
Ingenieure und Entwickler suchen oft nach robusten Tools, um fortschrittliche Sprachmodelle in ihre Anwendungen zu integrieren. Die EXAONE API von LG AI Research, gehostet auf Plattformen wie Together AI, sticht als leistungsstarke Option hervor. Diese Schnittstelle ermöglicht es Ihnen, Aufgaben von der Textvervollständigung bis zur multimodalen Verarbeitung durchzuführen.
EXAONE entwickelt sich zu einer zweisprachigen Modellfamilie, die Englisch und Koreanisch unterstützt, mit Varianten wie der 32B-Parameterversion, die sich in Argumentation, Mathematik und Code auszeichnet. Entwickler nutzen es über gehostete Dienste oder lokale Setups. Zuerst sollten Sie die Kernfunktionen verstehen. Dann gehen Sie zu den praktischen Implementierungsschritten über.
Die EXAONE API-Architektur verstehen
EXAONE repräsentiert das Engagement von LG AI Research, künstliche Intelligenz durch Sprachmodelle auf Expertenniveau zu demokratisieren. Die API-Architektur unterstützt mehrere Modellvarianten, darunter EXAONE 3.0, EXAONE 3.5, EXAONE 4.0 und EXAONE Deep, die jeweils für spezifische Anwendungsfälle optimiert sind.
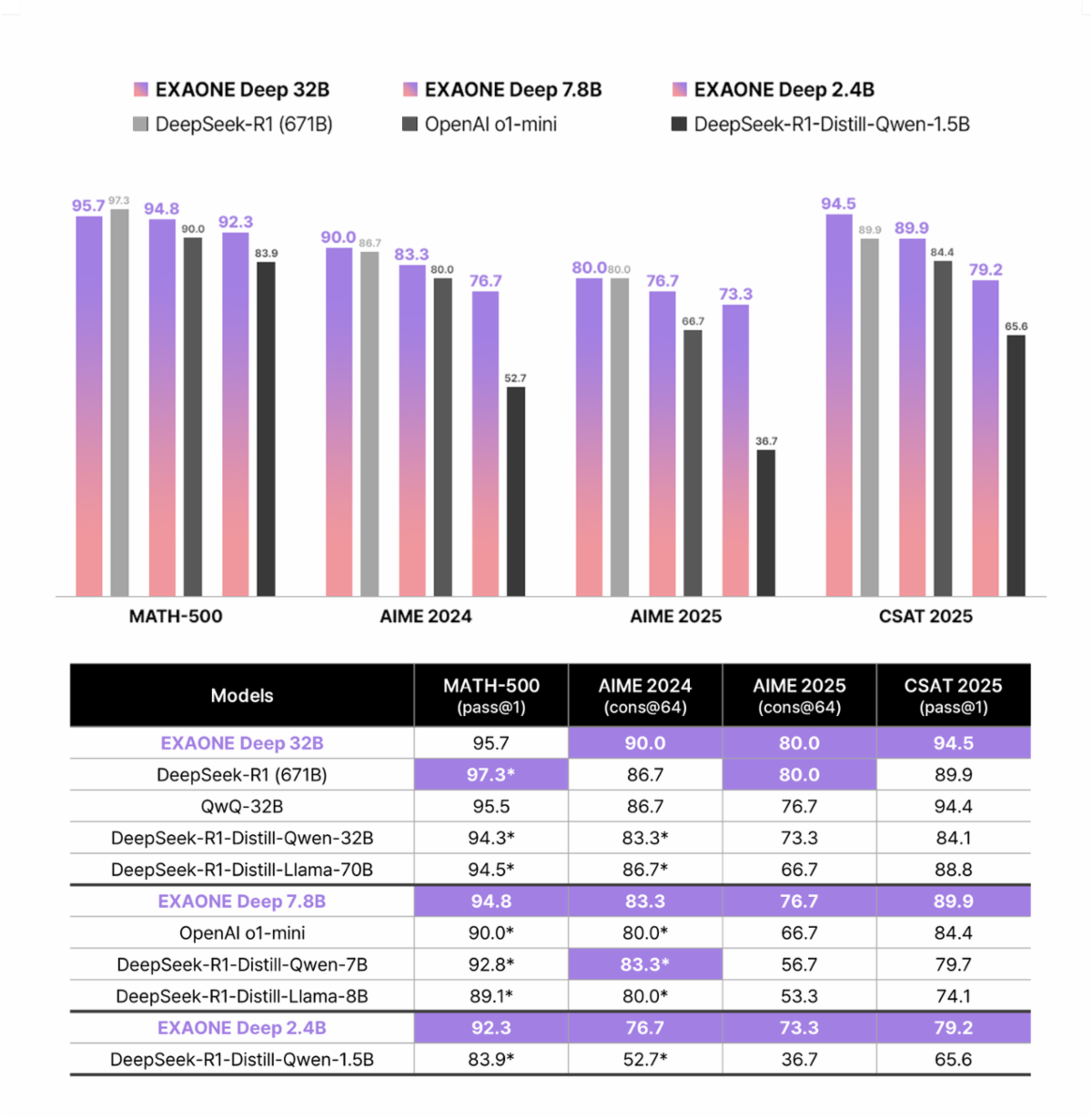
Die neueste EXAONE 4.0 führt bahnbrechende hybride Aufmerksamkeitsmechanismen ein. Im Gegensatz zu traditionellen Transformer-Architekturen kombiniert EXAONE 4.0 lokale Aufmerksamkeit mit globaler Aufmerksamkeit in einem Verhältnis von 3:1 für die 32B-Modellvariante. Darüber hinaus implementiert die Architektur QK-Reorder-Norm, wodurch LayerNorm von traditionellen Pre-LN-Schemata neu positioniert wird, um direkt auf Aufmerksamkeits- und MLP-Ausgaben angewendet zu werden.

