
Stellen Sie sich vor, Sie hätten die Möglichkeit, Daten von jeder Website zu extrahieren und Erkenntnisse in großem Umfang zu gewinnen – alles mit nur ein paar Zeilen Code. Klingt nach Magie, oder? Nun, Firecrawl macht dies möglich.
In diesem Leitfaden für Anfänger führe ich Sie durch alles, was Sie über Firecrawl wissen müssen, von der Installation bis hin zu fortgeschrittenen Datenextraktionstechniken. Egal, ob Sie Entwickler, Datenanalyst oder einfach nur neugierig auf Web Scraping sind, dieses Tutorial hilft Ihnen, mit Firecrawl zu beginnen und es in Ihre Workflows zu integrieren.

Was ist Firecrawl?
Firecrawl ist eine innovative Web Scraping- und Crawling-Engine, die Website-Inhalte in Formate wie Markdown, HTML und strukturierte Daten umwandelt. Dies macht es ideal für Large Language Models (LLMs) und KI-Anwendungen. Mit Firecrawl können Sie effizient sowohl strukturierte als auch unstrukturierte Daten von Websites sammeln und so Ihren Datenanalyse-Workflow vereinfachen.
Hauptmerkmale von Firecrawl
Crawl: Umfassendes Web Crawling
Mit dem /crawl-Endpunkt von Firecrawl können Sie eine Website rekursiv durchlaufen und Inhalte von allen Unterseiten extrahieren. Diese Funktion ist perfekt, um große Mengen an Webdaten zu entdecken und zu organisieren und sie in LLM-fähige Formate umzuwandeln.
Scrape: Gezielte Datenextraktion
Verwenden Sie die Scrape-Funktion, um bestimmte Daten von einer einzelnen URL zu extrahieren. Firecrawl kann Inhalte in verschiedenen Formaten liefern, darunter Markdown, strukturierte Daten, Screenshots und HTML. Dies ist besonders nützlich, um spezifische Informationen von bekannten URLs zu extrahieren.
Map: Schnelles Site-Mapping
Die Map-Funktion ruft schnell alle URLs ab, die mit einer bestimmten Website verknüpft sind, und bietet so einen umfassenden Überblick über ihre Struktur. Dies ist von unschätzbarem Wert für die Inhaltsentdeckung und -organisation.
Extract: Umwandlung unstrukturierter Daten in ein strukturiertes Format
Der /extract-Endpunkt ist die KI-gestützte Funktion von Firecrawl, die den Prozess des Sammelns strukturierter Daten von Websites vereinfacht. Er übernimmt die schwere Arbeit des Crawlens, Parsens und Organisierens der Daten in einem strukturierten Format.
Erste Schritte mit Firecrawl
Schritt 1: Registrieren und Ihren API-Schlüssel abrufen
Besuchen Sie Firecrawl's oficial website und registrieren Sie sich für ein Konto. Navigieren Sie nach der Anmeldung zu Ihrem Dashboard, um Ihren API-Schlüssel zu finden.
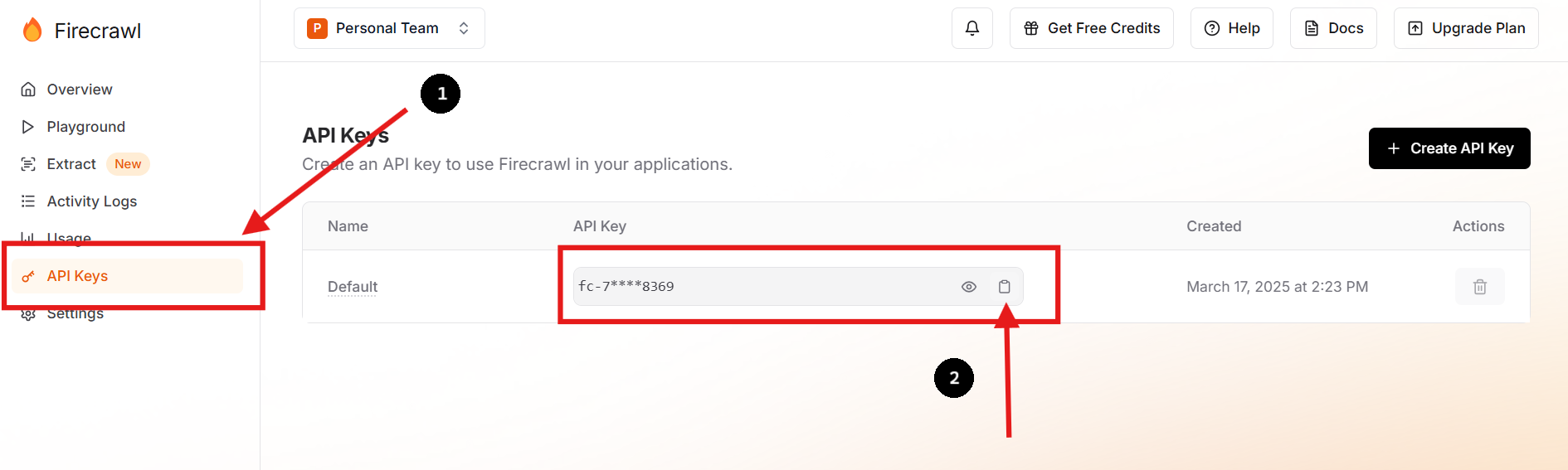
Sie können auch einen neuen API-Schlüssel erstellen und den vorherigen löschen, wenn Sie dies bevorzugen oder müssen.

