
Die Landschaft der großen Sprachmodelle (LLMs) entwickelt sich in atemberaubendem Tempo. Über die bloße Skalierung der Parameteranzahl hinaus konzentrieren sich führende Forschungslabore zunehmend auf die Verbesserung spezifischer Fähigkeiten wie Argumentation, komplexe Problemlösung und Effizienz. Die Knowledge Engineering Group (KEG) der Tsinghua University und Zhipu AI (THUDM) stehen mit ihrer GLM (General Language Model)-Serie konsequent an vorderster Front dieser Fortschritte. Die Einführung von GLM-4-32B-0414 und seinen nachfolgenden spezialisierten Varianten – GLM-Z1-32B-0414, GLM-Z1-Rumination-32B-0414 und das überraschend potente GLM-Z1-9B-0414 – markiert einen bedeutenden Schritt in diese Richtung und zeigt eine ausgeklügelte Strategie, die grundlegende Stärke mit gezielten Verbesserungen verbindet.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demans, and replaces Postman at a much more affordable price!

Die Grundlage: GLM-4-32B-0414
Während sich der bereitgestellte Text stark auf die abgeleiteten 'Z1'-Modelle konzentriert, ist das Verständnis der Basis, GLM-4-32B-0414, von entscheidender Bedeutung. Als Modell mit 32 Milliarden Parametern befindet es sich in einem hart umkämpften Segment des LLM-Marktes. Modelle dieser Größe zielen typischerweise auf ein Gleichgewicht zwischen starker Leistung über eine Vielzahl von Aufgaben und überschaubaren Rechenanforderungen im Vergleich zu Giganten mit Hunderten von Milliarden oder Billionen von Parametern ab.
Angesichts der Geschichte von THUDM mit zweisprachigen (Chinesisch-Englisch) Modellen verfügt GLM-4-32B wahrscheinlich über robuste Fähigkeiten in beiden Sprachen. Sein Training würde riesige Datensätze umfassen, die Text und Code umfassen, wodurch es Aufgaben wie Texterstellung, Übersetzung, Zusammenfassung, Beantwortung von Fragen und grundlegende Code-Unterstützung ausführen kann. Das Suffix '0414' deutet wahrscheinlich auf eine bestimmte Version oder einen Trainings-Checkpoint hin, was auf eine laufende Entwicklung und Verfeinerung hindeutet.
GLM-4-32B-0414 dient als wesentliches Sprungbrett für die spezialisierteren Z1-Serien. Es stellt eine leistungsstarke, generalistische Grundlage dar, auf der gezielte Fähigkeiten aufgebaut werden können. Seine Leistung bei Standard-Benchmarks wäre wahrscheinlich stark und würde eine hohe Ausgangsbasis vor der Spezialisierung schaffen. Stellen Sie es sich als den gut abgerundeten Absolventen vor, der bereit für eine fortgeschrittene, spezialisierte Ausbildung ist.
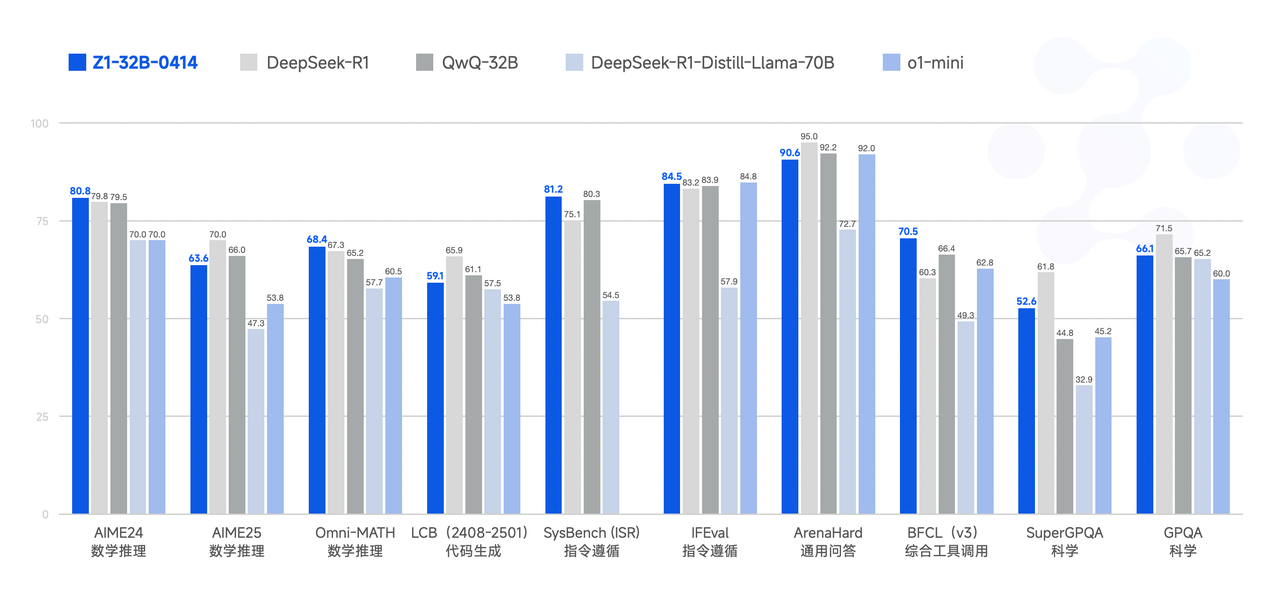
GLM-Z1-32B-0414: Die Schärfung der Argumentationsfähigkeit
