
Entwickler wenden sich zunehmend serverlosen Plattformen für die KI-Inferenz zu, und die Fal.ai API erweist sich als robuste Option für generative Medien. Diese API ermöglicht es Ihnen, Modelle für Bild-, Video-, Sprach- und Codegenerierung auszuführen, ohne die Infrastruktur verwalten zu müssen. Sie greifen über eine einheitliche Schnittstelle auf über 600 produktionsbereite Modelle zu, die effizient mit On-Demand-GPUs skaliert werden.
Als Nächstes erkunden wir die Grundlagen der Fal.ai API und führen Sie durch deren Zugriff und Nutzung.
Was ist die Fal.ai API?
Fal.ai API bietet eine generative Medienplattform, die Anwendungen mit schneller KI-Inferenz versorgt. Ingenieure nutzen sie, um modernste Modelle in Software zu integrieren, wodurch die Notwendigkeit der Serververwaltung entfällt. Die Plattform bietet eine 10-mal schnellere Leistung im Vergleich zu herkömmlichen Setups, dank optimierter serverloser GPUs, die auf Tausende von H100-Äquivalenten skaliert werden.

Im Kern konzentriert sich die Fal.ai API auf die Mediengenerierung. Zum Beispiel können Sie hochauflösende Bilder aus Textaufforderungen (Prompts) mit Modellen wie FLUX.1 generieren. Darüber hinaus unterstützt sie Videoanimation, Speech-to-Text und Interaktionen mit großen Sprachmodellen. Die API legt jedoch Wert auf Produktionsreife, mit Funktionen wie Streaming-Inferenz und Webhook-Unterstützung für asynchrone Aufgaben.
Darüber hinaus basiert die Fal.ai API auf einem Pay-per-Use-Modell, was die Kosten vorhersehbar hält. Sie zahlen nur für die genutzte Rechenleistung, wodurch sie sowohl für Prototypen als auch für skalierte Anwendungen geeignet ist. Um zu den Details überzugehen, schauen wir uns an, wie Sie sich anmelden.
Wie melde ich mich für die Fal.ai API an?
Sie beginnen mit der Erstellung eines Kontos auf der Fal.ai-Website. Navigieren Sie zu fal.ai und suchen Sie den Anmelde-Button in der oberen rechten Ecke. Geben Sie Ihre E-Mail-Adresse ein, legen Sie ein Passwort fest und bestätigen Sie Ihr Konto über die Bestätigungs-E-Mail. Dieser Vorgang dauert weniger als eine Minute.
Nach der Registrierung greifen Sie auf das Dashboard zu. Hier verwalten Sie Modelle, sehen Nutzungsstatistiken ein und generieren API-Schlüssel. Fal.ai erfordert für die Erstanmeldung keine Kreditkarte, aber Sie können später Zahlungsdetails für kostenpflichtige Funktionen hinzufügen. Darüber hinaus bietet die Plattform einen kostenlosen Tarif mit begrenzten Credits, der Ihnen das Testen grundlegender Funktionen ermöglicht.
Nach der Anmeldung erkunden Sie den Modellkatalog. Sie wählen aus Kategorien wie Text-zu-Bild oder Text-zu-Video. Dieser Schritt macht Sie mit den verfügbaren Endpunkten vertraut. Mit einem fertigen Konto können Sie nun Ihren API-Schlüssel abrufen.
Wie erhalte ich meinen Fal.ai API-Schlüssel?
Die Fal.ai API stützt sich zur Authentifizierung auf API-Schlüssel. Sie generieren einen über das Dashboard. Melden Sie sich zuerst an und klicken Sie unter Ihrem Profil auf den Abschnitt "Keys". Wählen Sie dann "Generate New Key" und benennen Sie ihn zu Referenzzwecken, z. B. "Development Key".
