
Entwickler suchen ständig nach leistungsstarken Tools, um intelligente Anwendungen zu entwickeln. OpenAI begegnet diesem Bedarf mit der Veröffentlichung von GPT-OSS, einer Reihe von Open-Weight-Sprachmodellen, die fortschrittliche Denkfähigkeiten bieten. Diese Modelle, einschließlich gpt-oss-120b und gpt-oss-20b, ermöglichen die Anpassung und Bereitstellung in verschiedenen Umgebungen. Benutzer greifen über APIs, die von Hosting-Plattformen bereitgestellt werden, auf sie zu, was eine nahtlose Integration in Projekte ermöglicht.
Um mit der GPT-OSS API zu arbeiten, erhalten Entwickler Zugang über Anbieter wie OpenRouter oder Together AI. Diese Plattformen hosten die Modelle und stellen Standard-Endpunkte bereit, die mit dem API-Format von OpenAI kompatibel sind. Diese Kompatibilität vereinfacht die Migration von proprietären Modellen.
Was ist GPT-OSS? Wichtige Funktionen und Fähigkeiten
OpenAI konzipiert GPT-OSS als eine Familie von Mixture-of-Experts (MoE)-Modellen. Diese Architektur aktiviert pro Token nur eine Teilmenge von Parametern, was die Effizienz steigert. Zum Beispiel verfügt gpt-oss-120b über insgesamt 117 Milliarden Parameter, aktiviert aber nur 5,1 Milliarden pro Token. Ähnlich verwendet gpt-oss-20b 21 Milliarden Parameter mit 3,6 Milliarden aktiven.
Die Modelle verwenden Transformer-basierte Strukturen mit abwechselnd dichten und spärlichen Aufmerksamkeits-Layern. Sie integrieren Rotary Positional Embeddings (RoPE) zur Handhabung langer Kontexte von bis zu 128.000 Token. Entwickler profitieren davon in Anwendungen, die umfangreiche Eingaben erfordern, wie z. B. die Dokumentenzusammenfassung.
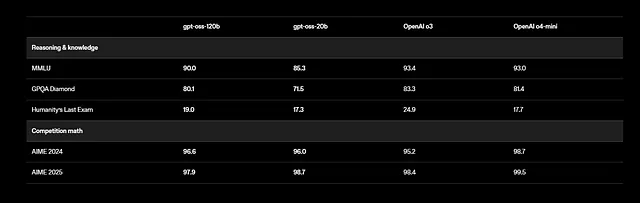
Darüber hinaus unterstützt GPT-OSS mehrsprachige Aufgaben, obwohl sich das Training auf Englisch mit Schwerpunkt auf STEM- und Coding-Daten konzentriert. Benchmarks zeigen beeindruckende Ergebnisse: gpt-oss-120b erzielt 94,2 % bei MMLU (Massive Multitask Language Understanding) und 96,6 % bei AIME (American Invitational Mathematics Examination). Es übertrifft Modelle wie o4-mini bei gesundheitsbezogenen Anfragen und Wettbewerbsmathematik.
Entwickler nutzen Tool-Calling-Funktionen, bei denen das Modell externe Funktionen wie Websuche oder Code-Ausführung aufruft. Diese agentische Fähigkeit ermöglicht den Aufbau autonomer Systeme. Zum Beispiel verknüpft das Modell mehrere Tool-Aufrufe in einer einzigen Antwort, um Probleme Schritt für Schritt zu lösen.
Zusätzlich halten sich die Modelle an die Apache 2.0-Lizenz, die eine freie Modifikation und Bereitstellung ermöglicht. OpenAI stellt Gewichte auf Hugging Face zur Verfügung, quantisiert im MXFP4-Format zur Reduzierung des Speicherbedarfs. Benutzer können sie lokal oder über Cloud-Anbieter ausführen.
Es gelten jedoch Sicherheitsaspekte. OpenAI führt Bewertungen im Rahmen seines Preparedness Frameworks durch, um Risiken wie Fehlinformationen zu testen. Entwickler implementieren Schutzmaßnahmen, wie z. B. das Filtern von Ausgaben, um Probleme zu mindern.
Im Wesentlichen kombiniert GPT-OSS Leistung mit Zugänglichkeit. Seine offene Natur fördert Beiträge der Community, was zu schnellen Verbesserungen führt. Als Nächstes identifizieren Sie Anbieter, die API-Zugriff auf diese Modelle anbieten.
Anbieter für den GPT-OSS API-Zugriff auswählen
Mehrere Plattformen hosten GPT-OSS-Modelle und stellen API-Endpunkte bereit. Entwickler wählen basierend auf Anforderungen wie Geschwindigkeit, Kosten und Skalierbarkeit. OpenRouter bietet zum Beispiel gpt-oss-120b mit wettbewerbsfähigen Preisen und einfacher Integration an.
