
Entwickler, die intelligente Anwendungen erstellen, fordern zunehmend Modelle, die diverse Datentypen verarbeiten können, ohne Geschwindigkeit oder Genauigkeit zu beeinträchtigen. GLM-4.6V begegnet diesem Bedarf direkt. Z.ai veröffentlicht diese Reihe als Open-Source multimodales großes Sprachmodell, das Text, Bilder, Videos und Dateien zu nahtlosen Interaktionen verbindet. Die API ermöglicht es Ihnen, diese Funktionen direkt in Ihre Projekte zu integrieren, sei es für die Dokumentenanalyse oder visuelle Suchagenten.
Während wir die Architektur, Zugriffsmethoden und Preisgestaltung von GLM-4.6V untersuchen, werden Sie sehen, wie es seine Konkurrenten in Benchmarks übertrifft. Darüber hinaus helfen Ihnen Integrationstipps mit Tools wie Apidog, schneller zu deployen. Beginnen wir mit dem Kerndesign des Modells.
GLM-4.6V verstehen: Architektur und Kernfunktionen
Die Ingenieure von Z.ai haben GLM-4.6V entwickelt, um multimodale Eingaben nativ zu verarbeiten und strukturierte Textantworten auszugeben. Diese Modellreihe umfasst zwei Varianten: das Flaggschiff GLM-4.6V (106 Milliarden Parameter) für Hochleistungsaufgaben und GLM-4.6V-Flash (9 Milliarden Parameter) für effiziente lokale Implementierungen. Beide unterstützen ein Kontextfenster von 128K Tokens, was die Analyse umfangreicher Dokumente – bis zu 150 Seiten – oder einstündiger Videos in einem Durchgang ermöglicht.

Im Kern enthält GLM-4.6V einen visuellen Encoder, der auf Langkontext-Protokolle abgestimmt ist. Diese Ausrichtung stellt sicher, dass das Modell feinkörnige Details über alle Eingaben hinweg beibehält. Es verarbeitet beispielsweise verschachtelte Text-Bild-Sequenzen und verankert Antworten an spezifischen visuellen Elementen wie Objektkoordinaten in Fotos. Native Funktionsaufrufe heben es ab; Entwickler rufen Tools direkt mit Bildparametern auf, und das Modell interpretiert visuelle Feedback-Schleifen.
Darüber hinaus verfeinert das Reinforcement Learning den Tool-Aufruf. Das Modell lernt, Aktionen zu verketten, wie das Abfragen eines Suchtools mit einem Screenshot und das Schlussfolgern über die Ergebnisse. Dies führt zu End-to-End-Workflows, von der Wahrnehmung bis zur Entscheidungsfindung. Folglich gewinnen Anwendungen an Autonomie ohne brüchige Nachbearbeitung.

In der Praxis führen diese Funktionen zu einer robusten Verarbeitung von realen Daten. Das Modell zeichnet sich durch die Erstellung von Rich-Text aus, indem es verschachtelte Bild-Text-Ausgaben für Berichte oder Infografiken generiert. Es unterstützt auch das Extended Model Context Protocol (MCP), das URL-basierte multimodale Eingaben für skalierbare Verarbeitung ermöglicht.
Benchmarks und Leistung: GLM-4.6V im Vergleich mit Mitbewerbern
Quantitative Daten bestätigen den Vorteil von GLM-4.6V. Auf MMBench erreicht es 82,5 % bei multimodaler QA und übertrifft LLaVA-1.6 um 4 Punkte. MathVista zeigt eine Genauigkeit von 68 % bei visuellen Gleichungen, dank abgestimmter Encoder.
