Manuelle Fetch-Aufrufe zu erstellen, Authentifizierungs-Tokens zu handhaben und API-Antworten für jede neue Integration zu parsen, ist das moderne Äquivalent zum Schreiben von Assembler-Code für Web-Apps. Claude Code Skills für die Datenabfrage verwandeln HTTP-Anfragen in deklarative, wiederverwendbare Tools, die Authentifizierungsmuster, Paginierung und Antwortvalidierung verstehen, wodurch Boilerplate-Code eliminiert und gleichzeitig die Konsistenz in Ihrer Codebasis gewährleistet wird.
Warum API-Netzwerk-Fähigkeiten für Entwicklungs-Workflows wichtig sind
Jeder Entwickler verbringt Stunden mit repetitiver API-Rohrverlegung: Einrichten von Headern für OAuth 2.0, Implementieren von exponentiellem Backoff für ratenbegrenzte Endpunkte und Schreiben von Typ-Guards für unvorhersehbare JSON-Antworten. Diese Aufgaben sind fehleranfällig und eng an spezifische Dienste gekoppelt, was sie schwer test- und wartbar macht. Claude Code Skills abstrahieren diese Komplexität in versionierte, testbare Tools, die Ihr KI-Assistent mit natürlicher Sprache aufrufen kann.
Die Umstellung erfolgt von imperativen API-Aufrufen zu deklarativem Datenabruf. Anstatt fetch(url, { headers: {...} }) zu schreiben, beschreiben Sie die Absicht: „Benutzerdaten von der GitHub-API mithilfe des Tokens aus ENV abrufen und typisierte Ergebnisse zurückgeben.“ Die Fähigkeit übernimmt die Credential-Verwaltung, die Wiederholungslogik und das Parsen der Antwort und liefert stark typisierte Daten, die Ihre Anwendung sofort verwenden kann.
Möchten Sie eine integrierte All-in-One-Plattform für Ihr Entwicklerteam, um mit maximaler Produktivität zusammenzuarbeiten?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!
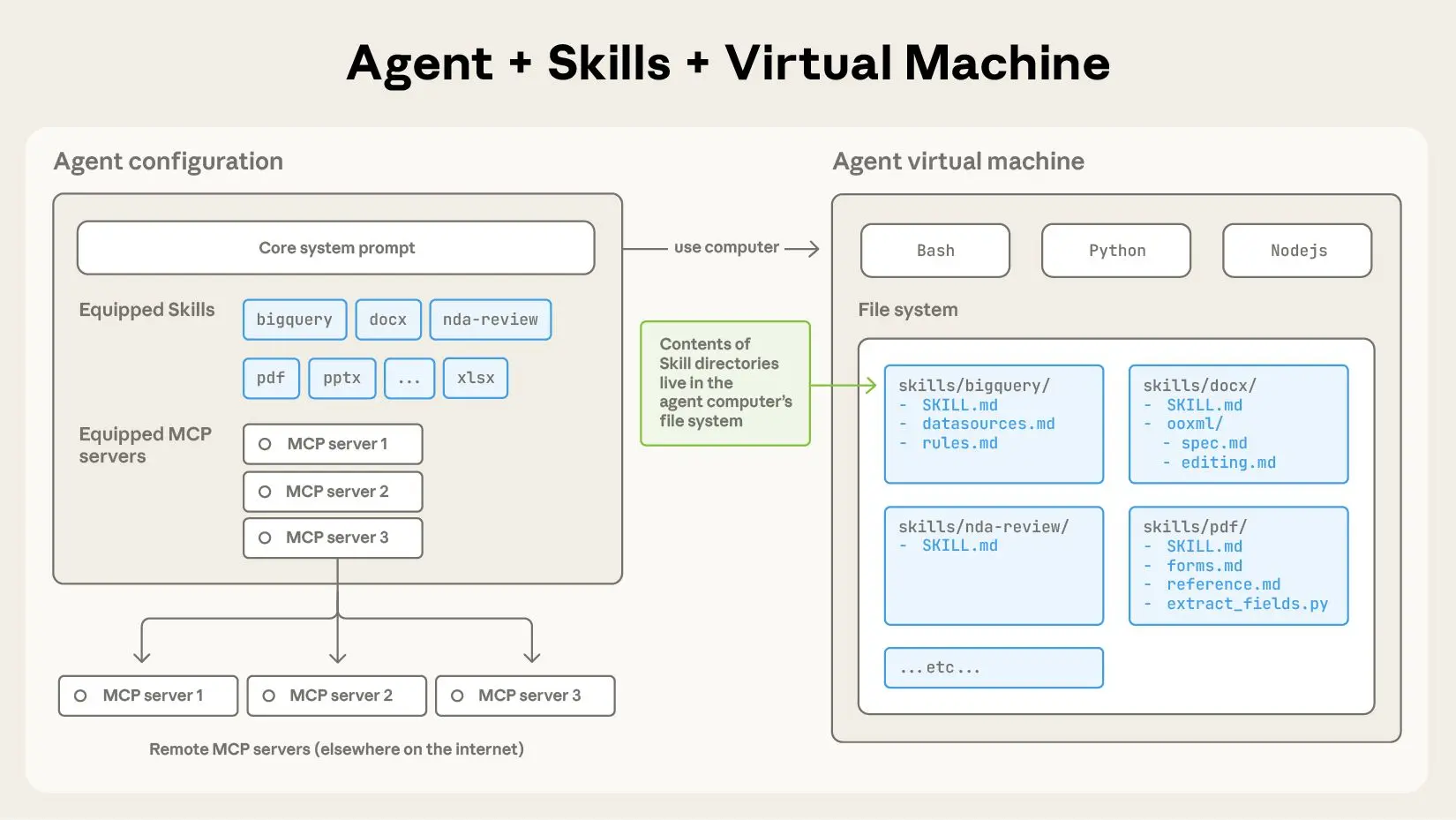
Einrichten der Datenabfrage-Fähigkeit in Claude Code
Schritt 1: Claude Code installieren und MCP konfigurieren
Wenn Sie die Claude Code CLI noch nicht installiert haben:
npm install -g @anthropic-ai/claude-code
claude --version # Should show >= 2.0.70
Erstellen Sie das MCP-Konfigurationsverzeichnis und die Datei:
# macOS/Linux
mkdir -p ~/.config/claude-code
touch ~/.config/claude-code/config.json
# Windows
mkdir %APPDATA%\claude-code
echo {} > %APPDATA%\claude-code\config.json

Schritt 2: Die Datenabfrage-Fähigkeit klonen und erstellen
Die offizielle Datenabfrage-Fähigkeit bietet Muster für REST, GraphQL und generische HTTP-Anfragen.
git clone https://github.com/anthropics/skills.git
