
Alibaba's Tongyi DeepResearch redefines autonomous AI agents with its 30B-parameter Mixture of Experts (MoE) model, activating just 3B parameters per token for efficient, high-fidelity web research. This open-source powerhouse crushes benchmarks like Humanity's Last Exam (32.9% vs. OpenAI o3's 24.9%) and xbench-DeepSearch (75.0% vs. 67.0%), enabling developers to tackle complex, multi-step queries—from legal analysis to travel itineraries—without proprietary lock-in.
Engineers at Tongyi Lab engineered this agent to conquer long-horizon reasoning and dynamic tool use head-on. Consequently, it outperforms closed models in real-world synthesis, all while running locally via Hugging Face. In this technical breakdown, we dissect its sparse architecture, automated data pipeline, RL-optimized training, benchmark dominance, and deployment hacks. By the close, you'll see how Tongyi DeepResearch—and tools like Apidog—unlock scalable agentic AI for your projects.
Understanding Tongyi DeepResearch: Core Concepts and Innovations
Tongyi DeepResearch redefines agentic AI by focusing on deep information retrieval and synthesis. Unlike traditional large language models (LLMs) that excel in short-form generation, this agent navigates dynamic environments like web browsers to uncover nuanced insights. Specifically, it employs a Mixture of Experts (MoE) architecture, where the full 30B parameters activate selectively to just 3B per token. This efficiency enables robust performance on resource-constrained hardware while maintaining high contextual awareness up to 128K tokens.
Furthermore, the model integrates seamlessly with inference paradigms that mimic human-like decision-making. In ReAct mode, it cycles through thought, action, and observation steps natively, bypassing heavy prompt engineering. For more demanding tasks, the Heavy mode activates the IterResearch framework, which orchestrates parallel agent explorations to avoid context overload. As a result, users achieve superior outcomes in scenarios requiring iterative refinement, such as academic literature reviews or market analysis.
What sets Tongyi DeepResearch apart lies in its commitment to openness. The entire stack—from model weights to training code—resides on platforms like Hugging Face and GitHub. Developers access the Tongyi-DeepResearch-30B-A3B variant directly, facilitating fine-tuning for domain-specific needs. Additionally, its compatibility with standard Python environments lowers the barrier to entry. For instance, installation involves a simple pip command after setting up a Conda environment with Python 3.10.
Transitioning to practical utility, Tongyi DeepResearch powers applications that demand verifiable outputs. In legal research, it parses statutes and case law, citing sources accurately. Similarly, in travel planning, it constructs multi-day itineraries by cross-referencing real-time data. These capabilities stem from a deliberate design philosophy: prioritize agentic reasoning over mere prediction.
The Architecture of Tongyi DeepResearch: Efficiency Meets Power
At its core, Tongyi DeepResearch leverages a sparse MoE design to balance computational demands with expressive power. The model activates only a subset of experts per token, routing inputs dynamically based on query complexity. This approach reduces latency by up to 90% compared to dense counterparts, making it viable for real-time agent deployments. Moreover, the 128K context window supports extended interactions, crucial for tasks involving lengthy document chains or threaded web searches.