Darüber hinaus unterstützen EXAONE-Modelle zweisprachige Funktionen in Englisch und Koreanisch. Jüngste Updates erweitern die mehrsprachige Unterstützung um Spanisch, wodurch die API für internationale Anwendungen geeignet ist. Die Modellreihe reicht von leichten 1,2B-Parametern für On-Device-Anwendungen bis hin zu robusten 32B-Parametern für Hochleistungsanforderungen.
Erste Schritte mit der EXAONE API-Einrichtung
Systemanforderungen und Voraussetzungen
Bevor Sie die EXAONE API implementieren, stellen Sie sicher, dass Ihre Entwicklungsumgebung die Mindestanforderungen erfüllt. Die API funktioniert effektiv auf verschiedenen Plattformen, einschließlich Cloud-basierter Bereitstellungen und lokaler Installationen. Spezifische Hardwareanforderungen hängen jedoch von Ihrer gewählten Bereitstellungsmethode ab.
Für lokale Bereitstellungsszenarien sollten Sie die Speicheranforderungen basierend auf der Modellgröße berücksichtigen. Das 1,2B-Modell benötigt etwa 2,4 GB RAM, während das 32B-Modell wesentlich mehr Ressourcen benötigt. Cloud-Bereitstellungsoptionen eliminieren diese Einschränkungen und bieten gleichzeitig Skalierbarkeitsvorteile.
Authentifizierung und Zugriffskonfiguration
Der EXAONE API-Zugriff variiert je nach gewählter Bereitstellungsplattform. Es gibt mehrere Integrationspfade, darunter die Bereitstellung über Hugging Face Hub, Together AI-Dienste und benutzerdefinierte Serverkonfigurationen. Jede Methode erfordert unterschiedliche Authentifizierungsansätze.
