Artificial intelligence continues to evolve rapidly, and developers now demand tools that deliver advanced reasoning capabilities. NVIDIA meets this need with the NVIDIA Llama Nemotron family of models. These models excel in tasks requiring complex reasoning, offer compute efficiency, and come with an open license for enterprise use. Developers can access these models through the NVIDIA Llama Nemotron API, provided via NVIDIA’s NIM microservices, making integration into applications seamless.
Understanding the NVIDIA Llama Nemotron Models
Before diving into the API, let’s examine the NVIDIA Llama Nemotron models. This family includes three variants: Nano, Super, and Ultra. Each targets specific deployment needs, balancing performance and resource demands.
- Nano (8B parameters): Engineers optimize this model for edge devices and PCs. It delivers high accuracy with minimal compute power, making it ideal for lightweight applications.
- Super (49B parameters): Developers design this model for single-GPU setups. It strikes a balance between throughput and accuracy, suitable for moderately complex tasks.
- Ultra (253B parameters): Experts craft this model for multi-GPU data center servers. It provides top-tier accuracy for the most demanding AI agent applications.
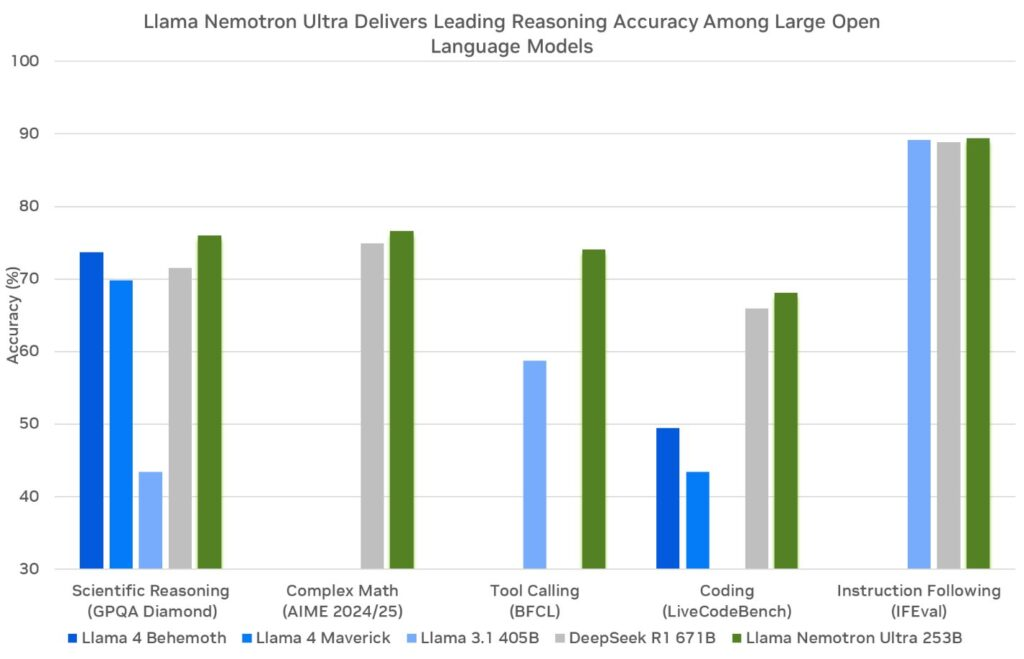
NVIDIA builds these models on Meta’s Llama framework, enhancing them with post-training techniques like distillation and reinforcement learning. Consequently, they excel in reasoning tasks such as scientific analysis, advanced mathematics, coding, and instruction following. Each model supports a context length of 128,000 tokens, enabling them to process lengthy documents or maintain context in extended interactions.
A standout feature is the ability to toggle reasoning on or off via the system prompt. Developers activate reasoning for complex queries, like troubleshooting, and disable it for simple tasks, like retrieving static information. This flexibility optimizes resource usage, a critical advantage in real-world applications.
Setting Up the NVIDIA Llama Nemotron API
To harness the NVIDIA Llama Nemotron API, you must first set it up. NVIDIA delivers this API through its NIM microservices, which support deployment across cloud, on-premises, or edge environments. Follow these steps to get started:
Join the NVIDIA Developer Program: Register to access resources, documentation, and tools. This step unlocks the ecosystem you need.
