Converting text into natural-sounding speech and transcribing audio back into text represents one of the most transformative technologies in modern development. These capabilities power everything from accessibility features to customer service applications, making them essential tools in your development toolkit.
Whether you're building a voice-enabled chatbot, creating an audiobook platform, or adding accessibility features to your application, choosing the right TTS APIs and STT APIs can determine your project's success. The market offers numerous options, each with distinct strengths, and pricing models.
This guide examines the five most powerful speech technology providers available today. We'll analyze their capabilities, assess their real-world performance, and help you make an informed decision about which platform suits your specific needs.
Understanzing TTS APIs and STT APIs
Text-to-speech technology converts written content into audio output. This process involves linguistic analysis, prosody generation, and audio synthesis. Modern TTS APIs produce remarkably natural-sounding speech that captures emphasis, emotion, and natural pacing.
Speech-to-text technology performs the inverse function it converts audio input into written text. This involves audio processing, acoustic modeling, and language recognition. STT APIs handle various accents, background noise, and specialized vocabulary with increasing accuracy.
Together, these technologies enable bimodal communication between users and applications. They break down barriers for users with visual or hearing impairments, allow hands-free interaction, and create new engagement channels for your products.
1. Google Cloud Text-to-Speech and Speech-to-Text
Google's speech technology services stand at the forefront of the industry, leveraging extensive machine learning infrastructure and massive training datasets.
TTS Capabilities
Google Cloud Text-to-Speech produces remarkably human-like voice outputs. The platform offers 220+ voices across 40+ languages, with multiple voice styles available for many languages. You can select different voice profiles optimized for different use cases conversational, news broadcast, or storytelling styles.
STT Capabilities
Google Cloud Speech-to-Text handles real-time transcription and batch processing of audio files. The service recognizes over 125 languages and variants, adapts to domain-specific vocabulary, and filters out background noise effectively.
Pricing Structure
Google implements a straightforward pay-as-you-go model. Text-to-speech charges roughly $0.000004 per character for standard voices, with premium voices costing slightly more. Speech-to-text pricing depends on whether you process audio in real-time or batch mode, starting around $0.006 per 15 seconds of audio.
The free tier provides monthly allowances, making it suitable for testing and small-scale projects.
2. Amazon Polly and Amazon Transcribe
Amazon Web Services provides mature, enterprise-grade speech services integrated directly into the AWS ecosystem.
Polly's Voice Technology
Amazon Polly generates speech using neural network technology, delivering natural-sounding audio across 29 languages. The platform offers hundreds of voices, including specialized options for child characters and neural voices that sound particularly human.
Transcribe's Recognition Capabilities
Amazon Transcribe converts audio into text with particular strength in handling background noise and multiple speakers. The service identifies speakers within audio files, timestamps individual words, and provides confidence scores for each transcription segment.
Pricing Model
Polly pricing operates on a per-character basis, with the first 5 million characters per month free and subsequent characters costing approximately $0.000004 each. Transcribe charges for audio processing time, with pricing around $0.0001 per second of audio processed.
3. Microsoft Azure Cognitive Services
Microsoft's speech services deliver enterprise reliability combined with advanced customization options.
Text-to-Speech Features
Azure Speech Services offers over 400 voices across 140+ language variants. The platform distinguishes itself through neural voices that sound remarkably human, with support for multiple speaking styles, emotions, and prosody variations.
Speech-to-Text Capabilities
Azure's speech recognition service processes real-time and batch audio inputs with high accuracy. The platform recognizes 85+ languages, supports diarization to identify multiple speakers, and provides word-level timing information.
Pricing Strategy
Azure uses a tiered pricing structure based on processing requirements. Basic speech-to-text starts around $0.006 per audio minute, while premium options offering speaker recognition and custom models cost more. Text-to-speech pricing falls around $0.000009 per character for standard voices.
4. IBM Watson Speech Services
IBM's Watson platform brings decades of speech technology research into modern APIs suitable for enterprise deployments.
Watson Text-to-Speech
Watson offers expressive voice synthesis with careful attention to natural prosody. The platform provides voices in multiple languages with customization options for pitch, rate, and volume. Watson's strength lies in handling complex linguistic challenges and maintaining natural speech patterns across various content types.
Watson Speech-to-Text
IBM's speech recognition service excels with real-time transcription and provides excellent support for technical and specialized vocabulary. The platform learns from your specific domain, improving accuracy as it processes more of your content.
