
ElevenLabs verwandelt Text in natürliche Sprache und unterstützt eine breite Palette an Stimmen, Sprachen und Stilen. Die API macht es einfach, Sprachausgabe in Apps einzubetten, Erzählpipelines zu automatisieren oder Echtzeit-Erlebnisse wie Sprachagenten zu entwickeln. Wenn Sie eine HTTP-Anfrage senden können, können Sie in Sekundenschnelle Audio generieren.
Was ist die ElevenLabs API?
Die ElevenLabs API bietet programmatischen Zugriff auf KI-Modelle, die Audio generieren, transformieren und analysieren. Die Plattform begann als Text-to-Speech-Dienst, hat sich aber zu einer vollständigen Audio-KI-Suite erweitert.
Kernfunktionen:
- Text-to-Speech (TTS): Konvertiert geschriebenen Text in gesprochenes Audio mit Kontrolle über Stimmcharakteristiken, Emotionen und Tempo
- Speech-to-Speech (STS): Transformiert eine Stimme in eine andere, während die ursprüngliche Intonation und das Timing erhalten bleiben
- Stimmklonung (Voice Cloning): Erstellt eine digitale Replik jeder Stimme aus nur 60 Sekunden sauberem Audio
- KI-Synchronisation (AI Dubbing): Übersetzt und synchronisiert Audio-/Videoinhalte in verschiedene Sprachen unter Beibehaltung der Stimmcharakteristiken des Sprechers
- Soundeffekte: Generiert Soundeffekte aus Textbeschreibungen
- Speech-to-Text: Transkribiert Audio mit hoher Genauigkeit in Text
Die API arbeitet über Standard-HTTP- und WebSocket-Protokolle. Sie können sie von jeder Sprache aus aufrufen, aber es gibt offizielle SDKs für Python und JavaScript/TypeScript mit integrierter Typsicherheit und Streaming-Unterstützung.
ElevenLabs API-Schlüssel erhalten
Bevor Sie einen API-Aufruf tätigen, benötigen Sie einen API-Schlüssel. So erhalten Sie einen:
Schritt 1: Erstellen Sie ein kostenloses Konto. Selbst der kostenlose Plan beinhaltet API-Zugriff mit 10.000 Zeichen pro Monat.
Schritt 2: Melden Sie sich an und navigieren Sie zum Abschnitt Profil + API-Schlüssel. Diesen finden Sie, indem Sie auf Ihr Profilsymbol in der unteren linken Ecke klicken oder direkt zu den Entwicklereinstellungen gehen.
Schritt 3: Klicken Sie auf API-Schlüssel erstellen. Kopieren Sie den Schlüssel und speichern Sie ihn sicher – Sie können den vollständigen Schlüssel danach nicht mehr sehen.
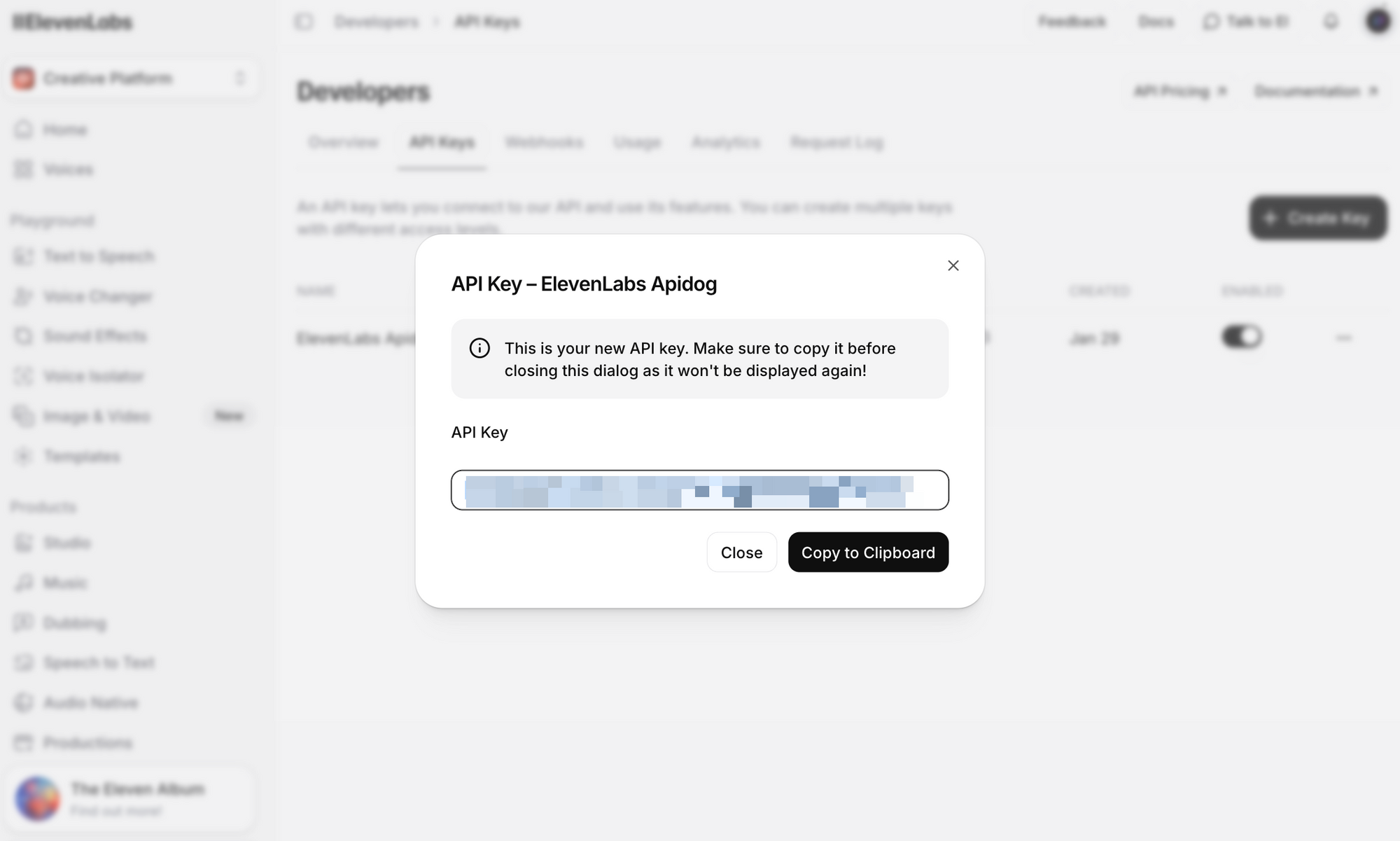
Wichtige Sicherheitshinweise:
- Speichern Sie Ihren API-Schlüssel niemals in der Versionskontrolle
- Verwenden Sie Umgebungsvariablen oder einen Secrets Manager in der Produktion
- API-Schlüssel können für bestimmte Arbeitsbereiche in Teamumgebungen festgelegt werden
- Rotieren Sie Schlüssel regelmäßig und widerrufen Sie kompromittierte Schlüssel sofort
Setzen Sie ihn als Umgebungsvariable für die Beispiele in diesem Leitfaden:
# Linux/macOS
export ELEVENLABS_API_KEY="ihr_api_schlüssel_hier"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="ihr_api_schlüssel_hier"
Übersicht der ElevenLabs API-Endpunkte
Die API ist um mehrere Ressourcengruppen herum organisiert. Hier sind die am häufigsten verwendeten Endpunkte:
| Endpunkt | Methode | Beschreibung |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Text in Sprache konvertieren |
/v1/text-to-speech/{voice_id}/stream | POST | Audio während der Generierung streamen |
/v1/speech-to-speech/{voice_id} | POST | Sprache von einer Stimme in eine andere konvertieren |
/v1/voices | GET | Alle verfügbaren Stimmen auflisten |
/v1/voices/{voice_id} | GET | Details zu einer bestimmten Stimme abrufen |
/v1/models | GET | Alle verfügbaren Modelle auflisten |
/v1/user | GET | Benutzerkontoinformationen und Nutzung abrufen |
/v1/voice-generation/generate-voice | POST | Eine neue zufällige Stimme generieren |
Basis-URL: https://api.elevenlabs.io
Authentifizierung: Alle Anfragen erfordern den Header xi-api-key:
xi-api-key: ihr_api_schlüssel_hier
Text-to-Speech mit cURL
Der schnellste Weg, die API zu testen, ist mit einem cURL-Befehl. Dieses Beispiel verwendet die Stimme Rachel (ID: 21m00Tcm4TlvDq8ikWAM), eine der Standardstimmen, die in allen Plänen verfügbar sind:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Willkommen bei unserer Anwendung. Dieses Audio wurde mit der ElevenLabs API generiert.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
Wenn erfolgreich, erhalten Sie eine Datei speech.mp3 mit dem generierten Audio. Spielen Sie sie mit einem beliebigen Mediaplayer ab.
Aufschlüsselung der Anfrage:
- voice_id (in der URL): Die ID der zu verwendenden Stimme. Jede Stimme in ElevenLabs hat eine eindeutige ID.
- text: Der Inhalt, der in Sprache umgewandelt werden soll. Das Flash v2.5-Modell unterstützt bis zu 40.000 Zeichen pro Anfrage.
