
Fortschritte erfolgen mit zunehmender Geschwindigkeit, und GPT-5.2 ist OpenAIs jüngstes Zeugnis für unermüdliche Innovation. Dieses am 11. Dezember 2025 veröffentlichte Modell verschiebt die Grenzen in den Bereichen allgemeine Intelligenz, Langkontextverarbeitung und insbesondere bei Kodierungsaufgaben. Ingenieure und Entwickler stehen nun vor einem Werkzeug, das nicht nur assistiert, sondern komplexe Arbeitsabläufe antizipiert.
Die Architektur von GPT-5.2: Ein Sprung in der Transformer-Effizienz
OpenAI-Ingenieure haben GPT-5.2 entwickelt, um Intelligenz ohne proportionalen Rechenaufwand zu skalieren. Im Kern verwendet das Modell eine verbesserte Transformer-Architektur, die Mixture-of-Experts (MoE)-Schichten für spärliche Aktivierung integriert. Dieser Ansatz aktiviert pro Token nur relevante Subnetzwerke, wodurch die Inferenzlatenz im Vergleich zur menschlichen Expertenleistung bei GDPval-Aufgaben um das bis zu 11-fache reduziert wird. Folglich verarbeiten Entwickler größere Datensätze schneller, was die Echtzeit-Code-Generierung in IDEs ermöglicht.
Darüber hinaus integriert GPT-5.2 fortschrittliche Positionskodierungen, die Kontextfenster auf 256k Tokens mit nahezu perfekter Wiedergabe erweitern. Traditionelle Modelle scheitern über 128k aufgrund von Aufmerksamkeitsverdünnung; GPT-5.2s /compact-Endpunkt komprimiert jedoch Einbettungen dynamisch, wodurch die semantische Treue erhalten bleibt. In Kodierungsszenarien bedeutet dies, ganze Repositories ohne Trunkierung zu analysieren. Wenn beispielsweise ältere Codebasen refaktorisiert werden, behält das Modell Variablenbereiche über Dateien hinweg bei und vermeidet die häufigen Fallstricke fragmentierten Kontexts.
Sicherheitsmechanismen sind tief in die Architektur eingebettet. GPT-5.2 verwendet konstitutionelle KI-Prinzipien, bei denen Belohnungsmodelle Halluzinationen während des Fine-Tunings bestrafen. Infolgedessen verbessert sich die Faktizität gegenüber GPT-5.1 Thinking bei deanonymisierten Abfragen um 30 %. Entwickler profitieren direkt: Generierte Code-Snippets enthalten weniger Syntaxfehler oder logische Inkonsistenzen, was die Debugging-Zyklen strafft.
Im Übergang zu praktischen Anwendungen zeichnet sich GPT-5.2 bei multimodalen Aufgaben aus. Seine Vision-Fähigkeiten halbieren die Fehlerraten beim Diagramm-Reasoning, wodurch es UML-Diagramme oder ERDs aus Screenshots interpretieren kann. Diese Integration erweist sich als unschätzbar wertvoll für API-Designer, die Endpunkte vor der Implementierung visuell skizzieren.
Die Kodierungsvarianten von GPT-5.2 im Detail: Zugeschnitten auf jeden Workflow
GPT-5.2 erscheint nicht als Monolith, sondern als Suite von Varianten, die jeweils für spezifische Kodierungsanforderungen optimiert sind. Obwohl die offizielle Veröffentlichung Instant-, Thinking- und Pro-Tiers hervorhebt, entwickelt sich die kodierungsfokussierte Codex-Linie innerhalb dieser weiter und manifestiert sich als spezialisierte Konfigurationen wie Codex Max und Mini. Diese schöpfen aus dem MoE-Backbone des Modells und weisen Experten für Syntax-Parsing, algorithmische Optimierung und die Übersetzung von natürlicher Sprache in Code zu.
