
Hey, KI-Enthusiasten! Macht euch bereit, denn Open AI hat gerade mit seinem neuen Open-Weight-Modell, GPT-OSS-120B, eine Bombe platzen lassen, die in der KI-Community für Aufsehen sorgt. Unter der Apache 2.0 Lizenz veröffentlicht, ist dieses Kraftpaket für Schlussfolgerungen, Codierung und agentische Aufgaben konzipiert, alles während es auf einer einzigen GPU läuft. In diesem Leitfaden tauchen wir ein in das, was GPT-OSS-120B besonders macht: seine herausragenden Benchmarks, erschwingliche Preise und wie Sie es über die OpenRouter API nutzen können. Lassen Sie uns dieses Open-Source-Juwel erkunden und Sie im Handumdrehen damit coden lassen!
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!
Was ist GPT-OSS-120B?
Open AIs GPT-OSS-120B ist ein Sprachmodell mit 117 Milliarden Parametern (davon 5,1 Milliarden aktiv pro Token), das Teil ihrer neuen Open-Weight-GPT-OSS-Serie ist, neben dem kleineren GPT-OSS-20B. Es wurde am 5. August 2025 veröffentlicht und ist ein Mixture-of-Experts (MoE)-Modell, das auf Effizienz optimiert ist und auf einer einzigen NVIDIA H100 GPU oder sogar auf Consumer-Hardware mit MXFP4-Quantisierung läuft. Es wurde für Aufgaben wie komplexe Schlussfolgerungen, Codegenerierung und Werkzeugnutzung entwickelt und verfügt über ein massives 128K Token-Kontextfenster – denken Sie an 300–400 Seiten Text! Unter der Apache 2.0 Lizenz können Sie es anpassen, bereitstellen oder sogar kommerzialisieren, was es zu einem Traum für Entwickler und Unternehmen macht, die Kontrolle und Datenschutz wünschen.

Benchmarks: Wie schneidet GPT-OSS-120B ab?
Das GPT-OSS-120B ist kein Leichtgewicht, wenn es um Leistung geht. Open AIs Benchmarks zeigen, dass es ein ernstzunehmender Konkurrent für proprietäre Modelle wie das eigene o4-mini und sogar Claude 3.5 Sonnet ist. Hier ist die Zusammenfassung:
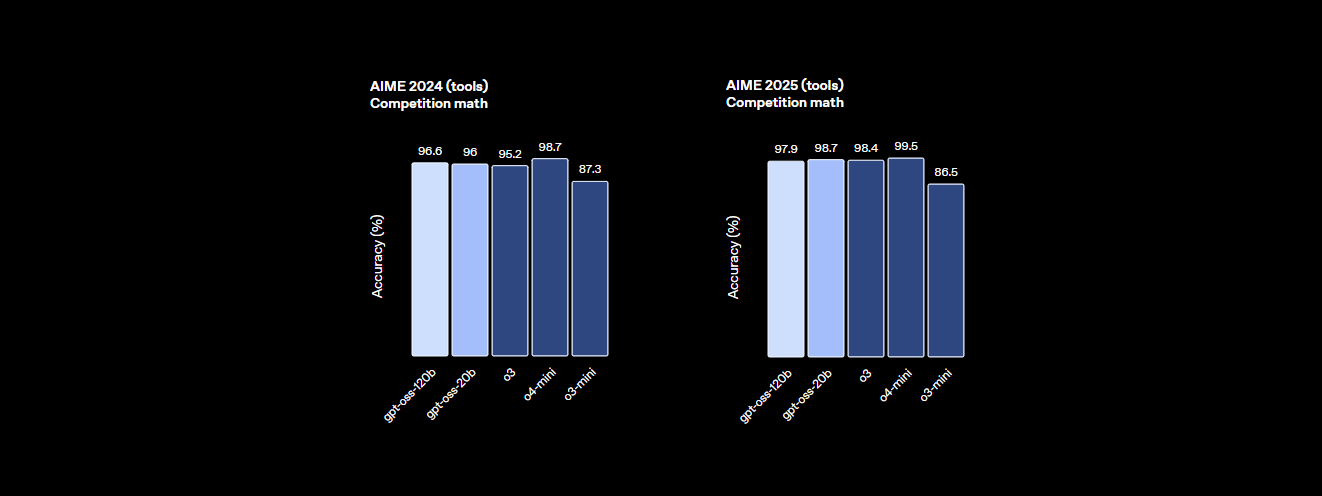
- Schlussfolgerungsfähigkeit: Es erreicht 94,2 % bei MMLU (Massive Multitask Language Understanding), knapp unter den 95,1 % von GPT-4, und erzielt 96,6 % bei AIME-Mathematikwettbewerben, womit es viele geschlossene Modelle übertrifft.