Together AI bietet eine weitere Option, die auf unternehmensgerechte Bereitstellungen abzielt. Es unterstützt das Modell über einen /v1/chat/completions-Endpunkt, der mit OpenAI-Clients kompatibel ist. Entwickler senden JSON-Payloads, die Nachrichten, max_tokens und Temperatur angeben.
Darüber hinaus liefern Fireworks AI und Cerebras Hochgeschwindigkeits-Inferenz. Cerebras erreicht bis zu 3.000 Token pro Sekunde, ideal für Echtzeitanwendungen. Die Preise variieren: OpenRouter berechnet etwa 0,15 $ pro Million Eingabe-Token, während Together AI ähnliche Tarife mit Mengenrabatten anbietet.
Entwickler ziehen auch Self-Hosting für den Datenschutz in Betracht. Tools wie vLLM oder Ollama ermöglichen das Ausführen von GPT-OSS auf lokalen Servern, die eine API bereitstellen. Zum Beispiel bedient vLLM das Modell mit OpenAI-kompatiblen Routen, wobei ein einziger Befehl zum Starten erforderlich ist.
Cloud-Anbieter vereinfachen jedoch die Skalierung. AWS, Azure und Vercel integrieren GPT-OSS über Partnerschaften mit OpenAI. Diese Optionen übernehmen den Lastausgleich und die automatische Skalierung.
Zusätzlich sollte die Latenz bewertet werden. gpt-oss-20b eignet sich für Edge-Geräte mit geringeren Anforderungen, während gpt-oss-120b GPUs wie NVIDIA H100 benötigt. Anbieter optimieren die Hardware, um eine konsistente Leistung zu gewährleisten.
Kurz gesagt, der richtige Anbieter passt zu den Projektzielen. Sobald die Wahl getroffen ist, können Sie die API-Zugangsdaten erhalten.
API-Zugriff erhalten und Ihre Umgebung einrichten
Entwickler beginnen mit der Registrierung auf der Website eines Anbieters. Für OpenRouter besuchen Sie openrouter.ai, erstellen ein Konto und navigieren zum Bereich "Keys". Generieren Sie einen neuen API-Schlüssel, benennen Sie ihn zur Referenz und kopieren Sie ihn sicher.
Als Nächstes installieren Sie Client-Bibliotheken. In Python verwenden Sie pip, um openai hinzuzufügen: pip install openai. Konfigurieren Sie den Client mit der Basis-URL und dem Schlüssel. Zum Beispiel:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Diese Einrichtung ermöglicht das Senden von Anfragen an gpt-oss-Modelle.
Darüber hinaus verwenden Sie für Together AI deren SDK: pip install together. Initialisieren Sie mit:
import together
together.api_key = "your_together_api_key"
Testen Sie die Verbindung, indem Sie Modelle auflisten oder eine einfache Abfrage senden.
Überprüfen Sie jedoch die Hardware, wenn Sie selbst hosten. Laden Sie Gewichte von Hugging Face herunter: huggingface-cli download openai/gpt-oss-120b. Verwenden Sie dann vLLM zum Bereitstellen: vllm serve openai/gpt-oss-120b.
Zusätzlich sollten Umgebungsvariablen für die Sicherheit festgelegt werden. Speichern Sie Schlüssel in .env-Dateien und laden Sie diese mit der dotenv-Bibliothek.
Im Falle von Problemen überprüfen Sie die Anbieterdokumentation auf Ratenbegrenzungen oder Authentifizierungsfehler. Diese Vorbereitung gewährleistet reibungslose API-Interaktionen.
Ihren ersten API-Aufruf an GPT-OSS tätigen
Entwickler erstellen Anfragen über den Chat-Completions-Endpunkt. Geben Sie das Modell, z. B. "openai/gpt-oss-120b", in der Payload an.
Für einen grundlegenden Aufruf bereiten Sie Nachrichten als Liste von Dictionaries vor. Jedes enthält Rolle (system, user, assistant) und Inhalt.
Hier ist ein Beispiel in Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Dies erzeugt eine Antwort, die das Konzept technisch erklärt.
Passen Sie außerdem Parameter zur Steuerung an. Die Temperatur beeinflusst die Kreativität – niedrigere Werte führen zu deterministischen Ausgaben. Top_p begrenzt die Token-Abtastung, während presence_penalty Wiederholungen verhindert.
Als Nächstes integrieren Sie Tool-Calling. Definieren Sie Tools in der Anfrage:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
Das Modell antwortet mit einem Tool-Aufruf, den Entwickler ausführen und zurückführen.
Gehen Sie jedoch sorgfältig mit Antworten um. Parsen Sie das JSON nach Inhalt, finish_reason und Nutzungsstatistiken wie Token-Anzahl.
Zusätzlich, für "Chain-of-Thought", fordern Sie mit "Think step by step." auf. Legen Sie den Denkaufwand in Systemnachrichten fest: "reasoning_effort: medium".
Experimentieren Sie mit gpt-oss-20b für schnellere Tests: Ersetzen Sie den Modellnamen in den Aufrufen.
In fortgeschrittenen Szenarien streamen Sie Antworten mit stream=True für Echtzeit-Ausgabe.