Schritt 2: Richten Sie Ihre Umgebung ein
Erstellen Sie in Ihrem Projektverzeichnis eine .env-Datei, um Ihren API-Schlüssel sicher als Umgebungsvariable zu speichern. Sie können dies tun, indem Sie die folgenden Befehle in Ihrem Terminal ausführen:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envDieser Ansatz hält sensible Informationen aus Ihrer Hauptcodebasis fern, erhöht die Sicherheit und vereinfacht die Konfigurationsverwaltung.
Schritt 3: Installieren Sie das Firecrawl SDK
Für Python-Benutzer installieren Sie das Firecrawl SDK mit pip:
pip install firecrawl Schritt 4: Verwenden Sie die "Scrape"-Funktion von Firecrawl
Hier ist ein einfaches Beispiel, wie Sie eine Website mit dem Python SDK scrapen können:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define the URL to scrape
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Scrape the website
response = app.scrape_url(url)
# Print the response
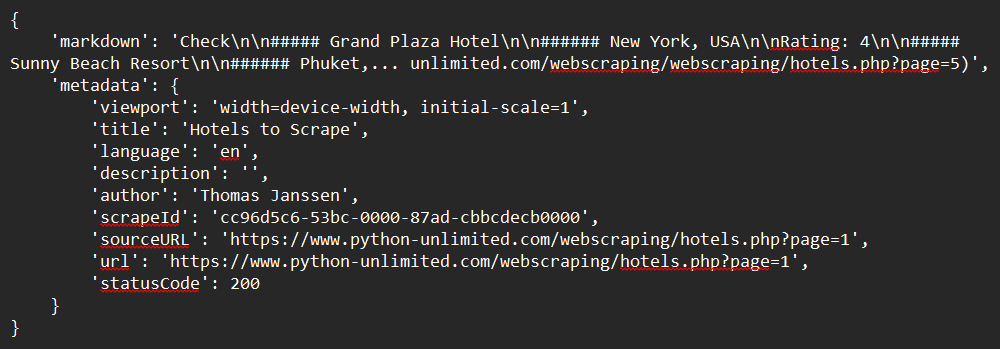
print(response)Beispielausgabe:
Schritt 5: Verwenden Sie die "Crawl"-Funktion von Firecrawl
Hier sehen wir ein einfaches Beispiel, wie man eine Website mit dem Python SDK crawlen kann:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Crawl a website and capture the response:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
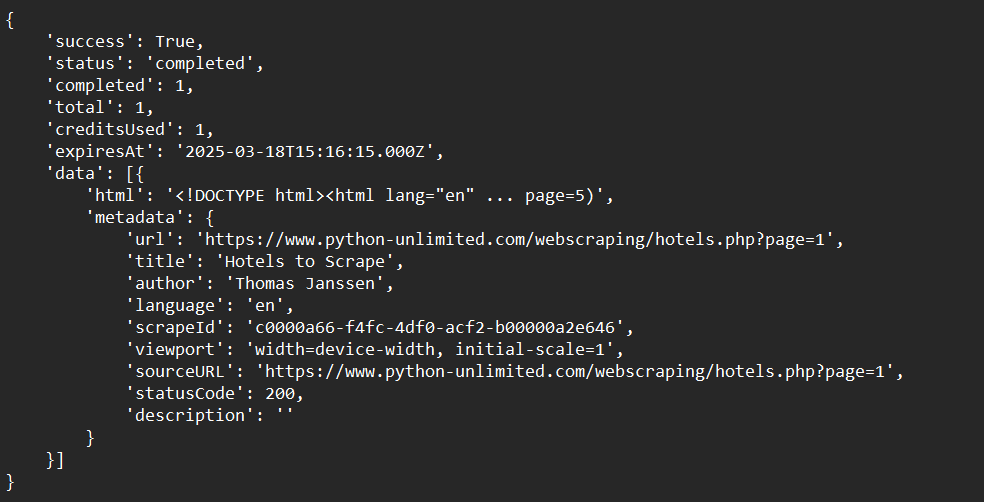
print(crawl_status)Beispielausgabe:
Schritt 6: Verwenden Sie die "Map"-Funktion von Firecrawl
Hier ist ein einfaches Beispiel, wie man Website-Daten mit dem Python SDK mappen kann:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Map a website:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)Beispielausgabe:

Schritt 7: Verwenden Sie die "Extract"-Funktion von Firecrawl (Open Beta)
Im Folgenden finden Sie ein einfaches Beispiel, wie Sie Website-Daten mit dem Python SDK extrahieren können:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Initialize FirecrawlApp with the API key from .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Define schema to extract contents into
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Call the extract function and capture the response
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extract the data provided in the schema.",
'schema': ExtractSchema.model_json_schema()
})
# Print the response
print(response)Beispielausgabe:
Fortgeschrittene Techniken mit Firecrawl
Umgang mit dynamischen Inhalten
Firecrawl kann dynamische JavaScript-basierte Inhalte verarbeiten, indem es Headless-Browser verwendet, um Seiten vor dem Scraping zu rendern. Dadurch wird sichergestellt, dass Sie alle Inhalte erfassen, auch wenn sie dynamisch geladen werden.
