
Die Open-Source-KI-Landschaft hat gerade eine weitere seismische Verschiebung erlebt. Z.ai, das chinesische KI-Unternehmen, das früher als Zhipu bekannt war, hat GLM-4.5 und GLM-4.5 Air veröffentlicht und verspricht, DeepSeek zu übertreffen, während es neue Standards für KI-Leistung und Zugänglichkeit setzt. Diese Modelle stellen mehr als nur inkrementelle Verbesserungen dar – sie verkörpern ein fundamentales Umdenken darüber, wie hybrides Denken und agentische Fähigkeiten in Produktionsumgebungen funktionieren sollten.
Die Veröffentlichung erfolgt zu einem entscheidenden Zeitpunkt, an dem Entwickler zunehmend kostengünstige Alternativen zu proprietären Modellen fordern, ohne dabei an Funktionalität einzubüßen. Sowohl GLM-4.5 als auch GLM-4.5 Air erfüllen dieses Versprechen durch ausgeklügelte architektonische Innovationen, die die Effizienz maximieren und gleichzeitig eine Spitzenleistung bei Denk-, Kodierungs- und multimodalen Aufgaben aufrechterhalten.
Die GLM-4.5 Architektur-Revolution verstehen
Die GLM-4.5-Serie stellt eine signifikante Abkehr von traditionellen Transformer-Architekturen dar. Auf einer vollständig selbst entwickelten Architektur aufbauend, erreicht GLM-4.5 SOTA-Leistung in Open-Source-Modellen durch mehrere Schlüssel-Innovationen, die es von Konkurrenten abheben.
GLM-4.5 verfügt über insgesamt 355 Milliarden Parameter mit 32 Milliarden aktiven Parametern, während GLM-4.5-Air ein kompakteres Design mit 106 Milliarden Gesamtparametern und 12 Milliarden aktiven Parametern aufweist. Diese Parameterkonfiguration spiegelt ein sorgfältiges Gleichgewicht zwischen Recheneffizienz und Modellfähigkeit wider, wodurch beide Modelle eine beeindruckende Leistung erbringen können, während die Inferenzkosten angemessen bleiben.
Die Modelle nutzen eine ausgeklügelte Mixture-of-Experts (MoE)-Architektur, die während der Inferenz nur eine Untermenge von Parametern aktiviert. Beide nutzen das Mixture-of-Experts-Design für optimale Effizienz, wodurch GLM-4.5 komplexe Aufgaben mit nur 32 Milliarden seiner 355 Milliarden Parameter verarbeiten kann. Gleichzeitig behält GLM-4.5 Air vergleichbare Denkfähigkeiten mit nur 12 Milliarden aktiven Parametern aus seinem Gesamtparameterpool von 106 Milliarden bei.
Dieser architektonische Ansatz begegnet direkt einer der drängendsten Herausforderungen beim Einsatz großer Sprachmodelle: dem Rechenaufwand der Inferenz. Traditionelle dichte Modelle erfordern die Aktivierung aller Parameter für jeden Inferenzvorgang, was eine unnötige Rechenlast für einfachere Aufgaben erzeugt. Die GLM-4.5-Serie löst dies durch intelligentes Parameter-Routing, das die Rechenkomplexität an die Aufgabenanforderungen anpasst.
Darüber hinaus unterstützen die Modelle Kontextfenster von bis zu 128k Eingabe- und 96k Ausgabe-Tokens, was erhebliche Fähigkeiten zur Kontextverarbeitung bietet, die ein ausgeklügeltes Langform-Denken und eine umfassende Dokumentenanalyse ermöglichen. Dieses erweiterte Kontextfenster erweist sich als besonders wertvoll für agentische Anwendungen, bei denen Modelle das Bewusstsein für komplexe mehrstufige Interaktionen aufrechterhalten müssen.
GLM-4.5 Air: Optimierte Leistungsmerkmale
GLM-4.5 Air erweist sich als Effizienz-Champion der Serie, speziell entwickelt für Szenarien, in denen Rechenressourcen sorgfältig verwaltet werden müssen. GLM-4.5-Air ist ein grundlegendes Modell, das speziell für KI-Agenten-Anwendungen entwickelt wurde und auf einer Mixture-of-Experts (MoE)-Architektur basiert, die Geschwindigkeit und Ressourcenoptimierung priorisiert, ohne die Kernfunktionen zu beeinträchtigen.