- model_id: Welches KI-Modell verwendet werden soll.
eleven_flash_v2_5bietet die beste Balance zwischen Geschwindigkeit und Qualität. - voice_settings: Optionale Feinabstimmungsparameter (unten detailliert beschrieben).
Die Antwort gibt rohe Audiodaten zurück. Das Standardformat ist MP3, aber Sie können andere Formate anfordern, indem Sie den Abfrageparameter output_format hinzufügen:
# PCM-Audio anstelle von MP3 abrufen
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hallo Welt", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Verwendung des Python SDK
Das offizielle Python SDK vereinfacht die Integration mit Typ-Hinweisen, integrierter Audiowiedergabe und Streaming-Unterstützung.
Installation
pip install elevenlabs
Um Audio direkt über Ihre Lautsprecher abzuspielen, benötigen Sie möglicherweise auch mpv oder ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Einfaches Text-to-Speech
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="Die ElevenLabs API macht es einfach, jeder Anwendung realistische Sprachausgabe hinzuzufügen.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George Stimme
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Audio in Datei speichern
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
audio = client.text_to_speech.convert(
text="Dieses Audio wird in einer Datei gespeichert.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio in output.mp3 gespeichert")
Verfügbare Stimmen auflisten
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Kategorie: {voice.category}")
Dies druckt alle in Ihrem Konto verfügbaren Stimmen aus, einschließlich vorgefertigter Stimmen, geklonter Stimmen und von Ihnen hinzugefügter Community-Stimmen.
Asynchrone Unterstützung
Für Anwendungen, die asyncio verwenden, bietet das SDK AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="ihr_api_schlüssel")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="Dies wurde asynchron generiert.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Asynchrones Audio gespeichert.")
asyncio.run(generate_speech())
Verwendung des JavaScript SDK
Das offizielle Node.js SDK (@elevenlabs/elevenlabs-js) bietet vollständige TypeScript-Unterstützung und funktioniert in Node.js-Umgebungen.
Installation
npm install @elevenlabs/elevenlabs-js
Einfaches Text-to-Speech
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachel Stimmen-ID
{
text: "Hallo vom ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
In Datei speichern (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Dieses Audio wird mit Node.js Streams in eine Datei geschrieben.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio in output.mp3 gespeichert");
Fehlerbehandlung
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Fehlerbehandlung testen.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`API Fehler: ${error.message}, Status: ${error.statusCode}`);
} else {
console.error("Unerwarteter Fehler:", error);
}
}
Das SDK versucht fehlgeschlagene Anfragen standardmäßig bis zu 2 Mal erneut, mit einem Timeout von 60 Sekunden. Beide Werte sind konfigurierbar.
Audio in Echtzeit streamen
Für Chatbots, Sprachassistenten oder jede Anwendung, bei der es auf Latenz ankommt, ermöglicht Streaming das Abspielen von Audio, bevor die gesamte Antwort generiert wurde. Dies ist entscheidend für konversationelle KI, bei der Benutzer nahezu sofortige Antworten erwarten.
Python Streaming
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
audio_stream = client.text_to_speech.stream(
text="Streaming ermöglicht es Ihnen, Audio fast sofort zu hören, ohne auf die vollständige Generierung warten zu müssen.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Gestreamtes Audio in Echtzeit über Lautsprecher abspielen
stream(audio_stream)
JavaScript Streaming
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "Dieses Audio wird in Echtzeit mit minimaler Latenz gestreamt.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
WebSocket Streaming
Für die geringste Latenz verwenden Sie WebSocket-Verbindungen. Dies ist ideal für Echtzeit-Sprachagenten, bei denen Text in Chunks (z. B. von einem LLM) ankommt:
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Initialkonfiguration senden
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "ihr_api_schlüssel",
}))
# Text-Chunks senden, sobald sie ankommen (z. B. von einem LLM)
text_chunks = [
"Hallo! ",
"Dies ist Streaming ",
"via WebSockets. ",
"Jeder Chunk wird separat gesendet."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Ende der Eingabe signalisieren
await ws.send(json.dumps({"text": ""}))
# Audio-Chunks empfangen
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("WebSocket-Audio gespeichert.")
asyncio.run(stream_tts_websocket())
Stimmenauswahl und -verwaltung
ElevenLabs bietet Hunderte von Stimmen. Die Wahl der richtigen Stimme ist entscheidend für die Benutzererfahrung Ihrer Anwendung.
