
Dieser Flow-Moment, wenn man tief in einer Debugging-Sitzung mit seinem Lieblings-KI-Tool steckt, nur um von einer unsichtbaren Wand getroffen zu werden, die sagt: „Halt, langsam, du hast dein Limit erreicht“? Wenn Sie mit **Codex**, dem Programmierassistenten von OpenAI, arbeiten, kommt Ihnen diese Frustration vielleicht nur allzu bekannt vor. **Codex-Nutzungsbeschränkungen** sind derzeit ein heißes Thema, besonders da immer mehr Entwickler es für alles nutzen, von schnellen Code-Snippets bis hin zu kompletten App-Builds. Die kurze Antwort? Ja, es gibt **Kontingente** und **Ratenbegrenzungen**, aber sie sind nicht pauschal – sie hängen von Ihrem Plan, der Komplexität der Aufgabe und sogar davon ab, wie Sie darauf zugreifen. In diesem Leitfaden werden wir die Details der **Codex**-Limits aufschlüsseln, Preisstufen erläutern, API-Key-Workarounds erkunden und einen Blick darauf werfen, worüber sich die Entwicklergemeinde auf Reddit und GitHub beschwert (und wie sie damit umgeht). Am Ende wissen Sie genau, wie Sie Ihre **Codex**-Sitzungen am Laufen halten, ohne diese Herzinfarkte mitten in der Eingabeaufforderung. Lassen Sie uns das entmystifizieren und Sie wieder ans Bauen bringen!
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt alle Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!
Codex-Nutzungsbeschränkungen verstehen: Die Grundlagen
Zunächst einmal: **Codex** verfügt über integrierte Schutzmechanismen, um Fairness und Nachhaltigkeit zu gewährleisten. Dies sind keine willkürlichen Hindernisse; sie dienen dazu, die Rechenressourcen von OpenAI zu verwalten und Missbrauch zu verhindern. Ab September 2025 basieren die **Codex-Nutzungsbeschränkungen** hauptsächlich auf Aufgaben, gemessen in "Nachrichten" oder "Aufgaben" und nicht in Roh-Tokens wie bei älteren APIs. Stellen Sie es sich so vor: Eine einfache Code-Vervollständigung könnte als eine Nachricht zählen, aber eine Refaktorierung mehrerer Dateien könnte, je nach Komplexität, mehrere verbrauchen.
Laut den offiziellen Dokumenten werden die Limits in einem rollierenden Fenster zurückgesetzt – oft alle 5 Stunden für lokale Aufgaben (wie CLI- oder IDE-Nutzung), wobei wöchentliche Obergrenzen für intensivere Nutzer greifen. Für ChatGPT Plus-Nutzer sind das grob 30-150 Nachrichten alle 5 Stunden lokal, plus eine wöchentliche Gesamtbegrenzung, die schnell erreicht werden kann, wenn Sie große Projekte durcharbeiten. Cloud-basierte Aufgaben (über die Weboberfläche von ChatGPT) erhalten derzeit mehr Spielraum, mit "großzügigen" Zuteilungen während dieser Beta-Phase, aber rechnen Sie nicht mit unbegrenzter Nutzung auf Dauer – OpenAI passt sich je nach Nachfrage an.
**Ratenbegrenzungen**? Sie sind hier weicher, an die Aufgabendauer gebunden und nicht an feste RPM/TPM wie bei der Kern-API. Komplexe Operationen (z. B. das Debuggen eines 10.000-Zeilen-Repos) könnten gedrosselt werden, wenn Sie 10 hintereinander ausführen, aber es geht mehr um Fairness als um strikte Abschaltungen. Enterprise-Benutzer erhalten anpassbare Setups, die aus einem gemeinsamen Kreditpool schöpfen, während kostenlose Tarife? Vergessen Sie es – **Codex** ist durch eine Paywall gesperrt. Das Ziel? Sicherstellen, dass jeder seinen Anteil bekommt, ohne die Server zum Absturz zu bringen. Wenn Sie an die Wand stoßen, sehen Sie eine höfliche Meldung "Nutzungslimit erreicht", die eine Wartezeit oder den Wechsel in den API-Modus erzwingt. Ärgerlich? Sicher. Aber es hält **Codex** für die Massen am Laufen.
Preispläne: Welcher passt zu Ihrem Codex-Workflow?