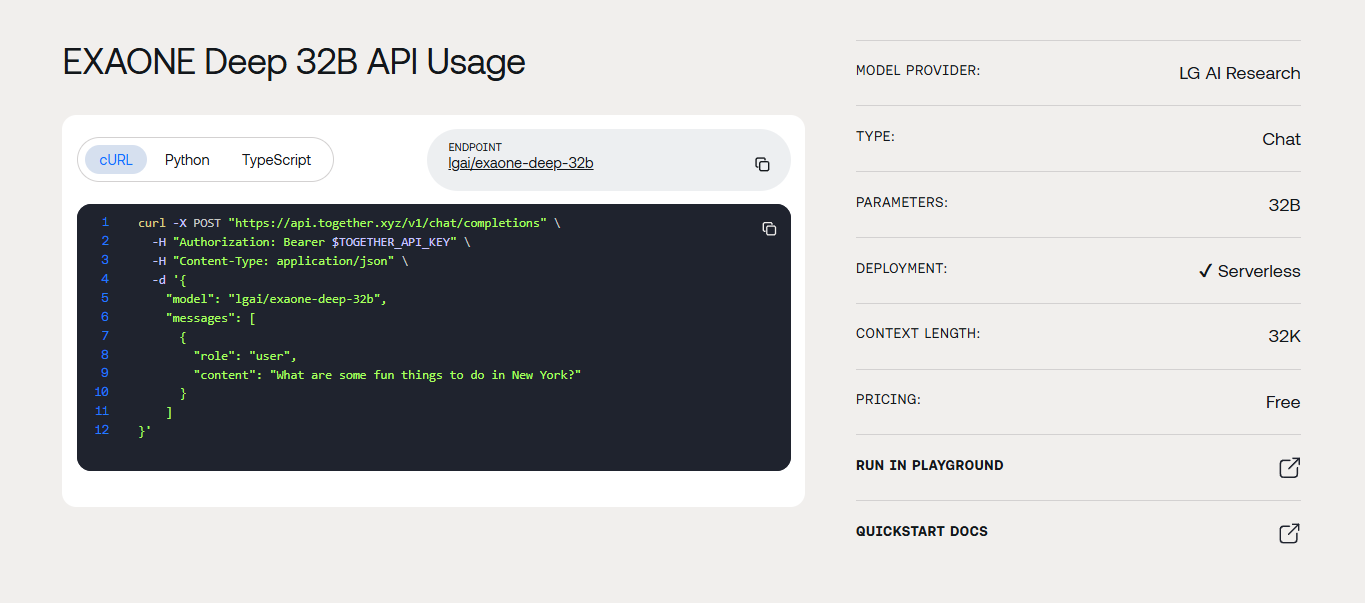
Bei der Verwendung von Together AI's EXAONE Deep 32B API-Endpunkt beinhaltet die Authentifizierung die Verwaltung von API-Schlüsseln. Erstellen Sie ein Konto bei Together AI, generieren Sie Ihren API-Schlüssel und konfigurieren Sie Umgebungsvariablen sicher. Geben Sie niemals API-Schlüssel in clientseitigem Code oder öffentlichen Repositories preis.
import Together from "together-ai";
const client = new Together({
apiKey: process.env.TOGETHER_API_KEY
});
async function callExaoneAPI(prompt) {
try {
const response = await client.chat.completions.create({
model: "exaone-deep-32b",
messages: [
{
role: "user",
content: prompt
}
],
max_tokens: 1000,
temperature: 0.7
});
return response.choices[0].message.content;
} catch (error) {
console.error("EXAONE API Error:", error);
throw error;
}
}
Lokale Bereitstellung mit Ollama-Integration
Ollama installieren und konfigurieren
Beginnen Sie mit dem Herunterladen von Ollama von der offiziellen Website. Die Installationsprozesse variieren je nach Betriebssystem, aber die Einrichtung bleibt unkompliziert. Nach der Installation überprüfen Sie die Installation, indem Sie grundlegende Befehle in Ihrem Terminal ausführen.
