
Entwickler suchen ständig nach effizienten Wegen, fortschrittliche KI-Modelle in Anwendungen zu integrieren. Die Gemini 3 Flash API bietet eine leistungsstarke Option, die hohe Intelligenz mit Geschwindigkeit und Kosteneffizienz in Einklang bringt.
Google treibt seine generativen KI-Angebote weiter voran. Das Gemini 3 Flash Modell sticht zudem in der aktuellen Produktpalette hervor. Ingenieure greifen über die Gemini API darauf zu, was schnelles Prototyping und die Bereitstellung in der Produktion ermöglicht.
So erhalten Sie Ihren Gemini API-Schlüssel
Sie beginnen damit, einen API-Schlüssel zu erhalten. Navigieren Sie zuerst zu Google AI Studio unter aistudio.google.com. Melden Sie sich gegebenenfalls mit Ihrem Google-Konto an. Wählen Sie anschließend das Gemini 3 Flash Vorschaumodell aus den verfügbaren Optionen aus. Klicken Sie dann auf die Option, einen API-Schlüssel zu generieren.
Google stellt diesen Schlüssel sofort bereit. Bewahren Sie ihn außerdem sicher auf – behandeln Sie ihn als sensible Anmeldeinformationen. Sie verwenden ihn im Header x-goog-api-key für alle Anfragen. Alternativ können Sie ihn zur Vereinfachung in Skripten als Umgebungsvariable festlegen.
Ohne einen gültigen Schlüssel schlagen Anfragen sofort mit Authentifizierungsfehlern fehl. Überprüfen Sie daher die Funktionalität des Schlüssels frühzeitig, indem Sie ihn in der interaktiven Oberfläche von Google AI Studio testen.
Die Funktionen von Gemini 3 Flash verstehen
Gemini 3 Flash bietet Intelligenz auf Pro-Niveau mit Flash-Geschwindigkeit. Insbesondere bleibt die Modell-ID während der Vorschauphase gemini-3-flash-preview. Es unterstützt ein riesiges Eingabekontextfenster von 1.048.576 Tokens und ein Ausgabelimit von 65.536 Tokens.
Darüber hinaus verarbeitet es multimodale Eingaben effektiv. Sie können Text, Bilder, Videos, Audio und PDFs bereitstellen. Die Ausgaben bestehen hauptsächlich aus Text, mit Optionen für strukturiertes JSON durch Schema-Durchsetzung.
Zu den Hauptfunktionen gehört die integrierte Denkprozesssteuerung. Entwickler passen die Denktiefe über den Parameter thinking_level an: minimal, niedrig, mittel oder hoch (Standard). Hoch maximiert die Denkqualität, während niedrigere Stufen die Latenz für Szenarien mit hohem Durchsatz priorisieren.
Zusätzlich können Sie die Medienauflösung für Vision-Aufgaben steuern. Die Optionen reichen von niedrig bis ultra_high und beeinflussen den Token-Verbrauch pro Frame oder Bild. Wählen Sie passend aus – hoch für detaillierte Bilder, mittel für Dokumente.
Das Modell integriert Tools wie die Google Search-Verankerung, Code-Ausführung und Funktionsaufrufe. Es schließt jedoch die Bilderzeugung und bestimmte fortschrittliche Robotik-Tools aus.
Preise für die Gemini 3 Flash API
Kostenmanagement ist bei API-Integrationen wichtig. Gemini 3 Flash arbeitet nach einem Pay-as-you-go-Modell. Eingabe-Tokens kosten 0,50 $ pro Million, während Ausgabe-Tokens (einschließlich Denk-Tokens) 3 $ pro Million kosten.
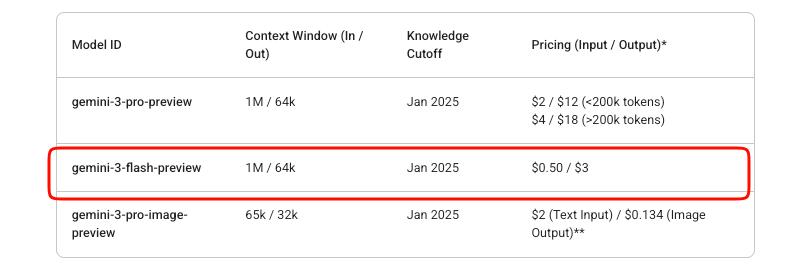
Google bietet kostenlose Experimente in AI Studio an. Die Nutzung der Produktions-API ist jedoch kostenpflichtig, sobald die Abrechnung aktiviert ist. Für dieses Vorschaumodell gibt es über die Studio-Testphasen hinaus keine kostenlose Stufe.
Kontext-Caching und Stapelverarbeitung helfen, die Kosten weiter zu optimieren. Caching reduziert die redundante Token-Verarbeitung für wiederholte Kontexte. Die Batch-API eignet sich für asynchrone Aufgaben mit hohem Volumen.
