
Entwickler, die intelligente Anwendungen erstellen, stehen oft vor der Herausforderung, modernste Modelle wie GPT-5.2 in ihre Arbeitsabläufe zu integrieren. Von OpenAI als die neueste Grenze der KI-Fähigkeiten veröffentlicht, verschiebt GPT-5.2 die Grenzen in den Bereichen Codegenerierung, Bildwahrnehmung und mehrstufiges Schlussfolgern. Sie integrieren es nicht nur zum Experimentieren, sondern um robuste, skalierbare Lösungen bereitzustellen, die komplexe professionelle Aufgaben bewältigen. Die Tiefe der API – von der Variantenauswahl bis zur Parameterabstimmung – erfordert jedoch einen strukturierten Ansatz. Hier kommen Tools wie Apidog ins Spiel, die das API-Design, -Testen und die Dokumentation vereinfachen, damit Sie sich auf Innovation statt auf Boilerplate konzentrieren können.
GPT-5.2 verstehen: Kernfunktionen und ihre Bedeutung für Entwickler
Sie wählen GPT-5.2, weil es Vorgänger in Präzision und Effizienz übertrifft. OpenAI positioniert es als eine Suite, die für Wissensarbeit optimiert ist, wo sie in Benchmarks modernste Ergebnisse erzielt. Zum Beispiel erreicht es 80,0 % bei SWE-Bench Verified für Codierungsaufgaben, was bedeutet, dass Sie genauere Softwarelösungen mit weniger Iterationen generieren. Darüber hinaus halbieren seine visuellen Fähigkeiten die Fehlerraten bei der Diagrammanalyse und ermöglichen Anwendungen wie automatisierte Datenvisualisierungstools.
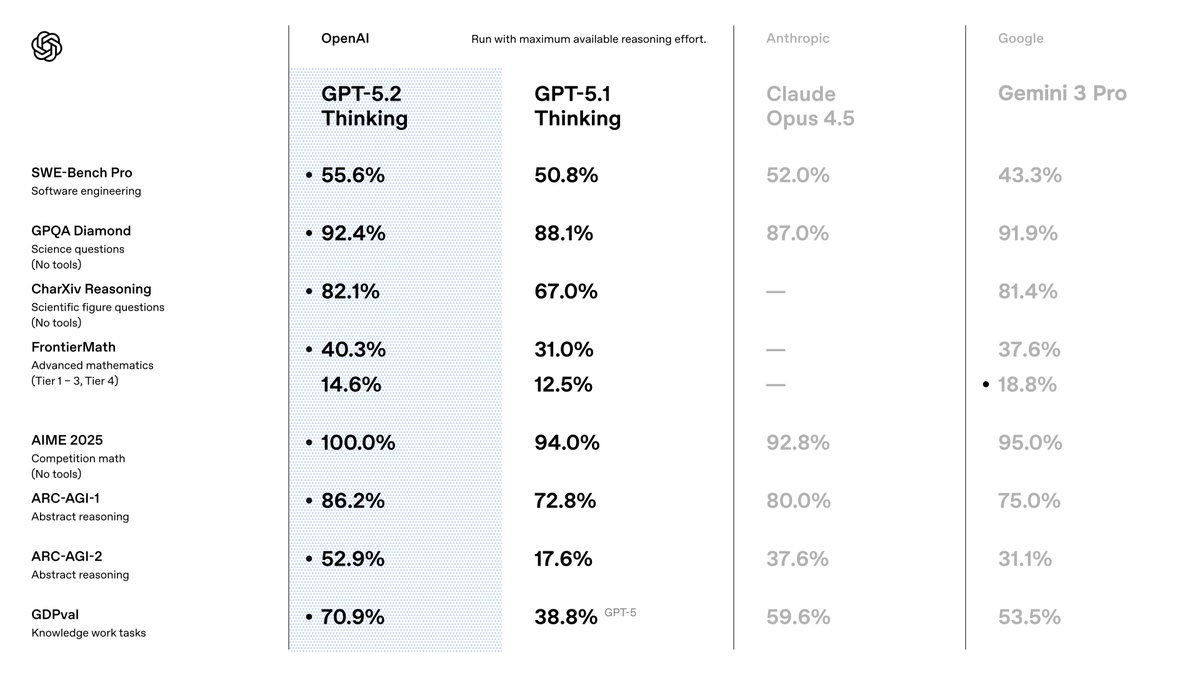
Beim Übergang von GPT-5.1 bemerken Sie Verbesserungen in der Faktizität – 30 % weniger Halluzinationen bei suchgestützten Abfragen – und im Umgang mit langen Kontexten, mit nahezu perfekter Genauigkeit bis zu 256k Tokens. Diese Funktionen sind wichtig, da sie den Nachbearbeitungsbedarf in Ihren Pipelines reduzieren. Sie profitieren auch von einer verbesserten Tool-Aufrufe mit 98,7 % in Multi-Turn-Benchmarks, was agentenbasierte Systeme optimiert.
