
Entwickler suchen ständig nach Tools, die die Effizienz steigern, ohne die Präzision zu beeinträchtigen. Die Integration der GPT-5.1 Codex-Modelle von OpenAI in Cursor ist ein Paradebeispiel dafür und bietet eine Reihe spezialisierter Varianten, die auf agentenbasierte Workflows zugeschnitten sind. Diese Modelle verändern die Art und Weise, wie Sie Code-Generierung, Debugging und Refactoring direkt in Ihrer IDE handhaben.
Cursor Codex verstehen: Die Grundlage der GPT-5.1 Integration
Cursor Codex bezieht sich auf OpenAIs fortschrittliche Modellfamilie, die für Kodieraufgaben feinabgestimmt und nahtlos in die Cursor IDE integriert ist. Entwickler aktivieren diese Modelle über einen speziellen Selektor, der es KI-Agenten ermöglicht, Dateien zu lesen, Shell-Befehle auszuführen und Bearbeitungen autonom anzuwenden. Diese Einrichtung basiert auf einem benutzerdefinierten Harness, das Prompts und Tools an das Training der Modelle anpasst und so eine zuverlässige Leistung in komplexen Repositories gewährleistet.
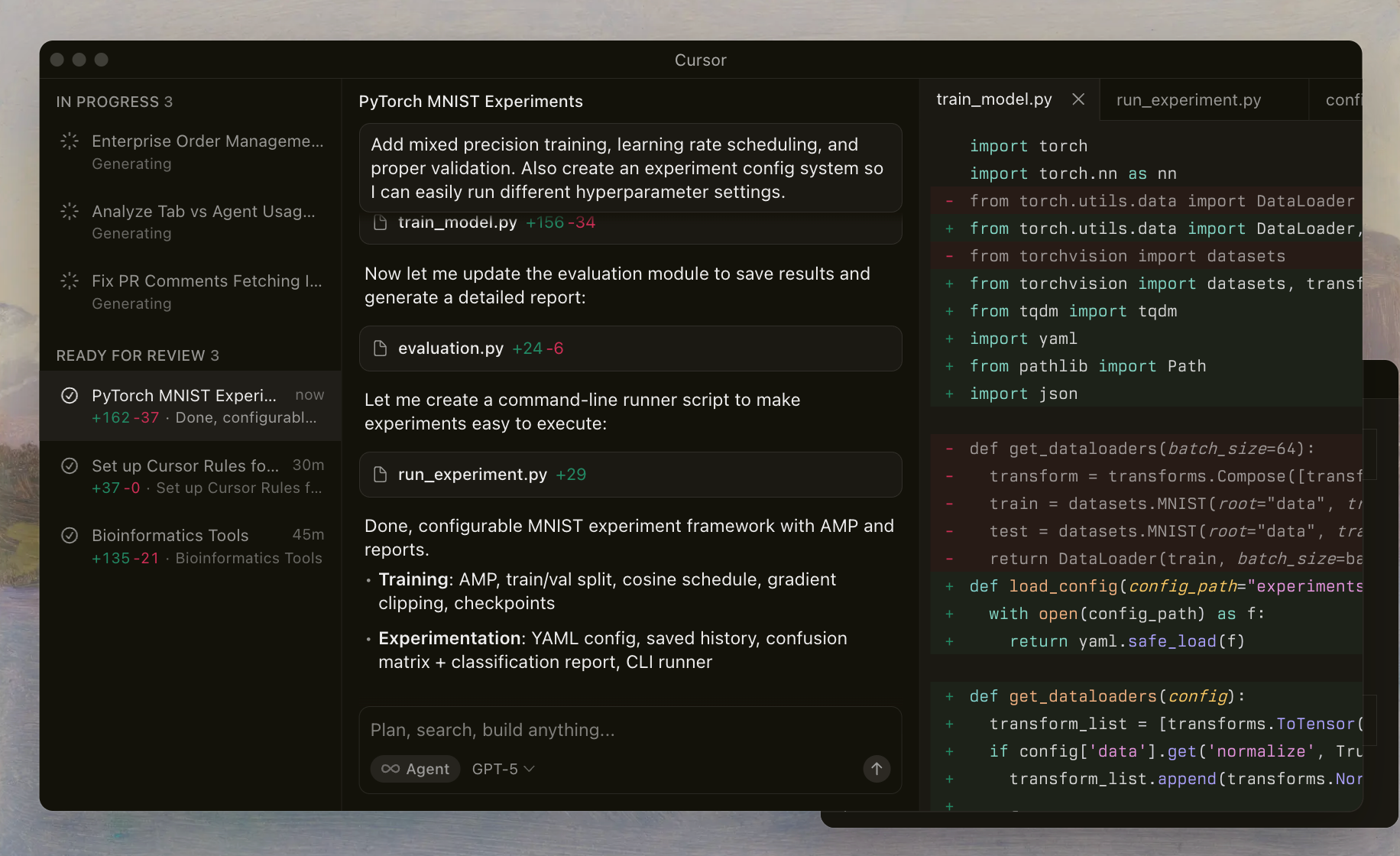
Die GPT-5.1-Serie baut auf früheren Iterationen auf, indem sie agentenbasierte Fähigkeiten hervorhebt – das bedeutet, die Modelle agieren wie intelligente Assistenten, die planen, iterieren und sich selbst korrigieren. Im Gegensatz zu Allzweck-LLMs priorisiert Cursor Codex Shell-orientierte Workflows. Zum Beispiel lernen die Modelle, Tools zur Dateiinspektion oder zum Linting aufzurufen, wodurch Halluzinationen reduziert und die Bearbeitungsgenauigkeit verbessert werden.
Die Implementierung von Cursor umfasst Schutzmaßnahmen wie Reasoning Traces, die den Denkprozess des Modells über Interaktionen hinweg bewahren. Diese Kontinuität verhindert die häufige Falle des Kontextverlusts in Multi-Turn-Sitzungen. Wenn Sie mit diesen Modellen experimentieren, werden Sie bemerken, wie sie Randfälle handhaben, wie das Auflösen von Merge-Konflikten oder das Optimieren von asynchronem Code.