- Programmierfähigkeiten: Bei Codeforces weist es eine Elo-Bewertung von 2622 auf und erreicht eine Erfolgsquote von 87,3 % bei HumanEval für die Codegenerierung, was es zum besten Freund eines Programmierers macht.
- Gesundheit und Werkzeugnutzung: Es übertrifft o4-mini bei HealthBench für gesundheitsbezogene Anfragen und zeichnet sich bei agentischen Aufgaben wie TauBench aus, dank seiner Chain-of-Thought (CoT)-Argumentation und Werkzeugaufruf-Fähigkeiten.
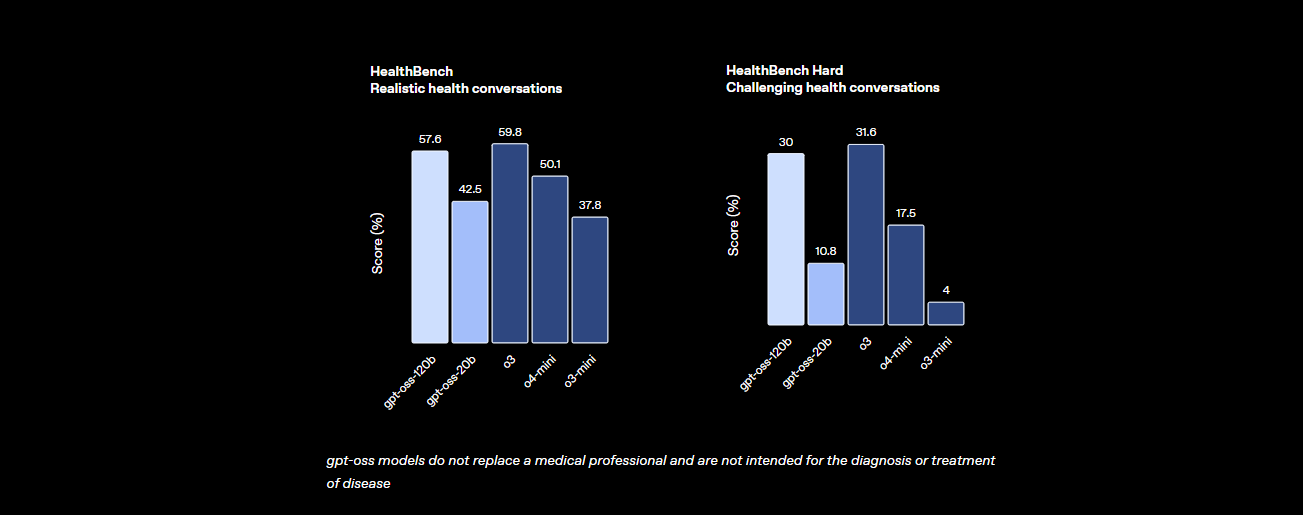
- Geschwindigkeit: Auf einer H100 GPU verarbeitet es 45 Token pro Sekunde, wobei Anbieter wie Cerebras bei hohem Bedarf bis zu 3.000 Token/Sek. erreichen. OpenRouter liefert ~500 Token/Sek. und übertrifft damit viele geschlossene Modelle.
Diese Statistiken zeigen, dass GPT-OSS-120B nahezu auf Augenhöhe mit erstklassigen proprietären Modellen ist, während es offen und anpassbar bleibt. Es ist ein Kraftpaket für Mathematik, Codierung und allgemeine Problemlösung, wobei die Sicherheit durch adversariales Fine-Tuning integriert ist, um Risiken gering zu halten.
