
Entwickler suchen nach Tools, die die Produktivität steigern, ohne unnötige Komplexität einzuführen. DeepSeek-V3.2 und DeepSeek-V3.2-Speciale erweisen sich als leistungsstarke Open-Source-Modelle, die für Denk- und Agentenaufgaben optimiert sind und eine überzeugende Alternative zu proprietären Systemen bieten. Diese Modelle zeichnen sich durch Codegenerierung, Problemlösung und die Verarbeitung langer Kontexte aus, wodurch sie ideal für die Integration in terminalbasierte Programmierumgebungen wie Claude Code sind.
DeepSeek-V3.2 verstehen: Ein Open-Source-Kraftpaket für Denkaufgaben
Entwickler schätzen Open-Source-Modelle für ihre Transparenz und Flexibilität. DeepSeek-V3.2 hebt sich als ein "Reasoning-First" großes Sprachmodell (LLM) hervor, das logische Schlussfolgerungen, Codesynthese und Agentenfähigkeiten priorisiert. Unter einer MIT-Lizenz veröffentlicht, baut dieses Modell auf früheren Iterationen wie DeepSeek-V3.1 auf und integriert Fortschritte in spärlichen Aufmerksamkeitsmechanismen, um erweiterte Kontexte von bis zu 128.000 Token zu verarbeiten.
Sie greifen auf DeepSeek-V3.2 hauptsächlich über Hugging Face zu, wo das Repository unter deepseek-ai/DeepSeek-V3.2 die Modellgewichte, Konfigurationsdateien und Tokenizer-Details beherbergt. Um das Modell lokal zu laden, installieren Sie die Transformers-Bibliothek über pip und führen Sie ein einfaches Skript aus:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Example inference
inputs = tokenizer("Write a Python function to compute Fibonacci sequence:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
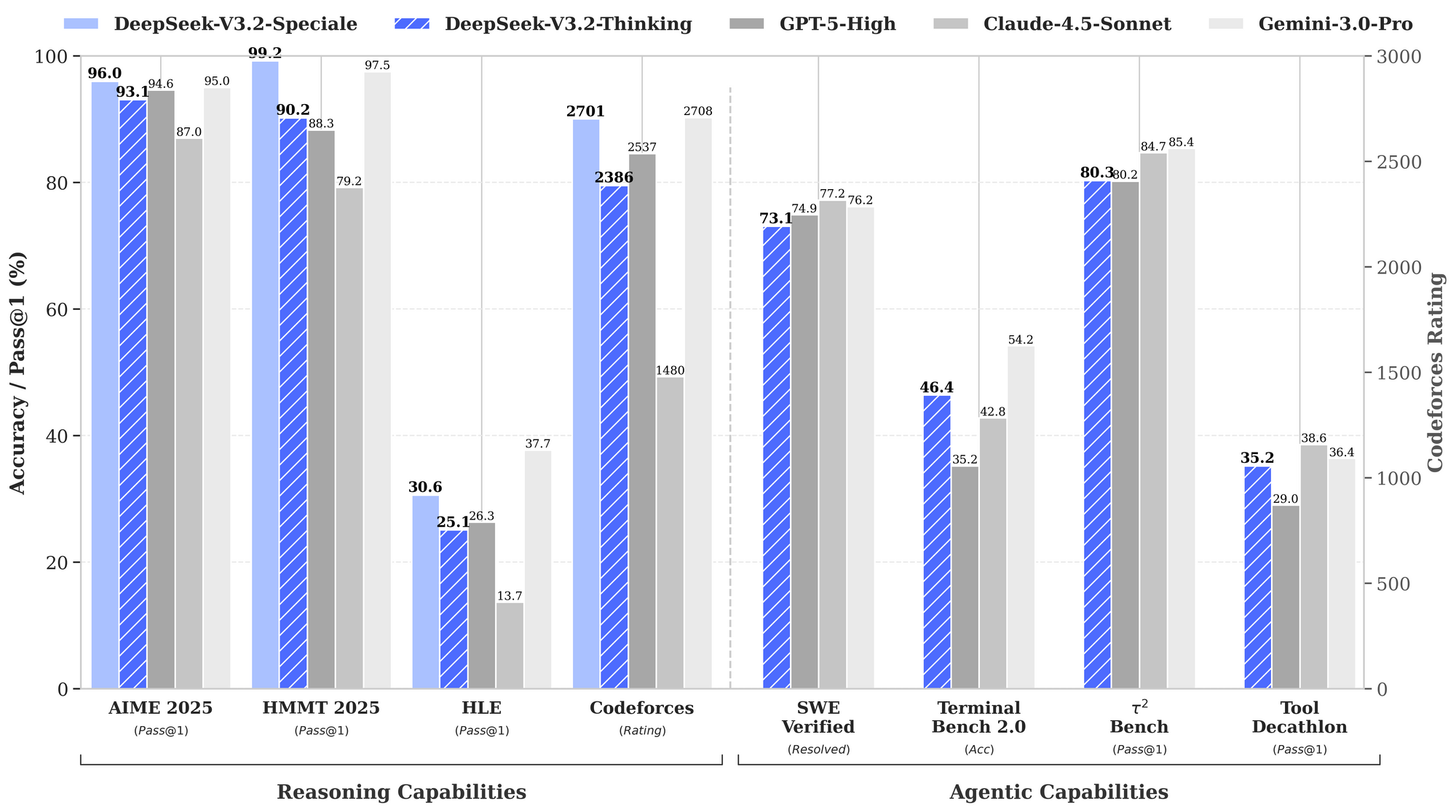
Dieses Setup erfordert eine GPU mit mindestens 16 GB VRAM für eine effiziente Inferenz, obwohl Quantisierungstechniken über Bibliotheken wie bitsandbytes den Speicherbedarf reduzieren. Die Architektur von DeepSeek-V3.2 verwendet ein Mixture-of-Experts (MoE)-Design mit 236 Milliarden Parametern, wobei pro Token nur eine Teilmenge aktiviert wird, um die Rechenleistung zu optimieren. Folglich erzielt es einen hohen Durchsatz auf Consumer-Hardware bei gleichzeitiger Beibehaltung einer wettbewerbsfähigen Leistung.