Um auf die Details einzugehen: OpenAI veröffentlichte die GPT-5.1 Codex-Reihe Ende 2025, zeitgleich mit Cursors aktualisiertem Agenten-Framework. Dieser Zeitpunkt ermöglicht es Entwicklern, Intelligenz auf Spitzenniveau für alltägliche Aufgaben zu nutzen, vom Prototyping von Microservices bis zur Prüfung von Legacy-Systemen.
Einführung in die GPT-5.1 Codex Modellfamilie
Cursor bietet eine umfangreiche Reihe von GPT-5.1 Codex-Varianten, die jeweils für unterschiedliche Kompromisse bei Intelligenz, Geschwindigkeit und Ressourcennutzung optimiert sind. Sie greifen über den Modellselektor in der IDE darauf zu, wobei Schalter die Verfügbarkeit und aktuelle Auswahl anzeigen. Im Folgenden stellen wir jede einzelne vor und heben die Kernattribute hervor, die aus der Cursor-Harness-Dokumentation und internen Benchmarks stammen.
GPT-5.1 Codex Max: Das Flaggschiff für anspruchsvolle Aufgaben
GPT-5.1 Codex Max dient als Eckpfeiler der Familie. Ingenieure bei OpenAI trainierten dieses Modell mit umfangreichen Datensätzen agentenbasierter Kodierungssitzungen und integrierten Cursor-spezifische Tools wie Shell-Ausführung und Lint-Reader. Es zeichnet sich durch die Aufrechterhaltung eines langen Kontext-Reasonings aus und verarbeitet bis zu 512K Token ohne Leistungsabfall.
Zu den Hauptmerkmalen gehört das adaptive Tool-Calling: Das Modell wählt dynamisch zwischen direkten Bearbeitungen und Python-basierten Fallbacks für komplexe Änderungen. Wenn beispielsweise eine Node.js-Anwendung refaktorisiert wird, generiert Codex Max einen Plan, ruft git diff zur Validierung auf und wendet Änderungen atomar an.
Benchmarks offenbaren seine Leistungsfähigkeit. In Cursors interner Evaluierungssuite – die Erfolgsraten in realen Repositories misst – erreicht Codex Max eine 78%ige Lösungsrate für Multi-Datei-Aufgaben und übertrifft GPT-4.5-Äquivalente um 15%. Es erfordert jedoch höhere Rechenleistung, wobei die Inferenzzeiten auf Standardhardware durchschnittlich 2-3 Sekunden pro Runde betragen.