# Ollama installieren (MacOS)
brew install ollama
# Ollama-Dienst starten
ollama serve
# EXAONE-Modell herunterladen
ollama pull exaone
Nach erfolgreicher Installation konfigurieren Sie Ollama, um EXAONE-Modelle effektiv auszuführen. Die Konfiguration umfasst das Herunterladen von Modellgewichten, die Einrichtung einer angemessenen Speicherzuweisung und die Optimierung von Leistungsparametern für Ihre spezifische Hardware.
EXAONE-Modelle lokal ausführen
Sobald die Ollama-Installation abgeschlossen ist, wird das Herunterladen von EXAONE-Modellen unkompliziert. Der Prozess umfasst das Herunterladen von Modellgewichten aus dem offiziellen Repository und die Konfiguration von Laufzeitparametern. Verschiedene Modellgrößen bieten unterschiedliche Leistungsmerkmale, wählen Sie daher basierend auf Ihren spezifischen Anforderungen.
# Spezifische EXAONE-Modellversion herunterladen
ollama pull exaone-deep:7.8b
# Modell mit benutzerdefinierten Parametern ausführen
ollama run exaone-deep:7.8b --temperature 0.5 --max-tokens 2048
Die lokale Bereitstellung ermöglicht auch benutzerdefinierte Feinabstimmungsmöglichkeiten. Fortgeschrittene Benutzer können Modellparameter ändern, Inferenz-Einstellungen anpassen und die Leistung für spezifische Anwendungsfälle optimieren. Diese Flexibilität macht EXAONE besonders attraktiv für Forschungsanwendungen und spezialisierte Implementierungen.
API-Integrationsmethoden und Best Practices
RESTful API-Implementierung
Die EXAONE API folgt standardmäßigen RESTful-Konventionen, was die Integration für die meisten Entwickler vertraut macht. HTTP POST-Anfragen handhaben die Modellinferenz, während GET-Anfragen Modellinformationen und Statusprüfungen verwalten. Eine ordnungsgemäße Fehlerbehandlung gewährleistet robuste Anwendungen, die API-Einschränkungen und Netzwerkprobleme elegant verwalten.
import requests
import json
def exaone_api_call(prompt, model_size="32b"):
url = "https://api.together.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": f"exaone-deep-{model_size}",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1500,
"temperature": 0.7,
"top_p": 0.9
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
Erweiterte Konfigurationsoptionen
Die EXAONE API unterstützt verschiedene Konfigurationsparameter, die die Ausgabequalität und Leistung erheblich beeinflussen. Die Temperatur steuert die Zufälligkeit in generierten Antworten, während top_p das Nucleus-Sampling-Verhalten verwaltet. Max_tokens begrenzt die Antwortlänge und hilft, Kosten und Antwortzeiten zu kontrollieren.
Zusätzlich unterstützt die API System-Prompts, die ein konsistentes Verhalten über mehrere Anfragen hinweg ermöglichen. Diese Funktion erweist sich als besonders wertvoll für Anwendungen, die eine spezifische Ton-, Stil- oder Formatkonsistenz erfordern. System-Prompts helfen auch, den Kontext über Konversationsstränge hinweg aufrechtzuerhalten.
EXAONE API mit Apidog testen
Effektives API-Testen beschleunigt die Entwicklung und gewährleistet zuverlässige Integrationen. Apidog bietet umfassende Testfunktionen, die speziell für moderne API-Workflows entwickelt wurden. Die Plattform unterstützt automatisierte Tests, Anforderungsvalidierung und Leistungsüberwachung.