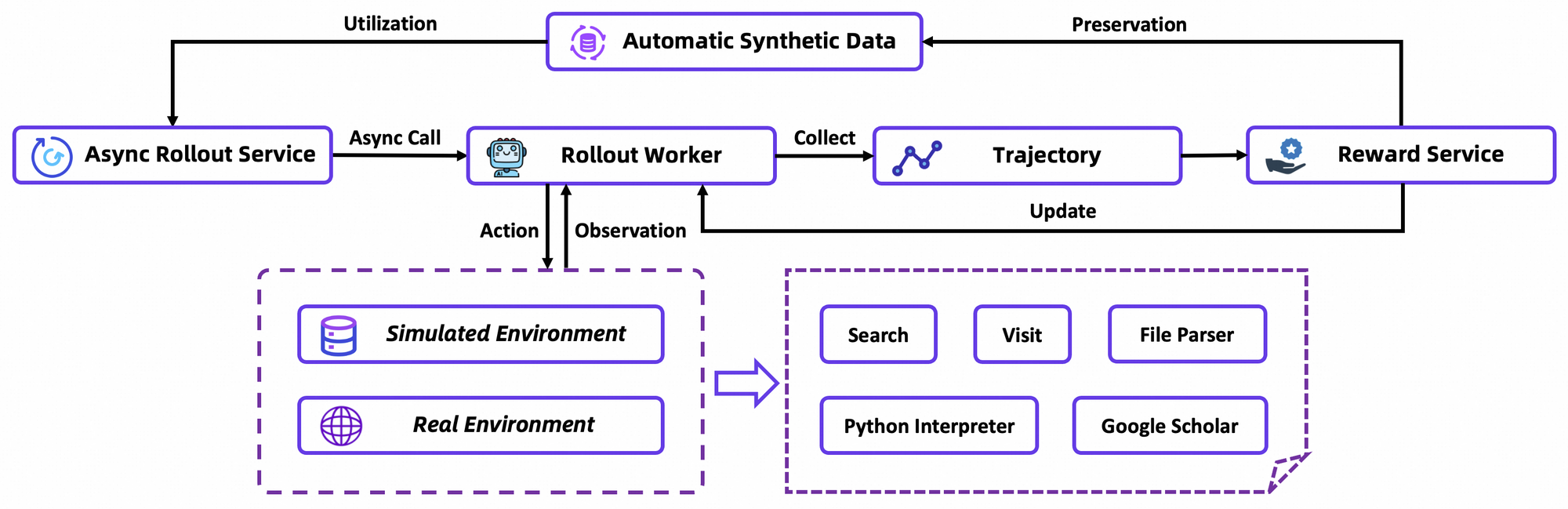
Key architectural components include a custom tokenizer optimized for agentic tokens—such as action prefixes and observation delimiters—and an embedded tool suite for browser navigation, retrieval, and computation. The framework supports on-policy reinforcement learning (RL) integration, where agents learn from simulated rollouts in a stable environment. Consequently, the model exhibits fewer hallucinations in tool invocations, as evidenced by its high scores on tool-use benchmarks.
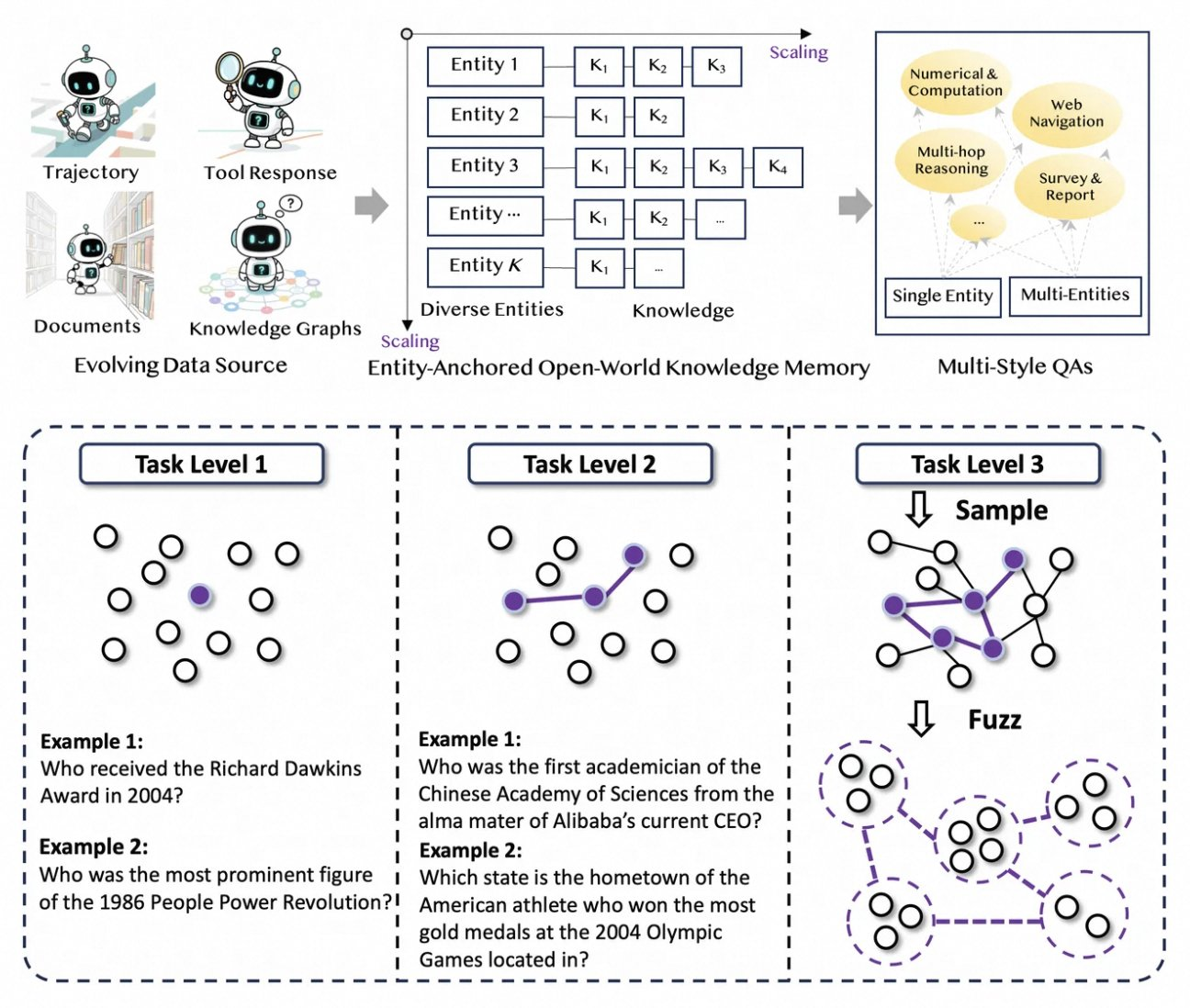
In addition, Tongyi DeepResearch incorporates entity-anchored knowledge memory, derived from graph-based data synthesis. This mechanism anchors responses to factual entities, enhancing traceability. For example, during a query on quantum computing advancements, the agent retrieves and synthesizes papers via WebSailor-like tools, grounding outputs in verifiable sources. Thus, the architecture not only processes information but actively curates it.
To illustrate, consider the model's handling of multi-modal inputs. Although primarily text-based, extensions via the GitHub repo allow integration with image parsers or code executors. Developers configure these in the inference script, specifying paths for datasets in JSONL format. As such, the architecture fosters extensibility, inviting contributions from the open-source community.
Automated Data Synthesis: Fueling Tongyi DeepResearch's Capabilities
Tongyi DeepResearch thrives on a novel, fully automated data pipeline that eliminates human annotation bottlenecks. The process begins with AgentFounder, a synthesis engine that reorganizes raw corpora—documents, web crawls, and knowledge graphs—into entity-anchored QA pairs. This step generates diverse trajectories for continual pre-training (CPT), covering reasoning chains, tool calls, and decision trees.