cd skills/skills/data-fetching
npm install
npm run build
Dies kompiliert die TypeScript-Handler nach dist/index.js.
Schritt 3: MCP zum Laden der Fähigkeit konfigurieren
Bearbeiten Sie ~/.config/claude-code/config.json:
{
"mcpServers": {
"data-fetching": {
"command": "node",
"args": ["/absolute/path/to/skills/data-fetching/dist/index.js"],
"env": {
"DEFAULT_TIMEOUT": "30000",
"MAX_RETRIES": "3",
"RATE_LIMIT_PER_MINUTE": "60",
"CREDENTIALS_STORE": "~/.claude-credentials.json"
}
}
}
}
Wichtig:
- Verwenden Sie absolute Pfade für
args - Umgebungsvariablen konfigurieren:
DEFAULT_TIMEOUT: Anfrage-Timeout in MillisekundenMAX_RETRIES: Anzahl der Wiederholungsversuche für 5xx-FehlerRATE_LIMIT_PER_MINUTE: DrosselungsschwelleCREDENTIALS_STORE: Pfad zur verschlüsselten Credentials-Datei
Schritt 4: Credentials Store einrichten
Erstellen Sie die Credentials-Datei, um das Hardcodieren von Tokens zu vermeiden:
# Verschlüsselten Credentials Store erstellen
mkdir -p ~/.claude
echo '{}' > ~/.claude/credentials.json
chmod 600 ~/.claude/credentials.json
Fügen Sie Ihre API-Tokens hinzu:
{
"github": {
"token": "ghp_your_github_token_here",
"baseUrl": "https://api.github.com"
},
"slack": {
"token": "xoxb-your-slack-token",
"baseUrl": "https://slack.com/api"
},
"custom-api": {
"token": "Bearer your-jwt-token",
"baseUrl": "https://api.yourcompany.com",
"headers": {
"X-API-Version": "v2"
}
}
}
Die Fähigkeit liest diese Datei beim Start und fügt die Zugangsdaten in die Anfragen ein.
Schritt 5: Installation überprüfen
claude
Nach dem Laden ausführen:
/list-tools
Sie sollten sehen:
Available tools:
- data-fetching:rest-get
- data-fetching:rest-post
- data-fetching:rest-put
- data-fetching:rest-delete
- data-fetching:graphql-query
- data-fetching:graphql-mutation
- data-fetching:raw-http
Wichtige API-Anfragemuster
1. RESTful GET-Anfragen
Tool: data-fetching:rest-get
Anwendungsfall: Daten von REST-Endpunkten mit Authentifizierung, Paginierung und Caching abrufen
Parameter:
service: Schlüssel, der dem Credentials Store entspricht (github, slack, custom-api)endpoint: API-Pfad (z. B./users,/repos/owner/name)params: Objekt der Abfrageparametercache: TTL in Sekunden (optional)transform: JMESPath-Ausdruck für die Antworttransformation
Beispiel: GitHub-Benutzer-Repositories abrufen
Use rest-get to fetch repositories for user "anthropics" from GitHub API, including pagination for 100 items per page, and return only name, description, and stargazers_count.