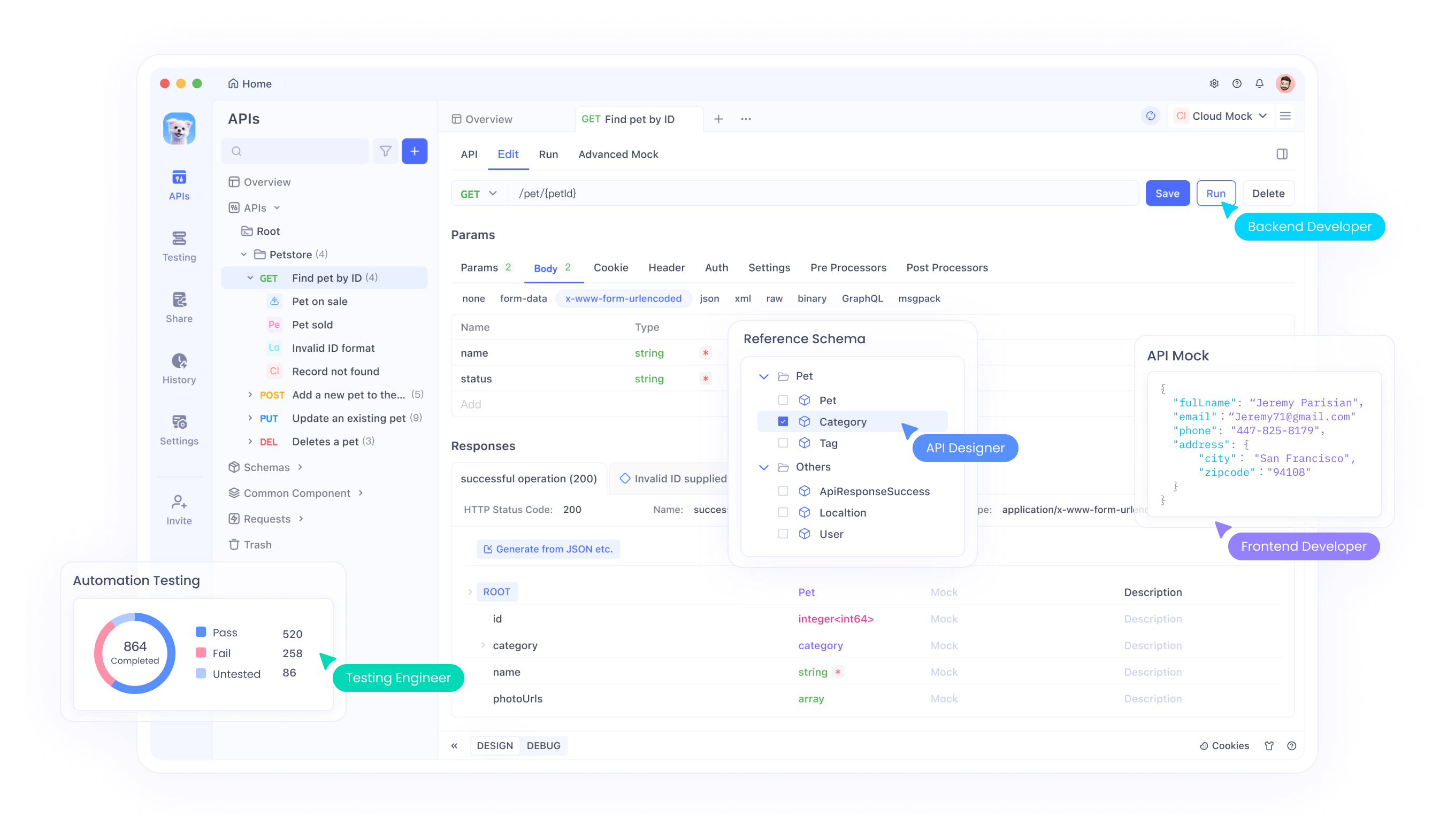
Apidog für EXAONE-Tests einrichten
Beginnen Sie mit der Erstellung eines Apidog-Kontos und der Installation der Desktop-Anwendung. Die Plattform bietet sowohl webbasierte als auch Desktop-Versionen, die jeweils leistungsstarke Testfunktionen bereitstellen. Desktop-Versionen bieten zusätzliche Funktionen wie lokale Dateiimporte und verbesserte Debugging-Tools.
Importieren Sie EXAONE API-Endpunkte in Apidog, indem Sie neue API-Spezifikationen erstellen. Definieren Sie Anforderungsparameter, Header und erwartete Antwortformate. Diese Dokumentation dient sowohl als Testkonfiguration als auch als Teamkollaborationstool, um eine konsistente API-Nutzung in Entwicklungsteams zu gewährleisten.