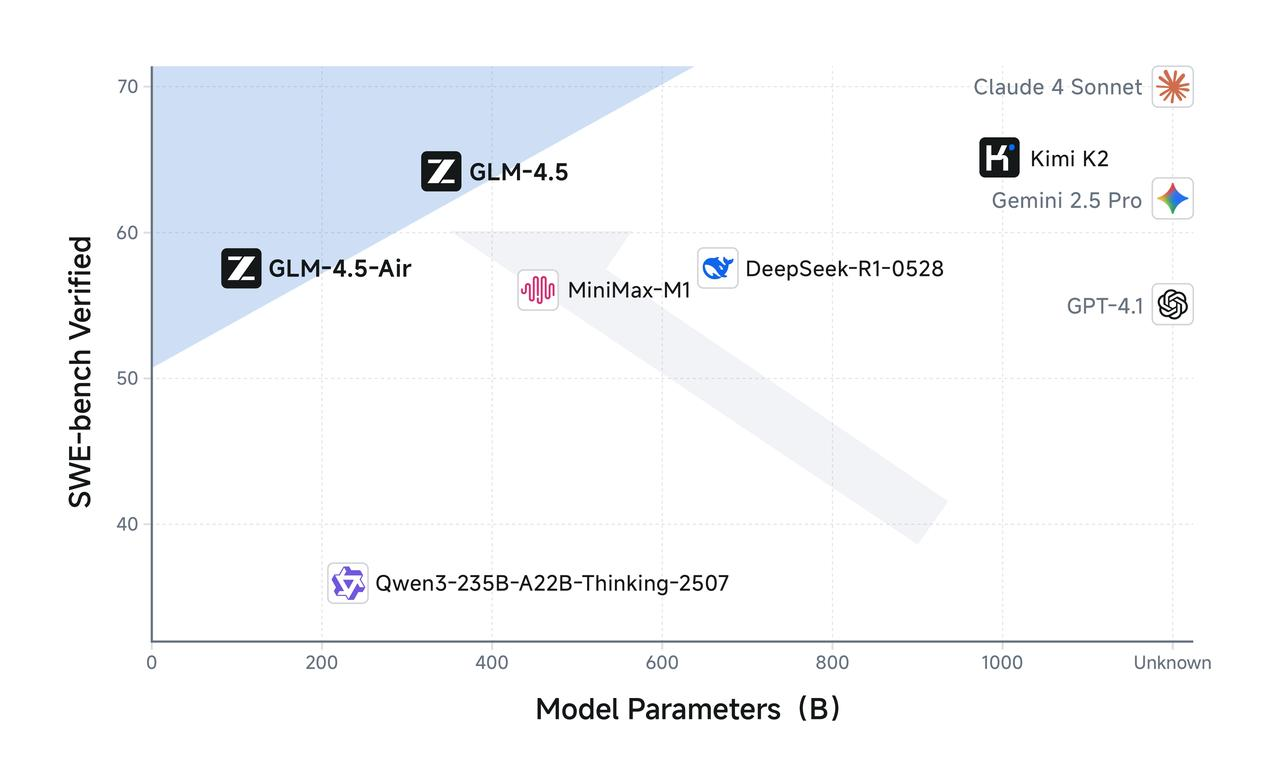
Die Air-Variante zeigt, wie eine durchdachte Parameterreduzierung die Modellqualität aufrechterhalten und gleichzeitig die Bereitstellungsfähigkeit drastisch verbessern kann. Mit 106 Milliarden Gesamtparametern und 12 Milliarden aktiven Parametern erzielt GLM-4.5 Air bemerkenswerte Effizienzgewinne, die sich direkt in reduzierten Inferenzkosten und schnelleren Antwortzeiten niederschlagen.
Speicheranforderungen stellen einen weiteren Bereich dar, in dem GLM-4.5 Air hervorragt. GLM-4.5-Air benötigt 16 GB GPU-Speicher (INT4 quantisiert bei ~12 GB), was es für Organisationen mit moderaten Hardwarebeschränkungen zugänglich macht. Dieser Zugänglichkeitsfaktor erweist sich als entscheidend für eine breite Akzeptanz, da viele Entwicklungsteams die Infrastrukturkosten, die mit größeren Modellen verbunden sind, nicht rechtfertigen können.
