Voice cloning technology represents one of the most significant advancements in modern application development. Developers now possess the capability to integrate hyper-realistic, emotionally expressive synthetic voices into their applications without requiring months of audio recording sessions. This transformation becomes possible through sophisticated voice clone APIs that leverage advanced machine learning algorithms and neural networks.
The convergence of TTS APIs (Text-to-Speech) with STT APIs (Speech-to-Text) creates a comprehensive ecosystem for voice-enabled applications. Whether you're building customer service chatbots, creating audiobook narration systems, or developing interactive gaming experiences, selecting the right API platform determines your success metrics.
Understanding Voice Clone Technology Fundamentals
Voice cloning operates on a straightforward yet powerful principle: machine learning models analyze audio samples to extract unique vocal characteristics, then reproduce those characteristics through synthetic speech generation. The process requires understanding several core components that distinguish premium voice clone APIs from basic solutions.
Modern voice cloning systems function across three primary operational layers. First, they capture voice samples containing specific tonal qualities, accent patterns, and emotional undertones. Subsequently, advanced neural networks process this data to identify and isolate the distinctive voice features. Finally, the trained model generates new speech while preserving all original voice characteristics, including pronunciation patterns, speaking pace, and emotional depth.
1. ElevenLabs: The Industry Standard for English Voice Quality
ElevenLabs occupies the dominant position in voice cloning APIs, having established itself as the gold standard for English voice synthesis quality. The platform's technical architecture enables voice cloning with minimal training data typically requiring just 30 seconds to two minutes of clear audio samples.
Key Technical Features:
- Ultra-Fast Voice Cloning: Generates voice clones within seconds of audio upload
- 300+ Prebuilt Voice Options: Provides ready-to-use voices across 30+ languages
- Emotion and Tone Control: Enables dynamic adjustment of vocal expression parameters
- API-First Design: Offers straightforward integration through REST endpoints and multiple SDK options
- WebSocket Support: Facilitates real-time streaming speech synthesis for conversational applications
ElevenLabs' voice quality delivers results so accurate that users consistently report the synthesized speech is virtually indistinguishable from natural human voices. This accuracy level has set industry benchmarks that competitors still strive to match.
Pricing Structure:
The platform operates on subscription-based and pay-as-you-go models. Basic plans commence at $5 monthly, while professional-tier subscriptions reach $99 monthly for advanced features including custom voice cloning and priority API access. Enterprise arrangements accommodate unlimited usage at custom pricing.
2. Resemble AI: Enterprise-Grade Voice Synthesis with Real-Time Capabilities
Resemble AI distinguishes itself through specialized emphasis on real-time voice conversion and commercial-grade applications. The platform processes voice cloning across an impressive 62 languages, making it particularly suited for globally distributed applications.
Distinguishing Technical Capabilities:
- Real-Time Voice Conversion: Supports live speech transformation without perceptible latency
- Emotional Expression Controls: Fine-tunes happiness, sadness, excitement, and additional emotional states
- Localization Framework: Handles language-specific voice characteristics and accent preservation
- API Endpoint Architecture: Provides low-latency endpoints optimized for streaming applications
- Custom Model Training: Enables enterprise customers to develop proprietary voice models
The platform's emphasis on emotional expression control proves particularly valuable for applications requiring nuanced vocal delivery. Customer service bots, virtual assistants, and interactive gaming characters all benefit from this granular emotional control.
Pricing Hierarchy:
Resemble AI structures pricing in tiers ranging from $5 monthly starter plans through enterprise arrangements costing $3,000 annually. Notably, the business plan beginning at $699 monthly unlocks custom voice cloning capabilities and priority API support.
3. Fish Audio: Open-Source Voice Synthesis with Advanced Control
Fish Audio represents a cutting-edge open-source approach to voice synthesis, offering developers unprecedented control over voice generation and customization. The platform excels for organizations seeking self-hosted solutions, fine-grained voice parameter control, and freedom from vendor lock-in constraints.
Platform Strengths:
- Open-Source Architecture: Provides transparent, modifiable code enabling custom implementations
- Advanced Voice Parameter Control: Offers fine-grained adjustment of pitch, speed, emotion, and acoustic characteristics
- Multiple Voice Cloning Models: Supports various cloning approaches from minimal samples to comprehensive training
- Self-Hosting Capability: Enables on-premise deployment for privacy-critical applications
- Cost-Effective Scaling: Reduces per-request costs through self-hosted infrastructure without vendor markup
Fish Audio's open-source foundation appeals particularly to developers building proprietary voice solutions or organizations with strict data residency requirements. The platform eliminates vendor dependencies while maintaining state-of-the-art voice synthesis quality.
Flexible Pricing Structure:
The open-source nature of Fish Audio allows free self-hosting with only infrastructure costs. Cloud-hosted variants offer pay-as-you-go pricing starting at minimal rates, while enterprise arrangements accommodate dedicated instances and priority support. Organizations prioritizing cost efficiency at scale find Fish Audio particularly attractive.
