von 0 gewährleistet deterministische Ausgaben für Sicherheitsaufgaben.
Analysieren Sie die Antwort: result = completion.choices[0].message.content. Für strukturierte Ausgaben verwenden Sie JSON-Parsing. Groq verbessert dies mit Prompt-Caching – Richtlinien können über Aufrufe hinweg wiederverwendet werden, um Kosten um 50 % zu senken.
Behandeln Sie Streaming für Echtzeit-Feedback: Setzen Sie stream=True und iterieren Sie über Blöcke. Dies eignet sich für Moderation mit hohem Volumen.
Integrieren Sie bei Bedarf Tools, obwohl sich gpt-oss-safeguard auf die Klassifizierung konzentriert. Definieren Sie Funktionen im Parameter tools für erweiterte Funktionen, wie das Abrufen externer Daten.
Überwachen Sie die Token-Nutzung: Die Eingabe umfasst Richtlinie plus Inhalt, die Ausgaben fügen Argumentation hinzu. Begrenzen Sie max_tokens, um Überläufe zu vermeiden. Wenn die Aufrufe beherrscht werden, erkunden Sie Beispiele.
Erweiterte Funktionen in der GPT-OSS-Safeguard API
gpt-oss-safeguard bietet fortschrittliche Tools für eine verfeinerte Kontrolle. Prompt-Caching auf Groq wiederverwendet Richtlinien, wodurch Latenz und Kosten reduziert werden.
Passen Sie reasoning_effort in der Systemnachricht an: „Reasoning: high“ für tiefe Analyse. Dies behandelt mehrdeutige Inhalte besser.
Nutzen Sie das 128k-Kontextfenster für lange Chats oder Dokumente. Speisen Sie ganze Konversationen für eine ganzheitliche Klassifizierung ein.
Integrieren Sie in größere Systeme: Leiten Sie Ausgaben an Eskalationswarteschlangen oder zur Protokollierung weiter. Verwenden Sie Webhooks für Echtzeit-Benachrichtigungen.
Bei Bedarf weiter optimieren, obwohl die Basis bei der Richtlinienbefolgung hervorragend ist. Kombinieren Sie mit kleineren Modellen zur Vorfilterung, um die Rechenleistung zu optimieren.
Sicherheit ist wichtig: Sichern Sie API-Schlüssel und überwachen Sie auf Prompt-Injektionen. Validieren Sie Eingaben, um Exploits zu verhindern.
Skalierung: Stellen Sie auf Clustern mit vLLM für hohen Durchsatz bereit. Anbieter wie Groq liefern über 1000 Tokens/Sekunde.
Diese Funktionen heben gpt-oss-safeguard von einem einfachen Klassifikator zu einem Unternehmenswerkzeug. Befolgen Sie jedoch Best Practices für optimale Ergebnisse.
Best Practices und Optimierung für GPT-OSS-Safeguard
Ingenieure optimieren gpt-oss-safeguard durch iterative Anpassung der Richtlinien. Testen Sie mit verschiedenen Datensätzen und messen Sie die Genauigkeit anhand von Metriken wie dem F1-Score.
Gleichen Sie die Modellgröße aus: Verwenden Sie 20b für Geschwindigkeit, 120b für Präzision. Quantisieren Sie Gewichte, um den Speicherbedarf zu reduzieren.
Überwachen Sie die Leistung: Protokollieren Sie Argumentationsspuren für Audits. Passen Sie die Temperatur minimal an – 0,0 eignet sich für deterministische Anforderungen.
Behandeln Sie Einschränkungen: Das Modell kann in hochspezialisierten Domänen Schwierigkeiten haben; ergänzen Sie es mit Domänendaten.
Stellen Sie eine ethische Nutzung sicher: Richten Sie Richtlinien an Vorschriften aus. Vermeiden Sie Voreingenommenheit durch Diversifizierung der Beispiele.
Regelmäßig aktualisieren: Wenn OpenAI gpt-oss-safeguard weiterentwickelt, integrieren Sie Verbesserungen.
Kostenmanagement: Für gehostete APIs verfolgen Sie die Token-Ausgaben. Lokale Bereitstellungen minimieren die Kosten.
Durch die Anwendung dieser Praktiken maximieren Sie die Effizienz. Zusammenfassend lässt sich sagen, dass gpt-oss-safeguard robuste Sicherheitssysteme ermöglicht.
Fazit: Integration von GPT-OSS-Safeguard in Ihren Workflow
Entwickler nutzen gpt-oss-safeguard, um anpassungsfähige Sicherheitsklassifikatoren zu erstellen. Von der Einrichtung bis zur erweiterten Nutzung stattet Sie dieser Leitfaden mit technischem Wissen aus. Implementieren Sie Richtlinien, führen Sie API-Aufrufe aus und optimieren Sie für Ihre Anforderungen. Während sich Plattformen weiterentwickeln, passt sich gpt-oss-safeguard nahtlos an und gewährleistet sichere Umgebungen.