Die Optimierung geht über die reine Parametereffizienz hinaus und umfasst spezialisiertes Training für agentenorientierte Aufgaben. Es wurde umfassend für die Werkzeugnutzung, das Web-Browsing, die Softwareentwicklung und die Frontend-Entwicklung optimiert, was eine nahtlose Integration mit Codierungsagenten ermöglicht. Diese Spezialisierung bedeutet, dass GLM-4.5 Air eine überlegene Leistung bei praktischen Entwicklungsaufgaben im Vergleich zu Allzweckmodellen ähnlicher Größe liefert.
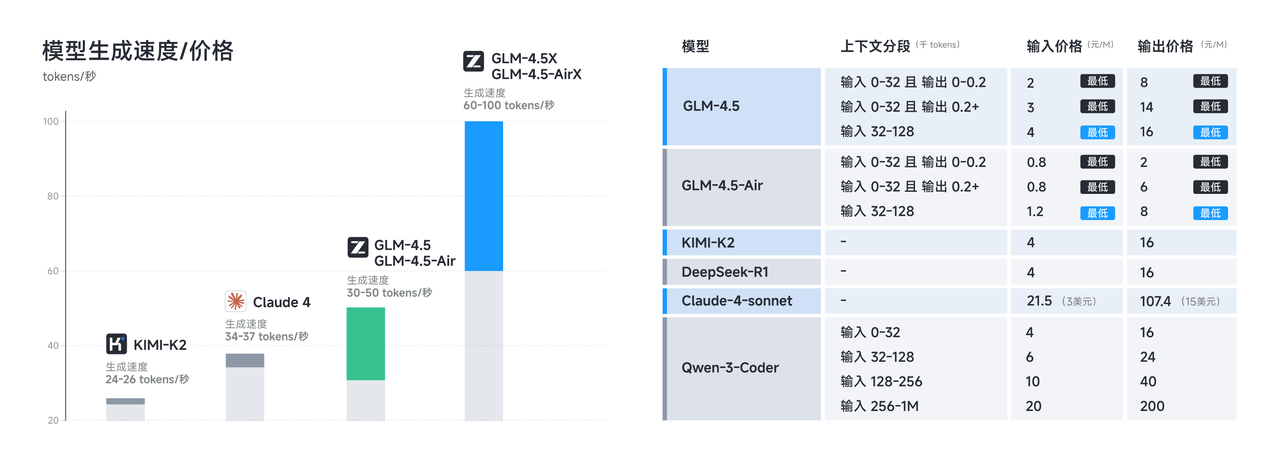
Die Antwortlatenz wird besonders wichtig in interaktiven Anwendungen, bei denen Benutzer nahezu sofortiges Feedback erwarten. Die reduzierte Parameteranzahl und die optimierte Inferenz-Pipeline von GLM-4.5 Air ermöglichen Antwortzeiten von unter einer Sekunde für die meisten Abfragen, wodurch es sich für Echtzeitanwendungen wie Code-Vervollständigung, interaktives Debugging und die Generierung von Live-Dokumentationen eignet.
Implementierung und Vorteile des hybriden Denkens
Das entscheidende Merkmal beider GLM-4.5-Modelle liegt in ihren hybriden Denkfähigkeiten. Sowohl GLM-4.5 als auch GLM-4.5-Air sind hybride Denkmodelle, die zwei Modi bieten: den Denkmodus für komplexes Denken und die Werkzeugnutzung, und den Nicht-Denkmodus für sofortige Antworten. Diese Dual-Modus-Architektur stellt eine fundamentale Innovation dar, wie KI-Modelle verschiedene Arten kognitiver Aufgaben handhaben.
Der Denkmodus wird aktiviert, wenn Modelle auf komplexe Probleme stoßen, die mehrstufiges Denken, Werkzeugnutzung oder erweiterte Analyse erfordern. Im Denkmodus generieren die Modelle Zwischenschritte des Denkprozesses, die für Entwickler sichtbar bleiben, aber vor Endbenutzern verborgen sind. Diese Transparenz ermöglicht das Debugging und die Optimierung von Denkprozessen, während saubere Benutzeroberflächen beibehalten werden.
Umgekehrt verarbeitet der Nicht-Denkmodus einfache Abfragen, die von sofortigen Antworten profitieren, ohne zusätzlichen Denkaufwand. Das Modell bestimmt automatisch, welcher Modus basierend auf der Abfragekomplexität und dem Kontext verwendet werden soll, um eine optimale Ressourcennutzung über verschiedene Anwendungsfälle hinweg zu gewährleisten.