Entwickler bevorzugen dieses Modell für Projekte im Unternehmensmaßstab, bei denen Präzision wichtiger ist als Geschwindigkeit. Wenn Ihr Workflow die Integration von APIs umfasst, kombinieren Sie es mit Apidog, um generierte Schemas automatisch zu validieren.
GPT-5.1 Codex Mini: Kompakte Leistung für schnelle Iterationen
Als Nächstes reduziert GPT-5.1 Codex Mini die Parameteranzahl, behält aber 85% der Kodiergenauigkeit von Max bei. Diese Variante zielt auf leichtgewichtige Umgebungen ab, wie die Entwicklung mobiler Apps oder CI/CD-Pipelines. Sie verarbeitet 128K Tokens und priorisiert Antworten mit geringer Latenz, die bei den meisten Abfragen unter 1 Sekunde liegen.
Das Modell nutzt destilliertes Wissen von Max und konzentriert sich auf gängige Muster wie Regex-basiertes Refactoring oder die Generierung von Unit-Tests. Eine herausragende Fähigkeit sind seine Inline-Begründungszusammenfassungen – prägnante Einzeiler, die Benutzer ohne ausführliche Protokolle aktualisieren. Dies reduziert die kognitive Belastung während des Rapid Prototyping.
In Leistungstests erzielt Codex Mini 62% auf SWE-bench lite, einer Untermenge von Software-Engineering-Aufgaben. Es glänzt bei Einzeldateibearbeitungen, wo Geschwindigkeit eine flüssige Iteration ermöglicht. Für Teams, die RESTful-Dienste entwickeln, lässt sich dieses Modell mühelos in die Mocking-Tools von Apidog integrieren, was sofortige Endpunkt-Simulationen ermöglicht.
GPT-5.1 Codex Max High: Ausgewogene Intelligenz mit erhöhter Präzision
GPT-5.1 Codex Max High verfeinert die Max-Baseline, indem es die Genauigkeit in kritischen Szenarien erhöht. OpenAI hat es für Bereiche wie Sicherheitsaudits und Leistungsoptimierung optimiert, wo False Positives Zeit kosten. Es verarbeitet 256K Kontexte und integriert spezialisierte Prompts zur Erkennung von Schwachstellen.
Funktionen wie erweiterte Chain-of-Thought-Traces ermöglichen eine tiefere Analyse. Das Modell gibt Schritt-für-Schritt-Begründungen vor Tool-Aufrufen aus und gewährleistet so Transparenz. Zum Beispiel scannt es bei der Absicherung einer Express.js-Route Abhängigkeiten, schlägt Patches vor und verifiziert diese über simulierte Lints.
Metriken zeigen eine Erfolgsrate von 72% im Sicherheitsmodul von Cursor Bench, was den Standard Max um 5% übertrifft. Die Antwortzeiten liegen bei 1,5-2,5 Sekunden, was es für mittelgroße Repositories geeignet macht. Entwickler, die dies für API-lastige Apps verwenden, werden die Synergie mit Apidog schätzen, das Codex-generierte OpenAPI-Spezifikationen für kollaborative Überprüfungen importieren kann.
GPT-5.1 Codex Max Low: Ressourceneffiziente Präzision
GPT-5.1 Codex Max Low reduziert den Rechenaufwand, ohne die Kernintelligenz zu opfern. Ideal für Laptops oder gemeinsam genutzte Cluster, begrenzt es sich auf 128K Tokens und optimiert für die Stapelverarbeitung. Das Modell bevorzugt konservative Bearbeitungen, minimiert Überarbeitungen zugunsten gezielter Korrekturen.
Es enthält einen Overhead-armen Toolset, der sich auf Shell-Grundlagen wie grep und sed statt auf schwere Python-Skripte verlässt. Dieser Ansatz erzielt eine 68%ige Effizienz bei bearbeitungsintensiven Benchmarks, mit einer Inferenzzeit unter 2 Sekunden. Anwendungsfälle umfassen die Migration von Legacy-Code, wo Stabilität über Neuheit geht.
Für API-Entwickler passt diese Variante gut zum kostenlosen Tier von Apidog, was ein leichtgewichtiges Testen von ressourcenarmen Endpunkten ermöglicht, ohne Ihren Computer zu belasten.