Generierte Ausführung:
// Handler führt aus:
const response = await fetch('https://api.github.com/users/anthropics/repos', {
headers: {
'Authorization': 'token ghp_your_github_token_here',
'Accept': 'application/vnd.github.v3+json'
},
params: {
per_page: 100,
page: 1
}
});
// Transformieren mit JMESPath
const transformed = jmespath.search(response, '[*].{name: name, description: description, stars: stargazers_count}');
return transformed;
Claude Code-Nutzung:
claude --skill data-fetching \
--tool rest-get \
--params '{"service": "github", "endpoint": "/users/anthropics/repos", "params": {"per_page": 100}, "transform": "[*].{name: name, description: description, stars: stargazers_count}"}'
2. POST/PUT/DELETE-Anfragen
Tool: data-fetching:rest-post / rest-put / rest-delete
Anwendungsfall: Ressourcen erstellen, aktualisieren oder löschen
Parameter:
service: Schlüssel des Credentials Storesendpoint: API-Pfadbody: Anfrage-Payload (Objekt oder JSON-String)headers: Zusätzliche HeaderidempotencyKey: Für Wiederholungssicherheit
Beispiel: Ein GitHub-Issue erstellen
Use rest-post to create an issue in the anthorpics/claude repository with title "Feature Request: MCP Tool Caching", body containing the description, and labels ["enhancement", "mcp"].
Ausführung:
await fetch('https://api.github.com/repos/anthropics/claude/issues', {
method: 'POST',
headers: {
'Authorization': 'token ghp_...',
'Content-Type': 'application/json'
},
body: JSON.stringify({
title: "Feature Request: MCP Tool Caching",
body: "Description of the feature...",
labels: ["enhancement", "mcp"]
})
});
3. GraphQL-Abfragen
Tool: data-fetching:graphql-query
Anwendungsfall: Komplexer Datenabruf mit verschachtelten Beziehungen
Parameter:
service: Schlüssel des Credentials Storesquery: GraphQL-Abfrage-Stringvariables: Objekt der AbfragevariablenoperationName: Benannte Operation
Beispiel: Repository-Issues mit Kommentaren abrufen
Use graphql-query to fetch the 10 most recent open issues from the anthorpics/skills repository, including title, author, comment count, and labels.
query RecentIssues($owner: String!, $repo: String!, $limit: Int!) {
repository(owner: $owner, name: $repo) {
issues(first: $limit, states: [OPEN], orderBy: {field: CREATED_AT, direction: DESC}) {
nodes {
title
author { login }
comments { totalCount }
labels(first: 5) { nodes { name } }
}
}
}
}
Parameter:
{
"service": "github",
"query": "query RecentIssues($owner: String!, $repo: String!, $limit: Int!) { ... }",
"variables": {
"owner": "anthropics",
"repo": "skills",
"limit": 10
}
}
4. Rohe HTTP-Anfragen
Tool: data-fetching:raw-http
Anwendungsfall: Grenzfälle, die nicht von REST/GraphQL-Tools abgedeckt werden
Parameter:
url: Vollständige URLmethod: HTTP-Methodeheaders: Header-Objektbody: Anfrage-Bodytimeout: Standard-Timeout überschreiben
Beispiel: Webhook-Zustellung mit benutzerdefinierten Headern
Use raw-http to POST to https://hooks.slack.com/services/YOUR/WEBHOOK/URL with a JSON payload containing {text: "Deployment complete"}, and custom header X-Event: deployment-success.
Erweiterte Netzwerkszenarien
Paginierungshandhabung
Die Fähigkeit erkennt automatisch Paginierungsmuster:
// GitHub Link Header-Parsing
const linkHeader = response.headers.get('Link');
if (linkHeader) {
const nextUrl = parseLinkHeader(linkHeader).next;
if (nextUrl && currentPage < maxPages) {
return {
data: currentData,
nextPage: currentPage + 1,
hasMore: true
};
}
}
Alle Seiten anfordern:
Use rest-get to fetch all repositories for user "anthropics", handling pagination automatically until no more pages exist.
Die Fähigkeit gibt ein flaches Array aller Ergebnisse zurück.
