
Das Gebiet der künstlichen Intelligenz (KI) expandiert weiterhin rasant, wobei Large Language Models (LLMs) zunehmend anspruchsvolle kognitive Fähigkeiten demonstrieren. Unter diesen Modellen sticht FractalAIResearch/Fathom-R1-14B als bemerkenswertes Modell hervor, das über etwa 14,8 Milliarden Parameter verfügt. Dieses Modell wurde von Fractal AI Research speziell entwickelt, um sich in komplexen mathematischen und allgemeinen Denkaufgaben auszuzeichnen. Was Fathom-R1-14B auszeichnet, ist seine Fähigkeit, dieses hohe Leistungsniveau mit bemerkenswerter Kosteneffizienz und innerhalb eines praktischen 16.384 (16K) Token-Kontextfensters zu erreichen. Dieser Artikel bietet einen technischen Überblick über Fathom-R1-14B, der seine Entwicklung, Architektur, Trainingsprozesse und die gemessene Leistung detailliert beschreibt und eine gezielte Anleitung zu seiner praktischen Implementierung auf der Grundlage etablierter Methoden bietet.
Fractal AI: Die Innovatoren hinter dem Modell

Fathom-R1-14B ist ein Produkt von Fractal AI Research, der Forschungsabteilung von Fractal, einem renommierten KI- und Analyseunternehmen mit Hauptsitz in Mumbai, Indien. Fractal hat sich weltweit einen Ruf für die Bereitstellung von Lösungen für künstliche Intelligenz und erweiterte Analysen für Fortune-500-Unternehmen erworben. Die Entwicklung von Fathom-R1-14B steht in engem Einklang mit Indiens wachsenden Ambitionen im Bereich der künstlichen Intelligenz.
Indiens KI-Bestrebungen
Die Entwicklung dieses Modells ist im Kontext der IndiaAI Mission besonders bedeutsam. Srikanth Velamakanni, Mitbegründer, Group Chief Executive & Vice-Chairman von Fractal, wies darauf hin, dass Fathom-R1-14B eine frühe Demonstration einer größeren Initiative ist. Er erwähnte: "Wir schlugen vor, Indiens erstes großes Denkmodell (LRM) im Rahmen der IndiaAI-Mission zu entwickeln... Dies [Fathom-R1-14B] ist nur ein winziger Beweis dafür, was möglich ist", und spielte damit auf Pläne für eine Reihe von Modellen an, darunter eine viel größere Version mit 70 Milliarden Parametern. Diese strategische Ausrichtung unterstreicht das nationale Engagement für KI-Selbstständigkeit und die Schaffung einheimischer Basismodelle. Fractals breitere Beiträge zur KI umfassen weitere wirkungsvolle Projekte, wie z. B. Vaidya.ai, eine multimodale KI-Plattform für die Gesundheitsunterstützung. Die Veröffentlichung von Fathom-R1-14B als Open-Source-Tool kommt daher nicht nur der globalen KI-Community zugute, sondern ist auch ein wichtiger Erfolg in Indiens sich entwickelnder KI-Landschaft.
Grundlegendes Design und architektonischer Entwurf von Fathom-R1-14B
Die beeindruckenden Fähigkeiten von Fathom-R1-14B basieren auf einer sorgfältig ausgewählten Grundlage und einem robusten architektonischen Design, das für Denkaufgaben optimiert ist.
Die Entwicklung von Fathom-R1-14B begann mit der Auswahl von Deepseek-R1-Distilled-Qwen-14B als Basismodell. Die "destillierte" Natur dieses Modells bedeutet, dass es sich um ein kompakteres und recheneffizienteres Derivat eines größeren übergeordneten Modells handelt, das speziell dafür entwickelt wurde, einen wesentlichen Teil der ursprünglichen Fähigkeiten beizubehalten, insbesondere die der angesehenen Qwen-Familie. Dies bot einen soliden Ausgangspunkt, den Fractal AI Research dann durch spezielle Nachbearbeitungstechniken sorgfältig verbesserte. Für seine Operationen verwendet das Modell typischerweise die Präzision bfloat16 (Brain Floating Point Format), die ein effektives Gleichgewicht zwischen Rechengeschwindigkeit und der numerischen Genauigkeit herstellt, die für komplexe Berechnungen erforderlich ist.