Die erste spezialisierte Variante, GLM-Z1-32B-0414, stellt eine gezielte Anstrengung dar, die "tiefen Denk"- und Argumentationsfähigkeiten des Modells, insbesondere in technischen Bereichen, deutlich zu steigern. Der beschriebene Entwicklungsprozess ist facettenreich und deutet auf fortschrittliche Feinabstimmungsmethoden hin:
- Cold Start: Dieser faszinierende Begriff deutet darauf hin, dass der Spezialisierungsprozess nicht nur durch Feinabstimmung der Basis GLM-4-32B initiiert wird, sondern möglicherweise auch durch die Verwendung seiner Gewichte als intelligenterer Ausgangspunkt für eine neue Trainingsphase, wodurch möglicherweise bestimmte Schichten oder Optimierer zurückgesetzt werden, um das Erlernen neuer, unterschiedlicher Argumentationspfade zu fördern, anstatt nur bestehende inkrementell zu verbessern.
- Extended Reinforcement Learning (RL): Standard-RLHF (Reinforcement Learning from Human Feedback) richtet Modelle an menschlichen Präferenzen aus. "Extended" RL könnte längere Trainingsdauern, ausgefeiltere Belohnungsmodelle oder neuartige RL-Algorithmen implizieren, die speziell entwickelt wurden, um mehrstufige Argumentationsprozesse zu kultivieren. Das Ziel ist es wahrscheinlich, dem Modell beizubringen, nicht nur plausible Antworten zu geben, sondern logischen Schritten zu folgen, implizite Annahmen zu identifizieren und mit komplexen Anweisungen umzugehen.
- Further Training on Specific Tasks: Die explizite Ausrichtung auf Mathematik, Code und Logik deutet darauf hin, dass das Modell auf kuratierten Datensätzen trainiert wurde, die reich an diesen Bereichen sind. Dies könnte mathematische Theoreme und Aufgabensätze (wie GSM8K, MATH-Datensätze), Code-Repositories und Programmierprobleme (wie HumanEval, MBPP) sowie logische Denkaufgaben umfassen. Diese direkte Exposition zwingt das Modell, Muster und Strukturen zu verinnerlichen, die für diese anspruchsvollen Bereiche spezifisch sind.
- General RL based on Pairwise Ranking Feedback: Diese Ebene zielt darauf ab, sicherzustellen, dass die Spezialisierung nicht auf Kosten der allgemeinen Kompetenz geht. Durch die Verwendung paarweiser Vergleiche (Beurteilung, welche von zwei Antworten für allgemeine Eingabeaufforderungen besser ist), behält das Modell seine Bandbreite an Fähigkeiten bei und schärft gleichzeitig seine Argumentationsspitzen. Dies verhindert katastrophales Vergessen und erhält die allgemeine Hilfsbereitschaft und Kohärenz aufrecht.
Das angegebene Ergebnis ist eine signifikante Verbesserung der mathematischen Fähigkeiten und der Lösung komplexer Aufgaben. Dies deutet darauf hin, dass GLM-Z1-32B-0414 wahrscheinlich deutlich höhere Ergebnisse bei Benchmarks wie:
- GSM8K: Mathematikaufgaben der Grundschule, die mehrstufiges arithmetisches Denken erfordern.
- MATH: Herausfordernde Wettbewerbsmathematikaufgaben.
- HumanEval / MBPP: Python-Code-Generierungsaufgaben, die die funktionale Korrektheit testen.