Wenn es um die Kosten geht, basiert **Codex** auf dem ChatGPT-Ökosystem, sodass Ihr Plan Ihre **Codex-Nutzungsbeschränkungen** bestimmt. Es gibt kein eigenständiges Codex-Abonnement – es ist gebündelt, was die Dinge einfach hält, aber Ihr Programmierbudget an Ihr Chat-Budget bindet. Hier ist die Aufschlüsselung:
**ChatGPT Plus (20 $/Monat)**: Der Einstiegspunkt für die meisten Solo-Entwickler. Sie erhalten 30-150 lokale Nachrichten alle 5 Stunden, mit einer wöchentlichen Obergrenze, die nach ein paar intensiven Tagen (denken Sie an 6-7 Sitzungen) greift. Cloud-Aufgaben sind vorerst nachsichtiger, ideal, wenn Sie Code-Generierung mit Brainstorming mischen. Großartig für Hobbyisten oder leichte Benutzer, aber wenn Sie Vollzeit programmieren, erwarten Sie, Sitzungen zu rotieren oder ein Upgrade durchzuführen.
**ChatGPT Pro (200 $/Monat)**: Für Power-User erhöht dies Ihre lokalen Nachrichten auf 300-1.500 alle 5 Stunden, plus erweiterte wöchentliche Limits. Es ist ein Biest für tägliche Arbeit über mehrere Projekte hinweg – perfekt, wenn **Codex** Ihr Hauptwerkzeug ist. Der Cloud-Zugriff bleibt großzügig, und Sie schalten Priorität bei neuen Modellen wie GPT-5-Codex-Vorschauen frei.
**Team (25 $/Benutzer/Monat, min. 2 Benutzer)**: Spiegelt Plus pro Platz wider, fügt aber Kollaborationsfunktionen wie gemeinsame Arbeitsbereiche hinzu. Flexible Preise ermöglichen es Ihnen, zusätzliche Credits für stoßweise Nutzung zu kaufen, um harte Obergrenzen zu umgehen. Wenn Ihre Gruppe Debugging-Marathons veranstaltet, skaliert dies ohne Drama.
**Enterprise/Edu (Angepasst, beginnt bei ca. 60 $/Benutzer/Monat)**: Die Königsklasse. Gemeinsame Kreditpools bedeuten organisationsweite Limits, die Sie anpassen können, mit Analysen zur Verfolgung des Verbrauchs. Benutzerdefinierte SLAs umfassen höhere Baselines und On-Demand-Boosts – denken Sie an unbegrenzte Nutzung für einen Sprint, dann wieder zurückfahren. Edu-Varianten fügen Compliance-Vorteile für Schulen hinzu.
Überziehungen? Plus und darunter erzwingen Wartezeiten, aber Pro/Team/Enterprise ermöglichen Ihnen den Kauf von Add-ons über die Preisliste (z. B. 0,02 $ pro zusätzlicher Nachricht).
Es ist nutzungsbasiert, überwachen Sie es also über Ihr Dashboard, um Überraschungen zu vermeiden. Die Philosophie von OpenAI: Bezahlen Sie für das, was Sie nutzen, aber beginnen Sie konservativ, um einen Rechnungsschock zu vermeiden. Für **Codex**-Hardcore-Nutzer ist Pro der Sweet Spot – erschwingliche Feuerkraft ohne Enterprise-Overhead.

Limits umgehen: Der OpenAI API-Key-Hack
Mitten in der Sitzung an eine Wand gestoßen? Hier kommt der **OpenAI API-Key** – Ihr Ausweg aus den planbasierten **Codex-Nutzungsbeschränkungen**. Anstatt sich auf die ChatGPT-Authentifizierung zu verlassen, wechseln Sie in den API-Modus für Pay-as-you-go-Freiheit. Generieren Sie einen Schlüssel unter platform.openai.com/api-keys (kostenlos, aber nutzungsbasiert abgerechnet) und setzen Sie ihn dann als Umgebungsvariable: export OPENAI_API_KEY=sk-yourkeyhere.
Im **Codex CLI** wechseln Sie mit codex config set preferred_auth_method apikey oder ad-hoc über --api-key. IDE-Erweiterungen fordern ihn ebenfalls an. Jetzt gelten die Standard-API-Raten: GPT-5-Codex für 0,015 $/1K Eingabetoken, 0,045 $/1K Ausgabe – spottbillig für die meisten Aufgaben. Keine 5-Stunden-Resets; nur RPM/TPM-Limits (z. B. 500 RPM für Plus-verknüpfte Schlüssel). Eine vollständige Debugging-Sitzung könnte Centbeträge kosten, im Gegensatz zum tagelangen Warten bei Plus.