Umgehen von Web Scraping-Blockern
Verwenden Sie die integrierten Funktionen von Firecrawl, um gängige Web Scraping-Blocker wie CAPTCHAs oder Ratenbegrenzungen zu umgehen. Dies beinhaltet das Rotieren von User Agents und IP-Adressen, um natürlichen Datenverkehr nachzuahmen.
Integration mit LLMs
Kombinieren Sie Firecrawl mit LLMs wie LangChain, um leistungsstarke KI-Workflows zu erstellen. Sie können beispielsweise Firecrawl verwenden, um Daten zu sammeln und diese dann in ein LLM für Analyse- oder Generierungsaufgaben einzuspeisen.
Behebung häufiger Probleme
Problem: "API-Schlüssel nicht erkannt"
Lösung: Stellen Sie sicher, dass Ihr API-Schlüssel korrekt als Umgebungsvariable oder in einer .env-Datei gespeichert ist.
Problem: "Crawling zu langsam"
Lösung: Verwenden Sie asynchrones Crawling, um den Prozess zu beschleunigen. Firecrawl unterstützt gleichzeitige Anfragen, um die Effizienz zu verbessern.
Problem: "Inhalt nicht korrekt extrahiert"
Lösung: Überprüfen Sie, ob die Website dynamische Inhalte verwendet. Wenn ja, stellen Sie sicher, dass Firecrawl so konfiguriert ist, dass es das JavaScript-Rendering verarbeiten kann.
Fazit
Herzlichen Glückwunsch zum Abschluss dieses umfassenden Anfängerleitfadens zu Firecrawl! Wir haben alles behandelt, was Sie für den Einstieg benötigen – von dem, was Firecrawl ist, bis hin zu detaillierten Installationsanweisungen, Verwendungsbeispielen und erweiterten Anpassungsoptionen. Bis jetzt sollten Sie ein klares Verständnis davon haben, wie Sie:
- Firecrawl einrichten und installieren in Ihrer Entwicklungsumgebung.
- Firecrawl konfigurieren und ausführen, um Daten effizient zu scrapen, crawlen, mappen und extrahieren.
- Fehlerbehebung Ihrer Crawling-Prozesse, um Ihre spezifischen Anforderungen zu erfüllen.
Firecrawl ist ein unglaublich leistungsstarkes Tool, das Ihre Datenextraktions-Workflows erheblich optimieren kann. Seine Flexibilität, Effizienz und einfache Integration machen es zur idealen Wahl für moderne Web-Crawling-Herausforderungen.
Jetzt ist es an der Zeit, Ihre neuen Fähigkeiten in die Praxis umzusetzen. Experimentieren Sie mit verschiedenen Websites, optimieren Sie Ihre Parser und integrieren Sie zusätzliche Tools, um eine wirklich angepasste Lösung zu erstellen, die Ihren individuellen Anforderungen entspricht.
Sind Sie bereit, Ihren Web Scraping-Workflow zu verzehnfachen? Laden Sie Apidog noch heute kostenlos herunter und entdecken Sie, wie es Ihre Firecrawl-Integration verbessern kann!