Standardstimmen
Diese Stimmen sind in allen Plänen verfügbar, einschließlich des kostenlosen Tarifs:
| Stimmenname | Stimmen-ID | Beschreibung |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Ruhige, junge Frau |
| Drew | 29vD33N1CtxCmqQRPOHJ | Gut abgestimmte männliche Stimme |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Charakter eines Kriegsveteranen |
| Paul | 5Q0t7uMcjvnagumLfvZi | Reporter vor Ort |
| Domi | AZnzlk1XvdvUeBnXmlld | Starke, durchsetzungsfähige Frau |
| Dave | CYw3kZ02Hs0563khs1Fj | Konversationeller britischer Mann |
| Fin | D38z5RcWu1voky8WS1ja | Irischer Mann |
| Sarah | EXAVITQu4vr4xnSDxMaL | Sanfte, junge Frau |
Stimmen-IDs finden
Verwenden Sie die API, um alle verfügbaren Stimmen zu durchsuchen:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
Oder filtern Sie nach Kategorie (vorgefertigt, geklont, generiert):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
# Nur vorgefertigte Stimmen auflisten
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
Sie können eine Stimmen-ID auch direkt von der ElevenLabs-Website kopieren: Wählen Sie eine Stimme aus, klicken Sie auf das Drei-Punkte-Menü und wählen Sie Stimmen-ID kopieren.