Der Übergang von lokalen Experimenten zur Nutzung im Produktionsmaßstab erfordert oft API-Zugriff. Dieser Wechsel bietet Skalierbarkeit ohne Hardware-Verwaltung und ebnet den Weg für Integrationen wie Claude Code.
DeepSeek-V3.2-Speciale: Erweiterte Funktionen für fortgeschrittene Agenten-Workflows
Während DeepSeek-V3.2 breite Anwendungsmöglichkeiten bietet, verfeinert DeepSeek-V3.2-Speciale diese Grundlagen für spezialisierte Anforderungen. Diese Variante, optimiert für Schlussfolgerungen auf Wettbewerbsniveau und risikoreiche Simulationen, verschiebt die Grenzen in Mathematik, Programmierwettbewerben und mehrstufigen Agentenaufgaben. Erhältlich über das Hugging Face Repository unter deepseek-ai/DeepSeek-V3.2-Speciale, teilt es die Kern-MoE-Architektur, integriert aber zusätzliche Nachschulungsanpassungen für Präzision.
Laden Sie DeepSeek-V3.2-Speciale ähnlich:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
Die Anzahl seiner Parameter spiegelt das Basismodell wider, doch Optimierungen in der spärlichen Aufmerksamkeit – DeepSeek Sparse Attention (DSA) – führen zu einer bis zu 50 % schnelleren Inferenz bei langen Sequenzen. DSA verwendet eine feinkörnige Sparsity, die die Qualität erhält und gleichzeitig die quadratische Komplexität in den Aufmerksamkeits-Layern reduziert.
In der Praxis glänzt DeepSeek-V3.2-Speciale in Szenarien, die verkettetes Denken erfordern, wie z.B. die Optimierung von Algorithmen für Wettbewerbsprogrammierung. Fordern Sie es zum Beispiel auf: "Lösen Sie dieses schwierige LeetCode-Problem: [Beschreibung]. Erklären Sie Ihren Ansatz Schritt für Schritt." Das Modell liefert strukturierte Lösungen mit Zeitkomplexitätsanalyse und übertrifft Generalistenmodelle oft um 15-20% bei Grenzfällen.