Für API-Benutzer integriert sich GPT-5.2 nahtlos in bestehende OpenAI-Ökosysteme. Sie greifen über die Chat Completions oder Responses API darauf zu und unterstützen Parameter wie die Temperatur zur Kreativitätskontrolle. Der Erfolg hängt jedoch von der Wahl der richtigen Variante ab. Diese werden wir als Nächstes untersuchen.
GPT-5.2-Varianten erkunden: Leistung an Ihre Bedürfnisse anpassen
GPT-5.2 bietet Varianten, die Geschwindigkeit, Tiefe und Kosten ausgleichen und es Ihnen ermöglichen, das Modellverhalten an die Aufgabenanforderungen anzupassen. Im Gegensatz zu monolithischen Modellen bieten diese Optionen – Instant, Thinking und Pro – Flexibilität. Sie aktivieren sie über spezifische Modell-IDs in Ihren API-Anfragen.
Beginnen Sie mit GPT-5.2 Instant (gpt-5.2-chat-latest). Diese Variante priorisiert niedrige Latenz für alltägliche Interaktionen, wie z.B. schnelle Informationssuche oder technisches Schreiben. Entwickler bevorzugen sie für Chatbots oder Echtzeit-Assistenten, bei denen Antwortzeiten unter 200 ms unerlässlich sind. Sie bewältigt Übersetzungen und Anleitungen mit verfeinerter Genauigkeit, wodurch sie ideal für kundenorientierte Apps ist.
Betrachten Sie als Nächstes GPT-5.2 Thinking (gpt-5.2). Diese Variante setzen Sie für tiefere Analysen ein, wie z.B. die Zusammenfassung langer Dokumente oder die logische Planung. Ihre Schlussfolgerungs-Engine glänzt in Mathematik und Entscheidungsfindung und löst 40,3 % der FrontierMath-Probleme. Verwenden Sie hier den Parameter reasoning – setzen Sie ihn auf 'high' oder 'xhigh' –, um die Ausgabequalität bei komplexen Abfragen zu verstärken. In Projektmanagement-Tools orchestriert es beispielsweise mehrstufige Workflows mit minimalen Fehlern.
Schließlich zielt GPT-5.2 Pro (gpt-5.2-pro) auf Spitzenleistung in anspruchsvollen Bereichen ab. Es erreicht 93,2 % bei GPQA Diamond für wissenschaftliche Fragen und glänzt im Programmieren mit weniger Randfallfehlern. Sie reservieren dies für F&E-Prototypen oder hochsensible Umgebungen, wie z.B. die Finanzmodellierung, wo Präzision die Geschwindigkeit überwiegt.