Das richtige Modell wählen
ElevenLabs bietet mehrere Modelle, die jeweils für verschiedene Anwendungsfälle optimiert sind:

# Alle verfügbaren Modelle mit Details auflisten
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
models = client.models.list()
for model in models:
print(f"Modell: {model.name}")
print(f" ID: {model.model_id}")
print(f" Sprachen: {len(model.languages)}")
print(f" Max Zeichen: {model.max_characters_request_free_user}")
print()
ElevenLabs API mit Apidog testen
Bevor Sie Integrationscode schreiben, hilft es, API-Endpunkte interaktiv zu testen. Apidog macht dies einfach – Sie können Anfragen visuell konfigurieren, Antworten (einschließlich Audio) überprüfen und Client-Code generieren, sobald Sie zufrieden sind.
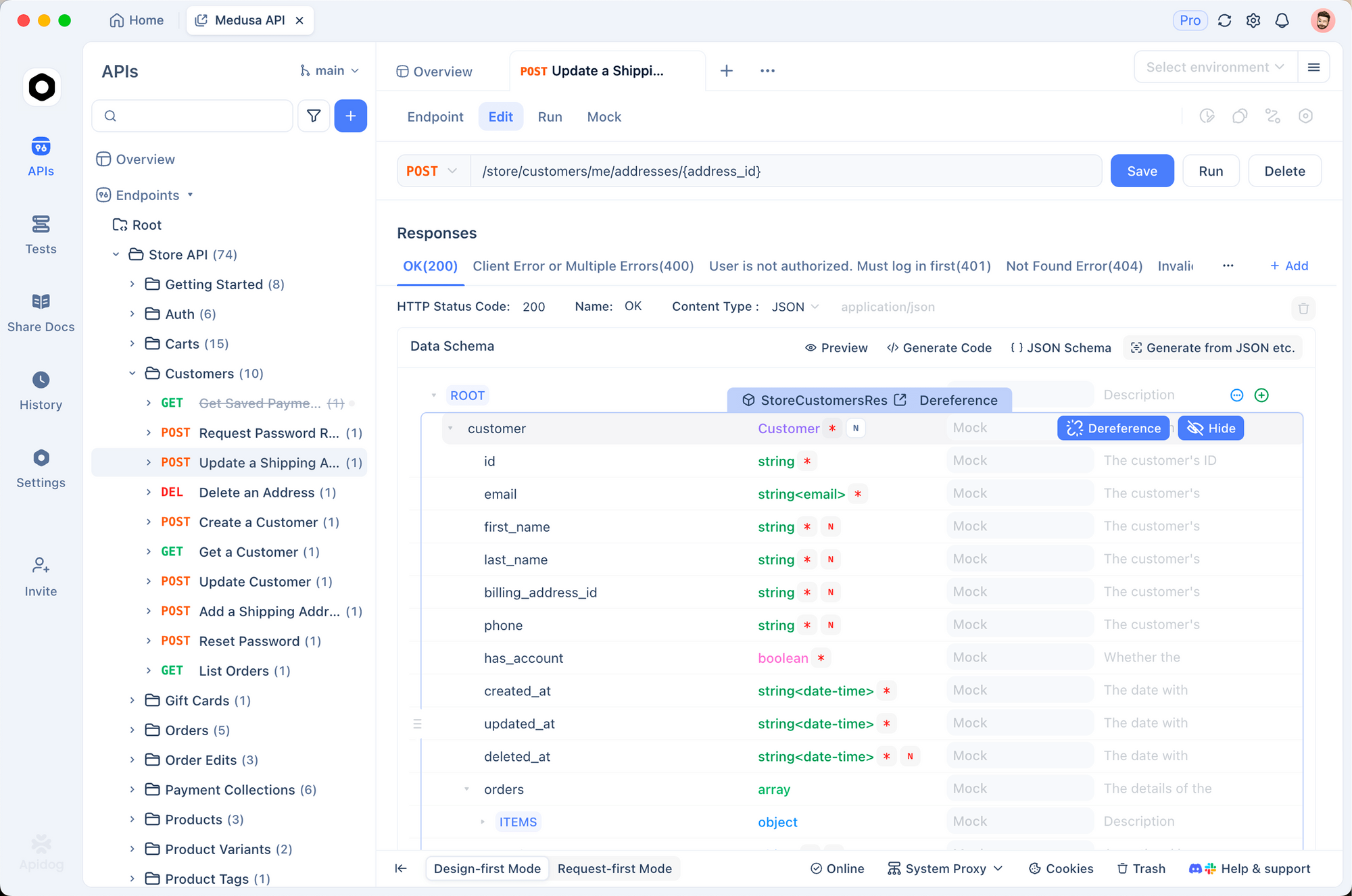
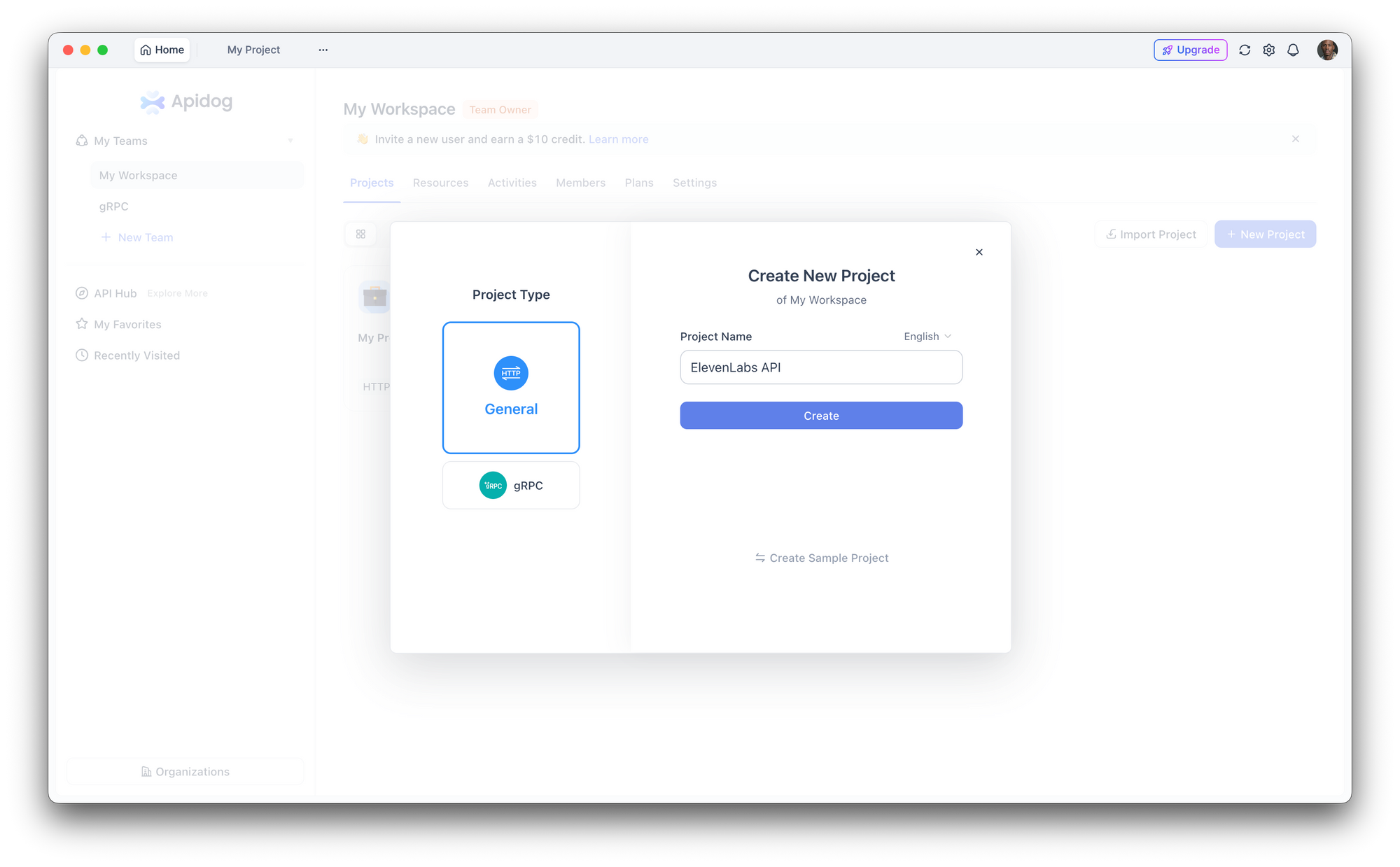
Schritt 1: Ein neues Projekt einrichten
Öffnen Sie Apidog und erstellen Sie ein neues Projekt. Nennen Sie es "ElevenLabs API" oder fügen Sie die Endpunkte einem bestehenden Projekt hinzu.