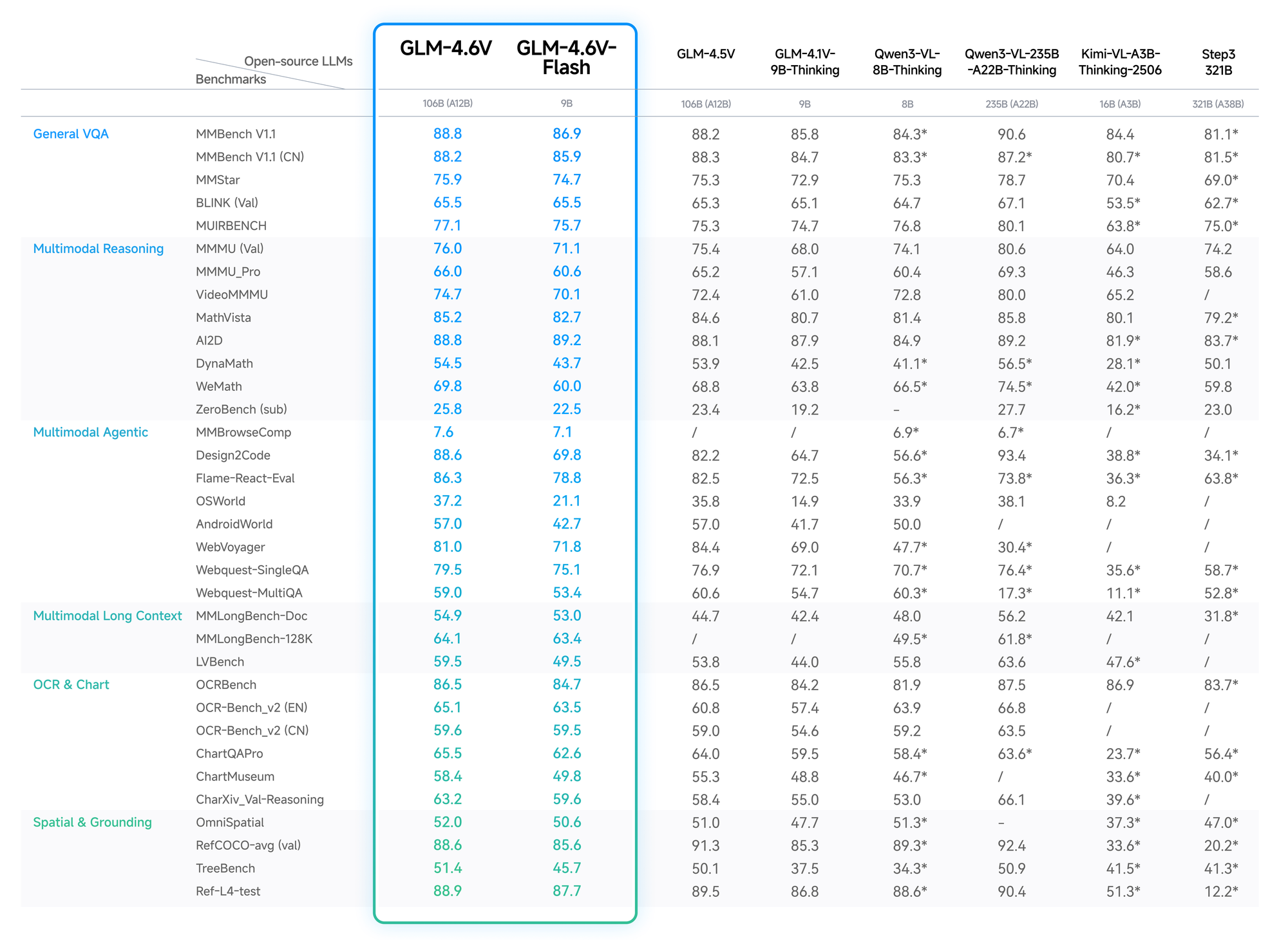
OCRBench-Tests ergeben 91 % für die Textextraktion aus verzerrten Bildern und übertreffen GPT-4V in den Open-Source-Rängen. Langkontext-Evaluierungen, wie Video-MME, erreichen 75 % für einstündige Clips, wobei Details über die Frames hinweg erhalten bleiben.