Das von Ihnen geteilte Bild hebt Umschalter für diese hervor, einschließlich "Max", "Mini", "High", "Low" und "Fast" Modi. Diese stimmen mit den Schlussfolgerungsanstrengungen überein: 'none' für sofortige Antworten, 'low' für grundlegende Aufgaben, bis zu 'xhigh' für eine umfassende Analyse. Sie schalten sie über API-Parameter um, um sicherzustellen, dass sich das Modell dynamisch anpasst. Wechseln Sie beispielsweise zu "Max High Fast" für ausgewogene Codierungssitzungen, die Geschwindigkeit priorisieren, ohne an Tiefe einzubüßen.
Durchdachte Variantenauswahl optimiert die Ressourcennutzung. Jetzt richten Sie den Zugang für diese Aufrufe ein.
Ihren GPT-5.2 API-Zugang einrichten: Authentifizierung und Umgebungsvorbereitung
Sie beginnen die Integration, indem Sie API-Anmeldeinformationen sichern. OpenAI benötigt einen API-Schlüssel, den Sie über das Plattform-Dashboard generieren. Navigieren Sie zu platform.openai.com, erstellen Sie bei Bedarf ein Konto und stellen Sie einen Schlüssel unter "API Keys" aus.
Als Nächstes installieren Sie das OpenAI Python SDK. Führen Sie pip install openai in Ihrem Terminal aus. Diese Bibliothek übernimmt HTTP-Anfragen, Wiederholungsversuche und Streaming out of the box. Für Node.js-Benutzer bietet npm install openai ähnliche Funktionalität. Sie importieren es wie folgt:
from openai import OpenAI
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Testen Sie die Konnektivität mit einer einfachen Vervollständigung:
response = client.chat.completions.create(
model="gpt-5.2-chat-latest",
messages=[{"role": "user", "content": "Erklären Sie kurz die Quantenverschränkung."}]
)
print(response.choices[0].message.content)
Dieser Aufruf überprüft die Einrichtung. Wenn Fehler auftreten, überprüfen Sie die Ratenbegrenzungen (Standard 3.500 RPM für Tier 1) oder die Gültigkeit des Schlüssels. Sie konfigurieren auch die Basis-URL für benutzerdefinierte Endpunkte, wie /compact für erweiterte Kontexte: client = OpenAI(base_url="https://api.openai.com/v1", api_key=...).
Mit den Grundlagen können Sie nun die Anforderungserstellung erkunden.
Effektive GPT-5.2 API-Anfragen erstellen: Parameter und Best Practices
Sie erstellen Anfragen über den Chat Completions-Endpunkt (/v1/chat/completions). Die Nutzlast umfasst model, messages und optionale Parameter wie temperature (0-2 für Determinismus) und max_tokens (bis zu 4096 Ausgabe).
Für GPT-5.2-Spezifika integrieren Sie reasoning_effort, um die Tiefe zu steuern:
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Schreiben Sie eine Python-Funktion für die Fibonacci-Folge."}],
reasoning_effort="high", # Entspricht dem Schalter "Max High"
temperature=0.7,
max_tokens=500
)
Dies generiert sauberen, kommentierten Code – 80 % benchmark-konform. Sie verfeinern durch Iteration: Fragen Sie nach "Für Leistung optimieren".
Für visuelle Aufgaben analysieren Sie Screenshots. Laden Sie einen UI-Mockup hoch und fragen Sie: "Schlagen Sie Verbesserungen der Barrierefreiheit vor." GPT-5.2 identifiziert Probleme wie Farbkontrast und nutzt dabei seine halbierte Fehlerrate.
In Multi-Tool-Agenten definieren Sie Funktionen für Datenbankabfragen. GPT-5.2 orchestriert Aufrufe und reduziert die Latenz in Mega-Agenten mit über 20 Tools.
Diese Beispiele demonstrieren Vielseitigkeit. Fehler treten jedoch auf – behandeln Sie sie mit Wiederholungsversuchen und Fallbacks.