Betrachten Sie GPT-5.2 Codex Max, das Flaggschiff für Projekte auf Unternehmensebene. Diese Variante nutzt die volle Pro-Level-Reasoning mit xhigh-Aufwand und erreicht 55,6 % auf SWE-Bench Pro – einem Benchmark, der reale GitHub-Probleme simuliert. Entwickler aktivieren sie für End-to-End-Korrekturen, bei denen sie autonom debuggt, refaktorisiert und bereitstellt. Im Gegensatz dazu priorisiert GPT-5.2 Codex Mini Geschwindigkeit und liefert Ausgaben mit Latenzen im Sub-Sekundenbereich für leichte Aufgaben wie die Snippet-Generierung. Es eignet sich für Rapid Prototyping, wo schnelle Iterationen wichtiger sind als eine erschöpfende Analyse.
Andere Konfigurationen optimieren die Kompromisse zwischen Qualität und Geschwindigkeit. GPT-5.2 Codex Max High gleicht Tiefe mit moderater Geschwindigkeit aus und ist ideal für die Feature-Implementierung in mittelgroßen Teams. Währenddessen entfernt GPT-5.2 Codex Low Fast nicht-essentielle Experten und konzentriert sich auf Boilerplate-Code wie RESTful-Endpunkte. Diese Variante glänzt in CI/CD-Pipelines und generiert Tests 40 % schneller als GPT-5.1-Äquivalente.
Für Umgebungen mit hohen Anforderungen verwendet GPT-5.2 Codex Max Extra High erweiterte Reasoning-Ketten und übertrifft bei FrontierMath-Benchmarks mit 40,3 %. Es bewältigt abstraktes Reasoning in Code, wie die Optimierung von Quantenalgorithmen oder Finanzmodellen. Auf der Effizienzseite integriert GPT-5.2 Codex Medium Fast Caching für wiederholte Abfragen, wodurch die Kosten für zwischengespeicherte Eingaben um 90 % gesenkt werden.
Entwickler wählen Varianten über API-Parameter aus: gpt-5.2-pro für Max-Tiers oder gpt-5.2-chat-latest für Instant-Derivate. Jede unterstützt Tool-Calling mit 98,7 % Genauigkeit auf Tau2-bench und ermöglicht eine nahtlose Integration mit externen Bibliotheken. Während wir als Nächstes Benchmarks untersuchen, zeigen diese Varianten quantifizierbare Vorteile gegenüber ihren Vorgängern.
Benchmark-Aufschlüsselung: Wie GPT-5.2 Kodierungsstandards neu definiert
Benchmarks liefern konkrete Beweise für die Überlegenheit von GPT-5.2, insbesondere in Kodierungsbereichen. Auf SWE-Bench Verified erreicht das Modell 80,0 %, eine Steigerung von 3,7 % gegenüber den 76,3 % von GPT-5.1. Diese Metrik bewertet gelöste GitHub-Probleme, wobei GPT-5.2 Codex Max autonom Schwachstellen in Produktionscodebasen behebt. Zum Beispiel identifiziert es Race Conditions in gleichzeitigen Python-Skripten und schlägt threadsichere Alternativen mit minimaler Störung vor.