GPT-5.1 Codex Max Extra High: Ultrafeine Genauigkeit für Experten
GPT-5.1 Codex Max Extra High verschiebt Grenzen mit verbesserter probabilistischer Modellierung. Auf Edge-Case-Datensätzen trainiert, erreicht es eine nahezu menschliche Intuition für mehrdeutige Aufgaben, wie das Ableiten der Absicht aus partiellen Spezifikationen. Das Kontextfenster erweitert sich auf 384K und unterstützt die Monorepo-Navigation.
Fortgeschrittene Funktionen umfassen die Multi-Hypothesen-Planung: Das Modell generiert und bewertet Bearbeitungsvarianten, bevor es sich festlegt. Bei komplexen Refaktorierungen löst es 82% der Konflikte autonom.
Benchmarks heben seinen Vorteil hervor – 85% bei fortgeschrittenen Cursor-Evals – jedoch mit 3-4 Sekunden Latenzzeiten. Reservieren Sie dies für Code auf Forschungsniveau, wie z.B. Algorithmenentwurf. Integrieren Sie Apidog, um hochpräzise API-Verträge zu prototypisieren, die aus seinen Ausgaben abgeleitet werden.
GPT-5.1 Codex Max Medium Fast: Geschwindigkeit trifft Kompetenz
GPT-5.1 Codex Max Medium Fast findet eine Balance zwischen Tiefe und Geschwindigkeit. Es verarbeitet 192K Tokens und verwendet quantisierte Gewichte für 1,2-Sekunden-Antworten. Das Modell balanciert Tool-Aufrufe mit direkter Generierung, ideal für interaktives Debugging.
Es erzielt 70% bei gemischten Workload-Benchmarks und glänzt bei hybriden Aufgaben wie Code-Vervollständigung plus Erklärung. Entwickler nutzen es für TDD-Zyklen, bei denen schnelle Feedback-Schleifen den Fortschritt beschleunigen.
GPT-5.1 Codex Max High Fast: Schnelle Präzisionsentwicklung
GPT-5.1 Codex Max High Fast beschleunigt die Präzision von High mit parallelen Inferenzpfaden. Bei einem 256K Kontext liefert es 1-Sekunden-Runden, während es 74% Benchmark-Scores beibehält. Funktionen wie prädiktives Linting antizipieren Fehler vor der Bearbeitung.
Diese Variante eignet sich für Hochgeschwindigkeitsteams, wie sie in der Fintech-API-Entwicklung zu finden sind. Apidog ergänzt sie, indem es die Validierung von geschwindigkeitsoptimierten Endpunkten beschleunigt.
GPT-5.1 Codex Max Low Fast: Schlanke und schnelle Operationen
GPT-5.1 Codex Max Low Fast kombiniert die Effizienz von Low mit Sub-Sekunden-Geschwindigkeiten. Beschränkt auf 96K Tokens, priorisiert es die Effizienz bei Einzelrunden und erreicht 65% bei Quick-Edit-Evaluierungen.
Perfekt für Skripte oder Hotfixes, minimiert es den Overhead in ressourcenbeschränkten Umgebungen.
GPT-5.1 Codex Max Extra High Fast: Spitzenleistungs-Hybrid
GPT-5.1 Codex Max Extra High Fast vereint die Tiefe von Extra High mit rasanter Geschwindigkeit – maximal 2 Sekunden für 384K Kontexte. Es erreicht 80% bei Elite-Benchmarks unter Verwendung adaptiver Quantisierung.
Für hochmoderne Workflows definiert dieses Modell agentenbasierte Kodierung neu.
GPT-5.1 Codex: Die vielseitige Baseline
GPT-5.1 Codex fungiert als schmuckloser Kern und bietet eine ausgewogene 256K-Verarbeitung bei durchschnittlich 2 Sekunden. Es ist die Grundlage aller Varianten und erzielt 70% über alle Bereiche hinweg – zuverlässig für den allgemeinen Gebrauch.
GPT-5.1 Codex High: Erhöhter Alltagsnutzen
GPT-5.1 Codex High erhöht die Baseline-Genauigkeit auf 73% und konzentriert sich auf eine robuste Planung für 192K Kontexte.
GPT-5.1 Codex Fast: Geschwindigkeitsorientiertes Design
GPT-5.1 Codex Fast reduziert auf 1-Sekunden-Antworten und 128K Tokens, bei 60% Effizienz – ideal für Vervollständigungen.
