
Die Qwen 3 Familie dominiert die Open-Source LLM-Landschaft im Jahr 2026. Ingenieure setzen diese Modelle überall ein – von geschäftskritischen Unternehmensagenten bis hin zu mobilen Assistenten. Bevor Sie Anfragen an Alibaba Cloud senden oder selbst hosten, optimieren Sie Ihren Workflow mit Apidog.
Übersicht über Qwen 3: Architektonische Innovationen, die die Leistung 2026 antreiben
Alibabas Qwen-Team veröffentlichte die Qwen 3-Serie am 29. April 2026 und markierte damit einen entscheidenden Fortschritt bei Open-Source Large Language Models (LLMs). Entwickler loben die Apache 2.0-Lizenz, die uneingeschränktes Fine-Tuning und kommerziellen Einsatz ermöglicht. Im Kern verwendet Qwen 3 eine Transformer-basierte Architektur mit Verbesserungen bei Positional Embeddings und Aufmerksamkeitsmechanismen, die Kontextlängen von bis zu 128K Token nativ unterstützen – und über YaRN auf 131K erweiterbar sind.

Darüber hinaus integriert die Serie Mixture-of-Experts (MoE)-Designs in ausgewählten Varianten, die während der Inferenz nur einen Bruchteil der Parameter aktivieren. Dieser Ansatz reduziert den Rechenaufwand bei gleichzeitiger Beibehaltung einer hohen Qualität der Ausgaben. Zum Beispiel berichten Ingenieure von bis zu 10x höherem Durchsatz bei Aufgaben mit langem Kontext im Vergleich zu dichten Vorgängern wie Qwen2.5-72B. Infolgedessen skalieren Qwen 3 Varianten effizient über verschiedene Hardware, von Edge-Geräten bis zu Cloud-Clustern.
Qwen 3 zeichnet sich auch durch mehrsprachige Unterstützung aus und verarbeitet über 119 Sprachen mit nuancierter Instruktionsbefolgung. Benchmarks bestätigen seinen Vorteil in STEM-Bereichen, wo es synthetische Mathematik- und Codedaten verarbeitet, die aus 36 Billionen Token verfeinert wurden. Daher profitieren Anwendungen in globalen Unternehmen von reduzierten Übersetzungsfehlern und verbessertem interlingualen Reasoning. Im Detail ermöglicht der hybride Reasoning-Modus – umschaltbar über Tokenizer-Flags – den Modellen, eine schrittweise Logik für Mathematik oder Codierung zu verwenden oder standardmäßig auf Nicht-Denken für Dialoge umzuschalten. Diese Dualität befähigt Entwickler, für jeden Anwendungsfall zu optimieren.
Schlüsselfunktionen, die Qwen 3 Varianten vereinen
Alle Qwen 3 Modelle teilen grundlegende Eigenschaften, die ihren Nutzen im Jahr 2026 steigern. Erstens unterstützen sie den Dual-Modus-Betrieb: Der Denkmodus aktiviert Chain-of-Thought-Prozesse für Benchmarks wie AIME25, während der Nicht-Denkmodus die Geschwindigkeit für Chat-Anwendungen priorisiert. Ingenieure schalten dies mit einfachen Parametern um und erreichen bis zu 92,3 % Genauigkeit bei komplexen mathematischen Aufgaben, ohne die Latenz zu beeinträchtigen.