Dieser hybride Ansatz löst eine hartnäckige Herausforderung in produktiven KI-Systemen: das Gleichgewicht zwischen Antwortgeschwindigkeit und Denkqualität. Traditionelle Modelle opfern entweder Geschwindigkeit für umfassendes Denken oder liefern schnelle, aber potenziell oberflächliche Antworten. Das Hybridsystem von GLM-4.5 eliminiert diesen Kompromiss, indem es die Denkkomplexität an die Aufgabenanforderungen anpasst.
Beide bieten einen Denkmodus für komplexe Aufgaben und einen Nicht-Denkmodus für sofortige Antworten, wodurch ein nahtloses Benutzererlebnis geschaffen wird, das sich an unterschiedliche kognitive Anforderungen anpasst. Entwickler können Modusauswahlparameter konfigurieren, um das Gleichgewicht zwischen Geschwindigkeit und Denktiefe basierend auf spezifischen Anwendungsanforderungen fein abzustimmen.
Der Denkmodus erweist sich als besonders wertvoll für agentische Anwendungen, bei denen Modelle mehrstufige Aktionen planen, Optionen zur Werkzeugnutzung bewerten und über längere Interaktionen hinweg kohärentes Denken aufrechterhalten müssen. Gleichzeitig gewährleistet der Nicht-Denkmodus eine reaktionsschnelle Leistung für einfache Abfragen wie Faktenabfragen oder unkomplizierte Code-Vervollständigungsaufgaben.
Technische Spezifikationen und Trainingsdetails
Die technische Grundlage der beeindruckenden Fähigkeiten von GLM-4.5 spiegelt umfangreiche Ingenieursarbeit und innovative Trainingsmethoden wider. Trainiert auf 15 Billionen Token, mit Unterstützung für bis zu 128k Eingabe- und 96k Ausgabe-Kontextfenster, demonstrieren die Modelle den Umfang und die Raffinesse, die für eine Spitzenleistung erforderlich sind.
Die Kuratierung der Trainingsdaten stellt einen kritischen Faktor für die Modellqualität dar, insbesondere für spezialisierte Anwendungen wie Codegenerierung und agentisches Denken. Der 15 Billionen Token umfassende Trainingskorpus umfasst diverse Quellen, darunter Code-Repositories, technische Dokumentationen, Denkbeispiele und multimodale Inhalte, die ein umfassendes Verständnis über Domänen hinweg ermöglichen.
Kontextfensterfähigkeiten unterscheiden GLM-4.5 von vielen konkurrierenden Modellen. GLM-4.5 bietet eine Kontextlänge von 128k und native Funktionsaufrufkapazität, was eine ausgeklügelte Langform-Analyse und mehrstufige Konversationen ohne Kontextkürzung ermöglicht. Das 96k Ausgabe-Kontextfenster stellt sicher, dass Modelle umfassende Antworten ohne künstliche Längenbeschränkungen generieren können.
Native Funktionsaufrufe stellen einen weiteren architektonischen Vorteil dar, der die Notwendigkeit externer Orchestrierungsebenen eliminiert. Modelle können externe Tools und APIs direkt als Teil ihres Denkprozesses aufrufen, wodurch effizientere und zuverlässigere agentische Workflows entstehen. Diese Fähigkeit erweist sich als wesentlich für Produktionsanwendungen, bei denen Modelle mit Datenbanken, externen Diensten und Entwicklungstools interagieren müssen.
Der Trainingsprozess beinhaltet eine spezialisierte Optimierung für agentische Aufgaben, die sicherstellt, dass Modelle starke Fähigkeiten in der Werkzeugnutzung, mehrstufigem Denken und Kontextpflege entwickeln. Eine einheitliche Architektur für Denk-, Kodierungs- und multimodale Wahrnehmungs-Aktions-Workflows ermöglicht nahtlose Übergänge zwischen verschiedenen Aufgabentypen innerhalb einzelner Interaktionen.