Preise: Erschwinglich und transparent
Einer der besten Aspekte von GPT-OSS-120B? Es ist kostengünstig, besonders im Vergleich zu proprietären Modellen. Hier ist eine Aufschlüsselung der Preise bei den wichtigsten Anbietern, basierend auf aktuellen Daten für ein 131K Kontextfenster:
- Lokale Bereitstellung: Betreiben Sie es auf Ihrer eigenen Hardware (z.B. einer H100 GPU oder einem 80GB VRAM Setup) für null API-Kosten. Ein GMKTEC EVO-X2 Setup kostet ~€2000 und verbraucht weniger als 200W, perfekt für kleine Unternehmen, die Wert auf Datenschutz legen.
- Baseten: $0.10/M Eingabetoken, $0.50/M Ausgabetoken. Latenz: 0.20s, Durchsatz: 491.1 Token/Sek. Max. Ausgabe: 131K Token.
- Fireworks: $0.15/M Eingabe, $0.60/M Ausgabe. Latenz: 0.56s, Durchsatz: 258.9 Token/Sek. Max. Ausgabe: 33K Token.
- Together: $0.15/M Eingabe, $0.60/M Ausgabe. Latenz: 0.28s, Durchsatz: 131.1 Token/Sek. Max. Ausgabe: 131K Token.
- Parasail: $0.15/M Eingabe, $0.60/M Ausgabe (FP4 Quantisierung). Latenz: 0.40s, Durchsatz: 94.3 Token/Sek. Max. Ausgabe: 131K Token.
- Groq: $0.15/M Eingabe, $0.75/M Ausgabe. Latenz: 0.24s, Durchsatz: 1.065 Token/Sek. Max. Ausgabe: 33K Token.
- Cerebras: $0.25/M Eingabe, $0.69/M Ausgabe. Latenz: 0.42s, Durchsatz: 1.515 Token/Sek. Max. Ausgabe: 33K Token. Ideal für Hochgeschwindigkeitsanforderungen, erreicht in einigen Setups bis zu 3.000 Token/Sek.
Mit GPT-OSS-120B erhalten Sie hohe Leistung zu einem Bruchteil der Kosten von GPT-4 (~$20.00/M Token), wobei Anbieter wie Groq und Cerebras eine rasend schnelle Durchsatzrate für Echtzeitanwendungen bieten.
Wie man GPT-OSS-120B mit Cline über OpenRouter verwendet
Möchten Sie die Leistung von GPT-OSS-120B für Ihre Codierungsprojekte nutzen? Während Claude Desktop und Claude Code aufgrund ihrer Abhängigkeit vom Anthropic-Ökosystem keine direkte Integration mit OpenAI-Modellen wie GPT-OSS-120B unterstützen, können Sie dieses Modell problemlos mit Cline, einer kostenlosen Open-Source VS Code-Erweiterung, über die OpenRouter API verwenden. Zusätzlich hat Cursor kürzlich seine Bring Your Own Key (BYOK)-Option für Nicht-Pro-Benutzer eingeschränkt, indem Funktionen wie Agenten- und Bearbeitungsmodi hinter einem $20/Monat-Abonnement gesperrt wurden, was Cline zu einer flexibleren Alternative für BYOK-Benutzer macht. Hier erfahren Sie, wie Sie GPT-OSS-120B mit Cline und OpenRouter Schritt für Schritt einrichten.
Schritt 1: Einen OpenRouter API-Schlüssel erhalten
- Bei OpenRouter registrieren:
- Besuchen Sie openrouter.ai und erstellen Sie ein kostenloses Konto mit Google oder GitHub.
2. GPT-OSS-120B finden:
- Suchen Sie im Tab Modelle nach „gpt-oss-120b“ und wählen Sie es aus.
3. Einen API-Schlüssel generieren:
- Gehen Sie zum Abschnitt Schlüssel, klicken Sie auf API-Schlüssel erstellen, benennen Sie ihn (z.B. „GPT-OSS-Cursor“) und kopieren Sie ihn. Speichern Sie ihn sicher
Schritt 2: Cline in VS Code mit BYOK verwenden
Für uneingeschränkten BYOK-Zugriff ist Cline (eine Open-Source VS Code-Erweiterung) eine fantastische Cursor-Alternative. Es unterstützt GPT-OSS-120B über OpenRouter ohne Funktionssperren. So richten Sie es ein:
- Cline installieren:
- Öffnen Sie VS Code (code.visualstudio.com).