Fathom-R1-14B basiert auf der Qwen2-Architektur, einer leistungsstarken Iteration innerhalb der Transformer-Modellfamilie. Transformer-Modelle sind der aktuelle Standard für hochleistungsfähige LLMs, was hauptsächlich auf ihre innovativen Self-Attention-Mechanismen zurückzuführen ist. Diese Mechanismen ermöglichen es dem Modell, die Bedeutung verschiedener Token – seien es Wörter, Unterwörter oder mathematische Symbole – innerhalb einer Eingabesequenz dynamisch zu gewichten, wenn es seine Ausgabe generiert. Diese Fähigkeit ist entscheidend für das Verständnis der komplizierten Abhängigkeiten, die in komplexen mathematischen Problemen und differenzierten logischen Argumenten vorhanden sind.
Der Maßstab des Modells, der durch etwa 14,8 Milliarden Parameter gekennzeichnet ist, ist ein Schlüsselfaktor für seine Leistung. Diese Parameter, die im Wesentlichen die gelernten numerischen Werte innerhalb der Schichten des neuronalen Netzes sind, kodieren das Wissen und die Denkfähigkeiten des Modells. Ein Modell dieser Größe bietet eine erhebliche Kapazität für die Erfassung und Darstellung komplexer Muster aus seinen Trainingsdaten.
Die Bedeutung des 16K-Kontextfensters
Eine kritische architektonische Spezifikation ist sein 16.384-Token-Kontextfenster. Dies bestimmt die maximale Länge der kombinierten Eingabeaufforderung und der vom Modell generierten Ausgabe, die in einem einzigen Vorgang verarbeitet werden kann. Während einige Modelle mit viel größeren Kontextfenstern aufwarten, ist die 16K-Kapazität von Fathom-R1-14B eine bewusste und pragmatische Designentscheidung. Sie ist ausreichend groß, um detaillierte Problemstellungen, umfangreiche Schritt-für-Schritt-Denkketten (wie sie oft in Mathematik auf Olympiade-Niveau erforderlich sind) und umfassende Antworten zu berücksichtigen. Wichtig ist, dass dies erreicht wird, ohne die quadratische Skalierung der Rechenkosten zu verursachen, die mit den Aufmerksamkeitsprozessen in extrem langen Sequenzen verbunden sein kann, wodurch Fathom-R1-14B agiler und weniger ressourcenintensiv während der Inferenz wird.
Fathom-R1-14B ist wirklich, wirklich kosteneffektiv
Einer der auffälligsten Aspekte von Fathom-R1-14B ist die Effizienz seines Nachbearbeitungsprozesses. Die primäre Version des Modells wurde für Kosten von etwa 499 USD optimiert. Diese bemerkenswerte wirtschaftliche Tragfähigkeit wurde durch eine ausgeklügelte, vielschichtige Trainingsstrategie erreicht, die sich darauf konzentrierte, die Denkfähigkeiten zu maximieren, ohne übermäßige Rechenausgaben zu verursachen.
Zu den Kerntechniken, die dieser effizienten Spezialisierung zugrunde liegen, gehörten:
- Supervised Fine-Tuning (SFT): Diese grundlegende Phase umfasste das Trainieren des Basismodells auf einem hochwertigen, kuratierten Datensatz von Problem-Lösungs-Paaren, der speziell auf fortgeschrittenes mathematisches Denken zugeschnitten war. Durch SFT lernte das Modell, korrekte Problemlösungswege und logische Ableitungen nachzuahmen.
- Iteratives Curriculum Learning: Anstatt das Modell dem gesamten Spektrum der Schwierigkeiten auf einmal auszusetzen, führt diese Strategie Herausforderungen in graduierter Weise ein. Das Modell beginnt mit einfacheren mathematischen Problemen und geht schrittweise zu komplexeren Problemen über, wie z. B. denen aus AIME und HMMT. Dieser strukturierte Ansatz erleichtert ein stabileres und effektiveres Lernen, so dass das Modell eine solide Grundlage aufbauen kann, bevor es sich an hochanspruchsvolle Aufgaben macht. Diese Technik war von zentraler Bedeutung für die Entwicklung eines wichtigen Vorläufermodells,
Fathom-R1-14B-V0.6. - Model Merging: Das endgültige Fathom-R1-14B-Modell ist eine Verschmelzung von zwei speziell optimierten Vorgängermodellen:
Fathom-R1-14B-V0.6(das ein iteratives Curriculum SFT durchlief) undFathom-R1-14B-V0.4(das sich auf SFT mit "Shortest-Chains" konzentrierte und wahrscheinlich die Prägnanz in den Lösungen betonte). Durch das Zusammenführen von Modellen, die mit leicht unterschiedlichen Schwerpunkten trainiert wurden, erbt das resultierende Modell eine breitere Palette von Stärken.