GPT-5.2 mit Apidog integrieren: Testen und Dokumentation vereinfachen
Apidog transformiert die Verwaltung Ihrer GPT-5.2 API-Workflows. Als All-in-One-Plattform unterstützt es OpenAPI-Spezifikationsimporte, Anforderungs-Erstellung und automatisiertes Testen. Sie importieren das OpenAI-Schema in Apidog und entwerfen dann Sammlungen für GPT-5.2-Aufrufe.
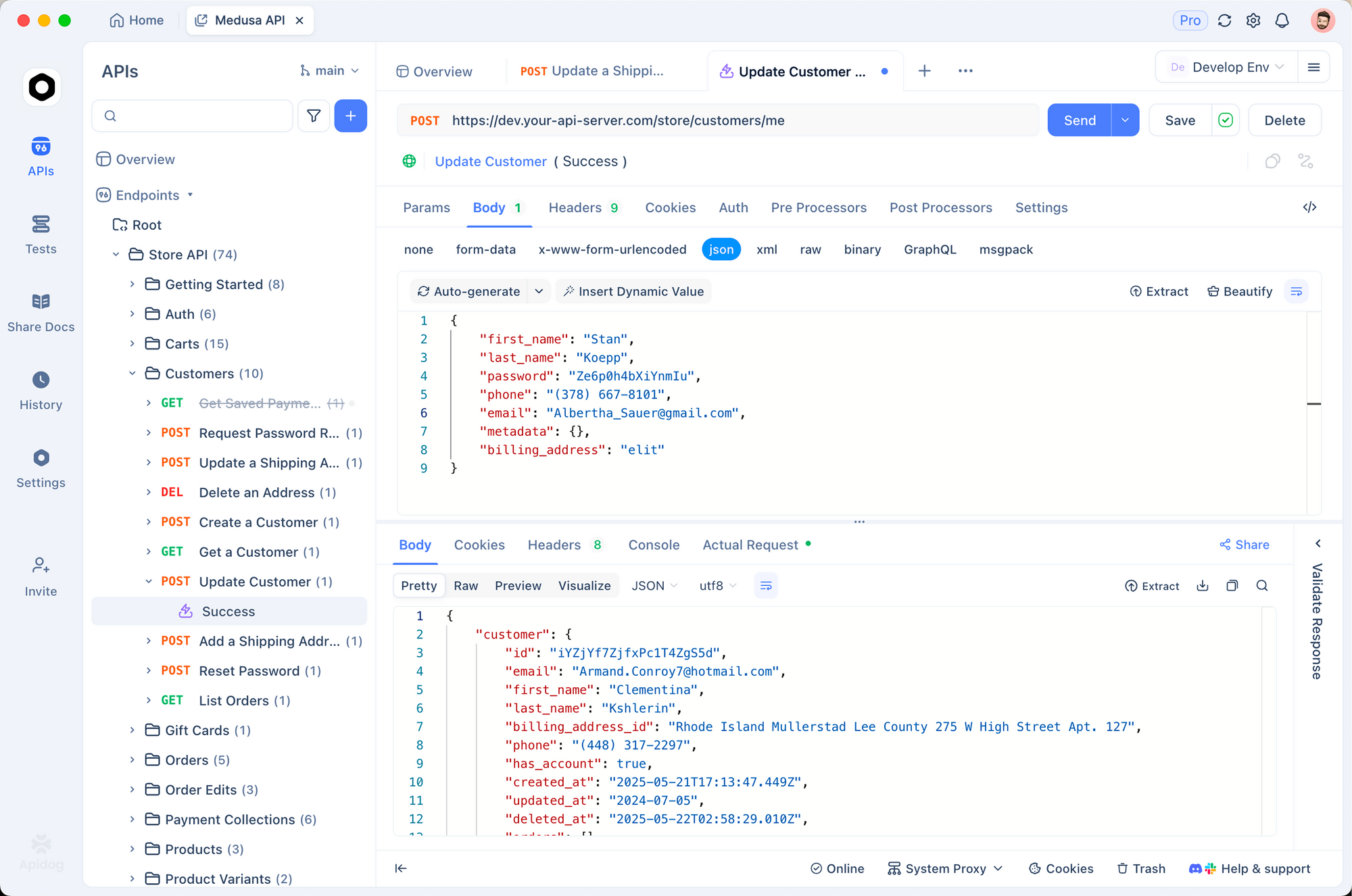
Beginnen Sie mit der Erstellung eines neuen Projekts in Apidog. Fügen Sie eine HTTP-Anfrage an https://api.openai.com/v1/chat/completions hinzu, legen Sie Header fest (Authorization: Bearer IHR_SCHLÜSSEL, Content-Type: application/json) und fügen Sie einen Beispieltext ein. Schalten Sie Variablen für Modelle wie "gpt-5.2-pro" um, um die Ausgaben nebeneinander zu vergleichen.