Lokale Ausführungen erfordern jedoch mehr Ressourcen – empfohlen werden 24 GB+ VRAM für volle Präzision. Für leichtere Setups wenden Sie die 4-Bit-Quantisierung an:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Diese Konfiguration behält 90% der ursprünglichen Wiedergabetreue bei und halbiert gleichzeitig den Speicherverbrauch. Wie beim Basismodell aktivieren Sie Denkmodi, um seine metakognitiven Spuren zu nutzen, bei denen es Annahmen während des Denkprozesses selbst korrigiert.
Open-Source-Zugang ermöglicht Anpassungen, aber für kollaborative oder skalierte Umgebungen bieten API-Endpunkte Zuverlässigkeit. Als Nächstes untersuchen wir, wie diese Modelle mit Cloud-basierten Interaktionen verbunden werden können.
Zugriff auf die DeepSeek API: Nahtlose Integration für skalierbare Entwicklung
Open-Source-Modelle wie DeepSeek-V3.2 und DeepSeek-V3.2-Speciale gedeihen in lokalen Setups, doch der API-Zugriff eröffnet breitere Anwendungsmöglichkeiten. Die DeepSeek-Plattform bietet eine kompatible Schnittstelle, die OpenAI- und Anthropic-SDKs für eine mühelose Migration unterstützt.
Registrieren Sie sich unter platform.deepseek.com, um einen API-Schlüssel zu erhalten.
Das Dashboard bietet Nutzungsanalysen und Abrechnungskontrollen. Rufen Sie Modelle über Standard-Endpunkte auf; für DeepSeek-V3.2 verwenden Sie den Alias deepseek-chat. DeepSeek-V3.2-Speciale erfordert eine spezifische Basis-URL: https://api.deepseek.com/v3.2_speciale_expires_on_20251215 – beachten Sie, dass diese temporäre Weiterleitung am 15. Dezember 2025 abläuft.
Eine einfache Curl-Anfrage demonstriert den Zugriff:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Generate a REST API endpoint in Node.js for user authentication."}],
"max_tokens": 500,
"temperature": 0.7
}'
Dies gibt JSON mit generiertem Code zurück, einschließlich Fehlerbehandlung und JWT-Integration. Für die Anthropic-Kompatibilität – entscheidend für Claude Code – setzen Sie die Basis-URL auf https://api.deepseek.com/anthropic und verwenden Sie das Python-SDK anthropic:
import anthropic
client = anthropic.Anthropic(base_url="https://api.deepseek.com/anthropic", api_key="your_deepseek_key")
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
messages=[{"role": "user", "content": "Explain quantum entanglement in code terms."}]
)
print(message.content[0].text)
Eine solche Kompatibilität gewährleistet Drop-in-Ersetzungen. Die Ratenbegrenzungen liegen bei 10.000 Token pro Minute für Standard-Tarife, skalierbar über Enterprise-Pläne.
Verwenden Sie Apidog, um diese Aufrufe zu prototypisieren. Importieren Sie die OpenAPI-Spezifikation aus der DeepSeek-Dokumentation in Apidog und simulieren Sie dann Anfragen mit variablen Payloads. Dieses Tool generiert automatisch Test-Suites, die Antworten anhand von Schemata validieren – unerlässlich, um sicherzustellen, dass die Modellausgaben Ihren Codebase-Standards entsprechen.
Nachdem der API-Zugriff gesichert ist, integrieren Sie diese Endpunkte in Entwicklungstools. Insbesondere Claude Code profitiert von diesem Setup, wie weiter unten erläutert wird.
Preisübersicht: Kostengünstige Strategien für die DeepSeek API-Nutzung
Budgetbewusste Entwickler schätzen vorhersehbare Kosten. DeepSeeks Preismodell belohnt effizientes Prompting und Caching, was sich direkt auf Claude Code-Sitzungen auswirkt.