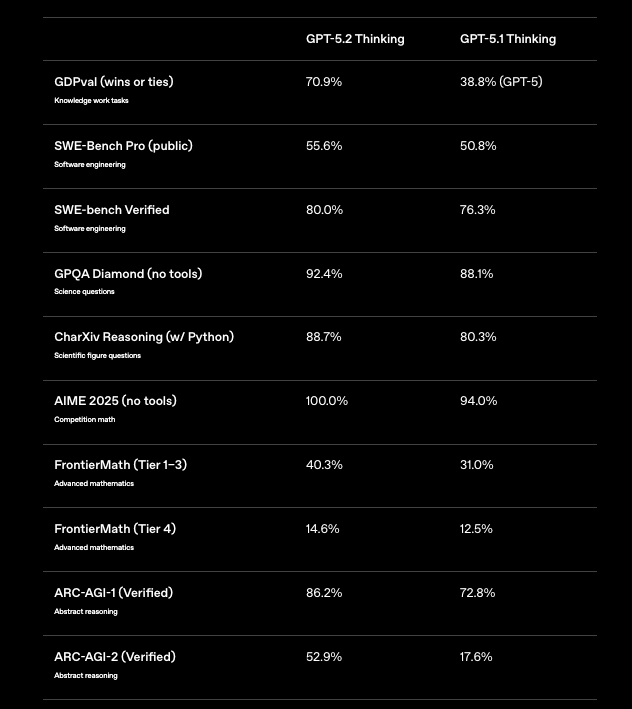
Darüber hinaus erreicht GPQA Diamond eine Genauigkeit von 92,4 % und brilliert bei Programmierfragen auf Graduiertenniveau. GPT-5.2 folgert algorithmische Beweise und generiert verifizierte Lösungen durch integrierte Python-Ausführung. Im Vergleich zu GPT-5.1s 88,1 % führt diese Fehlerreduzierung zu weniger Produktionsrücknahmen für Entwickler.
Im Bereich der visionsgestützten Codierung halbiert GPT-5.2 die Fehler beim Verständnis von Software-Schnittstellen. Es analysiert GUI-Mockups, um Frontend-Code in React oder SwiftUI automatisch zu generieren, wobei pixelgenaue Layouts beibehalten werden. Diese Fähigkeit erstreckt sich auf die Datenwissenschaft: Bei CharXiv Reasoning mit Python erreicht es 88,7 % und automatisiert ETL-Pipelines aus visualisierten Datensätzen.
Benchmarks für abstraktes Reasoning unterstreichen seinen Vorsprung zusätzlich. ARC-AGI-1 erreicht 86,2 % und demonstriert Mustererkennung in neuartigen Kodierungsrätseln, wie der Entwicklung von Kompressionsalgorithmen aus unvollständigen Spezifikationen. GPT-5.2 Codex High Fast verarbeitet diese in unter 5 Sekunden und übertrifft menschliche Experten bei GDPval mit einer Gewinnrate von 70,9 %.
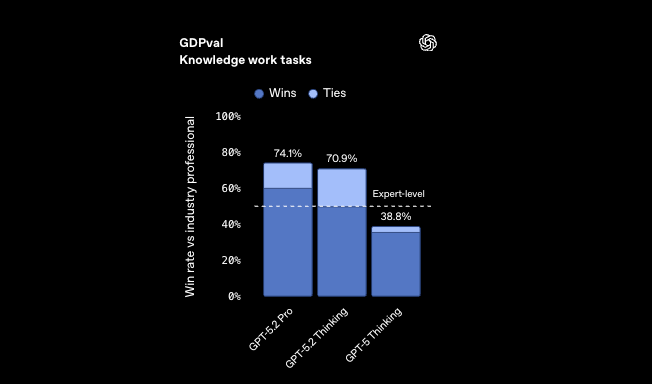
Im Übergang zu den wirtschaftlichen Auswirkungen führt die Effizienz von GPT-5.2 zu einer über 11-fachen Geschwindigkeit und weniger als 1 % Kosten im Vergleich zu Fachleuten bei Tabellenkalkulationsaufgaben – 68,4 % Genauigkeit in Szenarien des Investmentbankings. Entwickler nutzen dies zur Automatisierung von Finanz-APIs, wo Präzision auf Geschwindigkeit trifft.
Entscheidend ist, dass diese Gewinne aus einem verfeinerten Training auf vielfältigen Korpora stammen, einschließlich 10-mal mehr Code-Repositories als GPT-5.1. Herausforderungen bleiben jedoch bestehen: Randfälle in ressourcenarmen Sprachen wie Rust zeigen eine Varianz von 5-10 %. OpenAI begegnet dem durch fortlaufendes Fine-Tuning und verspricht vierteljährliche Updates.