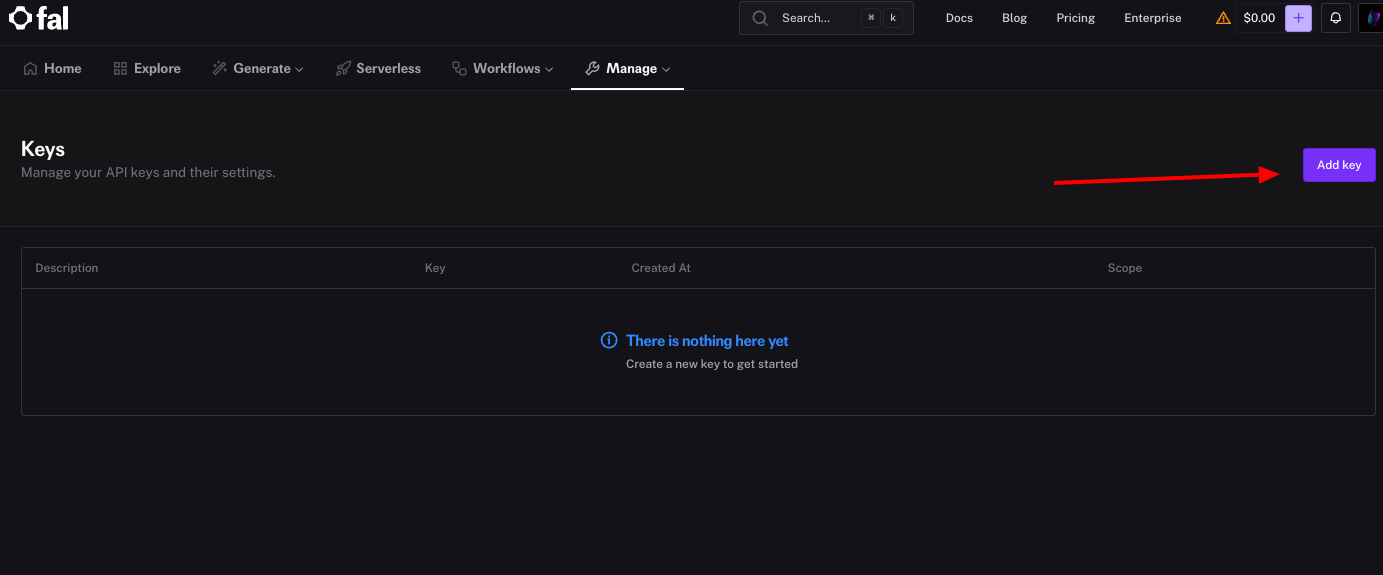
Das System zeigt den Schlüssel sofort an – kopieren Sie ihn und speichern Sie ihn sicher, da Fal.ai ihn nicht erneut anzeigen wird. Sie legen diesen Schlüssel als Umgebungsvariable fest, z. B. export FAL_KEY="your_key_here", um ein Hardcoding in Skripten zu vermeiden.
Wenn Sie mit mehreren Projekten arbeiten, generieren Sie für jedes separate Schlüssel. Diese Vorgehensweise erhöht die Sicherheit, indem sie den Widerruf ermöglicht, ohne andere Integrationen zu beeinträchtigen. Überwachen Sie außerdem die Schlüsselnutzung im Dashboard, um Anomalien zu erkennen. Mit dem Schlüssel in der Hand installieren Sie als Nächstes die Client-Bibliothek.
Wie installiere ich den Fal.ai Client?
Fal.ai bietet offizielle Client-Bibliotheken für eine einfachere Integration. Für JavaScript- oder Node.js-Umgebungen installieren Sie den Client über npm. Führen Sie den Befehl npm install --save @fal-ai/client in Ihrem Projektverzeichnis aus.
Diese Bibliothek übernimmt die Authentifizierung, die Anforderungseinreichung und das Parsen von Antworten. Sie ersetzt das veraltete @fal-ai/serverless-client, stellen Sie also sicher, dass Sie die neueste Version verwenden. Für Python-Benutzer installieren Sie fal-client mit pip install fal-client.
Nach der Installation importieren Sie die Bibliothek in Ihren Code. Zum Beispiel in JavaScript: import { fal } from "@fal-ai/client";. Sie konfigurieren sie mit Ihren Zugangsdaten, wenn Sie keine Umgebungsvariablen verwenden. Dieses Setup vereinfacht Aufrufe an Fal.ai API-Endpunkte. Im weiteren Verlauf wird die Authentifizierung zum nächsten kritischen Schritt.
Wie authentifiziere ich Anfragen mit der Fal.ai API?
Die Authentifizierung sichert Ihre Interaktionen mit der Fal.ai API. Sie verwenden den API-Schlüssel hauptsächlich in Headern oder Umgebungsvariablen. Für direkte HTTP-Anfragen fügen Sie Authorization: Key your_fal_key im Header ein.
Die Client-Bibliothek automatisiert dies jedoch. Konfigurieren Sie sie einmalig: fal.config({ credentials: "your_fal_key" });. Dieser Ansatz verhindert die Offenlegung in clientseitigem Code – leiten Sie Anfragen immer über einen Proxy, wenn Sie Webanwendungen erstellen.
Die Fal.ai API unterstützt derzeit keine anderen Authentifizierungsmethoden wie OAuth. Testen Sie die Authentifizierung, indem Sie eine einfache Anfrage stellen; ein 401-Fehler deutet auf Probleme hin. Drehen Sie Schlüssel außerdem regelmäßig, um bewährte Sicherheitspraktiken zu gewährleisten. Nun authentifiziert, erkunden Sie die verfügbaren Modelle.
Welche Modelle sind in der Fal.ai API verfügbar?