- Gehen Sie zum Erweiterungsbereich (
Strg+Umschalt+XoderCmd+Umschalt+X). - Suchen Sie nach „Cline“ und installieren Sie es (von nickbaumann98, github.com/cline/cline).
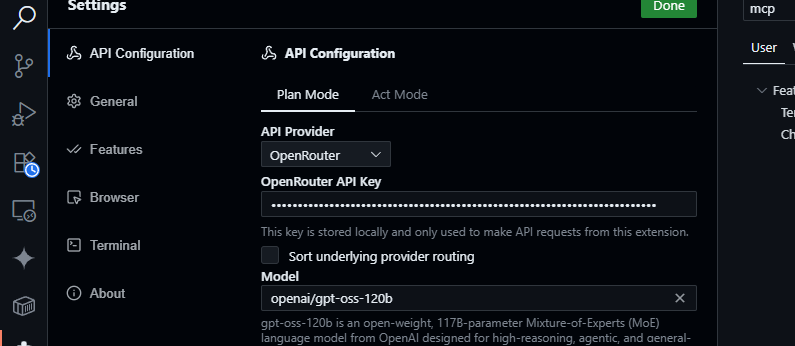
2. OpenRouter konfigurieren:
- Öffnen Sie das Cline-Panel (klicken Sie auf das Cline-Symbol in der Aktivitätsleiste).
- Klicken Sie auf das Zahnradsymbol im Cline-Panel.
- Wählen Sie OpenRouter als Anbieter.
- Fügen Sie Ihren OpenRouter API-Schlüssel ein.
- Wählen Sie
openai/gpt-oss-120bals Modell.
3. Speichern und Testen:
- Einstellungen speichern. Versuchen Sie im Cline-Chat-Panel:
Generieren Sie eine JavaScript-Funktion zum Parsen von JSON-Daten.
- Erwarten Sie eine Antwort wie:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- Testen Sie Codebasis-Abfragen:
src/api/server.js zusammenfassen
- Cline analysiert Ihr Projekt und liefert eine Zusammenfassung, indem es das 128K Kontextfenster von GPT-OSS-120B nutzt.
Warum Cline statt Cursor oder Claude?
- Keine Claude-Integration: Claude Desktop und Claude Code sind auf die Modelle von Anthropic (z.B. Claude 3.5 Sonnet) beschränkt und unterstützen aufgrund von Ökosystembeschränkungen keine OpenAI-Modelle wie GPT-OSS-120B.
- Cursors BYOK-Einschränkungen: Cursors jüngstes BYOK-Verbot für Nicht-Pro-Benutzer bedeutet, dass Sie ohne ein $20/Monat-Abonnement keinen Zugriff auf Agenten- oder Bearbeitungsmodi haben, selbst mit einem gültigen OpenRouter API-Schlüssel. Cline hat solche Beschränkungen nicht und bietet vollen Funktionszugriff kostenlos mit Ihrem API-Schlüssel.
- Datenschutz und Kontrolle: Cline sendet Anfragen direkt an OpenRouter, wodurch Server von Drittanbietern umgangen werden (im Gegensatz zu Cursors AWS-Routing), was den Datenschutz verbessert.
Tipps zur Fehlerbehebung
- Ungültiger API-Schlüssel? Überprüfen Sie Ihren Schlüssel im OpenRouter-Dashboard und stellen Sie sicher, dass er aktiv ist.
- Modell nicht verfügbar? Überprüfen Sie die Modellliste von OpenRouter nach openai/gpt-oss-120b. Falls es fehlt, versuchen Sie Anbieter wie Fireworks AI oder kontaktieren Sie den OpenRouter-Support.
- Langsame Antworten? Stellen Sie sicher, dass Ihre Internetverbindung stabil ist. Für eine schnellere Leistung sollten Sie leichtere Modelle wie GPT-OSS-20B in Betracht ziehen.
- Cline-Fehler? Aktualisieren Sie Cline über den Erweiterungsbereich und überprüfen Sie die Protokolle im Ausgabebereich von VS Code.
Warum GPT-OSS-120B verwenden?