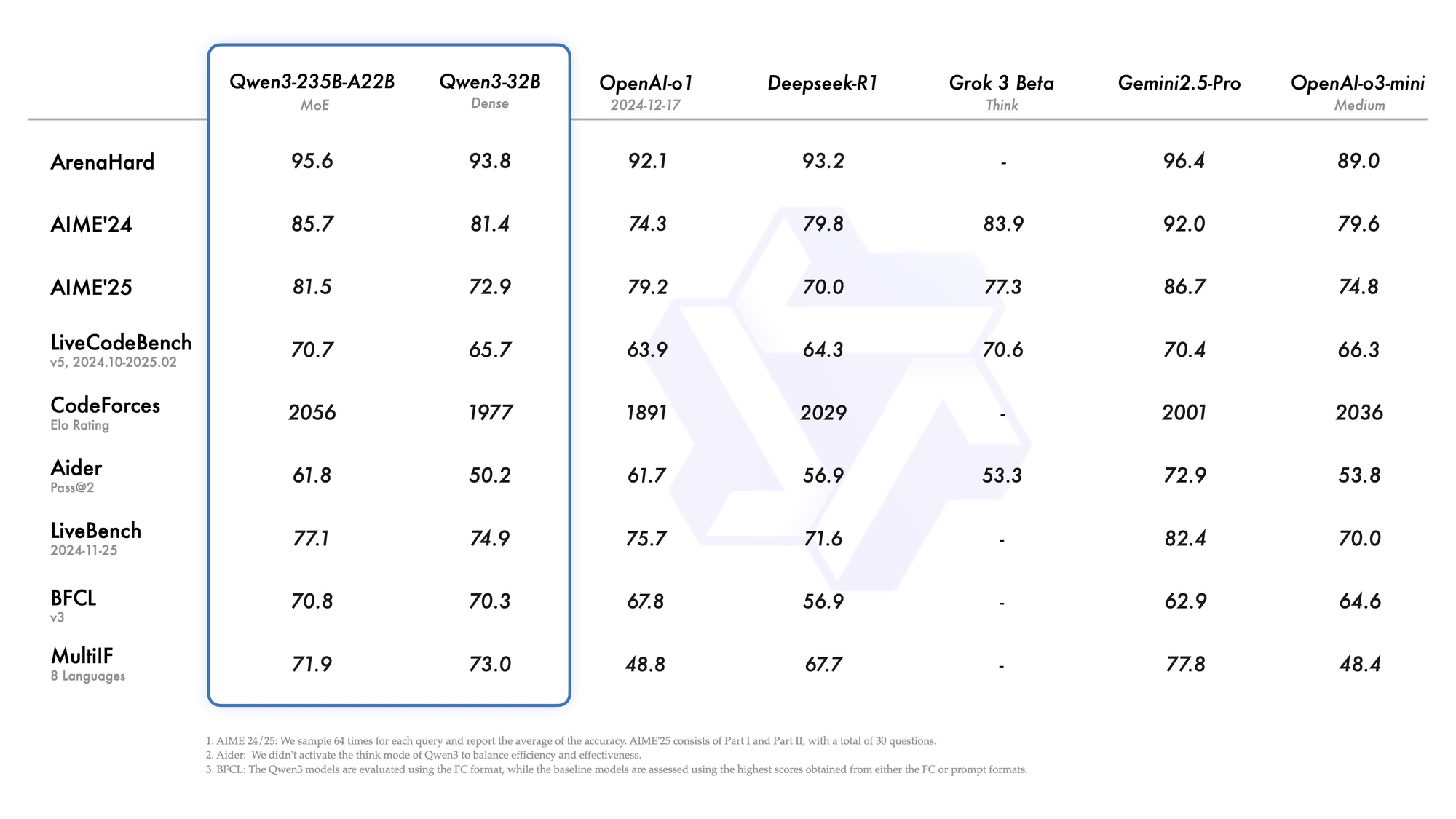
Zweitens ermöglichen Agenten-Funktionen nahtloses Tool-Calling und übertreffen Open-Source-Konkurrenten bei Aufgaben wie Browser-Navigation oder Code-Ausführung. Zum Beispiel erreichen Qwen 3 Varianten 69,6 auf Tau2-Bench Verified und konkurrieren mit proprietären Modellen. Zusätzlich deckt die mehrsprachige Kompetenz Dialekte von Mandarin bis Swahili ab, mit 73,0 auf MultiIF-Benchmarks.
Drittens resultiert die Effizienz aus quantisierten Varianten (z.B. Q4_K_M) und Frameworks wie vLLM oder SGLang, die 25 Token/Sekunde auf Consumer-GPUs liefern. Größere Modelle erfordern jedoch 16 GB+ VRAM, was Cloud-Deployments notwendig macht. Die Preisgestaltung bleibt wettbewerbsfähig, mit Input-Tokenpreisen von $0,20–$1,20 pro Million über Alibaba Cloud.