Umfassende Testsuiten erstellen
Entwickeln Sie Testsuiten, die verschiedene Szenarien abdecken, einschließlich erfolgreicher Anfragen, Fehlerbedingungen und Randfälle. Testen Sie verschiedene Parameterkombinationen, um das API-Verhalten gründlich zu verstehen. Die Testautomatisierungsfunktionen von Apidog ermöglichen eine kontinuierliche Validierung während der Entwicklungszyklen.
{
"test_cases": [
{
"name": "Basic Text Generation",
"request": {
"method": "POST",
"url": "{{base_url}}/chat/completions",
"headers": {
"Authorization": "Bearer {{api_key}}",
"Content-Type": "application/json"
},
"body": {
"model": "exaone-deep-32b",
"messages": [
{"role": "user", "content": "Explain quantum computing"}
],
"max_tokens": 500
}
},
"assertions": [
{"path": "$.choices[0].message.content", "operator": "exists"},
{"path": "$.usage.total_tokens", "operator": "lessThan", "value": 600}
]
}
]
}
Strategien zur Leistungsoptimierung
Anfrage-Batching und Caching
Optimieren Sie die API-Leistung durch intelligentes Anfrage-Batching und Antwort-Caching. Batching reduziert den Netzwerk-Overhead, während Caching redundante API-Aufrufe für identische Anfragen eliminiert. Diese Strategien verbessern die Anwendungsreaktionsfähigkeit erheblich und reduzieren gleichzeitig die Kosten.
Implementieren Sie Caching-Schichten mit Redis oder ähnlichen Technologien. Cachen Sie Antworten basierend auf Anforderungsparametern und stellen Sie sicher, dass die Cache-Invalidierung ordnungsgemäß erfolgt. Berücksichtigen Sie Cache-Ablaufrichtlinien basierend auf den Anforderungen Ihrer Anwendung und der Datensensibilität.
Fehlerbehandlung und Wiederholungslogik
Eine robuste Fehlerbehandlung verhindert Anwendungsfehler bei API-Problemen. Implementieren Sie exponentielle Backoff-Strategien für transiente Fehler, während permanente Fehler elegant behandelt werden. Das Management der Ratenbegrenzung stellt sicher, dass Anwendungen innerhalb der API-Kontingente bleiben, ohne Dienstunterbrechungen.
import time
import random
from typing import Optional
class ExaoneAPIClient:
def __init__(self, api_key: str, max_retries: int = 3):
self.api_key = api_key
self.max_retries = max_retries
def call_with_retry(self, prompt: str) -> Optional[str]:
for attempt in range(self.max_retries):
try:
response = self._make_api_call(prompt)
return response
except Exception as e:
if attempt == self.max_retries - 1:
raise e
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
return None
def _make_api_call(self, prompt: str) -> str:
# Implementierungsdetails für den eigentlichen API-Aufruf
pass
Beispiele für reale Implementierungen
Chatbot-Entwicklung mit EXAONE
Der Aufbau von konversationellen KI-Anwendungen mit der EXAONE API erfordert sorgfältiges Prompt Engineering und Kontextmanagement. Im Gegensatz zu einfacheren gpt-oss-Alternativen ermöglichen die fortschrittlichen Denkfähigkeiten von EXAONE komplexere Dialogsysteme.
Implementieren Sie ein Konversationsverlaufsmanagement, um den Kontext über mehrere Austausche hinweg aufrechtzuerhalten. Speichern Sie den Konversationszustand effizient, während Sie Token-Limits verwalten, um Kosten zu kontrollieren. Erwägen Sie die Implementierung einer Konversationszusammenfassung für langlaufende Chat-Sitzungen.