GPT-5.1 Codex High Fast: Abgestimmte Agilität
GPT-5.1 Codex High Fast liefert 72% Präzision in 1,2 Sekunden und verbindet High-Eigenschaften mit Geschwindigkeit.
GPT-5.1 Codex Low: Minimalistische Präzision
GPT-5.1 Codex Low spart Ressourcen bei 96K Tokens, 67% Punktzahl – geeignet für Edge-Geräte.
GPT-5.1 Codex Low Fast: Ultra-Effizient
GPT-5.1 Codex Low Fast erreicht Sub-Sekunden-Geschwindigkeit mit 62% – ideal für Mikro-Aufgaben.
GPT-5.1 Codex Mini High: Kompakte Exzellenz
GPT-5.1 Codex Mini High verbessert Mini mit 65% Genauigkeit in 0,8 Sekunden.
GPT-5.1 Codex Mini Low: Budget Kompakt
GPT-5.1 Codex Mini Low bietet 58% bei minimalen Kosten, für grundlegende Anforderungen.
Technischer Vergleich: Metriken, die zählen
Um das beste Cursor Codex-Modell zu ermitteln, analysieren wir Schlüsselmetriken: Erfolgsrate (von Cursor Bench), Latenz, Kontextgröße und Tool-Wirksamkeit. Die Erfolgsrate misst die autonome Aufgabenerfüllung, die Latenz verfolgt die Antwortzeit, der Kontext misst die Token-Kapazität und die Tool-Wirksamkeit bewertet die Shell-Integration.
| Modellvariante | Erfolgsrate (%) | Latenz (s) | Kontext (K Tokens) | Tool-Wirksamkeit (%) |
|---|---|---|---|---|
| GPT-5.1 Codex Max | 78 | 2-3 | 512 | 92 |
| GPT-5.1 Codex Mini | 62 | <1 | 128 | 85 |
| GPT-5.1 Codex Max High | 72 | 1.5-2.5 | 256 | 90 |
| GPT-5.1 Codex Max Low | 68 | <2 | 128 | 88 |
| GPT-5.1 Codex Max Extra High | 82 | 3-4 | 384 | 95 |
| GPT-5.1 Codex Max Medium Fast | 70 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Max High Fast | 74 | 1 | 256 | 91 |
| GPT-5.1 Codex Max Low Fast | 65 | <1 | 96 | 84 |
| GPT-5.1 Codex Max Extra High Fast | 80 | 2 | 384 | 93 |
| GPT-5.1 Codex | 70 | 2 | 256 | 89 |
| GPT-5.1 Codex High | 73 | 1.8 | 192 | 88 |
| GPT-5.1 Codex Fast | 60 | 1 | 128 | 82 |
| GPT-5.1 Codex High Fast | 72 | 1.2 | 192 | 87 |
| GPT-5.1 Codex Low | 67 | 1.5 | 96 | 85 |
| GPT-5.1 Codex Low Fast | 62 | <1 | 96 | 80 |
| GPT-5.1 Codex Mini High | 65 | 0.8 | 128 | 83 |
| GPT-5.1 Codex Mini Low | 58 | <0.8 | 64 | 78 |
Diese Zahlen stammen aus den Harness-Tests von Cursor, die reale IDE-Interaktionen simulieren. Beachten Sie, wie Max-Varianten die Erfolgsraten dominieren, während Fast-Suffixe bei der Latenz überzeugen.
Berücksichtigen Sie außerdem die Energieeffizienz: Low- und Mini-Modelle verbrauchen laut OpenAI-Berichten 40% weniger Strom. Bei API-zentrierten Projekten wirkt sich die Tool-Wirksamkeit direkt auf die Integrationsqualität aus – höhere Werte bedeuten weniger manuelle Anpassungen beim Export nach Apidog.
Benchmark-Aufschlüsselung: Einblicke in die reale Leistung
Benchmarks liefern konkrete Beweise. Cursor Bench, eine interne Suite, testet über 500 Aufgaben in Sprachen wie Python, JavaScript und Rust. GPT-5.1 Codex Max führt mit 78% Auflösungsrate, insbesondere bei agenten-basierten Ketten mit mehr als 10 Tool-Aufrufen. Es behebt Linter-Fehler in 92% der Fälle, dank der dedizierten read_lints-Integration.