Next, the pipeline escalates difficulty through iterative upgrades. For post-training, it employs graph-based methods like WebSailor-V2 to simulate "super-human" challenges, such as PhD-level questions modeled via set theory. As a result, the dataset spans millions of high-fidelity interactions, ensuring the model generalizes across domains. Notably, this automation scales linearly with compute, allowing continual updates without manual curation.
Furthermore, Tongyi DeepResearch incorporates multi-style data for robustness. Action synthesis records capture tool-use patterns, while multi-stage QA pairs refine planning skills. In practice, this yields agents that adapt to noisy web environments, filtering irrelevant snippets effectively. For developers, the repo provides scripts to replicate this pipeline, enabling custom dataset creation.
By prioritizing quality over quantity, the synthesis strategy addresses common pitfalls in agent training, like distributional shifts. Consequently, models trained this way demonstrate superior alignment with real-world tasks, as seen in its benchmark dominance.
End-to-End Training Pipeline: From CPT to RL Optimization
Tongyi DeepResearch's training unfolds in a seamless pipeline: Agentic CPT, Supervised Fine-Tuning (SFT), and Reinforcement Learning (RL). First, CPT exposes the base model to vast agentic data, infusing it with web-navigation priors and freshness signals. This phase activates latent capabilities, such as implicit planning, through masked language modeling on trajectories.

Following CPT, SFT aligns the model to instructional formats, using synthetic rollouts to teach precise action formulation. Here, the model learns to generate coherent ReAct cycles, minimizing errors in observation parsing. Transitioning smoothly, the RL stage employs Group Relative Policy Optimization (GRPO), a custom on-policy algorithm.
GRPO computes token-level policy gradients with leave-one-out advantage estimation, reducing variance in non-stationary settings. It also filters negative samples conservatively, stabilizing updates in the custom simulator—an offline Wikipedia database paired with a tool sandbox. Asynchronous rollouts via rLLM framework accelerate convergence, achieving SOTA with modest compute.