Die Flash-Variante tauscht eine geringe Genauigkeit (2-3 % Abfall) gegen eine 5-fache Geschwindigkeitssteigerung ein, ideal für Echtzeit-Anwendungen. Der Blog von Z.ai erläutert dies mit reproduzierbaren Setups auf Hugging Face.
Daher wählen Entwickler GLM-4.6V für zuverlässige, kostengünstige Leistung.
Hauptfunktionen der GLM-4.6V Modellreihe
GLM-4.6V bietet fortschrittliche Funktionen, die multimodale KI auf ein neues Niveau heben. Erstens decken seine Eingabemodalitäten Text, Bilder, Videos und Dateien ab, wobei die Ausgaben auf präzise Textgenerierung fokussiert sind. Entwickler schätzen die Flexibilität: Laden Sie ein Finanz-PDF hoch, und das Modell extrahiert Tabellen, analysiert Trends und schlägt Visualisierungen vor.
Die native Tool-Nutzung stellt einen Durchbruch dar. Im Gegensatz zu herkömmlichen Modellen, die eine externe Orchestrierung erfordern, integriert GLM-4.6V Funktionsaufrufe. Sie definieren Tools in Anfragen – zum Beispiel einen Cropper für Bilder – und das Modell übergibt visuelle Daten als Parameter. Es versteht dann die Ergebnisse und iteriert bei Bedarf. Dies schließt den Kreis für Aufgaben wie die visuelle Websuche: Erkennen der Absicht aus einem Abfragebild, Planung der Abfrage, Zusammenführung der Ergebnisse und Ausgabe begründeter Erkenntnisse.
Zusätzlich ermöglicht der 128K-Kontext eine Langform-Analyse. Verarbeiten Sie 200 Folien einer Präsentation; das Modell fasst die wichtigsten Themen zusammen und versieht Videoereignisse mit Zeitstempeln, wie Tore in einem Fußballspiel. Für die Frontend-Entwicklung repliziert es UIs aus Screenshots und gibt pixelgenauen HTML/CSS/JS-Code aus. Bearbeitungen in natürlicher Sprache folgen, wodurch Prototypen interaktiv verfeinert werden.
Die Flash-Variante optimiert auf Latenz. Mit 9 Milliarden Parametern läuft sie auf Consumer-Hardware über vLLM- oder SGLang-Inferenz-Engines. Auf Hugging Face verfügbare Gewichte ermöglichen ein Fine-Tuning, obwohl die Sammlung sich auf Basismodelle ohne umfangreiche Statistiken konzentriert. Insgesamt positionieren diese Funktionen GLM-4.6V als vielseitiges Rückgrat für Agenten in Business Intelligence oder kreativen Tools.
So greifen Sie auf die GLM-4.6V API zu: Schritt-für-Schritt-Einrichtung
Der Zugriff auf die GLM-4.6V API erweist sich dank ihrer OpenAI-kompatiblen Schnittstelle als unkompliziert. Beginnen Sie, indem Sie sich auf dem Z.ai-Entwicklerportal (z.ai) registrieren. Generieren Sie einen API-Schlüssel in Ihrem Kontodashboard – dieser Bearer-Token authentifiziert alle Anfragen.
Der Basis-Endpunkt befindet sich unter https://api.z.ai/api/paas/v4/chat/completions. Verwenden Sie die POST-Methode mit JSON-Payloads. Authentifizierungs-Header umfassen Authorization: Bearer <your-api-key> und Content-Type: application/json. Das Nachrichtenarray strukturiert Konversationen und unterstützt multimodale Inhalte.
Senden Sie zum Beispiel eine Bild-URL zusammen mit Textaufforderungen. Die Payload spezifiziert "model": "glm-4.6v" oder "glm-4.6v-flash". Aktivieren Sie Denk-Schritte mit "thinking": {"type": "enabled"} für transparente Denkprozesse. Der Streaming-Modus fügt "stream": true für Echtzeit-Antworten über Server-Sent Events hinzu.