Pro-Tipp: Modi mischen – ChatGPT für schnelle Aufgaben, API für Marathons. GitHub-Threads schwärmen von .bat-Skripten, die Schlüssel automatisch wechseln, wenn Limits erreicht werden, oder auth.json-Dateien über Konten hinweg rotieren. Es ist nicht unendlich (API hat ihre eigenen Stufen), aber es fühlt sich im Vergleich zu gebündelten Plänen grenzenlos an. Achten Sie einfach auf Ihre Rechnung – legen Sie Warnungen im Dashboard fest, um die Ausgaben zu begrenzen.
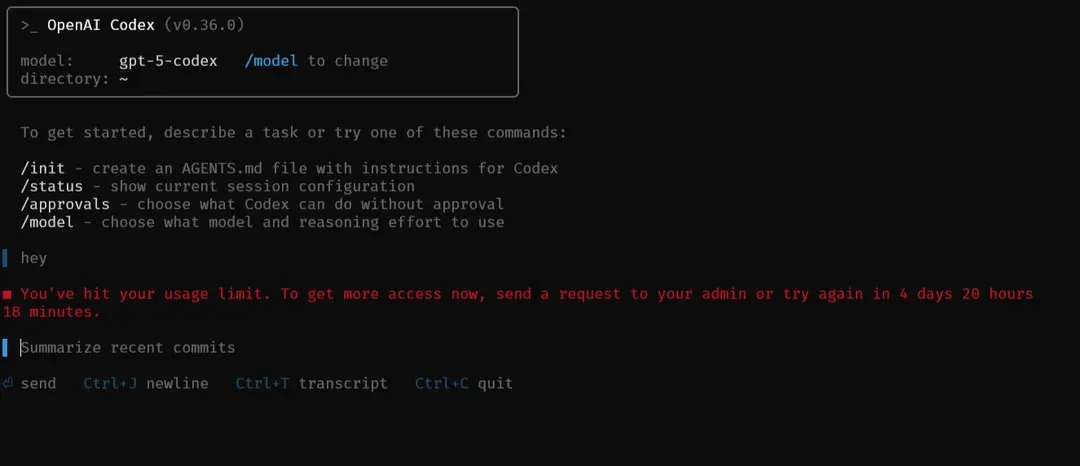
Was die Entwicklergemeinschaft sagt: Reddit- und GitHub-Beschwerden und -Erfolge
Kein Artikel über **Codex-Nutzungsbeschränkungen** ist vollständig ohne die unverfälschten Berichte von Entwicklern an der Front. Auf Reddits r/OpenAI bringt ein viraler Thread (97 Upvotes) den Schmerz auf den Punkt: "Codex-Limits sind ärgerlich, weil es dich nicht warnt!" OP Visible-Delivery-978 hatte für Plus bezahlt, eine Woche Nutzung in 1,5 Tagen Bugfixing-Glück verbraucht, und dann BAM – ausgesperrt ohne Vorwarnung. Kommentare spiegeln das Chaos wider: Ein Benutzer kündigte nach 5 Tagen Wartezeit, ein anderer nannte es "süchtig machend", wechselte aber zu Pro für weniger Unterbrechungen. Tipps? Reduzieren Sie auf "mittlere Argumentation", um Limits zu strecken, oder wechseln Sie in den Cloud-Modus für nahezu unbegrenzte Läufe. Ein Lichtblick: OpenAI setzte das Limit des Benutzers als Geste des guten Willens zurück, was Hoffnung auf bessere Warnungen weckte.
Das Codex-Repo von GitHub ist eine Goldgrube für Frustration, die zu Lösungen führte. In Diskussion #2251 beklagen sich Entwickler darüber, dass Plus-Caps nach insgesamt 12 Stunden ausgelöst werden, viel enger als bei Claudes Pro. Beschwerden häufen sich: Keine Nutzungstransparenz führt zu Panikattacken mitten in der Aufgabe, und wöchentliche Obergrenzen fühlen sich "allmählich niedriger" an, wie eine heimliche Drosselung. Workarounds glänzen – rotieren Sie 3-5 Plus-Konten über Auth-Swaps (hacky, aber effektiv) oder skripten Sie .bat-Dateien, um mitten im Workflow auf API-Schlüssel umzuschalten. Ein Entwickler schätzt 2-3 €/Tag für die API als billiger als ein Upgrade, während ein anderer vorschlägt, Sitzungen in AGENTS.md zusammenzufassen, um sie elegant fortzusetzen. Funktionsanforderungen? Automatische Re-Authentifizierung bei Limits und Fortschrittsexporte (verknüpft mit Issue #3366).