Diese Schritte bauen grundlegende Fähigkeiten auf. Integrieren Sie nun Testwerkzeuge wie Apidog.
Apidog für effizientes GPT-OSS API-Testen integrieren
Entwickler verlassen sich auf Apidog, um API-Interaktionen zu testen und zu debuggen. Dieses Tool bietet eine benutzerfreundliche Oberfläche zum Senden von Anfragen an gpt-oss-Endpunkte.
Zuerst installieren Sie Apidog von deren Website. Erstellen Sie ein neues Projekt und fügen Sie einen API-Endpunkt hinzu, wie z. B. https://openrouter.ai/api/v1/chat/completions.
Als Nächstes konfigurieren Sie die Header: Fügen Sie Authorization mit Bearer-Token und Content-Type als application/json hinzu.
Darüber hinaus erstellen Sie den Anfragetext. Verwenden Sie Apidogs JSON-Editor, um Modell, Nachrichten und Parameter einzugeben. Testen Sie beispielsweise einen gpt-oss-Aufruf zur Code-Generierung.
Apidog visualisiert Antworten und hebt Fehler oder Erfolge hervor. Es unterstützt Umgebungsvariablen zum Wechseln von API-Schlüsseln zwischen Anbietern.
Nutzen Sie jedoch Sammlungen, um Tests zu organisieren. Gruppieren Sie GPT-OSS-Abfragen nach Aufgabe, wie z. B. Reasoning oder Tool-Nutzung, und führen Sie sie in Batches aus.
Zusätzlich generiert Apidog Code-Snippets in Sprachen wie Python oder cURL aus Ihren Anfragen, was die Entwicklung beschleunigt.
Für die Zusammenarbeit teilen Sie Projekte mit Teams. Dies gewährleistet eine konsistente Prüfung von gpt-oss-Integrationen.
In der Praxis verwenden Sie Apidog, um die Token-Nutzung zu überwachen und Prompts zu optimieren, wodurch Kosten gesenkt werden.
Insgesamt steigert Apidog die Produktivität bei der Arbeit mit der GPT-OSS API.
Fortgeschrittene Nutzung: Feinabstimmung und Bereitstellung
Entwickler stimmen GPT-OSS für spezifische Domänen fein ab. Verwenden Sie die Transformers-Bibliothek von Hugging Face, um Gewichte zu laden und auf benutzerdefinierten Datensätzen zu trainieren.
Bereiten Sie beispielsweise Daten im JSONL-Format mit Prompt-Completion-Paaren vor. Führen Sie Feinabstimmungsskripte aus dem GitHub-Repo aus.
Darüber hinaus stellen Sie abgestimmte Modelle über vLLM für das API-Serving bereit. Dies unterstützt Produktionslasten mit Funktionen wie dynamischem Batching.
Als Nächstes erkunden Sie multimodale Erweiterungen. Obwohl textorientiert, integrieren Sie sie mit Vision-Modellen für Hybrid-Apps.
Achten Sie jedoch während der Feinabstimmung auf Overfitting. Verwenden Sie Validierungssets und Early Stopping.
Zusätzlich skalieren Sie mit verteilter Inferenz auf Clustern. Anbieter wie AWS bieten verwaltete Optionen an.
In agentischen Setups verketten Sie GPT-OSS mit externen APIs für Workflows wie automatisierte Forschung.
Diese Techniken erweitern die Fähigkeiten über grundlegende Aufrufe hinaus.
Best Practices, Einschränkungen und Fehlerbehebung
Entwickler befolgen Best Practices für optimale Ergebnisse. Erstellen Sie klare Prompts, verwenden Sie Few-Shot-Beispiele und iterieren Sie basierend auf den Ausgaben.
Beachten Sie außerdem Ratenbegrenzungen – überprüfen Sie die Dashboards des Anbieters, um Drosselung zu vermeiden.
Beachten Sie jedoch Einschränkungen: GPT-OSS kann halluzinieren, daher validieren Sie kritische Antworten. Es fehlen Echtzeit-Wissensaktualisierungen.
Sichern Sie zusätzlich API-Schlüssel und protokollieren Sie die Nutzung zur Kostenkontrolle.
Beheben Sie Fehler, indem Sie Fehlercodes überprüfen; 401 zeigt eine ungültige Authentifizierung an, 429 bedeutet, dass die Ratenbegrenzung erreicht wurde.
Zusammenfassend lässt sich sagen, dass Sie diese Richtlinien für eine zuverlässige Leistung einhalten sollten.
Fazit: Stärken Sie Ihre Projekte mit der GPT-OSS API
Entwickler verfügen nun über die Werkzeuge, um GPT-OSS effektiv zu integrieren. Von der Einrichtung bis zu den erweiterten Funktionen rüstet Sie dieser Leitfaden für den Erfolg aus. Experimentieren, verfeinern und innovieren Sie mit gpt-oss und Apidog, um wirkungsvolle KI-Lösungen zu schaffen.