- Logic Benchmarks: Tests mit deduktivem, induktivem und abduktivem Denken.
Im Vergleich zur Basis GLM-4-32B würde man erwarten, dass Z1-32B in diesen Bereichen deutliche prozentuale Zuwächse zeigt, die möglicherweise mit größeren, generalistischeren Modellen konkurrieren oder diese sogar übertreffen, die keine so fokussierte Argumentationsverbesserung erfahren haben. Es stellt eine strategische Wahl dar: ein leistungsfähiges Modell für hochwertige, kognitiv anspruchsvolle Aufgaben zu optimieren.
GLM-Z1-Rumination-32B-0414: Ermöglichen tieferen, sucherweiterten Gedanken
Das "Rumination"-Modell führt eine weitere Ebene der Raffinesse ein und zielt auf offene und komplexe Probleme ab, die mehr erfordern als nur das Abrufen oder Argumentieren über vorhandenes Wissen. Das Konzept der "Rumination" wird gegen "OpenAI's Deep Research" positioniert (bezieht sich möglicherweise konzeptionell auf Modelle, die in der Lage sind, eingehende Analysen oder mehrstufige Denkprozesse durchzuführen). Im Gegensatz zur Standard-Inferenz, bei der ein Modell eine Antwort in einem einzigen Durchgang generiert, impliziert Rumination eine Fähigkeit zum tieferen, potenziell iterativen und längeren Denken.
Schlüsselaspekte von GLM-Z1-Rumination-32B-0414 umfassen:
- Deep and Long Thinking: Dies deutet darauf hin, dass das Modell möglicherweise Techniken wie Chain-of-Thought, Tree-of-Thought oder interne Notizblöcke extensiver einsetzt oder möglicherweise sogar einen iterativen Verfeinerungsprozess, bei dem es seine eigenen Zwischenergebnisse kritisiert und verbessert, bevor die endgültige Antwort erzeugt wird. Dies ist entscheidend für Aufgaben, denen eine einzelne, leicht überprüfbare Antwort fehlt.
- Solving Open-Ended Problems: Das gegebene Beispiel – "Verfassen einer vergleichenden Analyse der KI-Entwicklung in zwei Städten und ihrer zukünftigen Entwicklungspläne" – veranschaulicht dies perfekt. Solche Aufgaben erfordern die Synthese von Informationen aus potenziell unterschiedlichen Quellen, die Strukturierung komplexer Argumente, das Treffen nuancierter Urteile und die Erstellung kohärenter, ausführlicher Texte.
- Scaled End-to-End RL with Graded Responses: Das Training beinhaltet RL, aber der Feedback-Mechanismus ist ausgefeilter als einfaches Präferenz-Ranking. Antworten werden basierend auf Ground-Truth-Antworten (falls zutreffend) oder detaillierten Rubriken (für qualitative Aufgaben) bewertet. Dies liefert ein viel reichhaltigeres Lernsignal und lehrt das Modell nicht nur, was "besser" ist, sondern warum es nach bestimmten Kriterien besser ist (z. B. Tiefe der Analyse, Kohärenz, Faktenrichtigkeit, Struktur).
- Search Tool Integration during Deep Thinking: Dies ist eine kritische Funktion. Für komplexe, forschungsartige Aufgaben ist das interne Wissen des Modells möglicherweise unzureichend oder veraltet. Durch die Integration von Suchfunktionen während des Generierungsprozesses kann das Modell aktiv nach relevanten, aktuellen Informationen suchen, diese analysieren und in seine "Rumination" einbeziehen. Dies verwandelt das Modell von einem statischen Wissensspeicher in einen dynamischen Forschungsassistenten.
Die erwarteten Verbesserungen liegen im Schreiben im Forschungsstil und im Umgang mit komplexen Aufgaben, die Informationssynthese und strukturierte Argumentation erfordern. Das Benchmarking solcher Fähigkeiten ist mit Standardmetriken notorisch schwierig. Die Bewertung könnte sich stärker auf Folgendes verlassen:
- Human Evaluation: Bewertung der Qualität, Tiefe und Kohärenz von ausführlichen Ausgaben basierend auf vordefinierten Rubriken.
- Performance on Complex QA: Datensätze wie StrategyQA oder QuALITY, die Argumentation über mehrere Informationen erfordern.
- Task-Specific Evaluations: Bewertung der Leistung bei maßgeschneiderten Aufgaben, die dem Beispiel der vergleichenden Analyse ähneln.