Apidogs Stärke liegt in seinem Mocking-Server. Sie generieren gefälschte Antworten, die die JSON-Struktur von GPT-5.2 nachahmen, ideal für die Offline-Entwicklung. Simulieren Sie beispielsweise eine "Max Extra High"-Antwort mit detaillierten Begründungsspuren. Führen Sie Tests mit Assertions zu Token-Zählungen oder Halluzinationsraten durch.

Dokumentieren Sie außerdem Ihre API mit dem integrierten Editor von Apidog. Erstellen Sie interaktive Dokumentationen, die Kollegen verwenden können, um Endpunkte zu erkunden. Exportieren Sie in Postman oder HAR für Portabilität. In der Produktion überwacht Apidog Aufrufe und warnt bei Anomalien wie hoher Latenz in "Low Fast"-Modi.
Durch die Integration von Apidog in Ihren Prozess beschleunigen Sie die Iteration. Laden Sie es kostenlos herunter und importieren Sie Ihre erste GPT-5.2-Anfrage – erleben Sie den Unterschied in wenigen Minuten.
GPT-5.2 API-Preise: Kosten und Leistung strategisch ausbalancieren
Sie können die Preisgestaltung bei der Skalierung von GPT-5.2-Anwendungen nicht ignorieren. OpenAI strukturiert die Kosten pro Million Token, mit Staffeln, die das Nutzungsvolumen widerspiegeln. Für GPT-5.2 Instant (gpt-5.2-chat-latest) erwarten Sie 1,75 $ pro 1 Mio. Eingabe-Tokens und 14 $ pro 1 Mio. Ausgabe-Tokens. Zwischengespeicherte Eingaben sinken auf 0,175 $ – eine Ersparnis von 90 % – was wiederholte Kontexte fördert.
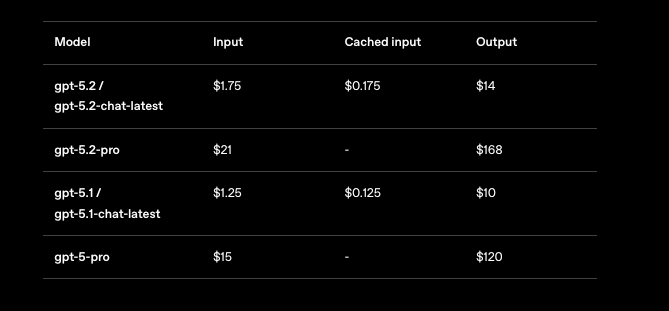
GPT-5.2 Thinking (gpt-5.2) spiegelt diese Raten wider, wodurch es für ausgewogene Aufgaben kostengünstig ist. GPT-5.2 Pro (gpt-5.2-pro) verlangt jedoch mehr: 21 $ pro 1 Mio. Eingabe- und 168 $ pro 1 Mio. Ausgabe-Tokens. Dieser Premium-Preis spiegelt seine überlegene Genauigkeit bei professionellen Abfragen wider, aber Sie bewerten den ROI sorgfältig.