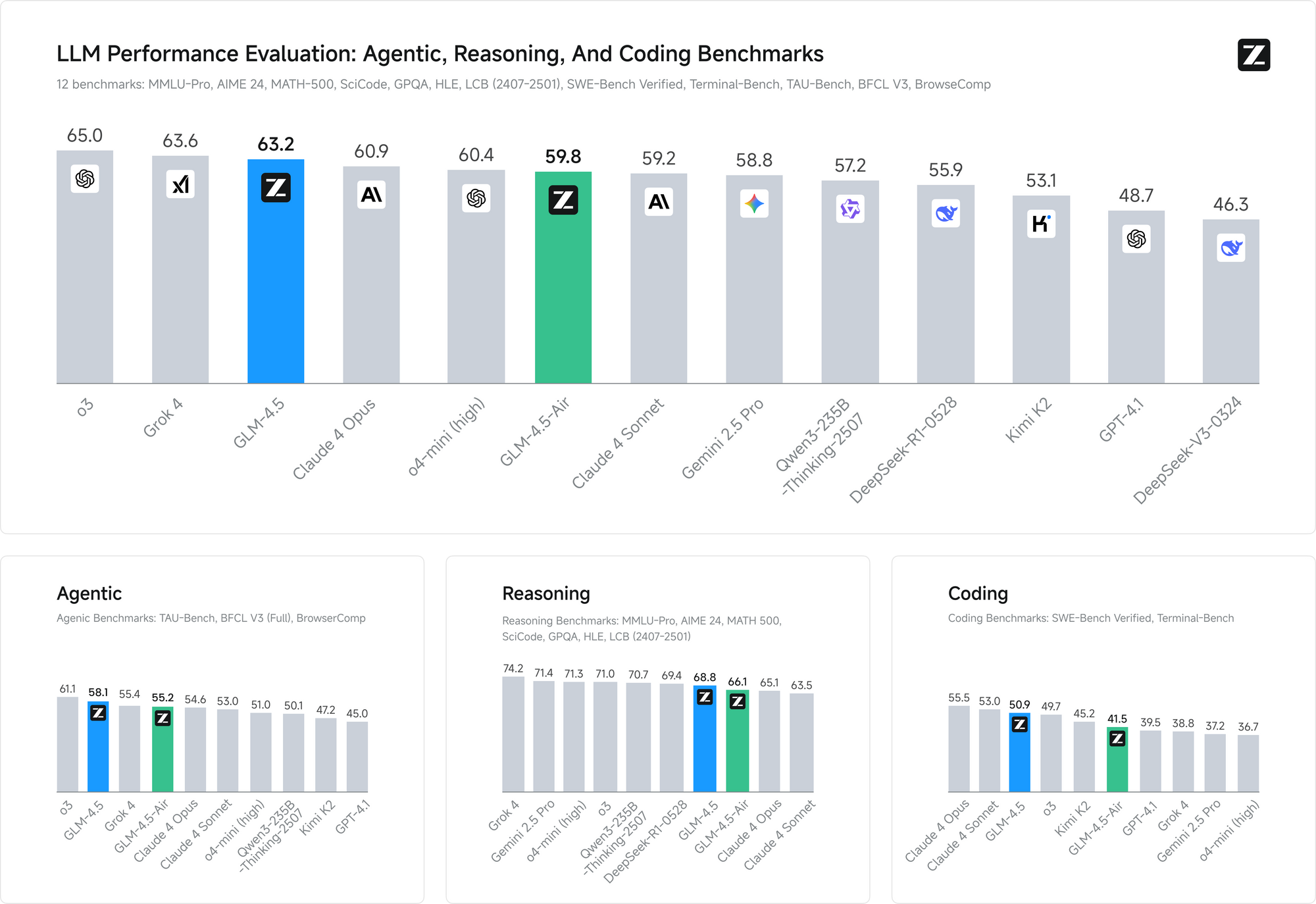
Leistungsbenchmarks bestätigen die Wirksamkeit dieser Trainingsansätze. Bei beiden Benchmarks erreicht GLM-4.5 die Leistung von Claude in Agentenfähigkeitsbewertungen und demonstriert eine wettbewerbsfähige Fähigkeit gegenüber führenden proprietären Modellen, während die Open-Source-Zugänglichkeit erhalten bleibt.
Lizenzierung und Vorteile der kommerziellen Bereitstellung
Die Open-Source-Lizenzierung stellt einen der bedeutendsten Wettbewerbsvorteile von GLM-4.5 in der aktuellen KI-Landschaft dar. Die Basismodelle, hybriden (Denk-/Nicht-Denk-) Modelle und FP8-Versionen werden alle unter der MIT-Lizenz für uneingeschränkte kommerzielle Nutzung und Sekundärentwicklung freigegeben, was eine beispiellose Freiheit für die kommerzielle Bereitstellung bietet.