Darüber hinaus legt Qwen 3 Wert auf Sicherheit durch integrierte Moderation, wodurch Halluzinationen um 15 % gegenüber Qwen2.5 reduziert werden. Entwickler nutzen dies für produktionsreife Anwendungen, von E-Commerce-Empfehlungssystemen bis hin zu Rechtsanalysatoren. Während wir uns den einzelnen Varianten zuwenden, bilden diese gemeinsamen Stärken eine konsistente Vergleichsbasis.
Die 5 besten Qwen 3 Modellvarianten im Jahr 2026
Basierend auf den Benchmarks 2026 von LMSYS Arena, LiveCodeBench und SWE-Bench listen wir die Top fünf Qwen 3 Varianten auf. Auswahlkriterien umfassen Reasoning-Scores, Inferenzgeschwindigkeit, Parametereffizienz und API-Zugänglichkeit. Jede Variante glänzt in unterschiedlichen Szenarien, aber alle treiben die Open-Source-Grenzen voran.
1. Qwen3-235B-A22B – Das absolute Flaggschiff MoE-Monster
Qwen3-235B-A22B zieht als führende MoE-Variante Aufmerksamkeit auf sich, mit 235 Milliarden Gesamtparametern und 22 Milliarden aktiven Parametern pro Token. Im Juli 2026 als Qwen3-235B-A22B-Instruct-2507 veröffentlicht, aktiviert es acht Experten über Top-K-Routing, wodurch die Rechenleistung im Vergleich zu dichten Äquivalenten um 90 % reduziert wird. Benchmarks positionieren es Kopf an Kopf mit Gemini 2.5 Pro: 95,6 auf ArenaHard, 77,1 auf LiveBench und Führung in CodeForces Elo (mit 5 % Vorsprung).
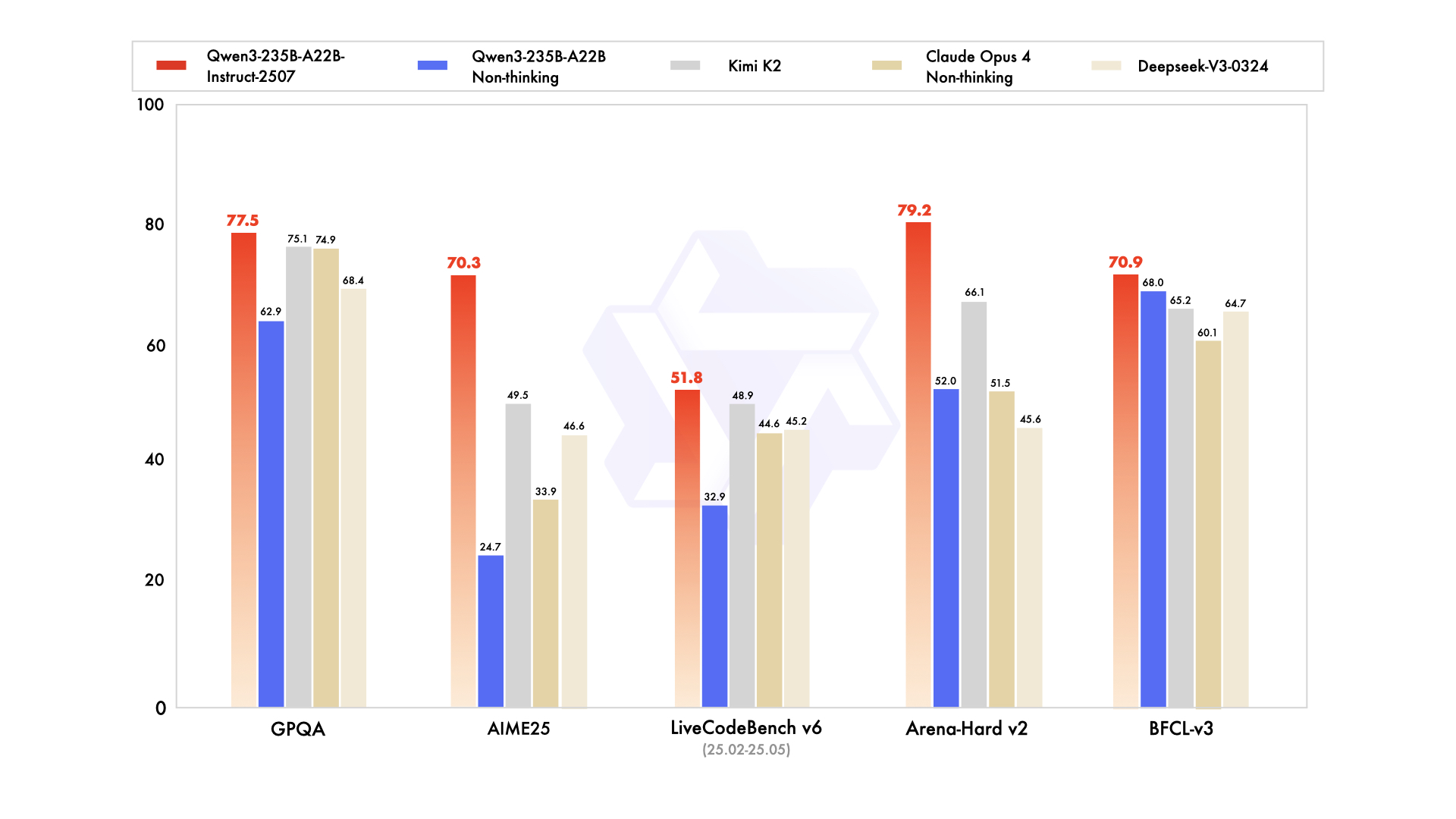
Beim Codieren erreicht es 74,8 auf LiveCodeBench v6 und generiert funktionales TypeScript mit minimalen Iterationen. Für Mathematik liefert der Denkmodus 92,3 auf AIME25 und löst mehrstufige Integrale durch explizite Deduktion. Mehrsprachige Aufgaben erzielen 73,0 auf MultiIF und verarbeiten arabische Anfragen fehlerfrei.