Schritt 2: Authentifizierung konfigurieren
Gehen Sie zu Projekt-Einstellungen > Auth und richten Sie einen globalen Header ein:
- Header-Name:
xi-api-key - Header-Wert: Ihr ElevenLabs API-Schlüssel
Dies fügt die Authentifizierung automatisch jeder Anfrage im Projekt hinzu.
Schritt 3: Eine Text-to-Speech-Anfrage erstellen
Erstellen Sie eine neue POST-Anfrage:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Body (JSON):
{
"text": "Die ElevenLabs API über Apidog testen. Das macht es einfach, mit verschiedenen Stimmen und Einstellungen zu experimentieren.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
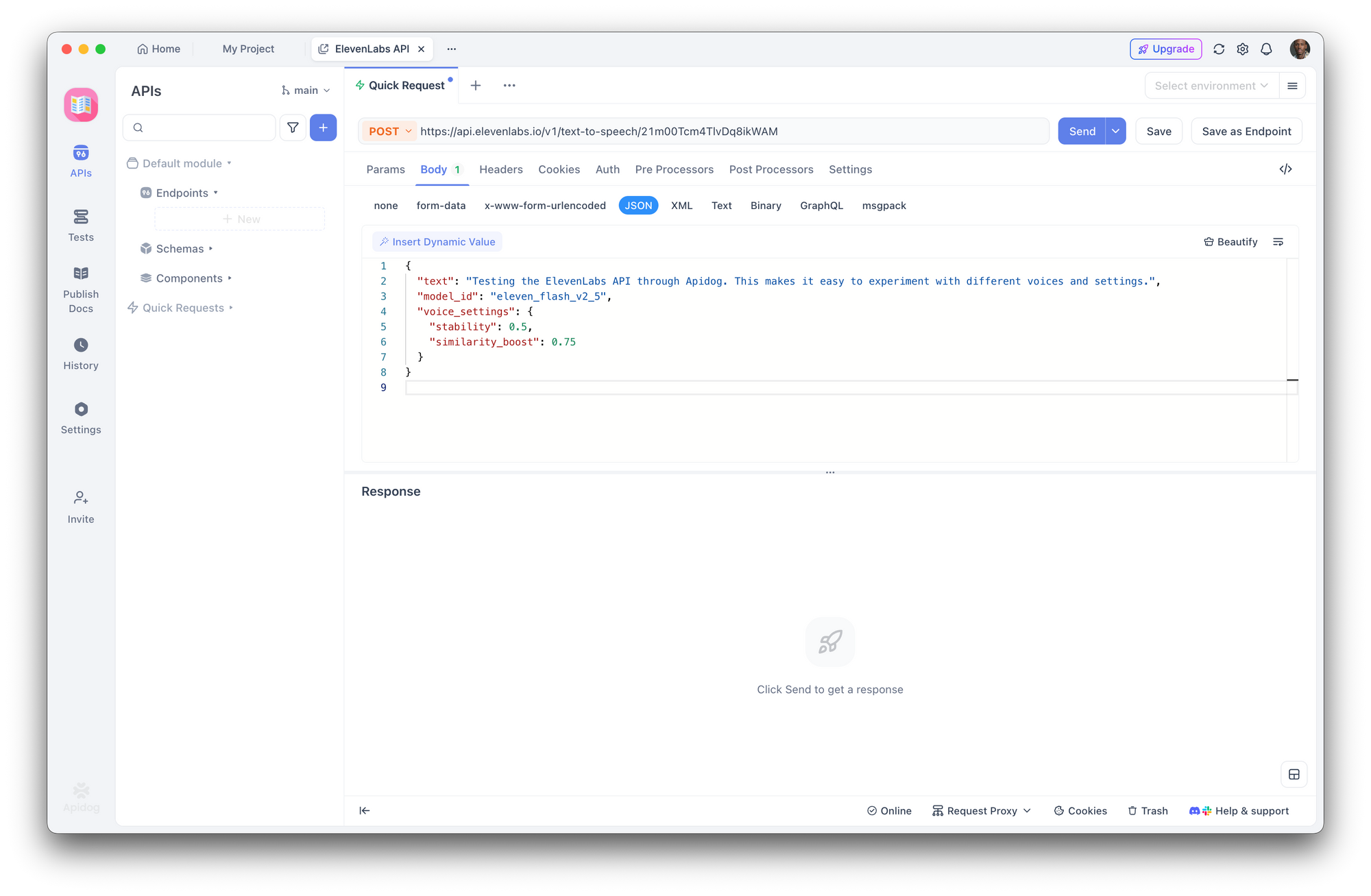
Klicken Sie auf Senden. Apidog zeigt die Antwort-Header an und lässt Sie das Audio direkt herunterladen oder abspielen.