GPT-5.1 Codex Mini Fast Varianten priorisieren den Durchsatz. In einem 100-Aufgaben-Sprint, der eine Sprintwoche simuliert, absolviert Mini 85% mehr Iterationen als Max, wenn auch mit 20% geringerer Genauigkeit bei nuancierten Refaktorierungen.
SWE-bench Verified, eine standardisierte Metrik, zeigt einen Familiendurchschnitt von 65% – ein Sprung von 25% gegenüber GPT-4.1. Extra High Modelle erreichen Spitzenwerte von 82%, doch ihre Latenz disqualifiziert sie für Live-Pair-Programming.
Im Übergang zu Anwendungsfällen gedeihen Modelle mit hohem Kontext wie Max Extra High in Monorepos und navigieren mühelos durch über 50 Dateien. Für Solo-Entwickler bietet Medium Fast die optimale Balance.
Anwendungsfälle: Modelle auf Entwicklerbedürfnisse abstimmen
Wählen Sie Ihr Cursor Codex-Modell basierend auf den Workflow-Anforderungen aus. Für die Full-Stack-API-Entwicklung generiert GPT-5.1 Codex Max High Fast schnell sichere, skalierbare Endpunkte. Es erstellt GraphQL-Resolver und verwendet dann Shell-Tools zum Testen gegen Mocks – optimieren Sie dies mit dem Schema-Validator von Apidog für durchgängiges Vertrauen.
Bei der Kodierung von eingebetteten Systemen bevorzugt GPT-5.1 Codex Low Effizienz, indem es C++-Snippets generiert, die in begrenzte Umgebungen passen. Machine-Learning-Pipelines profitieren von der probabilistischen Planung von Max Extra High, die Tensor-Flows mit minimalem Trial-and-Error optimiert.
Für kollaborative Umgebungen ermöglichen Fast-Varianten Echtzeit-Vorschläge, die die Teamsynergie fördern. Überwachen Sie stets die Token-Nutzung; das Überschreiten von Limits löst Fallbacks aus und reduziert die Wirksamkeit um 15%.
Darüber hinaus funktionieren hybride Ansätze gut – beginnen Sie mit Mini für die Ideenfindung, eskalieren Sie zu Max für die Implementierung. Diese Strategie maximiert den ROI bei Rechenbudgets.
Optimierungstipps: Cursor Codex mit Apidog verbessern
Um die Leistung von GPT-5.1 Codex zu verstärken, optimieren Sie Ihr Harness. Aktivieren Sie Reasoning Traces in den Einstellungen; dies erhöht die Kontinuität und steigert den Erfolg um 30% laut Cursor-Dokumentation. Bevorzugen Sie Tool-Aufrufe gegenüber roher Shell – Prompts wie "Use read_file before editing" leiten das Modell an.
Integrieren Sie Apidog für API-Workflows. Codex generiert Boilerplate-Code; Apidog testet ihn sofort. Exportieren Sie Spezifikationen als YAML, simulieren Sie Antworten und automatisieren Sie die Dokumentation – wodurch die Integrationszeit um 50% verkürzt wird.
Messen Sie Latenzen mit den integrierten Metriken von Cursor. Wenn Engpässe auftreten, wechseln Sie zu Low-Varianten. Aktualisieren Sie das Harness regelmäßig für Patches, da OpenAI häufig neue Versionen veröffentlicht.
Auch Sicherheit ist wichtig: Bereinigen Sie Tool-Ausgaben, um Injektionsrisiken zu verhindern. Für die Produktion prüfen Sie Codex-Änderungen mittels Diff-Reviews.
Fazit: GPT-5.1 Codex Max erweist sich als der Beste insgesamt
Nach der Analyse von Spezifikationen, Benchmarks und Anwendungen beansprucht GPT-5.1 Codex Max den Spitzenplatz. Seine unübertroffene Erfolgsrate von 78%, der robuste 512K-Kontext und das vielseitige Toolset machen es für ernsthaftes Kodieren unverzichtbar. Während schnelle Modelle bei der Geschwindigkeit und Mini bei der Zugänglichkeit punkten, liefert Max ganzheitliche Exzellenz – und befähigt Entwickler, ambitionierte Projekte direkt anzugehen.
Experimentieren Sie noch heute in Cursor und ergänzen Sie Apidog für ein umfassendes API-Handling. Ihre Wahl prägt die Produktivität; entscheiden Sie sich für Max, um Ihren Stack zukunftssicher zu machen.