Der Einsatz bevorzugt Cloud-APIs, wo es 256K Kontexte verarbeitet. Lokale Ausführungen erfordern jedoch 8x H100 GPUs. Ingenieure integrieren es für Agenten-Workflows, wie das Debuggen auf Repository-Ebene. Insgesamt setzt diese Variante den Standard für Tiefe im Jahr 2026, obwohl ihre Größe für Teams mit hohem Budget geeignet ist.
Stärken
- Entspricht oder übertrifft Gemini 2.5 Pro und Claude 3.7 Sonnet auf fast jeder 2026er Bestenliste (95,6 ArenaHard, 92,3 AIME25 Denkmodus, 74,8 LiveCodeBench v6).
- Hervorragend bei mehrstufigen Agenten-Workflows, komplexem Tool-Calling und Code-Verständnis auf Repository-Ebene.
- Verarbeitet 256K–1M Kontext mit YaRN ohne Qualitätsverlust.
- Der Denkmodus liefert nachprüfbare Chain-of-Thought-Argumentation, die mit Closed-Source-Frontier-Modellen konkurriert.
Schwächen
- Lokal extrem teuer und langsam – erfordert 8×H100 oder Äquivalentes für eine akzeptable Latenz.
- Die API-Preise sind die höchsten in der Familie ($1,20–$6,00/M Output-Token bei Spitzenkontext).
- Überdimensioniert für 95 % der Produktions-Workloads; die meisten Teams schöpfen seine Kapazität nie aus.
Wann es verwendet werden sollte
- Autonome Agenten auf Unternehmensniveau, die Mathematik auf PhD-Niveau lösen, ganze Codebasen debuggen oder juristische Vertragsanalysen mit nahezu null Halluzinationen durchführen müssen.
- Forschungslabore mit hohem Budget, die den Stand der Technik bei neuen Benchmarks vorantreiben.
- Interne Reasoning-Backends, bei denen die Kosten pro Token gegenüber maximaler Intelligenz zweitrangig sind.
2. Qwen3-30B-A3B – Der Sweet-Spot MoE-Champion
Qwen3-30B-A3B erweist sich als die erste Wahl für ressourcenbeschränkte Setups, mit 30,5 Milliarden Gesamtparametern und 3,3 Milliarden aktiven. Seine MoE-Struktur – 48 Schichten, 128 Experten (acht geroutet) – spiegelt das Flaggschiff wider, jedoch mit 10 % des Speicherbedarfs. Im Juli 2026 aktualisiert, übertrifft es QwQ-32B um das 10-fache an aktiver Effizienz und erreicht 91,0 auf ArenaHard und 69,6 auf SWE-Bench Verified.