Hier ist eine grundlegende Python-Integration unter Verwendung der requests-Bibliothek:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Describe the key elements in this image and suggest improvements."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
Dieser Code ruft eine Beschreibung mit Begründung ab. Für Videos oder Dateien erweitern Sie das Inhalts-Array ähnlich – URLs oder Base64-Kodierungen funktionieren. Ratenbegrenzungen gelten basierend auf Ihrem Plan; überwachen Sie diese über das Dashboard.
Apidog verbessert diesen Prozess. Importieren Sie die OpenAPI-Spezifikation aus der Z.ai-Dokumentation in Apidog und modellieren Sie dann Anfragen visuell. Testen Sie Funktionsaufrufe ohne Code, validieren Sie Payloads vor der Produktion. Dadurch iterieren Sie schneller und erkennen Fehler frühzeitig.
Der lokale Zugriff ergänzt die Cloud-Nutzung. Laden Sie Gewichte aus der GLM-4.6V-Sammlung von Hugging Face herunter und stellen Sie sie über kompatible Frameworks bereit. Dieses Setup eignet sich für datenschutzsensible Anwendungen, erfordert jedoch GPU-Ressourcen für das 106B-Modell.
Preisanalyse: Kostengünstige Skalierung mit GLM-4.6V
Z.ai strukturiert die Preisgestaltung von GLM-4.6V, um Zugänglichkeit und Leistung auszugleichen. Das Flaggschiff-Modell kostet 0,6 $ pro Million Eingabe-Tokens und 0,9 $ pro Million Ausgabe-Tokens. Dieses gestaffelte Modell berücksichtigt die multimodale Komplexität – Bilder und Videos verbrauchen Tokens basierend auf Auflösung und Länge.
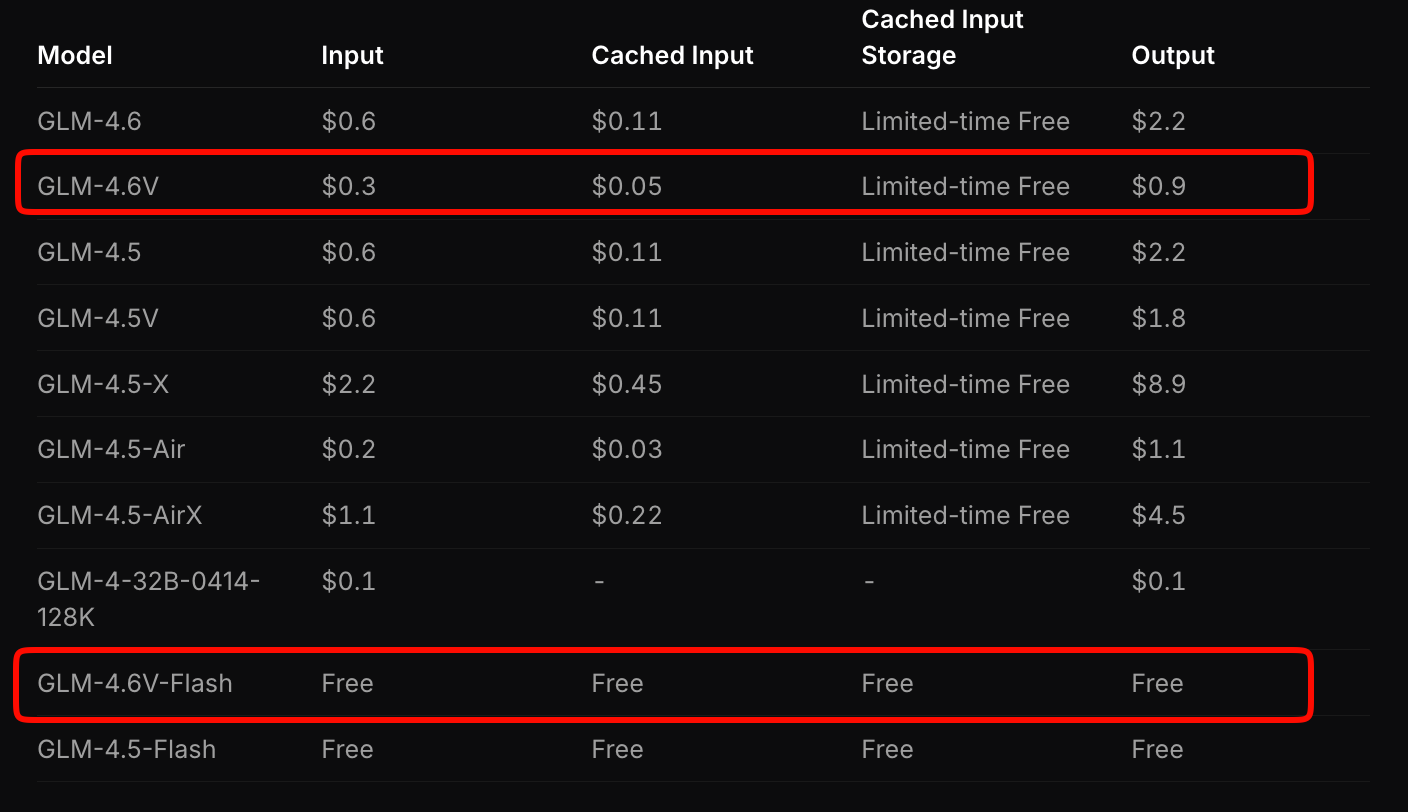
Im Gegensatz dazu bietet GLM-4.6V-Flash kostenlosen Zugang, ideal für Prototyping oder Edge-Deployments. Es fallen keine Token-Gebühren an, obwohl die Inferenzkosten an Ihre Hardware gebunden sind. Eine zeitlich begrenzte Aktion verdreifacht die Nutzungsquoten zu einem Siebtel der Kosten für kostenpflichtige Tarife, was das Experimentieren erschwinglich macht.