Die Fal.ai API hostet eine vielfältige Modellbibliothek. Schlüsselkategorien umfassen Text-zu-Bild, Text-zu-Video, Speech-to-Text und große Sprachmodelle. Zum Beispiel generiert FLUX.1 [dev] Bilder aus Prompts mit seinem 12-Milliarden-Parameter-Transformer.
Weitere bemerkenswerte Modelle: FLUX.1 [schnell] für schnelle Generierung in 1-4 Schritten, Stable Diffusion 3.5 für typografisch anspruchsvolle Bilder und Whisper für Audio-Transkription. Sie greifen über eindeutige IDs wie "fal-ai/flux/dev" darauf zu.
Durchsuchen Sie den Modell-Spielplatz unter fal.ai/models, um interaktiv zu testen. Jede Modellseite enthält Details zu Parametern, Beispielen und Preisen. Diese Vielfalt ermöglicht maßgeschneiderte Auswahlen. Wählen Sie zum Beispiel Recraft V3 für Vektorgrafiken. Nachdem die Modelle identifiziert wurden, lernen Sie, Bilder zu generieren.
Wie generiere ich Bilder mit der Fal.ai API?
Sie generieren Bilder, indem Sie einen Modell-Endpunkt abonnieren. Verwenden Sie den Client, um eine POST-Anfrage mit Eingabeparametern zu senden. Für FLUX.1 [dev] sieht der Code wie folgt aus:
import { fal } from "@fal-ai/client";
const result = await fal.subscribe("fal-ai/flux/dev", {
input: {
prompt: "A futuristic cityscape at dusk, with neon lights and flying cars",
image_size: "landscape_16_9",
num_inference_steps: 28,
guidance_scale: 3.5
}
});
console.log(result.images[0].url);
Diese Anfrage erzeugt eine Bild-URL. Die API verarbeitet den Prompt und gibt Metadaten wie Timings und Seed zurück. Aktivieren Sie zusätzlich Sicherheitsprüfungen, um NSFW-Inhalte zu filtern: enable_safety_checker: true.
Testen Sie Variationen, indem Sie Prompts anpassen. Für die Batch-Generierung setzen Sie num_images: 4. Die Ausgaben umfassen URLs, Dimensionen und Inhaltstypen. Diese Methode bildet die Grundlage für Medienaufgaben. Als Nächstes passen Sie mit erweiterten Parametern an.
Erweiterte Nutzung: Parameter und Anpassung in der Fal.ai API
Die Fal.ai API bietet umfangreiche Parameter zur Feinabstimmung. Bei der Bilderzeugung steuert prompt den Inhalt, während guidance_scale die Einhaltung kontrolliert – höhere Werte führen zu strengeren Ergebnissen, typischerweise zwischen 1.0 und 20.0.
Setzen Sie image_size als Enums wie "square_hd" oder benutzerdefinierte Objekte: { width: 1024, height: 768 }. Inferenzschritte (num_inference_steps) balancieren Geschwindigkeit und Qualität aus; 20-50 funktioniert gut. Seed gewährleistet Reproduzierbarkeit: Geben Sie eine Ganzzahl für konsistente Ausgaben an.
Beschleunigungsmodi ("none", "regular", "high") optimieren die Laufzeit. Für die Ausgabe wählen Sie "jpeg" oder "png" über output_format. Verarbeiten Sie Dateien durch Hochladen über fal.storage.upload(file) oder durch Verwendung von URLs/Base64.
Passen Sie weiter an mit Webhooks für Benachrichtigungen. Diese Optionen verbessern die Kontrolle. Überwachen Sie jedoch die Kosten, da mehr Schritte die Abrechnung erhöhen. Um zur Effizienz überzugehen, folgt die asynchrone Handhabung.
Wie gehe ich mit asynchronen Anfragen und Warteschlangen in der Fal.ai API um?
Die Fal.ai API unterstützt Warteschlangen für lange Aufgaben. Senden Sie über fal.queue.submit(model_id, { input: {...} }) und erhalten Sie eine request_id. Abfrage des Status: fal.queue.status(model_id, { requestId: "id" }).
Ergebnisse abrufen: fal.queue.result(model_id, { requestId: "id" }). Fügen Sie webhookUrl für Callbacks hinzu. Dies entkoppelt die Übermittlung vom Warten, ideal für die Stapelverarbeitung.
Streaming bietet Echtzeit-Updates:
const stream = await fal.stream("fal-ai/flux/dev", { input: {...} });
for await (const event of stream) {
console.log(event);
}
const result = await stream.done();
Warteschlangen verhindern Timeouts. Darüber hinaus helfen Logs (logs: true) beim Debugging. Nachdem Sie die asynchrone Verarbeitung beherrschen, integrieren Sie Testtools wie Apidog.
Wie integriere ich die Fal.ai API mit Apidog?