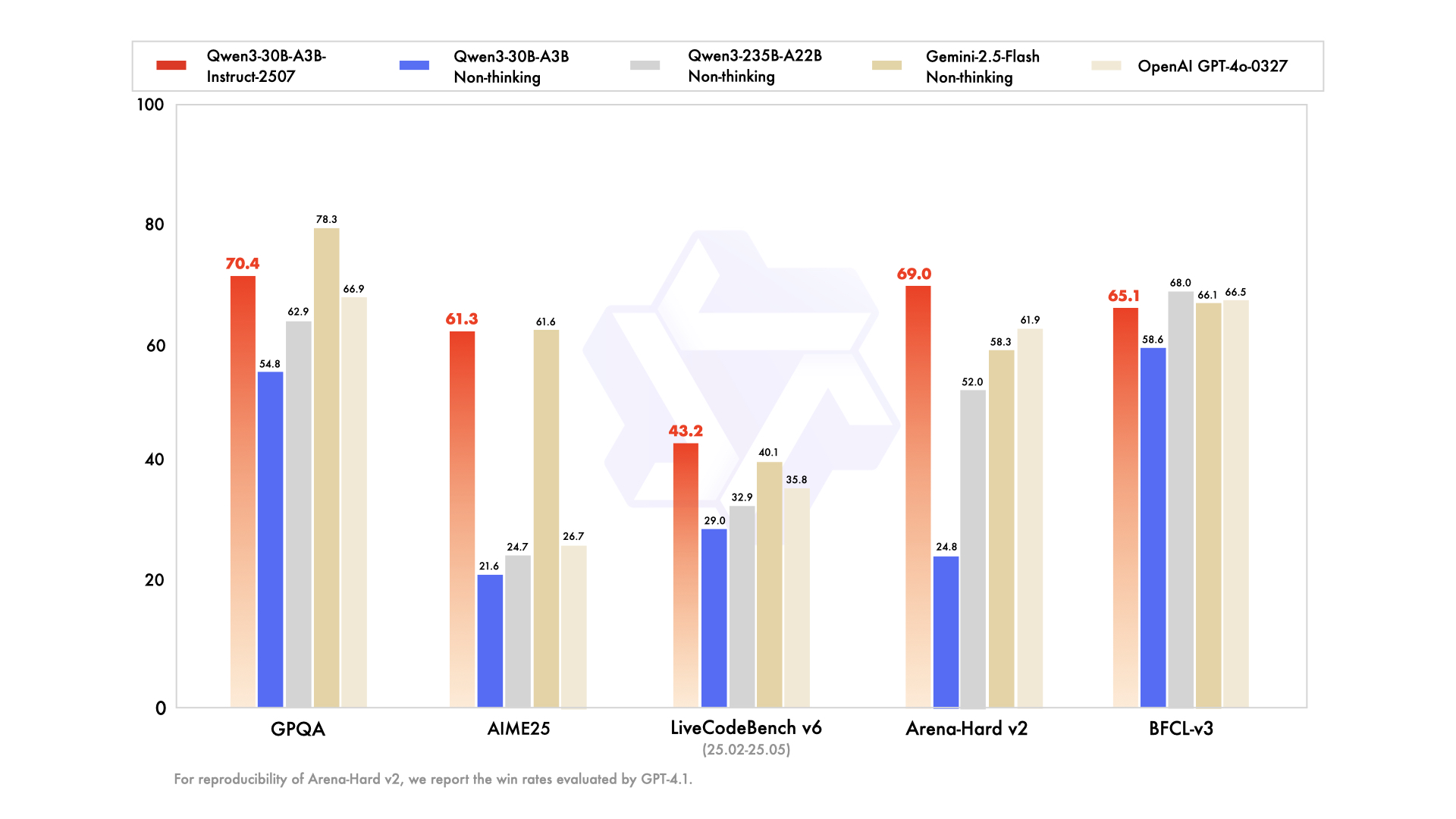
Code-Evaluierungen unterstreichen seine Leistungsfähigkeit: 32,4 % pass@5 bei neuen GitHub PRs, was GPT-5-High entspricht. Mathematik-Benchmarks zeigen 81,6 auf AIME25 im Denkmodus, was größeren Geschwistern ebenbürtig ist. Mit 131K Kontext über YaRN verarbeitet es lange Dokumente ohne Trunkierung.