Obtain API Credentials: NVIDIA provides API keys. Use these to authenticate your requests securely.
Install Required Libraries: For Python developers, install the requests library to handle HTTP calls. Run this command in your terminal:
pip install requests
With these steps completed, you prepare your environment to interact with the NVIDIA Llama Nemotron API. Next, we’ll explore how to make requests.
Making API Requests
The NVIDIA Llama Nemotron API adheres to RESTful standards, simplifying integration into your projects. You send POST requests to the API endpoint, embedding parameters in the request body. Let’s break this down with a practical example.
Here’s how you query the API using Python:
import requests
import json
# Define the API endpoint and authentication
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Create the request payload
payload = {
"model": "llama-nemotron-super",
"prompt": "How many R's are in the word 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Send the request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Process the response
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Error: {response.status_code} - {response.text}")
Key Parameters Explained
model: Specifies the model variant—Nano, Super, or Ultra. Select based on your deployment.prompt: Provides the input text for the model to process.max_tokens: Limits the response length in tokens. Adjust this to control output size.temperature: Ranges from 0 to 1. Lower values (e.g., 0.5) yield predictable outputs, while higher values (e.g., 0.9) increase creativity.reasoning: Toggles reasoning capabilities. Set to "on" for complex tasks, "off" for simple ones.
For instance, enabling reasoning suits tasks like solving math problems, while disabling it works for basic lookups. You can also add parameters like top_p for diversity control or stop_sequences to halt generation at specific tokens, such as "\n\n".
Here’s an extended example:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explain recursion in programming.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
This request generates a detailed explanation of recursion, stopping at a double newline. Tools like Apidog help you test and refine these requests efficiently.
Handling API Responses
After sending a request, the NVIDIA Llama Nemotron API returns a JSON response. This includes the generated text and metadata. Here’s a sample response:
{
"text": "There are three R's in the word 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Contains the model’s output.tokens_generated: Indicates the number of tokens produced.time_taken: Measures the generation time in seconds.
Always verify the status code. A 200 code signals success, allowing you to parse the JSON. Errors return codes like 400 or 500, with details in the response body for debugging. Implement error handling, such as retries or fallbacks, to ensure robustness in production.
For example, extend the earlier code:
if response.status_code == 200:
result = response.json()
print(f"Response: {result['text']}")
print(f"Tokens used: {result['tokens_generated']}")
else:
print(f"Failed: {response.text}")
# Add retry logic here if needed
This approach keeps your application reliable under varying conditions.
Best Practices and Use Cases
To maximize the NVIDIA Llama Nemotron API’s potential, adopt these best practices:
- Optimize Resource Usage: Activate reasoning only for complex tasks. This reduces compute costs significantly.
- Monitor Performance: Track
time_takento ensure timely responses, especially for real-time applications. - Tune Parameters: Experiment with
temperatureandmax_tokensto balance creativity and precision. - Secure Credentials: Store API keys in environment variables or secure vaults, never in code.
- Batch Requests: Process multiple prompts in one call to enhance efficiency.
Practical Use Cases
The API’s versatility supports diverse applications:
- Customer Support: Develop chatbots that resolve intricate queries with reasoning, like troubleshooting hardware issues.
- Education: Build tutors that explain concepts, such as calculus, with step-by-step logic.
- Research: Assist scientists in analyzing data or drafting hypotheses.
- Software Development: Generate code or debug scripts based on natural language inputs.
For a coding example:
payload = {
"model": "llama-nemotron-super",
"prompt": "Write a Python function to calculate a factorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
The model might return:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
This demonstrates its ability to reason through recursive logic. Apidog can assist in testing such API calls, ensuring accuracy.
Conclusion
The NVIDIA Llama Nemotron API empowers developers to create advanced AI agents with robust reasoning capabilities. Its toggleable reasoning feature optimizes performance, while its scalability across Nano, Super, and Ultra models suits diverse needs. Whether you build chatbots, educational tools, or coding assistants, this API delivers flexibility and power.
Moreover, integrating it with tools like Apidog enhances your workflow. Test endpoints, validate responses, and iterate quickly to focus on innovation. As AI advances, mastering the NVIDIA Llama Nemotron API positions you at the forefront of this transformative field.