GLM-Z1-Rumination stellt einen ehrgeizigen Vorstoß in Richtung Modelle dar, die als echte Mitarbeiter in komplexer Wissensarbeit fungieren können, in der Lage sind, Themen zu erforschen, Informationen zu sammeln und anspruchsvolle Argumente zu konstruieren.
GLM-Z1-9B-0414: Das Lightweight Powerhouse
Die vielleicht faszinierendste Veröffentlichung ist GLM-Z1-9B-0414. Während die Branche oft der Skalierung nachjagt, hat THUDM die fortschrittlichen Trainingsmethoden, die für die größeren Z1-Modelle entwickelt wurden, auf eine viel kleinere Basis mit 9 Milliarden Parametern angewendet. Dies ist bedeutsam, da kleinere Modelle weitaus zugänglicher sind: Sie benötigen weniger Rechenleistung für die Inferenz, sind günstiger zu betreiben und können einfacher auf Edge-Geräten oder Standardhardware eingesetzt werden.
Die wichtigste Erkenntnis ist, dass GLM-Z1-9B die Vorteile der ausgefeilten Trainingspipeline erbt: die Argumentationsverbesserungen aus der Entwicklung von Z1-32B (wahrscheinlich einschließlich der aufgabenspezifischen Trainings- und RL-Techniken) und möglicherweise Aspekte des Rumination-Trainings (obwohl möglicherweise reduziert). Das Ergebnis ist ein Modell, das deutlich über seiner Gewichtsklasse liegt.
Aussagen über "ausgezeichnete Fähigkeiten im mathematischen Denken und bei allgemeinen Aufgaben" und "Spitzenreiter unter allen Open-Source-Modellen gleicher Größe" deuten auf eine starke Leistung bei Benchmarks im Vergleich zu anderen Modellen im Bereich von 7B-13B Parametern hin (z. B. Mistral 7B, Llama 2 7B/13B-Varianten, Qwen 7B). Wir würden erwarten, dass GLM-Z1-9B besonders wettbewerbsfähige Ergebnisse erzielt bei:
- MMLU: Messung des breiten Multi-Task-Verständnisses.
- GSM8K/MATH: Demonstration von Argumentationsfähigkeiten, die in keinem Verhältnis zu ihrer Größe stehen.
- HumanEval/MBPP: Zeigen starker Programmierfähigkeiten für seine Klasse.
Dieses Modell adressiert ein kritisches Bedürfnis im KI-Ökosystem: ein optimales Gleichgewicht zwischen Effizienz und Effektivität zu erreichen. Für Benutzer und Organisationen, die unter Ressourcenbeschränkungen arbeiten (begrenzter GPU-Zugang, Budgetbeschränkungen, Bedarf an lokaler Bereitstellung), bietet GLM-Z1-9B eine überzeugende Option, die erweiterte Argumentationsfähigkeiten bietet, ohne die Infrastruktur viel größerer Modelle zu fordern. Es demokratisiert den Zugang zu anspruchsvoller KI.
Benchmarks und Leistungsanalyse (illustrativ)
Während spezifische, verifizierte Benchmark-Zahlen von Drittanbietern eine laufende Verfolgung erfordern, können wir basierend auf den Beschreibungen die relative Positionierung ableiten:
| Model | Parameter Size | Key Strengths | Likely High-Performing Benchmarks | Target Use Case |
|---|---|---|---|---|
| GLM-4-32B-0414 (Base) | 32B | Strong General Capabilities, Bilingualism | MMLU, C-Eval, General QA, Translation | Broad-purpose LLM tasks |
| GLM-Z1-32B-0414 (Reasoning) | 32B | Math, Code, Logic, Complex Task Solving | GSM8K, MATH, HumanEval, Logic Puzzles | Technical problem solving, analysis |
| GLM-Z1-Rumination-32B-0414 | 32B | Deep Reasoning, Open-Ended Tasks, Search Use | Long-form Eval, Complex QA, Research Tasks | Research, analysis, complex writing |
| GLM-Z1-9B-0414 (Efficient) | 9B | High Performance/Size Ratio, Math/General Tasks | MMLU, GSM8K, HumanEval (relative to size) | Resource-constrained deployment |
(Hinweis: Diese Tabellenstruktur hilft, die Differenzierung zu visualisieren. Tatsächliche Ergebnisse würden eine solche Tabelle in einem formellen Bericht ausfüllen.)