Ratenbegrenzung und Wiederholungslogik
Wiederholungsverhalten pro Anfrage konfigurieren:
{
"service": "github",
"endpoint": "/rate_limit",
"maxRetries": 5,
"retryDelay": "exponential",
"retryOn": [429, 500, 502, 503, 504]
}
Die Fähigkeit implementiert exponentielles Backoff mit Jitter:
const delay = Math.min(
(2 ** attempt) * 1000 + Math.random() * 1000,
30000
);
await new Promise(resolve => setTimeout(resolve, delay));
Verwaltung gleichzeitiger Anfragen
Mehrere API-Aufrufe effizient bündeln:
Use rest-get to fetch details for repositories: ["claude", "skills", "anthropic-sdk"], executing requests concurrently with a maximum of 3 parallel connections.
Die Fähigkeit verwendet p-limit, um die Parallelität zu drosseln:
import pLimit from 'p-limit';
const limit = pLimit(3); // Max 3 concurrent
const results = await Promise.all(
repos.map(repo =>
limit(() => fetchRepoDetails(repo))
)
);
Anfragenabfangen und Mocking
Zum Testen Anfragen abfangen, ohne echte APIs zu erreichen:
// In der Skill-Konfiguration
"env": {
"MOCK_MODE": "true",
"MOCK_FIXTURES_DIR": "./test/fixtures"
}
Anfragen geben nun Mock-Daten aus JSON-Dateien zurück:
// test/fixtures/github/repos/anthropics.json
[
{"name": "claude", "description": "AI assistant", "stars": 5000}
]
Praktische Anwendung: Erstellen eines GitHub-Dashboards
Schritt 1: Repository-Daten abrufen
Use rest-get to fetch all repositories from GitHub for organization "anthropics", including full description, star count, fork count, and open issues count. Cache results for 5 minutes.
Schritt 2: Mit Mitwirkenden-Daten anreichern
Für jedes Repository die Top-Mitwirkenden abrufen:
Use rest-get to fetch contributor statistics for repository "anthropics/claude", limit to top 10 contributors, and extract login and contributions count.
Schritt 3: Zusammenfassende Statistiken generieren
Daten in Claude Code kombinieren:
const repos = await fetchAllRepos('anthropics');
const enrichedRepos = await Promise.all(
repos.map(async (repo) => {
const contributors = await fetchTopContributors('anthropics', repo.name);
return { ...repo, topContributors: contributors };
})
);
return {
totalStars: enrichedRepos.reduce((sum, r) => sum + r.stars, 0),
totalForks: enrichedRepos.reduce((sum, r) => sum + r.forks, 0),
repositories: enrichedRepos
};
Schritt 4: Dashboard veröffentlichen
Use rest-post to create a GitHub Pages site with the dashboard data using the GitHub API to commit to the gh-pages branch.
Fehlerbehandlung und Resilienz
Die Fähigkeit kategorisiert Fehler zur ordnungsgemäßen Behandlung:
// 4xx Fehler: Client-Fehler
if (response.status >= 400 && response.status < 500) {
throw new SkillError('client_error', `Invalid request: ${response.status}`, {
statusCode: response.status,
details: await response.text()
});
}
// 5xx Fehler: Server-Fehler (wiederholbar)
if (response.status >= 500) {
throw new SkillError('server_error', `Server error: ${response.status}`, {
retryable: true,
statusCode: response.status
});
}
// Netzwerkfehler: Verbindungsfehler
if (error.code === 'ECONNREFUSED' || error.code === 'ETIMEDOUT') {
throw new SkillError('network_error', 'Netzwerk nicht erreichbar', {
retryable: true,
originalError: error.message
});
}
Claude Code empfängt strukturierte Fehler und kann entscheiden, ob ein erneuter Versuch, ein Abbruch oder eine Benutzerintervention erforderlich ist.
Fazit
Claude Code Skills für die API-Netzwerkkommunikation verwandeln Ad-hoc-HTTP-Anfragen in zuverlässige, typsichere und beobachtbare Datenabfrage-Tools. Durch die Zentralisierung der Credential-Verwaltung, die Implementierung intelligenter Wiederholungsversuche und die Bereitstellung einer strukturierten Fehlerbehandlung eliminieren Sie die häufigsten Ursachen für API-Integrationsfehler. Beginnen Sie mit den vier Kern-Tools – rest-get, rest-post, graphql-query und raw-http – und erweitern Sie diese dann für Ihre spezifischen Anwendungsfälle. Die Investition in die Skill-Konfiguration zahlt sich sofort in Code-Konsistenz und Entwicklungsgeschwindigkeit aus.
Wenn Ihre Datenabfrage-Fähigkeiten mit internen APIs interagieren, validieren Sie diese Endpunkte mit Apidog, um sicherzustellen, dass Ihre KI-gesteuerten Integrationen zuverlässige Kontrakte verwenden.