4. Tavus: Converging Voice with Video Synthesis
Tavus occupies a unique position by merging voice cloning with photorealistic video generation. The platform creates AI humans that speak with cloned voices while maintaining consistent facial expressions and lip synchronization.
Revolutionary Integration Features:
- Conversational Video Interface (CVI): Enables real-time face-to-face interactions with AI avatars
- Photorealistic Avatar Generation: Creates talking-head videos from script inputs
- Multilingual Support: Supports 30+ languages with automatic lip sync and dubbing
- Studio-Grade Synchronization: Delivers 24 kHz audio with perfect lip-sync accuracy
- Personalization at Scale: Generates thousands of customized videos maintaining consistent voice and appearance
This combination of voice and video synthesis proves exceptionally valuable for marketing campaigns, educational content, and customer engagement platforms. Organizations can personalize messages at scale while maintaining complete visual and vocal consistency.
Cost Considerations:
The enterprise-focused pricing model requires custom quotations. However, the platform's ability to generate thousands of personalized videos justifies investment for organizations with substantial content distribution needs.
5. Murf AI: Accessible Professional Voice Generation
Murf AI emphasizes accessibility without sacrificing professional quality. The platform attracts content creators, educators, and businesses seeking straightforward voice synthesis without prohibitive technical barriers.
Accessibility-Focused Features:
- Drag-and-Drop Interface: Simplifies voice synthesis without technical prerequisites
- 120+ Professional Voices: Provides extensive pre-built voice options
- Emotional Styles: Supports multiple vocal expressions within single projects
- Multi-Voice Narratives: Enables creation of dialogues involving multiple speakers
- Commercial Rights Included: Permits unrestricted commercial use of generated content
Murf democratizes voice synthesis by eliminating technical complexity. Content creators can focus on script writing while the platform handles voice generation automatically.
Transparent Pricing Structure:
The free plan provides approximately 10 minutes of monthly voice generation for testing. Creator plans begin at $19 monthly (annual billing) providing 2 hours of generation. Professional tiers reach $39 monthly with full voice library access and advanced features.
Comparative Analysis: Selecting Your Ideal Voice Clone API
Each platform excels in specific scenarios, and comparing their technical capabilities helps streamline selection. The following table provides a streamlined overview of how these five voice clone APIs stack against critical evaluation criteria:
| Feature | ElevenLabs | Resemble AI | Fish Audio | Tavus | Murf AI |
|---|---|---|---|---|---|
| English Voice Quality | Highest | Excellent | Excellent | Very High | Good |
| Language Support | 30+ | 62+ | 50+ | 30+ | 70+ |
| Real-Time Streaming | Yes | Yes | Yes | No | Limited |
| Voice Cloning Speed | 30 seconds | Varies | Fast | 2 minutes | No |
| Emotional Control | Good | Excellent | Excellent | Excellent | Very Good |
| Video Avatar Integration | No | No | No | Yes | No |
| Starting Price | $5/month | $5/month | Free (Self-Hosted) | Custom | Free |
| Best Use Case | English Quality | Enterprise | Developer-Focused | Video Content | Content Creators |
Strategic Selection Criteria
For Maximum English Voice Quality: ElevenLabs occupies the premium position when English voice fidelity determines application success. If your target market exclusively speaks English and voice naturalness becomes non-negotiable, ElevenLabs delivers the highest consistency and emotional authenticity compared to competing platforms.
For Real-Time Conversational Applications: Resemble AI and Fish Audio both support streaming architecture essential for conversational experiences. Applications requiring sub-100ms latency should prioritize these platforms, as their implementations eliminate perceptible delays between text input and audio output.
For Developer-Controlled Deployments: Fish Audio's open-source foundation appeals to development teams seeking complete control over voice synthesis pipelines. Self-hosted deployment eliminates vendor dependencies, reduces per-request costs at scale, and enables proprietary customizations impossible with closed-source competitors.
For Video-Centric Applications: Tavus stands alone in combining voice cloning with photorealistic avatar generation. Organizations creating personalized video campaigns, interactive educational content, or lifelike customer service avatars should evaluate Tavus exclusively, as no other platform offers comparable integrated capabilities.
For Non-Technical Teams: Murf AI's drag-and-drop interface and minimal technical requirements make it optimal for marketing teams, content creators, and organizations lacking dedicated development resources. The platform trades some advanced customization for remarkable accessibility.
For Cost-Conscious Startups: Both ElevenLabs and Resemble AI offer aggressive pricing at $5 monthly, making them accessible entry points. Fish Audio's free self-hosted option provides unlimited usage without subscription costs, though infrastructure expenses apply.
Practical Implementation with Apidog
Integrating voice clone APIs requires systematic testing and validation. Apidog streamlines this process by centralizing API testing within a single platform.