Vergleichen Sie dies mit Konkurrenten: GLM-4.6V unterbietet ähnliche multimodale APIs um 20-30 %, während es überlegene Benchmarks liefert. Für Anwendungen mit hohem Volumen berechnen Sie die Kosten mit dem Schätzungstool von Z.ai. Geben Sie eine Beispielarbeitslast ein – z. B. 100 tägliche Dokumentanalysen – und es projiziert die monatlichen Ausgaben.
Darüber hinaus mindern Open-Source-Gewichte die langfristigen Kosten. Fine-Tuning mit Ihren Daten reduziert die Abhängigkeit von Cloud-Aufrufen. Insgesamt ermöglicht diese Preisgestaltung Startups, ohne Budgetbeschränkungen zu skalieren.
Integration der GLM-4.6V API mit Apidog: Praktische Workflow-Optimierung
Apidog verwandelt die GLM-4.6V-Integration von manueller Plackerei in effiziente Zusammenarbeit. Als API-Client und Design-Tool importiert es die Z.ai-Spezifikation und generiert automatisch Anforderungsvorlagen. Sie ziehen multimodale Payloads per Drag-and-drop, zeigen Antworten in der Vorschau an und exportieren sie als Code-Snippets in Python, Node.js oder cURL.
Beginnen Sie, indem Sie ein neues Projekt in Apidog erstellen. Fügen Sie die Endpunkt-URL ein und authentifizieren Sie sich mit Ihrem Schlüssel. Für eine visuelle Erdungsaufgabe erstellen Sie eine Anfrage: fügen Sie einen `image_url`-Typ hinzu, geben Sie Koordinaten-Prompts ein und senden Sie die Anfrage. Apidog visualisiert die Ausgaben und hebt Denkphasen hervor.
Die Zusammenarbeit glänzt hier. Teilen Sie Sammlungen mit Teams; versionskontrollieren Sie Endpunkte, während Sie Tools hinzufügen. Umgebungsvariablen sichern Schlüssel über Entwicklungs-, Staging- und Produktionsumgebungen hinweg. Folglich verkürzen sich Bereitstellungszyklen – testen Sie eine vollständige Agentenkette in Minuten.