Anwendungen zur Inhaltserstellung
EXAONE zeichnet sich bei verschiedenen Aufgaben der Inhaltserstellung aus, darunter technische Dokumentation, kreatives Schreiben und Codegenerierung. Die zweisprachigen Funktionen der API machen sie besonders geeignet für internationale Workflows zur Inhaltserstellung.
class ContentGenerator:
def __init__(self, exaone_client):
self.client = exaone_client
def generate_blog_post(self, topic: str, target_language: str = "en") -> str:
prompt = f"""
Schreiben Sie einen umfassenden Blogbeitrag über {topic}.
Sprache: {target_language}
Anforderungen:
- Fügen Sie Einleitung, Hauptteil und Schluss ein
- Verwenden Sie einen ansprechenden Ton und eine klare Struktur
- Ziellänge: 800-1000 Wörter
"""
return self.client.generate(prompt, max_tokens=1200)
def generate_code_documentation(self, code_snippet: str) -> str:
prompt = f"""
Generieren Sie eine umfassende Dokumentation für diesen Code:
{code_snippet}
Fügen Sie ein:
- Zweck und Verhalten der Funktion
- Parameterbeschreibungen
- Erklärung des Rückgabewerts
- Anwendungsbeispiele
"""
return self.client.generate(prompt, max_tokens=800)
EXAONE im Vergleich zu alternativen Lösungen
Vorteile gegenüber traditionellen GPT-Modellen
EXAONE bietet mehrere Vorteile im Vergleich zu traditionellen GPT-Implementierungen und gpt-oss-Alternativen. Die hybride Aufmerksamkeitsarchitektur bietet ein besseres Verständnis langer Kontexte, während der Reasoning-Modus genauere Problemlösungsfähigkeiten ermöglicht.
Kosteneffizienz stellt einen weiteren wesentlichen Vorteil dar. Lokale Bereitstellungsoptionen eliminieren Gebühren pro Token, wodurch EXAONE für Anwendungen mit hohem Volumen wirtschaftlich wird. Darüber hinaus sind Datenschutzvorteile für Organisationen attraktiv, die sensible Daten verarbeiten.
Integrationsflexibilität
Im Gegensatz zu einigen proprietären Lösungen unterstützt EXAONE mehrere Bereitstellungsmuster. Wählen Sie zwischen Cloud-APIs, lokalen Installationen oder hybriden Ansätzen basierend auf spezifischen Anforderungen. Diese Flexibilität berücksichtigt verschiedene organisatorische Einschränkungen und technische Präferenzen.
Fehlerbehebung bei häufigen Problemen
Verbindungs- und Authentifizierungsprobleme
Netzwerkverbindungsprobleme und Authentifizierungsfehler stellen häufige Integrationsherausforderungen dar. Überprüfen Sie API-Endpunkte, Authentifizierungsdaten und stellen Sie eine ordnungsgemäße Header-Konfiguration sicher. Netzwerk-Debugging-Tools helfen, Verbindungsprobleme schnell zu identifizieren.
Überwachen Sie API-Ratenbegrenzungen sorgfältig, da das Überschreiten von Kontingenten zu temporären Sperren führt. Implementieren Sie eine ordnungsgemäße Ratenbegrenzung in Ihren Anwendungen, um Dienstunterbrechungen zu vermeiden. Erwägen Sie ein Upgrade der API-Pläne, wenn höhere Limits erforderlich werden.
Modellleistungsoptimierung
Wenn Modellantworten inkonsistent oder von geringer Qualität erscheinen, überprüfen Sie die Prompt-Engineering-Techniken. EXAONE reagiert gut auf klare, spezifische Anweisungen mit angemessenem Kontext. Experimentieren Sie mit verschiedenen Temperatur- und top_p-Werten, um die gewünschten Ausgabemerkmale zu erzielen.
Berücksichtigen Sie die Auswahl der Modellgröße basierend auf Ihren Anforderungen. Größere Modelle bieten eine bessere Leistung, erfordern jedoch mehr Ressourcen und Verarbeitungszeit. Balancieren Sie Leistungsanforderungen gegen Ressourcenbeschränkungen und Antwortzeitanforderungen.