Die Struktur aufschlüsseln: Cache-Treffer gelten für wiederholte Präfixe, ideal für iteratives Codieren, bei dem Sie Prompts über mehrere Sitzungen hinweg verfeinern. Fehlversuche berechnen volle Eingaberaten, also strukturieren Sie Konversationen, um die Wiederverwendung zu maximieren. Ausgaben skalieren linear mit der Generierungslänge – begrenzen Sie max_tokens, um die Kosten zu kontrollieren.
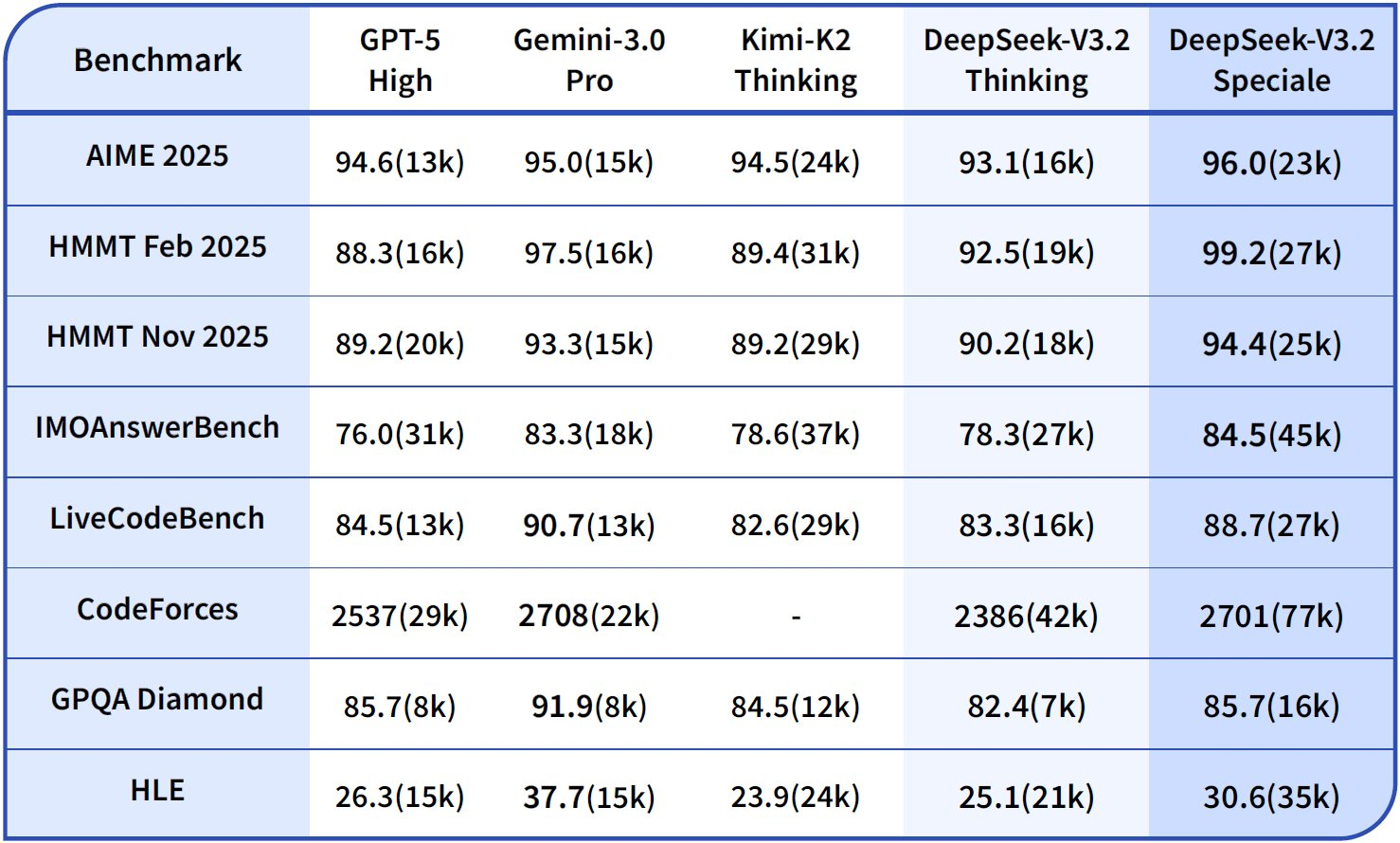
| Modellvariante | Input Cache-Treffer ($/1M Tokens) | Input Cache-Fehlversuch ($/1M Tokens) | Output ($/1M Tokens) | Kontextlänge |
|---|---|---|---|---|
| DeepSeek-V3.2 | 0.028 | 0.28 | 0.42 | 128K |
| DeepSeek-V3.2-Speciale | 0.028 | 0.28 | 0.42 | 128K |
Unternehmensnutzer verhandeln Mengenrabatte, aber kostenlose Stufen bieten monatlich 1 Million Token zum Testen. Überwachen Sie über das Dashboard; integrieren Sie die Protokollierung in Claude Code, um die Token-Nutzung zu verfolgen:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=$DEEPSEEK_API_KEY
claude --log-tokens
Dieser Befehl gibt Metriken nach der Sitzung aus und hilft bei der Optimierung von Prompts. Für Codierung mit langem Kontext hält DSA in V3.2-Varianten die Kosten auch bei über 100.000 Token stabil, im Gegensatz zu dichten Modellen, die quadratisch eskalieren.
DeepSeek-V3.2 und V3.2-Speciale in Claude Code integrieren: Schritt-für-Schritt-Anleitung
Claude Code revolutioniert die terminalbasierte Entwicklung als Agenten-Tool von Anthropic. Es interpretiert natürliche Sprachbefehle, führt Git-Operationen aus, erklärt Codebasen und automatisiert Routinen – alles innerhalb Ihrer Shell. Durch das Weiterleiten von Anfragen an DeepSeek-Modelle nutzen Sie kostengünstiges Denken, ohne die intuitive Benutzeroberfläche von Claude Code zu opfern.