Pricing Details
IBM offers usage-based pricing with monthly minimums starting around $0.02 per 1,000 requests for text-to-speech. Speech-to-text pricing depends on whether you process audio in real-time or batch mode, typically ranging from $0.02 to $0.03 per minute of audio.
The platform includes a lite plan with monthly allowances suitable for initial development.
5. Murf AI: Studio-Quality Voice Generation
Murf AI specializes in creating ultra-realistic, studio-quality voice outputs tailored for content creators and enterprises seeking professional audio production without expensive voice talent.
Murf's Voice Technology
Murf offers over 150 AI voices across 20+ languages, with distinctive strength in voice quality and emotional expression. The platform stands out for generating voices that sound like professional voice actors, making it ideal for audiobook production, corporate training materials, and video narration.
Pricing Strategy
Murf uses a straightforward subscription model based on monthly word limits. Basic plans start around $13 per month for 10,000 words, while professional plans offer 50,000+ words monthly. Pay-as-you-go options exist for users with occasional needs, charging around $0.30 per 1,000 words.
The platform includes a free tier allowing users to test voice quality and features before committing to paid plans.
When Murf Excels
Murf particularly shines for content creators, marketing teams, and enterprises producing high-volume audio content. If your primary need involves converting existing text content into professional-sounding narration, Murf's combination of voice quality and ease of use outperforms general-purpose TTS APIs.
The platform's studio-quality focus makes it less suitable for real-time applications or STT integration, representing a deliberate trade-off toward audio excellence rather than bidirectional speech processing.
Comparing the Top TTS APIs and STT APIs
| Feature | Google Cloud | AWS | Azure | IBM Watson | Murf AI |
|---|---|---|---|---|---|
| Languages Supported | 40+ | 30+ | 140+ | 10+ | 20+ |
| Voice Count | 220+ | 400+ | 400+ | 20+ | 150+ |
| Voice Quality | High | High | High | High | Studio-Grade |
| Custom Voices | Limited | Limited | Advanced | Limited | Limited |
| Real-time Processing | Yes | Yes | Yes | Yes | Limited |
| Batch Processing | Yes | Yes | Yes | Yes | Yes |
| SSML Support | Yes | Yes | Yes | Yes | Partial |
| Best For | All-purpose | All-purpose | Enterprise | Enterprise | Content creators |
| Starting Price | $0.000004/char | $0.000004/char | $0.000009/char | Variable | $13/month |
Streamlining TTS and STT Integration with Apidog
Once you've selected your preferred TTS APIs or STT APIs, the actual integration and testing phase becomes critical. This is where Apidog transforms your development workflow, providing professional-grade tools specifically designed for working with voice technology platforms.
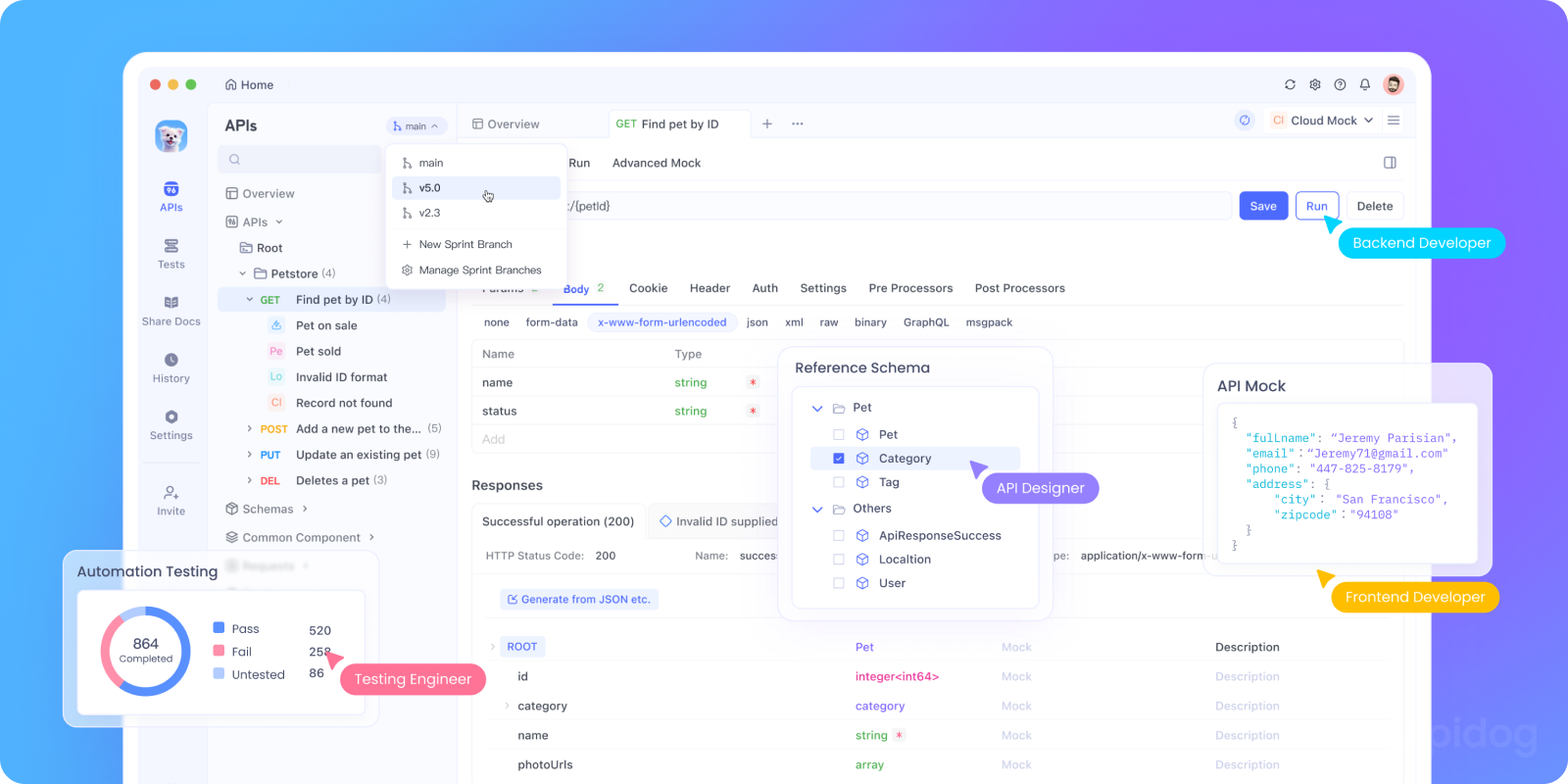
Why Apidog Accelerates TTS and STT Development
Apidog serves as your central hub for designing, testing, and managing TTS and STT API integrations. Rather than juggling multiple tools and platforms, you consolidate your entire voice API workflow into a single interface.