Erweitern Sie auf die Überwachung: Apidog protokolliert Latenzen und Fehler und identifiziert Engpässe in multimodalen Flüssen. Kombinieren Sie es mit GLM-4.6V-Flash für kostenlose lokale Tests und skalieren Sie dann in die Cloud. Entwickler berichten von einer 40 % schnelleren Prototypenentwicklung mit solchen Tools.
Anwendungsfälle aus der Praxis: GLM-4.6V in der Produktion
GLM-4.6V glänzt in dokumentenintensiven Branchen. Finanzanalysten laden Berichte hoch; das Modell analysiert Diagramme, berechnet Kennzahlen und generiert Executive Summaries mit eingebetteten Visualisierungen. Ein Unternehmen reduzierte die Analysezeit von Stunden auf Minuten, indem es den 128K-Kontext für Jahresabschlüsse nutzte.
Im E-Commerce werden visuelle Suchagenten aktiviert. Kunden laden Produktfotos hoch; GLM-4.6V plant Abfragen, ruft Übereinstimmungen ab und schlussfolgert über Attribute wie Farbvarianten. Dies steigert die Konversionsrate laut frühen Anwendern um 15 %.

Frontend-Teams beschleunigen das Prototyping. Geben Sie einen Screenshot ein; erhalten Sie bearbeitbaren Code. Iterieren Sie mit Prompts wie "Füge eine responsive Navigationsleiste hinzu." Die Pixelgenauigkeit des Modells minimiert Überarbeitungen und halbiert die Zeit von Design bis Bereitstellung.

Videoplattformen profitieren von temporaler Schlussfolgerung. Fassen Sie Vorlesungen mit Zeitstempeln zusammen oder erkennen Sie Ereignisse in Überwachungsfeeds. Die native Tool-Nutzung integriert sich mit Datenbanken und markiert Anomalien automatisch.
Diese Fälle demonstrieren die Vielseitigkeit von GLM-4.6V. Der Erfolg hängt jedoch vom Prompt Engineering ab – formulieren Sie klare Anweisungen, um die Genauigkeit zu maximieren.
Herausforderungen und Best Practices für die GLM-4.6V API-Nutzung
Trotz ihrer Stärken stehen multimodale Modelle vor Hürden. Hochauflösende Eingaben erhöhen die Token-Anzahl und damit die Kosten – komprimieren Sie Bilder zuerst auf 512x512 Pixel. Kontextüberläufe bergen das Risiko von Halluzinationen; teilen Sie lange Videos in Segmente auf.
Best Practices mindern diese Probleme. Nutzen Sie den Denkmodus zum Debuggen; er zeigt Zwischenschritte an. Validieren Sie Tool-Ausgaben mit Assertions in Ihrem Code. Für Apidog-Benutzer richten Sie automatisierte Tests an Endpunkten ein, um Schemata durchzusetzen.
Überwachen Sie Quoten genau – das kostenlose Flash vermeidet Überraschungen, aber kostenpflichtige Tarife erfordern Budgetierung. Zum Schluss verfeinern Sie die domänenspezifischen Daten über offene Gewichte, um die Spezifität zu erhöhen.
Fazit: Heben Sie Ihre Projekte heute mit GLM-4.6V auf ein neues Niveau
GLM-4.6V definiert multimodale KI durch native Tools, einen riesigen Kontext und offene Zugänglichkeit neu. Seine API, wettbewerbsfähig bepreist mit 0,6 $/M Eingabe für das Vollmodell und kostenlos für Flash, lässt sich nahtlos in Plattformen wie Apidog integrieren. Von Dokumentenagenten bis hin zu UI-Generatoren treibt es Innovationen voran.
Setzen Sie diese Erkenntnisse jetzt um: Holen Sie sich Ihren API-Schlüssel, testen Sie in Apidog und entwickeln Sie. Die Zukunft der KI bevorzugt diejenigen, die solche Fähigkeiten frühzeitig nutzen. Welche Anwendung werden Sie als Nächstes transformieren?