Dieser Lizenzierungsansatz eliminiert viele Einschränkungen, die andere Open-Source-Modelle begrenzen. Organisationen können GLM-4.5-Implementierungen ohne Lizenzgebühren oder Nutzungsbeschränkungen modifizieren, weiterverbreiten und kommerzialisieren. Die MIT-Lizenz adressiert speziell kommerzielle Bedenken, die den Einsatz von KI in Unternehmen oft erschweren.
Mehrere Zugriffsmethoden und Plattformintegration
GLM-4.5 und GLM-4.5 Air bieten Entwicklern mehrere Zugriffsmöglichkeiten, die jeweils für unterschiedliche Anwendungsfälle und technische Anforderungen optimiert sind. Das Verständnis dieser Bereitstellungsoptionen ermöglicht es Teams, die am besten geeignete Integrationsmethode für ihre spezifischen Anwendungen auszuwählen.
Offizielle Website und direkter API-Zugriff
Die primäre Zugriffsmethode beinhaltet die Nutzung der offiziellen Plattform von Z.ai unter chat.z.ai, die eine benutzerfreundliche Oberfläche für die sofortige Modellinteraktion bietet. Diese webbasierte Oberfläche ermöglicht schnelles Prototyping und Testen, ohne technische Integrationsarbeit zu erfordern. Entwickler können Modellfähigkeiten bewerten, Prompt-Engineering-Strategien testen und Anwendungsfälle validieren, bevor sie sich für API-Implementierungen entscheiden.
Direkter API-Zugriff über die offiziellen Endpunkte von Z.ai bietet produktionsreife Integrationsmöglichkeiten mit umfassender Dokumentation und Support. Die offizielle API bietet eine feingranulare Kontrolle über Modellparameter, einschließlich der Auswahl des hybriden Denkmodus, der Nutzung des Kontextfensters und der Optionen für die Antwortformatierung.
OpenRouter-Integration für vereinfachten Zugriff
OpenRouter bietet optimierten Zugriff auf GLM-4.5-Modelle über ihre vereinheitlichte API-Plattform unter openrouter.ai/z-ai. Diese Integrationsmethode erweist sich als besonders wertvoll für Entwickler, die bereits die Multi-Modell-Infrastruktur von OpenRouter nutzen, da sie die Notwendigkeit separater API-Schlüsselverwaltung und Integrationsmuster eliminiert.
Die OpenRouter-Implementierung übernimmt Authentifizierung, Ratenbegrenzung und Fehlerbehandlung automatisch, was die Integrationskomplexität für Entwicklungsteams reduziert. Darüber hinaus ermöglicht das standardisierte API-Format von OpenRouter ein einfaches Modellwechseln und A/B-Testing zwischen GLM-4.5 und anderen verfügbaren Modellen ohne Codeänderungen.
Das Kostenmanagement wird durch das vereinheitlichte Abrechnungssystem von OpenRouter transparenter, das detaillierte Nutzungsanalysen und Ausgabenkontrollen über mehrere Modellanbieter hinweg bietet. Dieser zentralisierte Ansatz vereinfacht das Budgetmanagement für Organisationen, die mehrere KI-Modelle in ihren Anwendungen verwenden.
Hugging Face Hub für Open-Source-Bereitstellung
Hugging Face Hub hostet GLM-4.5-Modelle und bietet umfassende Modellkarten, technische Dokumentation und von der Community getriebene Anwendungsbeispiele. Diese Plattform erweist sich als unerlässlich für Entwickler, die Open-Source-Bereitstellungsmuster bevorzugen oder eine umfassende Modellanpassung benötigen.
Die Hugging Face-Integration ermöglicht die lokale Bereitstellung mithilfe der Transformers-Bibliothek, wodurch Organisationen die vollständige Kontrolle über Modell-Hosting und Datenschutz erhalten. Entwickler können Modellgewichte direkt herunterladen, benutzerdefinierte Inferenz-Pipelines implementieren und Bereitstellungskonfigurationen für spezifische Hardwareumgebungen optimieren.
Self-Hosted Bereitstellungsoptionen
Organisationen mit strengen Datenschutzanforderungen oder spezialisierten Infrastrukturbedürfnissen können GLM-4.5-Modelle mithilfe selbstgehosteter Konfigurationen bereitstellen. Die MIT-Lizenz ermöglicht eine uneingeschränkte Bereitstellung in privaten Cloud-Umgebungen, On-Premise-Infrastrukturen oder hybriden Architekturen.