Es wird erwartet, dass das Z1-32B-Modell bei argumentationsintensiven Aufgaben das Basis-32B-Modell deutlich übertrifft. Das Rumination-Modell erreicht möglicherweise nicht die Top-Benchmarks, zeichnet sich aber in qualitativen Bewertungen komplexer, generativer Aufgaben aus. Der Wert des Z1-9B-Modells liegt in seinen hohen Ergebnissen relativ zu anderen Modellen unter ~13B Parametern, die sie aufgrund seines spezialisierten Trainings möglicherweise in Mathematik und Argumentation übertreffen.
Tiefe Einblicke und Implikationen
Die Veröffentlichung dieser GLM-Varianten bietet mehrere Einblicke in die Strategie von THUDM und die breitere Entwicklung von LLMs:
- Beyond Scaling: Diese Suite demonstriert eine klare Strategie zur Verbesserung von Modellen durch ausgefeilte Trainingstechniken, anstatt sich ausschließlich auf die Erhöhung der Parameteranzahl zu verlassen. Spezialisierung ist der Schlüssel.
- Advanced Training Methodologies: Die explizite Erwähnung von Cold Starts, unterschiedlichen RL-Ansätzen (paarweises Ranking, End-to-End-Bewertung), aufgabenspezifischem Curriculum-Learning und Suchintegration unterstreicht die Komplexität und Innovation, die beim Modelltraining über das Standard-Pre-Training und die Feinabstimmung hinaus stattfinden.
- Reasoning as a Core Focus: Beide Z1-32B-Varianten betonen stark die Argumentation – logisch, mathematisch und analytisch. Dies spiegelt ein wachsendes Verständnis wider, dass wahre KI-Fähigkeit mehr als nur Mustererkennung erfordert; sie erfordert robuste Schlussfolgerungsfähigkeiten.
- The Rumination Concept: Die Einführung von "Rumination" und sucherweitertem Denken verschiebt die Grenzen der LLM-Fähigkeiten in Richtung autonomerer Forschung und Analyse. Dies könnte sich erheblich auf Wissensarbeit, Inhaltserstellung und wissenschaftliche Entdeckungen auswirken.
- Democratization through Efficiency: Das Z1-9B-Modell ist ein entscheidender Beitrag. Durch die Kaskadierung fortschrittlicher Trainingstechniken auf kleinere Modelle macht THUDM leistungsstarke KI zugänglicher und fördert eine breitere Akzeptanz und Innovation. Es stellt die Vorstellung in Frage, dass modernste Fähigkeiten exklusiv den größten Modellen vorbehalten sind.
- Competitive Positioning: Die hervorgehobenen spezifischen Fähigkeiten (Argumentation, tiefes Denken, Effizienz) und die impliziten Vergleiche (z. B. "gegen OpenAI's Deep Research") deuten darauf hin, dass THUDM seine Modelle strategisch positioniert, um im globalen KI-Bereich effektiv zu konkurrieren, indem es sich auf unterschiedliche Stärken konzentriert.
Fazit
Das GLM-4-32B-0414 und seine spezialisierten Z1-Nachkommen stellen einen bedeutenden Fortschritt in der GLM-Familie dar und tragen wesentlich zum KI-Bereich bei. GLM-4-32B bietet eine solide Grundlage, während GLM-Z1-32B den Intellekt des Modells für komplexe Argumentationsaufgaben in Mathematik, Code und Logik schärft. GLM-Z1-Rumination leistet Pionierarbeit für tieferes, suchintegriertes Denken für offene Forschung und Analyse. Schließlich liefert GLM-Z1-9B eine beeindruckende Mischung aus erweiterten Fähigkeiten und Effizienz, wodurch leistungsstarke KI auch in ressourcenbeschränkten Szenarien zugänglich wird.
Zusammen zeigen diese Modelle einen ausgeklügelten Ansatz zur KI-Entwicklung, der nicht nur den Maßstab, sondern auch die gezielte Spezialisierung, innovative Trainingsmethoden und praktische Einsatzüberlegungen schätzt. Da THUDM weiterhin iteriert und möglicherweise Open Source oder den Zugriff auf diese Modelle ermöglicht, bieten sie überzeugende Alternativen und leistungsstarke Werkzeuge für Forscher, Entwickler und Benutzer, die erweiterte Argumentations- und Problemlösungsfähigkeiten suchen. Der Fokus auf Argumentation und Effizienz weist auf eine Zukunft hin, in der KI nicht nur größer, sondern nachweislich intelligenter und zugänglicher ist.