Das Modell GPT-OSS-120B ist ein Wendepunkt für Entwickler und Unternehmen und bietet eine überzeugende Mischung aus Leistung, Flexibilität und Kosteneffizienz. Hier sind die Gründe, warum es herausragt:
- Open-Source-Freiheit: Unter der Apache 2.0 Lizenz können Sie GPT-OSS-120B ohne Einschränkungen feinabstimmen, bereitstellen oder kommerzialisieren, was Ihnen die volle Kontrolle über Ihre KI-Workflows gibt.
- Kostenersparnis: Betreiben Sie es lokal auf einer einzelnen H100 GPU oder Consumer-Hardware (80GB VRAM) für null API-Kosten. Über OpenRouter sind die Preise mit ~$0.50/M Eingabetoken und ~$2.00/M Ausgabetoken äußerst wettbewerbsfähig, ein Bruchteil der ~$20.00/M Token von GPT-4, was bis zu 90% Ersparnis für Vielnutzer bietet. Andere Anbieter wie Groq ($0.15/M Eingabe, $0.75/M Ausgabe) und Cerebras ($0.25/M Eingabe, $0.69/M Ausgabe) halten die Kosten ebenfalls niedrig.
- Leistung: Es erreicht nahezu Parität mit OpenAIs o4-mini und erzielt 94,2 % bei MMLU, 96,6 % bei AIME-Mathematik und 87,3 % bei HumanEval für die Codierung. Sein 128K Token-Kontextfenster (300–400 Seiten) verarbeitet massive Codebasen oder Dokumente mit Leichtigkeit.
- Chain-of-Thought (CoT) Reasoning: Die vollständige CoT-Transparenz des Modells ermöglicht es Ihnen, seine Schritt-für-Schritt-Argumentation zu verfolgen, was das Debuggen von Ausgaben und das Erkennen von Verzerrungen oder Fehlern erleichtert. Sie können den Argumentationsaufwand (niedrig, mittel, hoch) über System-Prompts (z.B. „Reasoning: high“) für Aufgaben wie komplexe Mathematik oder Codierung anpassen, um Geschwindigkeit und Tiefe auszugleichen. Dieses unüberwachte CoT-Design unterstützt Forscher bei der Überwachung des Modellverhaltens ohne direkte Aufsicht, was Vertrauen und Sicherheit erhöht.
- Agentische Fähigkeiten: Die native Unterstützung für die Nutzung von Tools, wie Web-Browsing und Python-Code-Ausführung, macht es ideal für agentische Workflows. Es kann mehrere Tool-Aufrufe verketten (z.B. 28 aufeinanderfolgende Websuchen in einer Demo) für komplexe Aufgaben wie Datenaggregation oder Automatisierung.
- Datenschutz: Hosten Sie es vor Ort (z.B. über Dell Enterprise Hub) für vollständige Datenkontrolle, perfekt für Unternehmen oder datenschutzbewusste Benutzer.
- Flexibilität: Kompatibel mit OpenRouter, Fireworks AI, Cerebras und lokalen Setups wie Ollama oder LM Studio, läuft es auf verschiedener Hardware, von RTX GPUs bis Apple Silicon.
Der Community-Buzz auf X hebt seine Geschwindigkeit (bis zu 1.515 Token/Sek. auf Cerebras) und seine Programmierfähigkeiten hervor, wobei Entwickler seine Fähigkeit lieben, Multi-Datei-Projekte zu handhaben, und seine Open-Weight-Natur für die Anpassung. Egal, ob Sie KI-Agenten bauen oder für Nischenaufgaben feinabstimmen, GPT-OSS-120B liefert einen unübertroffenen Wert.
Fazit
Open AIs GPT-OSS-120B ist ein revolutionäres Open-Weight-Modell, das erstklassige Leistung mit kostengünstiger Bereitstellung verbindet. Seine Benchmarks konkurrieren mit proprietären Modellen, seine Preise sind geldbörsenfreundlich und es lässt sich leicht mit Cursor oder Cline über die OpenRouter API integrieren. Egal, ob Sie codieren, debuggen oder komplexe Probleme lösen, dieses Modell liefert. Probieren Sie es aus, experimentieren Sie mit seinem 128K Kontextfenster und teilen Sie uns Ihre coolen Anwendungsfälle in den Kommentaren mit – ich bin ganz Ohr!
Weitere Details finden Sie im Repo unter github.com/openai/gpt-oss oder in der Ankündigung von Open AI unter openai.com.
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!