Die selbstgehostete Bereitstellung bietet maximale Kontrolle über Modellverhalten, Sicherheitskonfigurationen und Integrationsmuster. Organisationen können benutzerdefinierte Authentifizierungssysteme, spezialisierte Überwachungsinfrastrukturen und domänenspezifische Optimierungen ohne externe Abhängigkeiten implementieren.
Containerbasierte Bereitstellung mittels Docker oder Kubernetes ermöglicht skalierbare, selbstgehostete Implementierungen, die sich an unterschiedliche Arbeitslastanforderungen anpassen können. Diese Bereitstellungsmuster erweisen sich als besonders wertvoll für Organisationen mit bestehender Expertise in der Container-Orchestrierung.
Integration in Entwicklungs-Workflows mit Apidog
Bei der Implementierung von GLM-4.5-Modellen auf verschiedenen Plattformen – sei es über OpenRouter, direkten API-Zugriff, Hugging Face-Bereitstellungen oder selbstgehostete Konfigurationen – müssen Entwickler die Leistung über diverse Anwendungsfälle hinweg validieren, verschiedene Parameterkonfigurationen testen und eine zuverlässige Fehlerbehandlung sicherstellen. Das API-Test-Framework von Apidog ermöglicht eine systematische Bewertung von Modellantworten, Latenzeigenschaften und Ressourcennutzungsmustern über all diese Bereitstellungsmethoden hinweg.
Die Dokumentationsgenerierungsfähigkeiten der Plattform erweisen sich als besonders wertvoll, wenn GLM-4.5 gleichzeitig über mehrere Zugriffsmethoden bereitgestellt wird. Entwickler können automatisch umfassende API-Dokumentationen generieren, die Modellkonfigurationsoptionen, Eingabe-/Ausgabe-Schemas und Anwendungsbeispiele enthalten, die spezifisch für die hybriden Denkfähigkeiten von GLM-4.5 über OpenRouter, direkte API und selbstgehostete Bereitstellungen hinweg sind.
Kollaborative Funktionen innerhalb von Apidog erleichtern den Wissensaustausch zwischen Entwicklungsteams, die mit GLM-4.5-Implementierungen arbeiten. Teammitglieder können Testkonfigurationen teilen, Best Practices dokumentieren und an Integrationsmustern zusammenarbeiten, die die Modelleffektivität maximieren.
Umgebungsmanagement-Funktionen gewährleisten konsistente GLM-4.5-Bereitstellungen über Entwicklungs-, Staging- und Produktionsumgebungen hinweg, unabhängig davon, ob Teams den Managed Service von OpenRouter, direkte API-Integration oder selbstgehostete Implementierungen nutzen. Entwickler können separate Konfigurationen für verschiedene Umgebungen pflegen und gleichzeitig reproduzierbare Bereitstellungsmuster sicherstellen.
Implementierungsstrategien und Best Practices
Die erfolgreiche Bereitstellung von GLM-4.5-Modellen erfordert eine sorgfältige Berücksichtigung der Infrastrukturanforderungen, Leistungsoptimierungstechniken und Integrationsmuster, die die Modelleffektivität maximieren. Organisationen sollten ihre spezifischen Anwendungsfälle mit den Modellfähigkeiten abgleichen, um optimale Bereitstellungskonfigurationen zu bestimmen.
Die Hardwareanforderungen variieren erheblich zwischen GLM-4.5 und GLM-4.5 Air, wodurch Organisationen Varianten auswählen können, die ihren Infrastrukturbeschränkungen entsprechen. Teams mit robuster GPU-Infrastruktur können das vollständige GLM-4.5-Modell für maximale Leistungsfähigkeit nutzen, während ressourcenbeschränkte Umgebungen feststellen könnten, dass GLM-4.5 Air ausreichende Leistung zu reduzierten Infrastrukturkosten bietet.
Das Feinabstimmen von Modellen stellt eine weitere kritische Überlegung für Organisationen mit spezialisierten Anforderungen dar. Die MIT-Lizenz ermöglicht eine umfassende Modell-Anpassung, wodurch Teams GLM-4.5 für domänenspezifische Anwendungen anpassen können. Das Feinabstimmen erfordert jedoch eine sorgfältige Datenkuratierung und Trainingsexpertise, um optimale Ergebnisse zu erzielen.