Das übergeordnete Ziel dieses akribischen Trainingsprozesses war es, "präzises, aber genaues mathematisches Denken" zu vermitteln.
Fractal AI Research untersuchte auch einen alternativen Trainingsweg mit einer Variante namens Fathom-R1-14B-RS. Diese Version enthielt Reinforcement Learning (RL), insbesondere unter Verwendung eines Algorithmus namens GRPO (Generalized Reward Pushing Optimization), zusammen mit SFT. Während dieser Ansatz eine vergleichbare hohe Leistung erbrachte, waren seine Nachbearbeitungskosten mit 967 USD etwas höher. Die Entwicklung beider Versionen unterstreicht das Engagement für die Erforschung verschiedener Methoden, um eine optimale Denkweise effizient zu erreichen. Im Rahmen ihres Engagements für Transparenz hat Fractal AI Research die Trainingsrezepte und Datensätze als Open Source veröffentlicht.
Leistungs-Benchmarks: Quantifizierung von Exzellenz im Denken
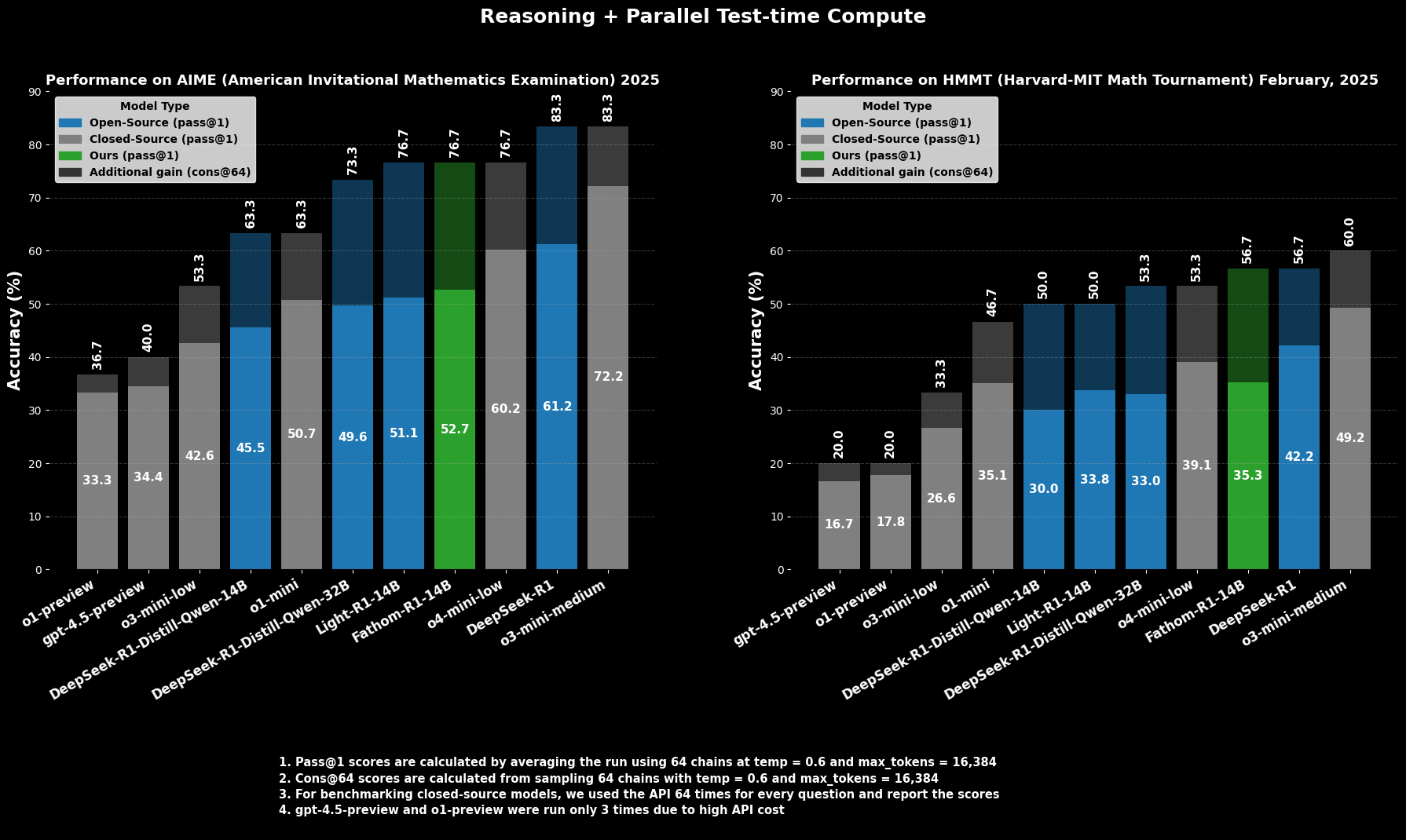
Die Leistungsfähigkeit von Fathom-R1-14B ist nicht nur theoretisch, sondern wird durch beeindruckende Leistungen bei strengen, international anerkannten mathematischen Denkbenchmarks untermauert.