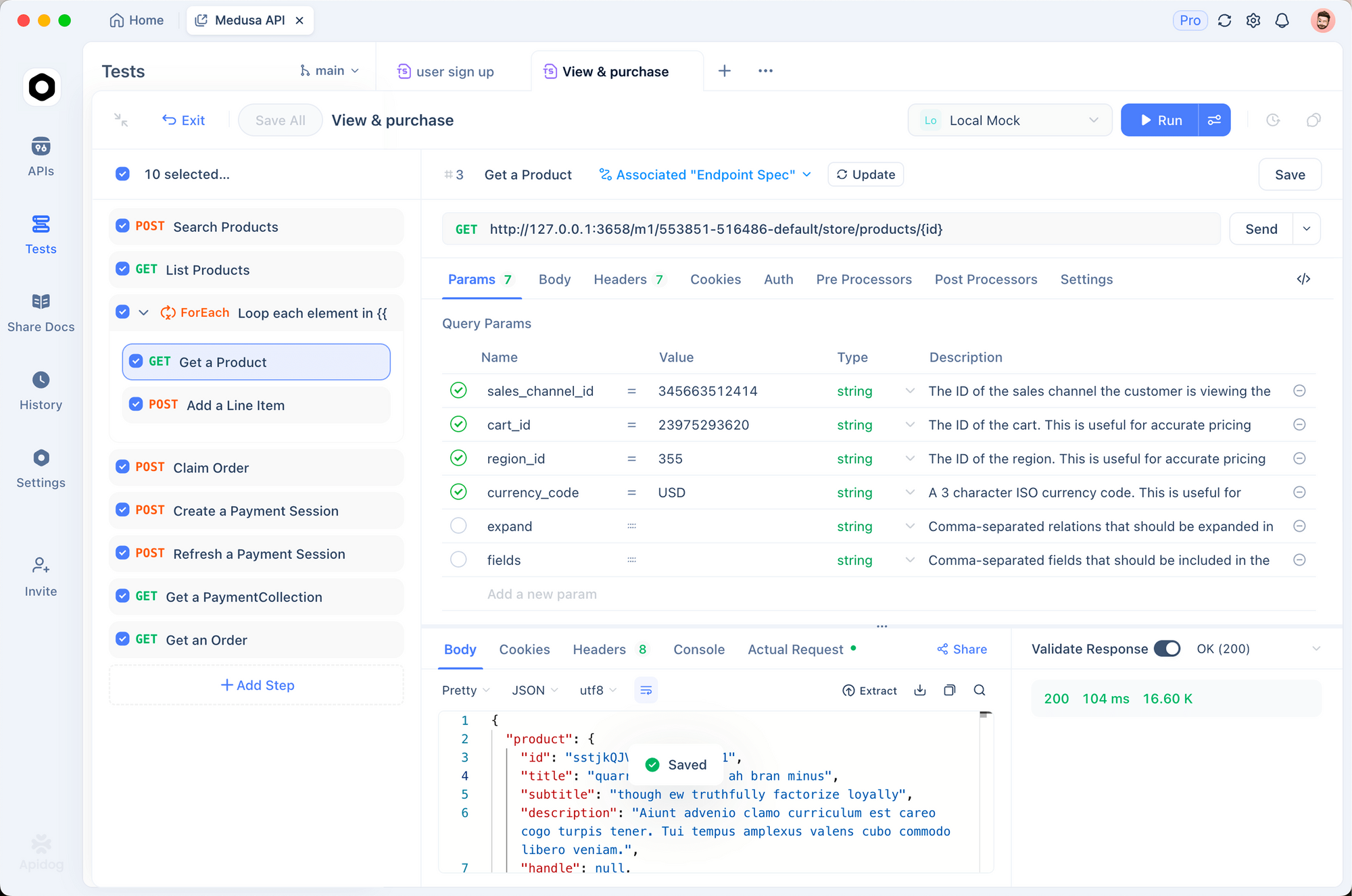
Implementation Workflow:
- API Design: Utilize Apidog's visual editor to document voice clone API endpoints alongside other integrations
- Test Scenario Creation: Build comprehensive test scenarios validating voice synthesis quality and latency parameters
- Mock Data Generation: Create realistic mock responses before deploying against production APIs
- Automated Testing: Execute continuous integration testing ensuring voice synthesis remains consistent across deployments
- Documentation Generation: Automatically generate API documentation for team collaboration
Apidog's environment management feature proves particularly valuable when testing against multiple voice clone APIs simultaneously. Switching between ElevenLabs, Resemble AI, and other platforms requires only environment selection no endpoint modifications necessary.
Conclusion: Choosing Your Voice Synthesis Future
Voice clone APIs have transitioned from experimental technology to essential development components. The five platforms detailed throughout this guide each represent different optimization priorities whether quality, accessibility, multilingual support, video integration, or specific technical requirements.
Your implementation success depends on selecting the platform aligning with your application's unique requirements. Test multiple options using platforms like Apidog to evaluate performance, latency, and voice quality across realistic scenarios.
Get Started: Download Apidog to design, test, and integrate voice clone APIs alongside your broader development ecosystem. Centralize your API testing while your voice synthesis implementation advances from prototype to production.