Stärken
- 10× günstigere aktive Parameter als das 235B, während es ~90–95 % der Flaggschiff-Reasoning-Qualität beibehält (91,0 ArenaHard, 81,6 AIME25).
- Läuft komfortabel auf einer einzelnen 80GB A100 oder zwei 40GB Karten mit vLLM + FlashAttention.
- Bestes Preis-Leistungs-Verhältnis unter allen Open MoE-Modellen des Jahres 2026.
- Übertrifft jedes dichte 72B–110B Modell bei Codierung und Mathematik.
Schwächen
- Benötigt immer noch ~24–30GB VRAM in FP8/INT4; nicht Laptop-freundlich.
- Etwas geringere kreative Schreibflüssigkeit als reine dichte Modelle ähnlicher Größe.
- Die Latenz des Denkmodus springt um das 2–3-fache im Vergleich zum Nicht-Denken.
Wann es verwendet werden sollte
- Produktions-Code-Agenten, automatisierte PR-Reviews oder interne DevOps-Copilots.
- Forschungspipelines mit hohem Durchsatz, die Reasoning auf Spitzenniveau in Mathematik oder Naturwissenschaften mit einem vernünftigen Budget benötigen.
- Jedes Team, das zuvor Llama-405B oder Mixtral-123B verwendet hat, aber besseres Reasoning zu geringeren Kosten wünscht.
3. Qwen3-32B – Der dichte Allrounder-König
Das dichte Qwen3-32B liefert 32 Milliarden voll aktive Parameter und betont rohen Durchsatz gegenüber Sparsität. Auf 36 Billionen Token trainiert, entspricht es Qwen2.5-72B in der Basisleistung, excelled aber in der Post-Training-Anpassung. Benchmarks zeigen 89,5 auf ArenaHard und 73,0 auf MultiIF, mit starker kreativer Schreibweise (z.B. Rollenspiel-Narrative mit 85 % menschlicher Präferenz).
Beim Codieren führt es BFCL mit 68,2 an und generiert Drag-and-Drop-UIs aus Prompts. Mathematik liefert 70,3 auf AIME25, obwohl es MoE-Konkurrenten im Chain-of-Thought hinterherhinkt. Sein 128K Kontext eignet sich für Wissensdatenbanken, und der Nicht-Denkmodus erhöht die Dialoggeschwindigkeit auf 20 Token/Sekunde.
Stärken
- Außergewöhnliche Instruktionsbefolgung und kreative Ausgabe – oft größeren MoE-Modellen in blinden menschlichen Bewertungen für Schreiben und Rollenspiele vorgezogen.
- Einfach mit LoRA/QLoRA auf Consumer-Hardware (16–24GB VRAM) fine-zuzuneh.
- Schnellste Inferenz unter Modellen, die GPT-4o bei vielen Aufgaben immer noch übertreffen (89,5 ArenaHard).
- Sehr starke mehrsprachige Leistung über 119+ Sprachen.
Schwächen
- Fällt ~8–12 Punkte hinter MoE-Geschwistermodelle bei den schwierigsten Mathematik- und Codierungs-Benchmarks zurück, wenn der Denkmodus aktiviert ist.
- Keine Parameter-Effizienz-Tricks – jedes Token kostet die volle 32B-Rechenleistung.
Wann es verwendet werden sollte
- Plattformen zur Inhaltserstellung, Roman-Schreibassistenten, Marketing-Text-Tools.
- Projekte, die ein intensives Fine-Tuning erfordern (domänenspezifische Chatbots, Stiltransfer).
- Teams, die eine nahezu Flaggschiff-Qualität wünschen, aber unter 24 GB VRAM bleiben müssen.