Überwachen Sie die Nutzung über die Google Cloud Billing Dashboards. Plötzliche Spitzen resultieren oft aus hohen media_resolution-Einstellungen oder umfangreichem Reasoning.
Ihre erste API-Anfrage stellen
Sie beginnen mit einfacher Textgenerierung. Der Endpunkt ist https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
Konstruieren Sie eine POST-Anfrage. Fügen Sie Ihren API-Schlüssel in den Headern ein. Der Body enthält Inhalte als Array von Rollen-Part-Objekten.
Hier ist ein grundlegendes cURL-Beispiel:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
Die Antwort liefert Kandidaten mit Textteilen. Behandeln Sie zusätzlich Nutzungsmetadaten für Token-Zählungen.
Für Streaming-Antworten verwenden Sie den Endpunkt :streamGenerateContent. Dies liefert inkrementell Teilergebnisse und verbessert die wahrgenommene Latenz in Anwendungen.
Integration mit offiziellen SDKs
Google pflegt SDKs, die die Interaktionen vereinfachen. Installieren Sie das Python-Paket über pip install google-generativeai.
Initialisieren Sie den Client:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
Das SDK verwaltet automatisch Gedankensignaturen für mehrstufige Konversationen und den Werkzeugeinsatz. Folglich sollten SDKs gegenüber rohem HTTP für Produktionscode bevorzugt werden.
Node.js-Benutzer erhalten ähnlichen Komfort über @google/generative-ai.
Multimodale Eingaben verarbeiten
Gemini 3 Flash zeichnet sich durch multimodale Verarbeitung aus. Laden Sie Dateien hoch oder stellen Sie Inline-Daten-URIs bereit.
In Python:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
Passen Sie media_resolution in der Generierungskonfiguration für die Token-Effizienz an:
generation_config = {
"media_resolution": "media_resolution_high"
}
Videos und PDFs folgen ähnlichen Mustern. Kombinieren Sie außerdem mehrere Modalitäten in einer Anfrage für komplexe Analyseaufgaben.
Erweiterte Funktionen: Denktiefe und Tools
Steuern Sie die Argumentation explizit. Setzen Sie thinking_level auf „low“ für schnelle Antworten:
"generationConfig": {
"thinking_level": "low"
}
Hohe Denktiefe ermöglicht eine tiefere interne Chain-of-Thought-Verarbeitung.
Aktivieren Sie Tools wie Funktionsaufrufe. Definieren Sie Funktionen in der Anfrage; das Modell gibt Aufrufe zurück, wenn dies angemessen ist.
Strukturierte Ausgaben erzwingen JSON-Schemata:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
Kombinieren Sie diese für agentische Workflows. Zum Beispiel, Antworten mit Echtzeit-Suche verankern.
Testen und Debuggen mit Apidog