Apidog verbessert die Entwicklung der Fal.ai API, indem es eine einheitliche Plattform zum Testen bietet. Erstellen Sie zunächst ein Projekt in Apidog und importieren Sie das OpenAPI-Schema von fal.ai/docs (z. B. /api/openapi/queue/openapi.json?endpoint_id=fal-ai/flux/dev).
Authentifizierung konfigurieren: Fügen Sie Authorization: Key your_fal_key in den Headern hinzu. Richten Sie Anfragen für Endpunkte wie POST an "fal-ai/flux/dev" ein, einschließlich JSON-Payloads mit prompt und Parametern.
Apidog simuliert Antworten, indem es GPU-Verzögerungen und Ausgaben nachbildet. Laden Sie Dateien für Bildbearbeitungen hoch oder testen Sie Grenzfälle. Führen Sie Sammlungen aus, um Szenarien abzudecken, und debuggen Sie Prompts iterativ.
Zu den Vorteilen gehören schnellere Iterationen (bis zu 40% berichtet), Kosteneinsparungen durch Mocks und Fehlererkennung (z. B. 429 Ratenbegrenzungen). Teamkollaborationsfunktionen gewährleisten Konsistenz. Diese Integration optimiert Workflows. Als Nächstes wenden Sie Best Practices an.
Best Practices für die Nutzung der Fal.ai API
Optimieren Sie die Leistung, indem Sie geeignete Modelle auswählen – verwenden Sie schnellere Varianten für höhere Geschwindigkeit. Begrenzen Sie Datenpunkte in Anfragen, um Latenz zu vermeiden. Implementieren Sie zusätzlich Caching für wiederholte Prompts.
Sichern Sie Schlüssel mit Umgebungsvariablen und Proxys. Überwachen Sie die Nutzung über das Dashboard, um Kosten zu kontrollieren. Führen Sie Batch-Anfragen durch, wo möglich, beachten Sie aber die Ratenbegrenzungen.
Verwenden Sie für die Produktion dedizierte Cluster für hohe Lasten. Testen Sie gründlich mit Mocks in Apidog. Treten Sie außerdem dem Fal.ai Discord bei, um Einblicke in die Community zu erhalten. Diese Praktiken gewährleisten zuverlässige Integrationen. Fehler treten jedoch auf, behandeln Sie sie daher ordnungsgemäß.
Wie gehe ich mit Fehlern in der Fal.ai API um?
Die Fal.ai API gibt strukturierte Fehler zurück. Client-Probleme (z. B. Validierung) führen zu 4xx-Codes mit Details wie "Invalid prompt." Serverfehler sind 5xx, oft transient – versuchen Sie es mit exponentiellem Backoff erneut.
Häufige Fehler: 401 (Authentifizierung fehlgeschlagen) – Schlüssel prüfen; 429 (Ratenbegrenzung) – warten und Frequenz reduzieren; 400 (ungültige Eingabe) – Parameter validieren.
Fangen Sie Ausnahmen im Code ab:
try {
const result = await fal.subscribe(...);
} catch (error) {
console.error(error.response.data);
}
Logs helfen bei der Diagnose. Apidog simuliert Fehler zum Testen. Eine ordnungsgemäße Fehlerbehandlung gewährleistet Robustheit. Betrachten Sie abschließend die Preisgestaltung.
Was kostet die Fal.ai API?
Die Fal.ai API verwendet ein Pay-per-Use-Preismodell. Serverless wird pro Ausgabe abgerechnet, z. B. 0,0001 $ pro Megapixel für Bilder. Videomodelle wie Veo 3 kosten 0,20 $ pro Sekunde (Audio ausgeschaltet).
Der kostenlose Tarif bietet anfängliche Credits. Upgraden Sie für mehr über das Dashboard. Die stündliche GPU-Preisgestaltung beginnt bei 1,2 $ für H100s im Compute-Modus.
Verfolgen Sie Ausgaben im Dashboard. Optimieren Sie durch Reduzierung der Schritte oder Verwendung schnellerer Modelle. Dieses Modell eignet sich für variable Arbeitslasten. Zusammenfassend ermöglicht die Fal.ai API eine effiziente KI-Entwicklung.
Fazit
Sie verstehen nun umfassend, wie Sie auf die Fal.ai API zugreifen und sie nutzen können. Von der Anmeldung und Schlüsselgenerierung bis hin zu fortgeschrittenen Integrationen mit Apidog – dieser Leitfaden rüstet Sie für produktionsreife Anwendungen aus. Experimentieren Sie mit Modellen, behandeln Sie Fehler sorgfältig und überwachen Sie die Kosten. Während sich die KI weiterentwickelt, bleibt die Fal.ai API ein vielseitiges Werkzeug. Beginnen Sie noch heute mit dem Bauen.