Beginnen Sie mit den Voraussetzungen: Installieren Sie Claude Code über pip (pip install claude-code) oder von GitHub anthropics/claude-code. Stellen Sie sicher, dass Node.js und Git in Ihrem PATH vorhanden sind.
Umgebungsvariablen für DeepSeek-Kompatibilität konfigurieren:
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-your_deepseek_key_here"
export ANTHROPIC_MODEL="deepseek-chat" # For V3.2
export ANTHROPIC_SMALL_FAST_MODEL="deepseek-chat"
export API_TIMEOUT_MS=600000 # 10 minutes for long reasoning
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 # Optimize for API
Für DeepSeek-V3.2-Speciale fügen Sie die benutzerdefinierte Basis hinzu: export ANTHROPIC_BASE_URL="https://api.deepseek.com/v3.2_speciale_expires_on_20251215/anthropic". Überprüfen Sie das Setup, indem Sie claude --version ausführen; es erkennt den Endpunkt automatisch.
Starten Sie Claude Code in Ihrem Projektverzeichnis:
cd /path/to/your/repo
claude
Interagieren Sie über Befehle. Für die Codegenerierung: "/generate Implementieren Sie einen binären Suchbaum in C++ mit AVL-Balancierung." DeepSeek-V3.2 verarbeitet dies und gibt Dateien mit Erklärungen aus. Sein Denkmodus aktiviert sich implizit für komplexe Aufgaben und verfolgt die Logik vor dem Code.
Handhaben Sie Agenten-Workflows: "/agent Debuggen Sie diese fehlerhafte Test-Suite und schlagen Sie Korrekturen vor." Das Modell analysiert Stack-Traces, schlägt Patches vor und führt Commits über Git aus – alles angetrieben durch DeepSeeks 84,8% SWE-Bench-Ergebnis. Die parallele Tool-Nutzung glänzt hier; geben Sie "/use-tool pytest" an, um Tests inline auszuführen.