Integration von GPT-5.2 mit Apidog: API-Entwicklung optimieren
Die API-Entwicklung erfordert Präzision, und GPT-5.2 passt hervorragend zu Apidog, einer robusten Plattform für Design, Test und Dokumentation. Apidogs OpenAPI 3.0-Unterstützung harmoniert perfekt mit GPT-5.2s Tool-Calling, wodurch Entwickler Schema-Definitionen aus natürlicher Sprache generieren können. Beschreiben Sie beispielsweise einen Benutzerauthentifizierungs-Endpunkt, und GPT-5.2 gibt YAML-Spezifikationen aus; Apidog visualisiert und mockt diese dann sofort.
Darüber hinaus validiert Apidogs Testsuite GPT-5.2-generierten Code anhand realer Payloads. Laden Sie eine Codex Max-Ausgabe für eine E-Commerce-API hoch, und Apidog führt automatisierte Assertions aus, die Übersehene Ratenbegrenzungen kennzeichnen. Diese Synergie reduziert die Integrationszeit um 50 %, da Entwickler ohne Werkzeugwechsel iterieren können.
In der Praxis beginnen Sie mit GPT-5.2 Thinking für die Endpunktlogik: Es erstellt Handler mit fehlertoleranten Mustern und erreicht 100 % bei den mathematisch integrierten AIME 2025-Aufgaben. Exportieren Sie nach Apidog zur Zusammenarbeit – Teammitglieder kommentieren Schemata gemeinsam und stellen die Einhaltung von Standards wie OAuth 2.0 sicher.
Apidog verbessert auch die Vision-Funktionen von GPT-5.2. Laden Sie Wireframes hoch, lassen Sie das Modell CRUD-Operationen ableiten und dokumentieren Sie diese dann in Apidogs interaktiver Konsole. Die Preisgestaltung ist erschwinglich: GPT-5.2 zu 1,75 $/1M Input-Tokens ergänzt Apidogs kostenlose Stufe und macht die unternehmensweite Einführung machbar.
Herausforderungen ergeben sich bei Multi-Turn-Interaktionen; die 98,7 % Tool-Genauigkeit von GPT-5.2 mildert dies jedoch ab. Entwickler skripten Apidog-Workflows, um Aufrufe zu verketten und so vollständige API-Lebenszyklen von der Spezifikation bis zur Bereitstellung zu automatisieren.
Zukünftige Richtungen: Was liegt jenseits von GPT-5.2?
OpenAI deutet die Rolle von GPT-5.2 als Grundlage für multimodale Agenten an. Kommende Codex-Optimierungen versprechen native IDE-Plugins, die das Modell direkt in VS Code einbetten. Erwarten Sie Integrationen mit Edge-Geräten, die Mini-Varianten auf Laptops für die Offline-Codierung ausführen.
Apidog entwickelt sich parallel weiter und fügt KI-gestützte Schema-Evolution hinzu. Entwickler werden GPT-5.2 für versionierte APIs auffordern, wobei Apidog die Migrationen automatisch handhabt.
Herausforderungen umfassen den Energieverbrauch: Das Training rivalisierte mit den Outputs kleiner Nationen, was zu umweltfreundlicheren MoE-Designs führte. Regulierungslandschaften fordern Transparenz; OpenAIs Sicherheitsbewertungen, die 0,995 bei mentalen Gesundheitsantworten erzielten, setzen Präzedenzfälle.
Zusammenfassend lässt sich sagen, dass GPT-5.2 das Programmieren vom Handwerk zur Wissenschaft erhebt. Seine Varianten ermöglichen vielfältige Workflows, Benchmarks validieren Behauptungen, und Integrationen wie Apidog machen es zugänglich. Entwickler, nehmen Sie diese Veränderung an – laden Sie Apidog kostenlos herunter und experimentieren Sie noch heute mit GPT-5.2. Die Zukunft codiert sich selbst.