Schritt 4: Mit Parametern experimentieren
Verwenden Sie die Oberfläche von Apidog, um Stimmen-IDs schnell auszutauschen, Modelle zu ändern oder Spracheinstellungen anzupassen, ohne Roh-JSON bearbeiten zu müssen. Speichern Sie verschiedene Konfigurationen als separate Endpunkte in Ihrer Sammlung für einen einfachen Vergleich.
Schritt 5: Client-Code generieren
Sobald Sie bestätigt haben, dass die Anfrage funktioniert, klicken Sie in Apidog auf Code generieren, um gebrauchsfertigen Client-Code in Python, JavaScript, cURL, Go, Java und mehr zu erhalten. Dies eliminiert die manuelle Übersetzung von API-Dokumenten in funktionierenden Code.
Jetzt ausprobieren:Laden Sie Apidog kostenlos herunter
Stimmeinstellungen und Feinabstimmung
Stimmeinstellungen ermöglichen es Ihnen, den Klang einer Stimme anzupassen. Diese Parameter werden im Objekt voice_settings gesendet:
| Parameter | Bereich | Standard | Effekt |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Höher = konsistenter, weniger ausdrucksstark. Niedriger = variabler, emotionaler. |
similarity_boost | 0.0 - 1.0 | 0.75 | Höher = näher an der Originalstimme. Niedriger = mehr Variation. |
style | 0.0 - 1.0 | 0.0 | Höher = übertriebenerer Stil. Erhöht die Latenz. Nur für Multilingual v2. |
use_speaker_boost | boolean | true | Erhöht die Ähnlichkeit zum ursprünglichen Sprecher. Geringfügige Latenzerhöhung. |
Praktische Beispiele:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="ihr_api_schlüssel")
# Erzählerstimme: konsistent, stabil
narration = client.text_to_speech.convert(
text="Kapitel Eins. Es war ein heller, kalter Apriltag.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Konversationelle Stimme: ausdrucksstark, natürlich
conversational = client.text_to_speech.convert(
text="Oh wow, das ist wirklich eine tolle Idee! Lass mich mal überlegen, wie wir das umsetzen könnten.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Richtlinien:
- Für Hörbücher und Erzählungen verwenden Sie eine höhere Stabilität (0,7-0,9) für eine konsistente Wiedergabe
- Für Chatbots und konversationelle KI verwenden Sie eine niedrigere Stabilität (0,3-0,5) für natürliche Variationen
- Für Charakterstimmen experimentieren Sie mit einem niedrigeren similarity_boost (0,4-0,6), um unterschiedliche Persönlichkeiten zu schaffen
- Der Parameter
stylefunktioniert nur mit Multilingual v2 und erhöht die Latenz – verzichten Sie darauf für Echtzeitanwendungen
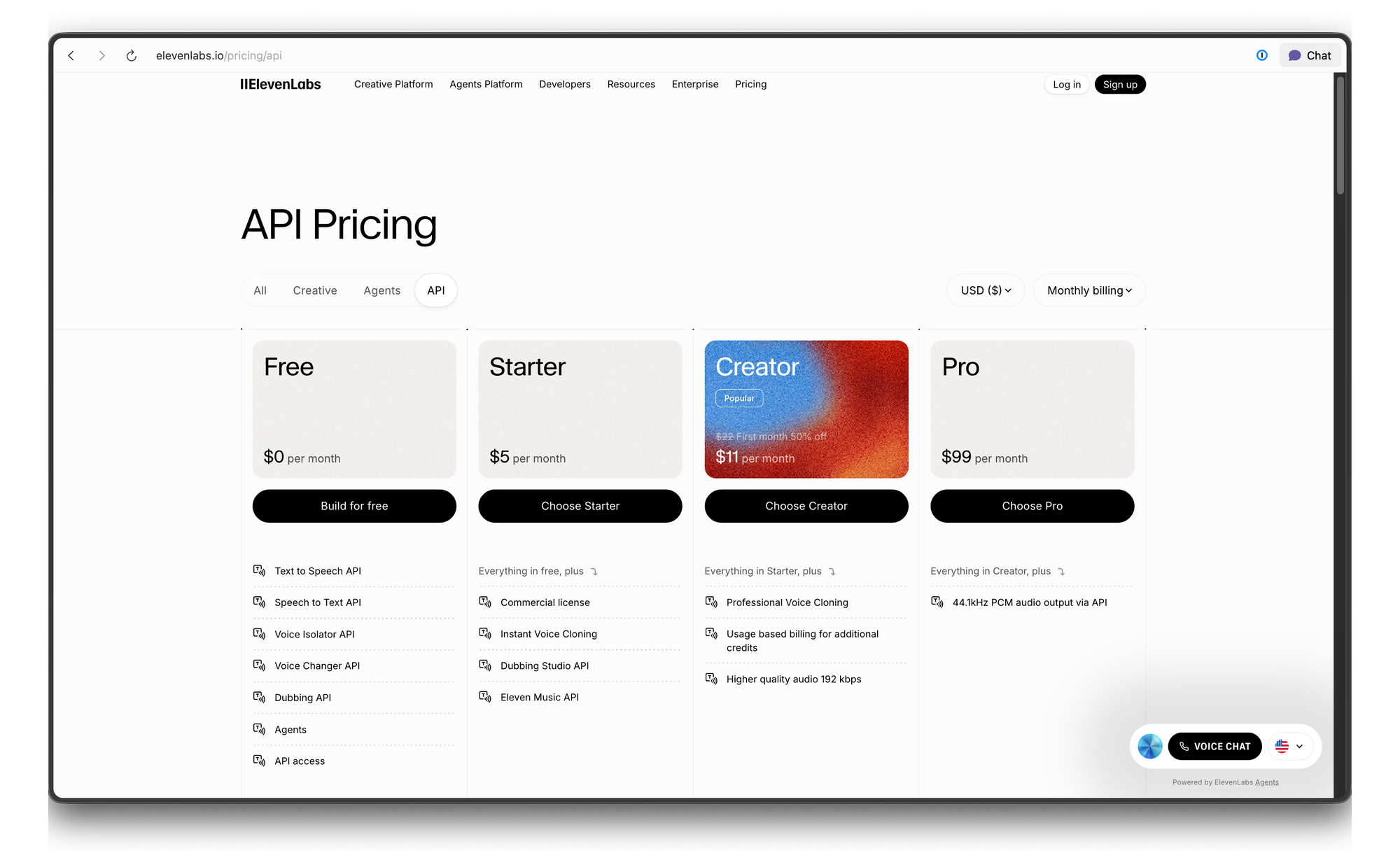
ElevenLabs API Preise und Ratenbegrenzungen
ElevenLabs verwendet ein kreditbasiertes Preissystem. Hier ist die Aufschlüsselung:
Fehlerbehebung
| Fehler | Ursache | Lösung |
|---|---|---|
| 401 Unautorisiert | Ungültiger oder fehlender API-Schlüssel | Überprüfen Sie den Wert Ihres xi-api-key Headers |
| 422 Unprocessable Entity | Ungültiger Anfrage-Body | Stellen Sie sicher, dass voice_id existiert und der Text nicht leer ist |
| 429 Too Many Requests | Ratenbegrenzung überschritten | Fügen Sie exponentielles Backoff hinzu oder upgraden Sie Ihren Plan |
| Audio klingt roboterhaft | Falsches Modell oder falsche Einstellungen | Versuchen Sie Multilingual v2 mit einer Stabilität von 0.5 |
| Aussprachefehler | Problem bei der Textnormalisierung | Zahlen/Abkürzungen ausschreiben oder SSML-ähnliche Formatierung verwenden |
Fazit
Die ElevenLabs API bietet Entwicklern Zugriff auf einige der realistischsten Sprachsynthesen, die heute verfügbar sind. Ob Sie ein paar Zeilen Erzählung oder eine vollständige Echtzeit-Sprachpipeline benötigen, die API skaliert von einfachen cURL-Aufrufen bis zu Produktions-WebSocket-Streams.
Bereit, Ihrer Anwendung eine realistische Sprachausgabe hinzuzufügen? Laden Sie Apidog herunter, um ElevenLabs API-Endpunkte zu testen, mit Spracheinstellungen zu experimentieren und Client-Code zu generieren – alles kostenlos, keine Kreditkarte erforderlich.