Erfolg bei AIME und HMMT
Bei der AIME2025 (American Invitational Mathematics Examination), einem anspruchsvollen Mathematikwettbewerb vor dem College, erreicht Fathom-R1-14B eine Pass@1-Genauigkeit von 52,71 %. Die Metrik Pass@1 gibt den Prozentsatz der Probleme an, für die das Modell in einem einzigen Versuch eine korrekte Lösung generiert. Wenn dem Modell mehr Rechenbudget zur Testzeit zugestanden wird, bewertet mit cons@64 (Konsistenz unter 64 Stichprobenlösungen), steigt seine Genauigkeit bei AIME2025 auf beeindruckende 76,7 %.
In ähnlicher Weise erzielt das Modell beim HMMT25 (Harvard-MIT Mathematics Tournament), einem weiteren Wettbewerb auf hohem Niveau, 35,26 % Pass@1, was auf 56,7 % cons@64 ansteigt. Diese Ergebnisse sind besonders bemerkenswert, da sie innerhalb des 16K-Token-Ausgabebudgets des Modells erzielt werden, was praktische Einsatzüberlegungen widerspiegelt.
Vergleichende Leistung
In vergleichenden Auswertungen übertrifft Fathom-R1-14B andere Open-Source-Modelle ähnlicher oder sogar größerer Größe auf diesen spezifischen mathematischen Benchmarks bei Pass@1 deutlich. Noch auffälliger ist, dass seine Leistung, insbesondere unter Berücksichtigung der Metrik cons@64, es als wettbewerbsfähig mit einigen leistungsfähigen Closed-Source-Modellen positioniert, von denen oft angenommen wird, dass sie Zugang zu weitaus größeren Ressourcen haben. Dies unterstreicht die Effizienz von Fathom-R1-14B bei der Umsetzung seiner Parameter und seines Trainings in ein hochwertiges Denken.
Versuchen wir, Fathom-R1-14B auszuführen
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Dieser Abschnitt bietet eine gezielte Anleitung zum Ausführen von Fathom-R1-14B mit der Hugging Face transformers-Bibliothek in einer Python-Umgebung. Dieser Ansatz ist gut geeignet für Benutzer mit Zugriff auf leistungsfähige GPU-Hardware, entweder lokal oder über Cloud-Anbieter. Die hier beschriebenen Schritte folgen eng den etablierten Praktiken für den Einsatz solcher Modelle.
Umgebungskonfiguration
Die Einrichtung einer geeigneten Python-Umgebung ist entscheidend. Die folgenden Schritte beschreiben eine gängige Einrichtung mit Conda auf einem Linux-basierten System (oder Windows Subsystem for Linux):
Zugriff auf Ihren Computer: Wenn Sie eine Remote-Cloud-GPU-Instanz verwenden, stellen Sie über SSH eine Verbindung zu dieser her.Bash
# Beispiel: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Überprüfen der GPU-Erkennung: Stellen Sie sicher, dass das System die NVIDIA-GPU erkennt und die Treiber korrekt installiert sind.Bash
nvidia-smi
Erstellen und Aktivieren einer Conda-Umgebung: Es ist eine gute Praxis, Projektabhängigkeiten zu isolieren.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Installieren der erforderlichen Bibliotheken: Installieren Sie PyTorch (kompatibel mit Ihrer CUDA-Version), Hugging Face transformers, accelerate (für effizientes Laden und Verteilen von Modellen), notebook (für Jupyter) und ipywidgets (für Notebook-Interaktivität).Bash
# Stellen Sie sicher, dass Sie eine PyTorch-Version installieren, die mit dem CUDA-Toolkit Ihrer GPU kompatibel ist
# Beispiel für CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Oder für CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Python-basierte Inferenz in einem Jupyter Notebook
Mit der vorbereiteten Umgebung können Sie ein Jupyter Notebook verwenden, um Fathom-R1-14B zu laden und mit ihm zu interagieren.