Insgesamt erweist sich GPT-5.2 als token-effizient und senkt oft die Gesamtausgaben im Vergleich zu GPT-5.1 für qualitativ hochwertige Ausgaben. Sie verfolgen dies über den Nutzungsanalysator des Dashboards. Für Unternehmen verhandeln Sie benutzerdefinierte Staffeln. Tools wie Apidog helfen bei der Kostenschätzung, indem sie simulierte Token-Flüsse protokollieren.
Mit diesen Zahlen gehen Sie zu praktischen Beispielen über.
Praktische Beispiele: Codegenerierung und visuelle Aufgaben mit GPT-5.2
Sie wenden GPT-5.2 in konkreten Szenarien an. Betrachten Sie die Codegenerierung: Fordern Sie eine React-Komponente mit Zustandsverwaltung an.
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Erstellen Sie eine React-Aufgabenliste mit useReducer."}],
reasoning_effort="medium"
)
Die Ausgabe liefert sauberen, kommentierten Code – 80 % benchmark-konform. Sie verfeinern durch Iteration: Fragen Sie nach "Für Leistung optimieren".
Für visuelle Aufgaben analysieren Sie Screenshots. Laden Sie einen UI-Mockup hoch und fragen Sie: "Schlagen Sie Verbesserungen der Barrierefreiheit vor." GPT-5.2 identifiziert Probleme wie Farbkontrast und nutzt dabei seine halbierte Fehlerrate.
In Multi-Tool-Agenten definieren Sie Funktionen für Datenbankabfragen. GPT-5.2 orchestriert Aufrufe und reduziert die Latenz in Mega-Agenten mit über 20 Tools.
Diese Beispiele demonstrieren Vielseitigkeit. Fehler treten jedoch auf – behandeln Sie sie mit Wiederholungsversuchen und Fallbacks.
Fehler und Randfälle bei GPT-5.2 API-Aufrufen behandeln
Sie stoßen auf Ratenbegrenzungen oder ungültige Parameter. Umschließen Sie Aufrufe in try-except:
try:
response = client.chat.completions.create(...)
except openai.RateLimitError:
time.sleep(60) # Rückzug
response = client.chat.completions.create(...)
Bei Halluzinationen überprüfen Sie mit Suchwerkzeugen. In langen Kontexten verwenden Sie /compact, um Historien zu komprimieren. Überwachen Sie auf Verzerrungen in sensiblen Anwendungen und wenden Sie Filter an.
Apidog hilft hier: Skript-Tests für Fehlerszenarien, um die Widerstandsfähigkeit zu gewährleisten.
Fortgeschrittene Optimierungen: GPT-5.2 für die Produktion skalieren
Sie skalieren, indem Sie Prompts feinabstimmen und die Assistants API für persistente Threads verwenden. Implementieren Sie Caching für wiederholte Eingaben. Für globale Anwendungen leiten Sie über Edge-Server weiter.
Integrieren Sie mit Frameworks wie LangChain: Verknüpfen Sie GPT-5.2 mit Vektorspeichern für RAG-Systeme.
Bleiben Sie schließlich auf dem Laufenden – OpenAI iteriert schnell.
Fazit: Die GPT-5.2 API beherrschen und die Zukunft gestalten
Sie verfügen nun über die Werkzeuge, um GPT-5.2 effektiv zu nutzen. Von der Variantenauswahl bis zum Apidog-gestützten Testen wenden Sie diese Schritte an, um Ihre Projekte zu verbessern. Die Preisgestaltung bleibt für den durchdachten Einsatz zugänglich und erschließt Funktionen, die einst Laboren vorbehalten waren.
Experimentieren Sie noch heute: Prototypen Sie einen GPT-5.2-Agenten und messen Sie die Vorteile. Teilen Sie Ihre Builds in den Kommentaren – welche Herausforderungen stellen sich Ihnen? Für tiefere Einblicke erkunden Sie die OpenAI-Dokumentation. Bauen Sie mutig.