Testing Voice API Parameters requires careful attention to multiple variables. Apidog's visual testing interface allows you to create complex test scenarios that validate TTS responses across different voice selections, languages, and SSML parameters. You can set up automated tests that verify audio generation speed, confirm proper voice selection, and validate error handling without writing extensive test code.
Performance Monitoring matters significantly when working with speech APIs. Apidog captures detailed metrics about your TTS and STT API calls, including response latency, processing times, and audio generation speeds. These metrics help you identify bottlenecks early and optimize your implementation before reaching production.
Building Automated Test Scenarios for Voice APIs
The platform excels at orchestrating multi-step workflows that mirror real-world TTS and STT usage patterns. You might create a test scenario that converts text to speech using one provider, then feed that audio to another STT API, validating the transcription accuracy. Apidog's logical flow controls (if, for, foreach) enable sophisticated testing patterns that match your actual application behavior.
Managing API Authentication and Credentials
TTS APIs and STT APIs require proper authentication management. Apidog securely handles API keys, OAuth tokens, and other credentials across different environments. This security-first approach prevents accidental credential exposure while allowing seamless switching between development, staging, and production endpoints.
Collaborative Testing and Documentation
When your team works with TTS APIs and STT APIs, maintaining documentation becomes essential. Apidog generates interactive API documentation that reflects your exact configuration, parameters, and test results. Team members can review how voice APIs behave under different conditions, reducing integration friction and onboarding time for new developers.
Monitoring Cost and Usage
Working with multiple TTS APIs and STT APIs across different providers can create unexpected billing surprises. Apidog helps you monitor API calls and usage patterns, providing visibility into which endpoints consume the most resources and generating cost optimization opportunities.
Conclusion
The landscape of TTS APIs and STT APIs offers exceptional options for developers. Google Cloud and AWS provide enterprise-grade reliability with competitive pricing. Azure excels in customization and language support. IBM Watson serves organizations with broader enterprise platform investments. Murf AI delivers studio-quality voice generation for content creators and marketing teams.
Your specific requirements determine the best choice. Start by testing multiple platforms using their free tiers, assess performance with your actual content and use cases, and scale to the platform that best aligns with your needs.
The speech technology landscape continues evolving rapidly. These five platforms lead the market today, but staying informed about emerging capabilities and pricing changes remains essential for maintaining optimal performance and cost efficiency.