4. Qwen3-14B – Edge- & Mobile-Kraftpaket
Qwen3-14B priorisiert Portabilität mit 14,8 Milliarden Parametern und unterstützt 128K Kontexte auf Mid-Range-Hardware. Es konkurriert mit Qwen2.5-32B in Effizienz, erzielt 85,5 auf ArenaHard und liefert sich ein Kopf-an-Kopf-Rennen mit Qwen3-30B-A3B in Mathematik/Codierung (innerhalb einer 5%-Marge). Auf Q4_0 quantisiert, läuft es mit 24,5 Token/Sekunde auf mobilen Geräten wie dem RedMagic 8S Pro.
Agenten-Aufgaben erreichen 65,1 auf Tau2-Bench, was den Einsatz von Tools in Anwendungen mit geringer Latenz ermöglicht. Die mehrsprachige Unterstützung glänzt mit 70 % Genauigkeit bei der dialektalen Inferenz. Für Edge-Geräte verarbeitet es 32K Kontexte offline, ideal für IoT-Analysen.
Ingenieure schätzen seinen geringen Ressourcenbedarf für Federated Learning, wo Datenschutz vor Skalierbarkeit geht. Daher eignet es sich für mobile KI-Assistenten oder eingebettete Systeme.
Stärken
- Läuft mit 24–30 Token/Sekunde auf modernen Telefonen (Snapdragon 8 Gen 4, Dimensity 9400), wenn auf Q4_K_M quantisiert.
- Übertrifft immer noch Qwen2.5-32B und Llama-3.1-70B bei den meisten Reasoning-Benchmarks.
- Hervorragend für On-Device-RAG mit 32K–128K Kontext.
- Niedrigste API-Kosten im Top-Tier-Leistungsbereich.
Schwächen
- Beginnt bei mehrstufigen Agenten-Aufgaben, die >5 Tool-Aufrufe erfordern, Schwierigkeiten zu haben.
- Die Qualität des kreativen Schreibens liegt merklich unter der von 32B+-Modellen.
- Weniger zukunftssicher, da die Benchmarks weiter steigen.
Wann es verwendet werden sollte
- On-Device-Assistenten (Android/iOS-Apps, Wearables).
- Datenschutzsensible Bereitstellungen (Gesundheitswesen, Finanzen), bei denen Daten das Gerät nicht verlassen dürfen.
- Echtzeit-Eingebettete Systeme (Roboter, Autos, IoT-Gateways).
5. Qwen3-8B – Das ultimative Prototyping- und Leichtgewichts-Arbeitstier
Als Abschluss der Top Fünf bietet Qwen3-8B 8 Milliarden Parameter für schnelle Iterationen und übertrifft Qwen2.5-14B bei 15 Benchmarks. Es erreicht 81,5 auf AIME25 (nicht-denkend) und 60,2 auf LiveCodeBench, ausreichend für grundlegende Code-Reviews. Mit 32K nativem Kontext wird es über Ollama auf Laptops bereitgestellt und erreicht 25 Token/Sekunde.
Diese Variante eignet sich für Anfänger, die mehrsprachigen Chat oder einfache Agenten testen. Ihr Denkmodus verbessert logische Rätsel und erreicht 75 % bei Deduktionsaufgaben. Dadurch beschleunigt es Proof-of-Concepts, bevor auf größere Geschwister skaliert wird.
Stärken
- Läuft mit >25 Token/Sekunde auch auf Laptops mit 8–12 GB VRAM (MacBook M3 Pro, RTX 4070 mobil).
- Überraschend kompetente Instruktionsbefolgung – übertrifft Gemma-2-27B und Phi-4-14B auf den meisten 2026er Bestenlisten.
- Perfekt für lokale Ollama- oder LM Studio-Experimente.
- Günstigste API-Preise in der Familie.
Schwächen
- Deutliche Reasoning-Grenze bei Mathematik auf Graduiertenniveau und fortgeschrittenen Codierungsproblemen.
- Anfälliger für Halluzinationen bei wissensintensiven Aufgaben.
- Begrenzter Kontext (32K nativ, 128K mit YaRN, aber langsamer).
Wann es verwendet werden sollte
- Schnelles Prototyping und MVP-Erstellung.
- Bildungstools, persönliche Assistenten oder Hobbyprojekte.
- Frontend-Routing-Schicht in Hybridsystemen (8B zur Triage verwenden, bei Bedarf auf 30B/235B eskalieren).