Sicherheitsüberlegungen und Best Practices
API-Schlüsselverwaltung
Eine sichere Speicherung von API-Schlüsseln verhindert unbefugten Zugriff und potenzielle Sicherheitsverletzungen. Verwenden Sie Umgebungsvariablen, sichere Tresore oder Konfigurationsmanagementsysteme zur Schlüsselverwaltung. Committen Sie niemals API-Schlüssel in Versionskontrollsysteme oder legen Sie sie in clientseitigem Code offen.
Implementieren Sie Schlüsselrotationsrichtlinien, um Sicherheitsrisiken zu minimieren. Regelmäßige Schlüsselaktualisierungen reduzieren die Expositionsfenster, falls Kompromittierungen auftreten. Überwachen Sie API-Nutzungsmuster, um ungewöhnliche Aktivitäten zu erkennen, die auf Sicherheitsprobleme hinweisen könnten.
Datenschutz und Compliance
Bei der Verarbeitung sensibler Daten über die EXAONE API sollten Sie die Auswirkungen auf den Datenschutz sorgfältig berücksichtigen. Lokale Bereitstellungsoptionen bieten maximale Datenschutzkontrolle, während Cloud-Bereitstellungen eine sorgfältige Bewertung der Datenverarbeitungsrichtlinien erfordern.
Implementieren Sie Datenbereinigungsverfahren, um sensible Informationen vor API-Anfragen zu entfernen. Erwägen Sie die Implementierung zusätzlicher Verschlüsselungsschichten für hochsensible Anwendungen. Überprüfen Sie die Compliance-Anforderungen, die spezifisch für Ihre Branche und Ihren geografischen Standort sind.
Zukünftige Entwicklungen und Roadmap
Kommende Funktionen
LG AI Research entwickelt die EXAONE-Funktionen kontinuierlich weiter, mit regelmäßigen Modellaktualisierungen und Funktionsverbesserungen. Zukünftige Veröffentlichungen können zusätzliche Sprachunterstützung, verbesserte Denkfähigkeiten und erweiterte Tool-Integrationsfunktionen umfassen.
Bleiben Sie über API-Änderungen durch offizielle Dokumentation und Community-Kanäle informiert. Planen Sie Migrationspfade, wenn neue Modellversionen verfügbar werden. Testen Sie neue Versionen gründlich vor der Produktionsbereitstellung.
Community- und Ökosystemwachstum
Das EXAONE-Ökosystem wächst weiter mit Community-Beiträgen, Integrationen von Drittanbietern und spezialisierten Tools. Die aktive Teilnahme an Community-Diskussionen bietet Einblicke in Best Practices und aufkommende Anwendungsfälle.
Erwägen Sie, zu Open-Source-Projekten im Zusammenhang mit der EXAONE-Integration beizutragen. Das Teilen von Erfahrungen und Lösungen kommt der gesamten Entwicklergemeinschaft zugute und verbessert potenziell die Plattform für alle.
Fazit
Die EXAONE API bietet leistungsstarke Funktionen für Entwickler, die fortgeschrittene KI-Integrationsoptionen suchen. Von der Flexibilität der lokalen Bereitstellung bis hin zu ausgeklügelten Denkfähigkeiten bietet EXAONE überzeugende Alternativen zu Mainstream-Lösungen. Die umfassenden Bereitstellungsoptionen, robusten Leistungsmerkmale und das wachsende Ökosystem machen EXAONE zu einer ausgezeichneten Wahl für verschiedene Anwendungsszenarien.
Der Erfolg mit der EXAONE API hängt von einer ordnungsgemäßen Einrichtung, einer durchdachten Integrationsplanung und kontinuierlicher Optimierung ab. Verwenden Sie Tools wie Apidog für effiziente Test- und Debugging-Workflows. Befolgen Sie Best Practices für die Sicherheit und bleiben Sie über Plattform-Updates informiert, um die Effektivität Ihrer Implementierung zu maximieren.