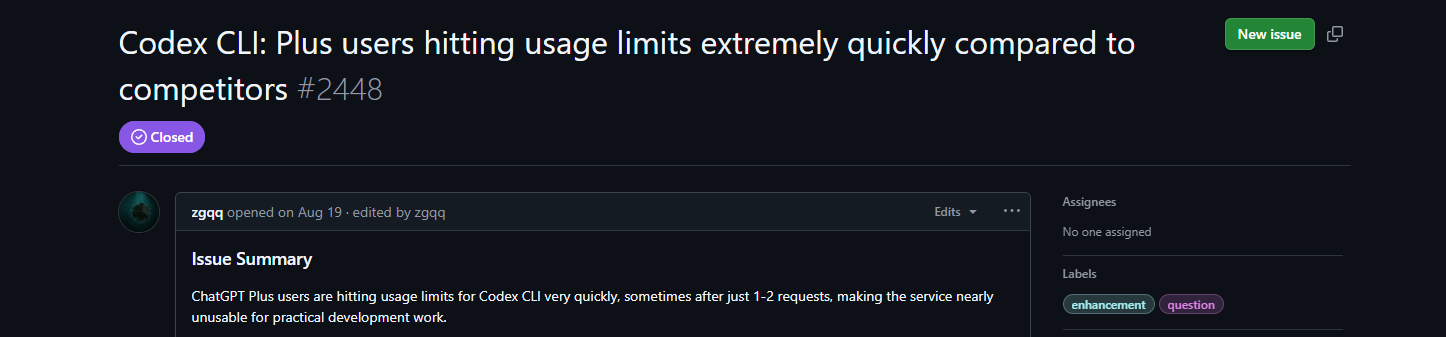
Issue #2448 heizt die Stimmung an: Plus-Nutzer stoßen nach 1-2 Anfragen an ihre Grenzen, was die CLI "nahezu unbrauchbar" macht. Im Vergleich zu Claudes Marathon-Sitzungen ist das ein Stimmungskiller – Entwickler drohen mit Wechseln und beklagen verlorenen Schwung. Vorschläge: Plus-Baselines erhöhen, CLI-Nutzungszähler hinzufügen (PR #3977 wird bald zusammengeführt) oder vollständig auf nutzungsbasierte Abrechnung umstellen. Community-Hacks umfassen die Arbeit in Unterverzeichnissen, um Kontext zu cachen und kleine Aufgaben zu stapeln. Milvus' schneller Verweis bestätigt dies: Planen Sie strategisch, überwachen Sie Dashboards und fordern Sie Enterprise-Boosts für große Projekte an.
Die Stimmung? Limits sind schlecht für den Flow, aber die Community ist widerstandsfähig – API-Wechsel und Plan-Stacks sorgen dafür, dass der Code weiterfließt. OpenAI hört zu (diese Resets und PRs beweisen es), sodass die Feedback-Schleifen enger werden.
Fazit: Limits navigieren und Tipps zur Maximierung Ihrer Codex-Sitzungen
Um dies positiv abzuschließen, hier ist, wie Sie **Codex-Nutzungsbeschränkungen** wie ein Profi umgehen können. Batch-Prompts: Eine große "generieren + testen + debuggen"-Anfrage anstelle von gesprächigen Hin- und Her-Chats. Nutzen Sie die Cloud für Stoßzeiten und verfolgen Sie dies über Dashboard-Benachrichtigungen, und richten Sie eine API als Backup ein. Für Teams ist der Enterprise-Pool ein Lebensretter. Und hey, wenn sich die Limits ändern (OpenAI passt sich basierend auf Feedback an), bleiben Sie dran an diesen GitHub-Issues.
**Codex** ist die Anpassungen wert – seine Intelligenz spart Stunden, ob mit oder ohne Limits. Haben Sie eine Horrorstory zu Limits oder einen Hack? Teilen Sie es auf den Entwicklerplattformen mit. Bis zum nächsten Mal: Programmieren Sie clever, testen Sie oft, und mögen Ihre Kontingente immer voll sein!