Effektives Testen gewährleistet zuverlässige Integrationen. Apidog erweist sich hierfür als robustes Tool. Es vereint API-Design, Debugging, Mocking und automatisierte Tests auf einer einzigen Plattform.
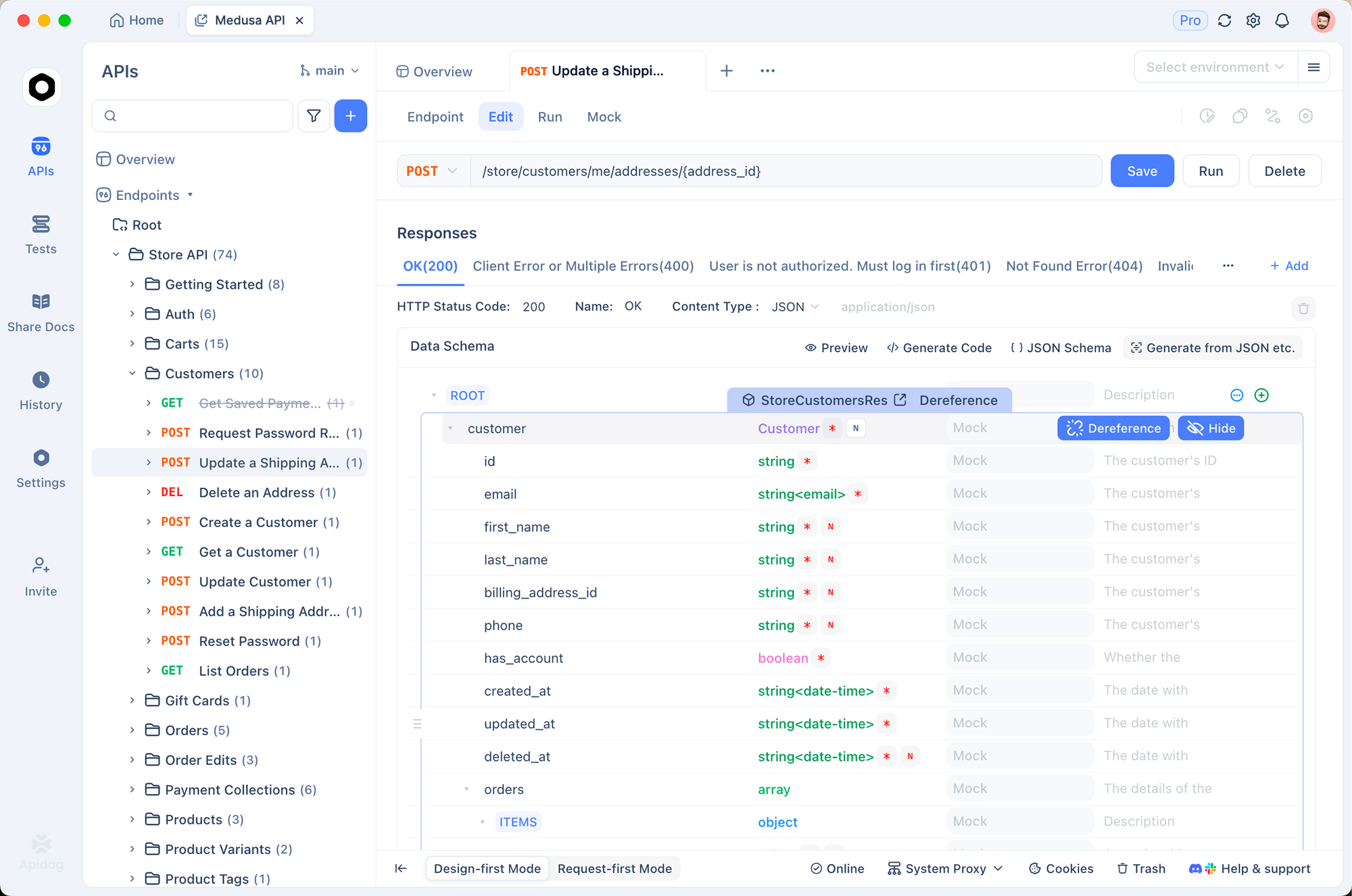
Importieren Sie zunächst den Gemini-Endpunkt in Apidog. Erstellen Sie eine neue Anfrage, die auf die Methode generateContent verweist. Speichern Sie Ihren API-Schlüssel als Umgebungsvariable – Apidog unterstützt mehrere Umgebungen für Entwicklung, Staging und Produktion.
Senden Sie Anfragen visuell. Apidog zeigt Antworten klar an und hebt Token-Nutzung und Fehler hervor. Richten Sie zusätzlich Zusicherungen ein, um Antwortstrukturen automatisch zu validieren.
Für mehrstufige Chats pflegen Sie den Konversationsverlauf über Anfragen hinweg mithilfe von Apidogs Skripting oder Variablen. Dies simuliert reale Benutzersitzungen effizient.
Apidog generiert auch Mock-Server. Simulieren Sie Gemini-Antworten während der Frontend-Entwicklung, ohne Kontingent zu verbrauchen.
Automatisieren Sie außerdem Test-Suites. Definieren Sie Szenarien, die verschiedene Denktiefen, multimodale Eingaben und Fehlerfälle abdecken. Führen Sie diese in CI/CD-Pipelines aus.
Viele Entwickler stellen fest, dass Apidog die Debugging-Zeit im Vergleich zu raw cURL oder grundlegenden Clients erheblich reduziert. Seine intuitive Benutzeroberfläche verarbeitet komplexe JSON-Bodies mühelos.
Best Practices für den Produktionseinsatz
Implementieren Sie eine Wiederholungslogik mit exponentiellem Backoff. Ratenbegrenzungen gelten, insbesondere in der Vorschau.
Cachen Sie Kontexte, wo immer möglich, um Tokens zu minimieren. Verwenden Sie Gedankensignaturen präzise in Raw-Anfragen, um Validierungsfehler zu vermeiden.
Überwachen Sie die Kosten proaktiv. Protokollieren Sie die Anzahl der Eingabe-/Ausgabe-Tokens pro Anfrage.
Halten Sie die Temperatur bei Standard 1.0 – Abweichungen beeinträchtigen die Argumentationsleistung.
Bleiben Sie schließlich über die offiziellen Dokumentationen auf dem Laufenden. Vorschaumodelle entwickeln sich weiter; planen Sie potenzielle Breaking Changes ein.
Fazit
Sie verfügen nun über das Wissen, Gemini 3 Flash effektiv zu integrieren. Beginnen Sie mit einfachen Anfragen und skalieren Sie dann auf multimodale und durch Tools erweiterte Anwendungen. Nutzen Sie Tools wie Apidog, um Entwicklungsworkflows zu optimieren.
Gemini 3 Flash ermöglicht Entwicklern, intelligente, reaktionsschnelle Systeme kostengünstig zu erstellen. Experimentieren Sie frei in AI Studio und wechseln Sie dann zur API für die Bereitstellung.