Starten des Jupyter Notebook-Servers: Wenn Sie sich auf einem Remote-Server befinden, starten Sie Jupyter Notebook, um den Remote-Zugriff zu ermöglichen und einen Port anzugeben.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Wenn Sie remote arbeiten, müssen Sie wahrscheinlich die SSH-Portweiterleitung von Ihrem lokalen Computer einrichten, um auf die Jupyter-Oberfläche zuzugreifen:Bash
# Beispiel: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Öffnen Sie dann http://localhost:8889 (oder Ihren gewählten lokalen Port) in Ihrem Webbrowser.
Python-Code für die Modellinteraktion: Erstellen Sie ein neues Jupyter Notebook und verwenden Sie den folgenden Python-Code:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Definieren Sie die Modell-ID von Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Laden des Tokenizers für {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Laden des Modells {model_id} (dies kann eine Weile dauern)...")
# Laden Sie das Modell mit bfloat16-Präzision für Effizienz und device_map für die automatische Verteilung
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Verwenden Sie bfloat16, wenn Ihre GPU dies unterstützt
device_map="auto", # Verteilt Modellschichten automatisch auf die verfügbare Hardware
trust_remote_code=True # Einige Modelle erfordern dies möglicherweise
)
print("Modell und Tokenizer erfolgreich geladen.")
# Definieren Sie eine mathematische Beispielaufforderung
prompt = """Frage: Natalia verkaufte im April Clips an 48 ihrer Freunde und dann verkaufte sie im Mai halb so viele Clips. Im Juni verkaufte sie 4 weitere Clips als im Mai. Wie viele Clips hat Natalia insgesamt im April, Mai und Juni verkauft? Geben Sie eine Schritt-für-Schritt-Lösung an.
Lösung:"""
print(f"\nAufforderung:\n{prompt}")
# Tokenisieren Sie die Eingabeaufforderung
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Stellen Sie sicher, dass die Eingaben sich auf dem Gerät des Modells befinden
print("\nGenerieren der Lösung...")
# Generieren Sie die Ausgabe aus dem Modell
# Passen Sie die Generierungsparameter nach Bedarf für verschiedene Arten von Problemen an
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximale Anzahl neuer Token, die für die Lösung generiert werden sollen
num_return_sequences=1, # Anzahl der unabhängigen Sequenzen, die generiert werden sollen
temperature=0.1, # Niedrigere Temperatur für deterministischere, faktische Ausgaben
top_p=0.7, # Verwenden Sie das Nucleus-Sampling mit top_p
do_sample=True # Aktivieren Sie das Sampling, damit Temperatur und top_p einen Effekt haben
)
# Decodieren Sie die generierten Token in eine Zeichenkette
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerierte Lösung:\n")
print(solution_text)
Fazit: Die Auswirkungen von Fathom-R1-14B auf zugängliche KI
FractalAIResearch/Fathom-R1-14B ist ein überzeugender Beweis für technischen Einfallsreichtum in der zeitgenössischen KI-Arena. Sein spezifisches Design mit etwa 14,8 Milliarden Parametern, der Qwen2-Architektur und einem 16K-Token-Kontextfenster hat in Kombination mit bahnbrechendem und kostengünstigem Training (etwa 499 $ für die primäre Version) zu einem LLM geführt, das führende Leistung erbringt. Dies wird durch seine Ergebnisse bei anstrengenden mathematischen Denkbenchmarks wie AIME und HMMT belegt.
Fathom-R1-14B veranschaulicht überzeugend, dass die Grenzen des KI-Denkens durch intelligentes Design und effiziente Methoden vorangetrieben werden können, wodurch eine Zukunft gefördert wird, in der Hochleistungs-KI demokratischer und weitreichender von Vorteil ist.
Benötigen Sie eine integrierte All-in-One-Plattform für Ihr Entwicklerteam, um mit maximaler Produktivität zusammenzuarbeiten?
Apidog liefert alle Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!