In detail, the RL environment simulates browser interactions faithfully, rewarding multi-step success over single actions. This fosters long-horizon planning, where agents iterate on partial failures. As a technical note, the loss function incorporates KL divergence for conservatism, preventing mode collapse. Developers replicate this via the repo's evaluation scripts, benchmarking custom policies.
Overall, this pipeline marks a breakthrough: it connects pre-training to deployment without silos, yielding agents that evolve through trial-and-error.
Benchmark Performance: How Tongyi DeepResearch Excels
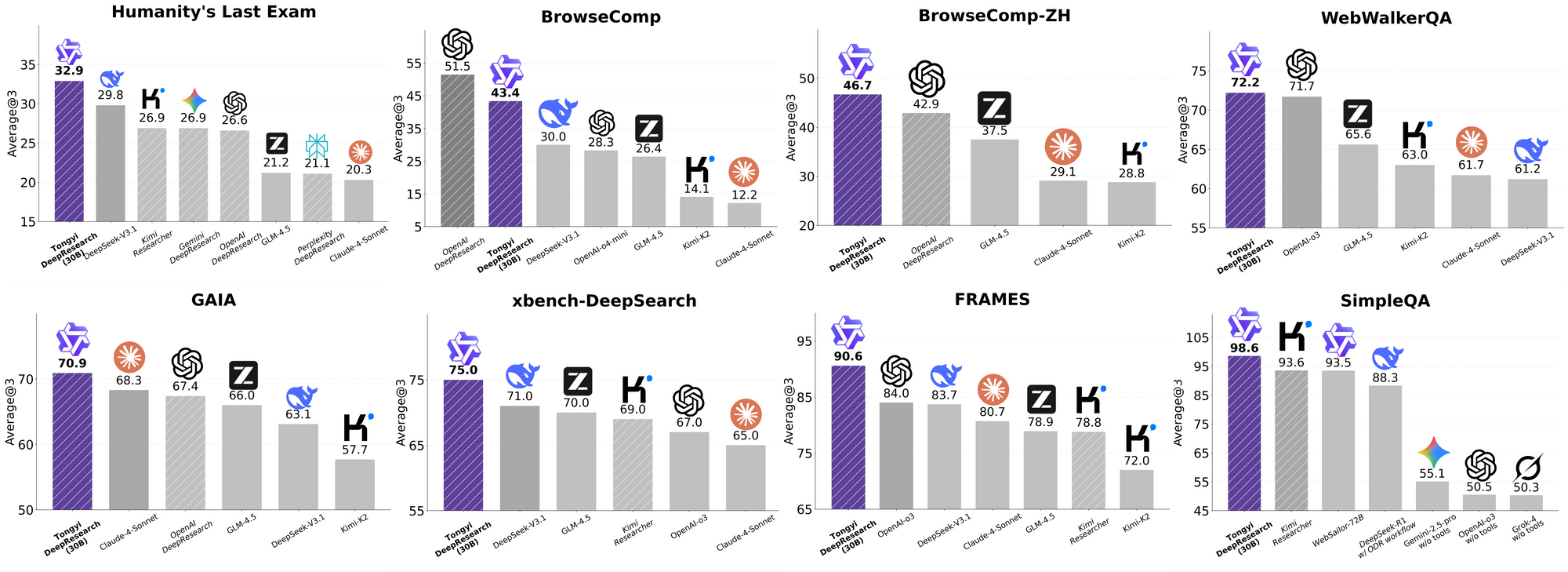
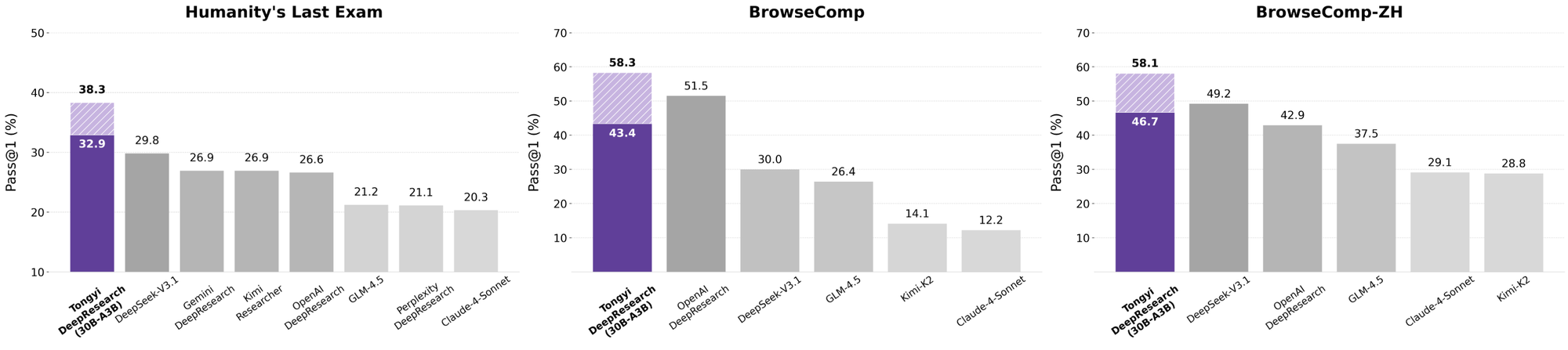
Tongyi DeepResearch shines in rigorous agentic benchmarks, validating its design. On Humanity's Last Exam (HLE), a test of academic reasoning, it scores 32.9 in ReAct mode—surpassing OpenAI's o3 at 24.9. This gap widens in Heavy mode to 38.3, highlighting IterResearch's efficacy.