Passen Sie es mit Plugins an. Erweitern Sie die YAML-Konfiguration von Claude Code (~/.claude-code/config.yaml), um DeepSeek für logikintensive Prompts zu priorisieren:
models:
default: deepseek-chat
fallback: deepseek-chat # For V3.2-Speciale, override per session
reasoning_enabled: true
max_context: 100000 # Leverage 128K window
Testen Sie Integrationen mit Apidog. Exportieren Sie Claude Code-Sitzungen als HAR-Dateien, importieren Sie sie in Apidog und spielen Sie sie gegen DeepSeek-Endpunkte ab. Dies validiert Latenz (typischerweise <2s für 1K Token) und Fehlerraten und verfeinert Prompts für die Produktion.
Beheben Sie häufige Probleme: Wenn die Authentifizierung fehlschlägt, generieren Sie Ihren API-Schlüssel neu. Bei Token-Limits teilen Sie große Codebasen mit "/summarize repo structure first." Diese Anpassungen gewährleisten einen reibungslosen Betrieb.
Fortgeschrittene Techniken: DeepSeek in Claude Code für optimale Leistung nutzen
Über die Grundlagen hinaus nutzen fortgeschrittene Benutzer die Stärken von DeepSeek. Aktivieren Sie Chain-of-Thought (CoT) explizit: "/think Lösen Sie dieses dynamische Programmierproblem: [Details]." V3.2-Speciale generiert metakognitive Spuren, die sich durch Quasi-Monte-Carlo-Simulationen im Text selbst korrigieren – was die Genauigkeit auf HMMT auf 94,6% steigert.
Für Bearbeitungen mehrerer Dateien verwenden Sie "/edit --files main.py utils.py Logging-Dekoratoren hinzufügen." Der Agent navigiert Abhängigkeiten und wendet Änderungen atomar an. Benchmarks zeigen eine Erfolgsquote von 80,3% auf Terminal-Bench 2.0, was Gemini-3.0-Pro übertrifft.
Integrieren Sie externe Tools: Konfigurieren Sie "/tool npm run build" für die Validierung nach der Generierung. DeepSeeks Tool-Nutzungs-Benchmark (84,7%) gewährleistet eine zuverlässige Orchestrierung.
Ethik überwachen: DeepSeek stimmt über RLHF mit Sicherheitsstandards überein, aber überprüfen Sie die Ausgaben auf Voreingenommenheit in Codeannahmen. Verwenden Sie die Schema-Validierung von Apidog, um sichere Muster, wie die Eingabebereinigung, durchzusetzen.
Auf Teams skalieren: Konfigurationen über Dotfiles-Repos teilen. In CI/CD betten Sie Claude Code-Skripte mit DeepSeek für automatisierte PR-Reviews ein – wodurch die Überprüfungszeit um 40% reduziert wird.
Praktische Anwendungen: DeepSeek-gestützter Claude Code in Aktion
Betrachten Sie ein Fintech-Projekt: "/generate Sichere API für Transaktionsverarbeitung mit GraphQL." DeepSeek-V3.2 generiert Schema, Resolver und Rate-Limiting-Middleware, validiert nach OWASP-Standards.
In ML-Pipelines: "/agent Optimieren Sie dieses PyTorch-Modell für Edge-Deployment." Es refaktoriert für Quantisierung, testet auf simulierter Hardware und dokumentiert Kompromisse.
Diese Fälle zeigen eine 2-3-fache Produktivitätssteigerung, untermauert durch Benutzerberichte auf GitHub-Issues.
Fazit
DeepSeek-V3.2 und DeepSeek-V3.2-Speciale verwandeln Claude Code in ein logikzentriertes Kraftpaket. Vom Open-Source-Laden bis zur API-gesteuerten Skalierbarkeit liefern diese Modelle eine benchmarkführende Leistung zu einem Bruchteil der Kosten. Implementieren Sie die beschriebenen Schritte – beginnend mit Apidog für das API-Prototyping – und erleben Sie optimierte Workflows.
Experimentieren Sie noch heute: Richten Sie Ihre Umgebung ein, führen Sie einen Beispielbefehl aus und iterieren Sie. Die Integration beschleunigt nicht nur die Entwicklung, sondern fördert auch ein tieferes Codeverständnis durch transparentes Denken. Während sich die KI weiterentwickelt, stellen Tools wie diese sicher, dass Entwickler an vorderster Front bleiben.