API-Preise und Bereitstellungsüberlegungen für Qwen 3 Modelle
Der Zugriff auf Qwen 3 über APIs demokratisiert fortschrittliche KI, wobei Alibaba Cloud mit wettbewerbsfähigen Tarifen führend ist. Preisstaffelungen nach Token: Für Qwen3-235B-A22B kosten Eingaben $0,20–$1,20/Million (Bereich 0–252K), Ausgaben $1,00–$6,00/Million. Qwen3-30B-A3B spiegelt dies zu 80 % des Tarifs wider, während dichte Modelle wie Qwen3-32B auf $0,15 Eingabe/$0,75 Ausgabe fallen.
Drittanbieter wie Together AI bieten Qwen3-32B zu $0,80/1M Gesamttoken an, mit Mengenrabatten. Cache-Treffer reduzieren die Kosten: implizit um 20 %, explizit um 10 %. Im Vergleich zu GPT-5 ($3–15/1M) unterbietet Qwen 3 um 70 %, was eine kostengünstige Skalierung ermöglicht.
Bereitstellungstipps: Verwenden Sie vLLM für Batching, SGLang für OpenAI-Kompatibilität. Apidog verbessert dies durch das Mocken von Qwen-Endpunkten, das Testen von Payloads und das Generieren von Dokumentationen – entscheidend für CI/CD-Pipelines. Lokale Ausführungen über Ollama eignen sich für Prototyping, aber APIs sind hervorragend für die Produktion.
Sicherheitsfunktionen wie Ratenbegrenzung und Moderation schaffen Mehrwert, ohne zusätzliche Gebühren. Daher wählen budgetbewusste Teams basierend auf dem Token-Volumen: kleine Varianten für die Entwicklung, Flaggschiffe für die Inferenz.
Entscheidungstabelle – Wählen Sie Ihr Qwen 3 Modell im Jahr 2026
| Rang | Modell | Parameter (Gesamt/Aktiv) | Zusammenfassung der Stärken | Hauptschwächen | Am besten geeignet für | Ca. API-Kosten (Eingabe/Ausgabe pro 1M Token) | Min. VRAM (quantisiert) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Maximale Schlussfolgerung, Agenten-Fähigkeit, Mathematik, Code | Extrem teuer & aufwendig | Spitzenforschung, Unternehmensagenten, Null-Toleranz-Genauigkeit | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (cloud) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Bestes Preis-Leistungs-Verhältnis, starke Schlussfolgerung | Benötigt immer noch Server-GPU | Produktions-Code-Agenten, Mathematik-/Wissenschafts-Backends, Hochvolumen-Inferenz | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | Kreatives Schreiben, einfaches Fine-Tuning, Geschwindigkeit | Bleibt hinter MoE bei den schwierigsten Aufgaben zurück | Content-Plattformen, Domänen-Fine-Tuning, mehrsprachige Chatbots | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | Edge/Mobilfähig, großartiges On-Device-RAG | Begrenzte mehrstufige Agenten-Fähigkeit | On-Device-KI, datenschutzkritische Apps, eingebettete Systeme | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | Laptop-/Telefon-Geschwindigkeit, am günstigsten | Deutliche Obergrenze bei komplexen Aufgaben | Prototyping, persönliche Assistenten, Routing-Schicht in Hybridsystemen | $0.10 / $0.50 | 4–8GB |
Endgültige Empfehlung für 2026
Die meisten Teams sollten im Jahr 2026 standardmäßig Qwen3-30B-A3B verwenden – es liefert 90 %+ der Leistung des Flaggschiffs zu einem Bruchteil der Kosten und Hardware-Anforderungen. Steigen Sie nur auf 235B-A22B um, wenn Sie die letzten 5–10 % der Reasoning-Qualität wirklich benötigen und das Budget dafür haben. Wechseln Sie zum 32B dichten Modell für kreative oder stark Fine-Tuning-lastige Workloads und verwenden Sie 14B/8B, wenn Latenz, Datenschutz oder Geräteeinschränkungen dominieren.
Welche Variante Sie auch wählen, Apidog wird Ihnen Stunden beim API-Debugging ersparen. Laden Sie es noch heute kostenlos herunter und beginnen Sie selbstbewusst mit Qwen 3 zu entwickeln.