Similarly, BrowseComp evaluates complex info-seeking; Tongyi achieves 43.4 (EN) and 46.7 (ZH), edging o3's 49.7 and 58.1 respectively in efficiency. The xbench-DeepSearch benchmark, user-centric for deep queries, sees Tongyi at 75.0 versus o3's 67.0, underscoring superior retrieval synthesis.
Other metrics reinforce this: FRAMES at 90.6 (vs. o3's 84.0), GAIA at 70.9, and SimpleQA at 95.0. A comparative chart visualizes these, with bars for Tongyi DeepResearch towering over Gemini, Claude, and others across HLE, BrowseComp, xbench, FRAMES, and more. Blue bars denote Tongyi's leads, gray baselines show competitors' shortfalls.
These results stem from targeted optimizations, like selective expert routing for search tasks. Thus, Tongyi DeepResearch not only competes but leads in open-source agentics.
Comparing Tongyi DeepResearch to Industry Leaders
When developers evaluate AI agents, comparisons reveal true value. Tongyi DeepResearch, at 30B-A3B, outperforms OpenAI's o3 in HLE (32.9 vs. 24.9) and xbench (75.0 vs. 67.0), despite o3's larger scale. Against Google's Gemini, it claims 35.2 on BrowseComp-ZH, a 10-point edge.
Proprietary models like Claude 3.5 Sonnet lag in tool-use; Tongyi's 90.6 on FRAMES dwarfs Sonnet's 84.3. Open-source peers, such as Llama variants, trail further—e.g., 21.1 on HLE. Tongyi's MoE sparsity enables this parity, consuming less inference compute.
Moreover, accessibility tips the scales: while o3 demands API credits, Tongyi runs locally via Hugging Face. For API-heavy workflows, pair it with Apidog to mock endpoints, simulating tool calls efficiently.
In essence, Tongyi DeepResearch democratizes elite performance, challenging closed ecosystems.
Real-World Applications: Tongyi DeepResearch in Action
Tongyi DeepResearch transcends benchmarks, driving tangible impact. In Gaode Mate, Alibaba's navigation app, it plans intricate trips—querying flights, hotels, and events in parallel via Heavy mode. Users receive synthesized itineraries with citations, reducing planning time by 70%.
Likewise, Tongyi FaRui revolutionizes legal research. The agent analyzes statutes, cross-references precedents, and generates briefs with verifiable links. Professionals verify outputs swiftly, minimizing errors in high-stakes domains.