Die Konfiguration des Hybridmodus erfordert eine durchdachte Parameterabstimmung, um die Antwortgeschwindigkeit mit der Denkqualität in Einklang zu bringen. Anwendungen mit strengen Latenzanforderungen bevorzugen möglicherweise aggressivere Standardeinstellungen für den Nicht-Denkmodus, während Anwendungen, die die Denkqualität priorisieren, von niedrigeren Schwellenwerten für den Denkmodus profitieren könnten.
API-Integrationsmuster sollten die nativen Funktionsaufruffähigkeiten von GLM-4.5 nutzen, um effiziente agentische Workflows zu erstellen. Anstatt externe Orchestrierungsebenen zu implementieren, können Entwickler sich auf die integrierten Werkzeugnutzungsfähigkeiten des Modells verlassen, um die Systemkomplexität zu reduzieren und die Zuverlässigkeit zu verbessern.
Sicherheitsüberlegungen und Risikomanagement
Die Bereitstellung von Open-Source-Modellen wie GLM-4.5 bringt Sicherheitsaspekte mit sich, die Organisationen durch umfassende Risikomanagementstrategien angehen müssen. Die Verfügbarkeit von Modellgewichten ermöglicht eine gründliche Sicherheitsprüfung, erfordert aber auch eine sorgfältige Handhabung, um unbefugten Zugriff oder Missbrauch zu verhindern.
Die Sicherheit der Modellinferenz erfordert den Schutz vor adversariellen Eingaben, die das Modellverhalten beeinträchtigen oder sensible Informationen aus Trainingsdaten extrahieren könnten. Organisationen sollten Eingabevalidierung, Ausgabefilterung und Anomalieerkennungssysteme implementieren, um potenziell problematische Interaktionen zu identifizieren.
Die Sicherheit der Bereitstellungsinfrastruktur wird entscheidend, wenn GLM-4.5-Modelle in Produktionsumgebungen gehostet werden. Standard-Sicherheitspraktiken wie Netzwerkisolierung, Zugriffskontrollen und Verschlüsselung gelten für KI-Modellbereitstellungen ebenso wie für traditionelle Anwendungen.
Datenschutzüberlegungen erfordern sorgfältige Aufmerksamkeit für den Informationsfluss zwischen Anwendungen und GLM-4.5-Modellen. Organisationen müssen sicherstellen, dass sensible Dateneingaben angemessen geschützt werden und dass Modellausgaben vertrauliche Informationen nicht unbeabsichtigt preisgeben.
Die Sicherheit der Lieferkette erstreckt sich auf die Herkunft des Modells und die Integritätsprüfung. Organisationen sollten Modell-Checksums validieren, Download-Quellen überprüfen und Kontrollen implementieren, die sicherstellen, dass die bereitgestellten Modelle den beabsichtigten Konfigurationen entsprechen.
Die Open-Source-Natur von GLM-4.5 ermöglicht eine umfassende Sicherheitsprüfung, die Vorteile gegenüber proprietären Modellen bietet, bei denen Sicherheitseigenschaften undurchsichtig bleiben. Organisationen können Modellarchitektur, Trainingsdatenmerkmale und potenzielle Schwachstellen durch direkte Untersuchung analysieren, anstatt sich auf die Sicherheitsaussagen des Anbieters zu verlassen.
Fazit
GLM-4.5 und GLM-4.5 Air stellen bedeutende Fortschritte in den Open-Source-KI-Fähigkeiten dar und liefern wettbewerbsfähige Leistung, während sie die Zugänglichkeit und Flexibilität beibehalten, die erfolgreiche Open-Source-Projekte auszeichnen. Z.ai hat sein Basismodell der nächsten Generation, GLM-4.5, veröffentlicht, das durch architektonische Innovationen, die reale Bereitstellungsherausforderungen adressieren, SOTA-Leistung in Open-Source-Modellen erreicht.
Die hybride Denkarchitektur zeigt, wie durchdachtes Design traditionelle Kompromisse zwischen Antwortgeschwindigkeit und Denkqualität eliminieren kann. Diese Innovation bietet eine Vorlage für die zukünftige Modellentwicklung, die den praktischen Nutzen über die reine Benchmark-Leistung stellt.
Kosteneffizienzvorteile machen GLM-4.5 für Organisationen zugänglich, die fortschrittliche KI-Fähigkeiten zuvor als unerschwinglich teuer empfanden. Die Kombination aus reduzierten Inferenzkosten und permissiver Lizenzierung schafft Möglichkeiten für den Einsatz von KI in verschiedenen Branchen und Unternehmensgrößen.