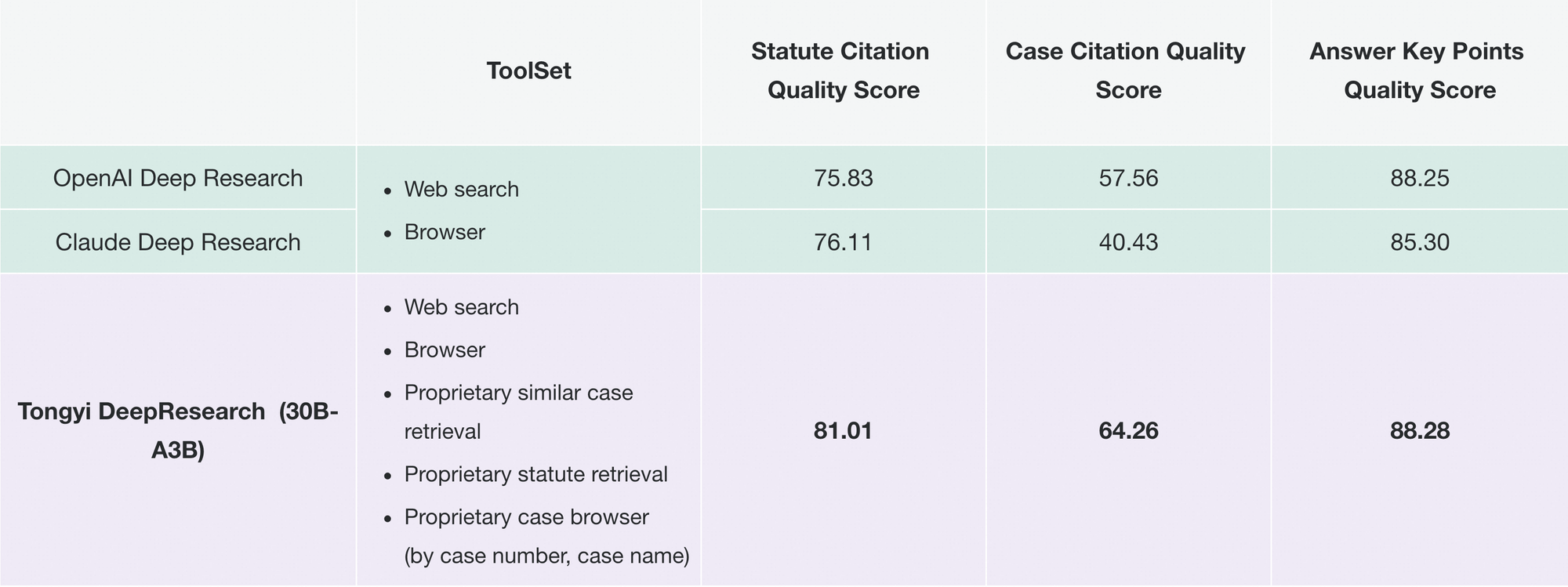
Beyond these, enterprises adapt it for market intelligence: scraping competitor data, synthesizing trends. The repo's modularity supports such extensions—add custom tools via JSON configs.
As adoption grows, Tongyi DeepResearch integrates into ecosystems like LangChain, amplifying agent swarms. For API devs, Apidog complements this by validating integrations pre-deployment.
These cases demonstrate scalability: from consumer apps to B2B tools, the model delivers reliable autonomy.
Getting Started with Tongyi DeepResearch: A Developer's Guide
Implement Tongyi DeepResearch effortlessly with its GitHub repo. Begin by creating a Conda env: conda create -n deepresearch python=3.10. Activate and install: pip install -r requirements.txt.
Prepare data in eval_data/ as JSONL, with question and answer keys. For files, prepend names to questions and store in file_corpus/. Edit run_react_infer.sh for model path (e.g., Hugging Face URL) and API keys for tools.
Run: bash run_react_infer.sh. Outputs land in specified paths, ready for analysis.
For Heavy mode, configure IterResearch params in code—set agent count and rounds. Benchmark via evaluation/ scripts, comparing to baselines.
Troubleshoot with logs; common issues like tokenizer mismatches resolve via BF16 tensor checks. To enhance, download Apidog free for API simulation, testing tool endpoints without live calls.
This setup equips you to prototype agents rapidly.
Future Directions: Scaling Tongyi DeepResearch Further
Looking ahead, Tongyi Lab targets context expansion beyond 128K, enabling ultra-long horizons like book-length analyses. They plan validation on larger MoE bases, probing scalability limits.
RL enhancements include partial rollouts for efficiency and off-policy methods to mitigate shifts. Community contributions could integrate vision or multi-lingual tools, broadening scope.
As open-source evolves, Tongyi DeepResearch will anchor collaborative advancements, fostering AGI pursuits.
Conclusion: Embrace the Tongyi DeepResearch Era
Tongyi DeepResearch transforms agentic AI, blending efficiency, openness, and prowess. Its benchmarks, architecture, and apps position it as a leader, outpacing rivals like OpenAI's offerings. Developers, harness this power—download the model, experiment, and integrate with Apidog for seamless APIs.
In a field racing toward autonomy, Tongyi DeepResearch accelerates progress. Start building today; the insights await.


