
In the rapidly evolving world of artificial intelligence, the ability to stream responses from Large Language Models (LLMs) in real time has become essential for enhancing user interactions and improving overall application performance. One of the best ways to achieve this is through Server-Sent Events (SSE), a robust technology built on the HTTP protocol that provides a one-way communication channel between the server and the client. In this article, we will delve into how SSE works, how it can be used to stream LLM responses, and how tools like Apidog can simplify debugging and improve development efficiency.
What Are Server-Sent Events (SSE)?
Server-Sent Events are a lightweight, real-time communication technology based on the HTTP protocol. With SSE, a server establishes a continuous, one-way connection to the client. The server pushes updates to the client without the need for the client to repeatedly request new data. This makes SSE ideal for streaming dynamic content like real-time updates, live notifications, and, in the case of AI models, continuous responses from LLMs.
The beauty of SSE lies in its simplicity and low overhead. Unlike WebSockets, which allow two-way communication, SSE is designed for scenarios where the server needs to push data continuously to the client. This is particularly useful when streaming AI-generated content in real-time, as the client can see the model's thought process unfold as it generates each part of the response.
How SSE Works in LLM Streaming
When using LLMs, especially with complex models like DeepSeek R1, responses often arrive in fragmented pieces. With SSE, each of these fragments is sent as a separate "event" in the stream. This allows developers and end users to witness the entire process in real time. As the server sends each event, the client is updated immediately, ensuring that users receive the most up-to-date information available.
Benefits of Using SSE for AI Model Responses
- Real-Time Data Delivery: SSE allows the client to receive updates immediately as they are generated, without any delay.
- Efficient Communication: The server sends data only when new events occur, reducing unnecessary requests and improving system efficiency.
- Simplified Client-Side Implementation: With SSE, clients don’t need complex logic to handle continuous data updates, as they are automatically received and displayed.
Setting up SSE Debugging with Apidog
To get started with SSE debugging using Apidog, ensure you’re using version 2.6.49 or higher. Apidog provides a user-friendly platform for working with APIs, making it easier to handle SSE connections and debug the real-time data streams from LLMs like DeepSeek R1.
Step 1: Create a New Endpoint in Apidog
Start by creating a new HTTP project in Apidog. This allows you to set up a workspace for testing and debugging your API requests. Once your project is set up, add a new endpoint by entering the AI model’s URL. This is where the SSE stream will be coming from. In this example, we will use DeepSeek as the AI model. (PRO TIP: You can clone the out-of-box DeepSeek API project in Apidog's API Hub).
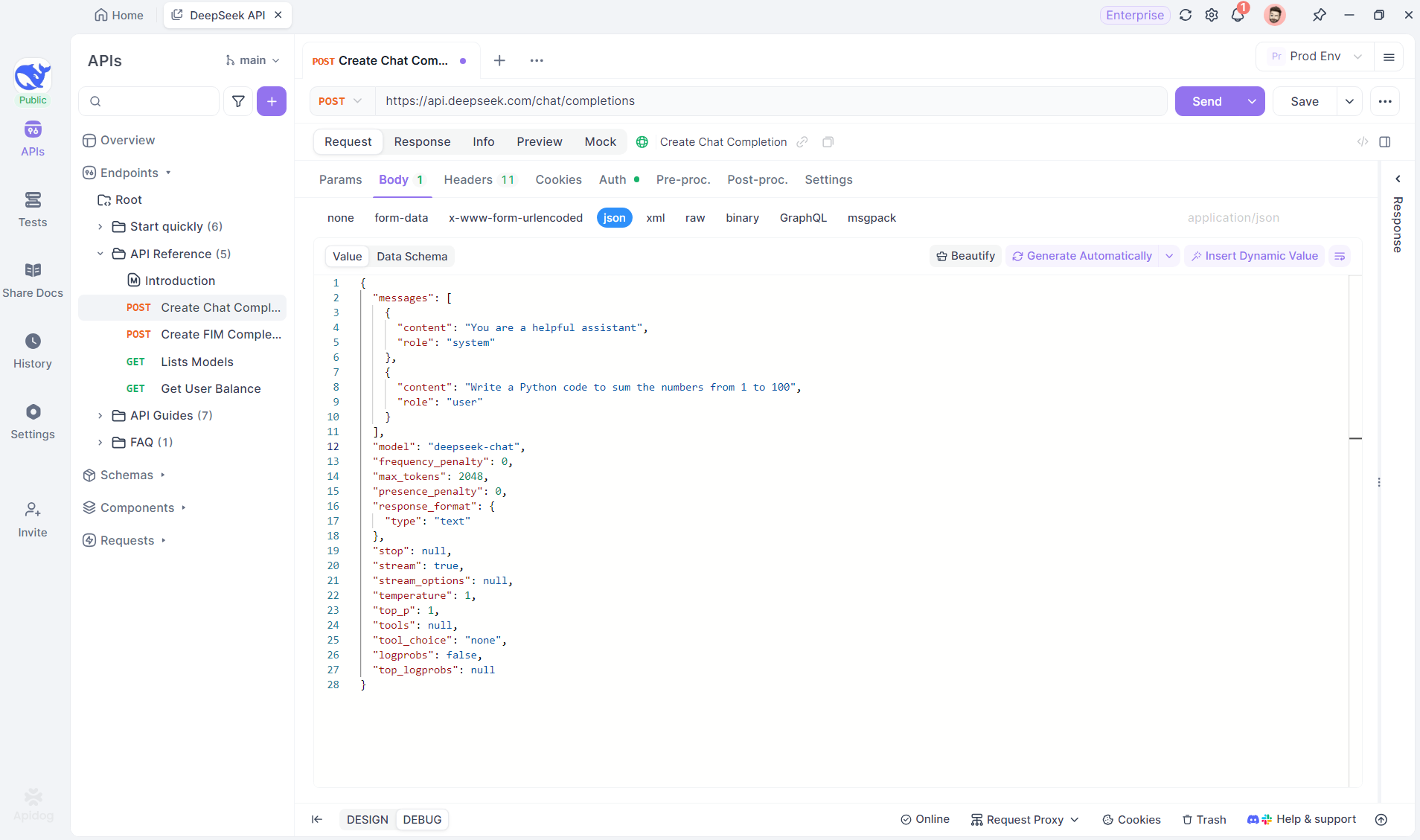
Step 2: Send the Request
After adding the endpoint, send the request to the server by clicking Send at the right top. If the server’s response header includes Content-Type: text/event-stream, Apidog will automatically recognize that the data is being streamed via SSE. Apidog’s intelligent system will parse this response and display it in the response panel, allowing you to see the real-time stream as it’s being generated.
Step 3: View Real-Time Responses
Apidog’s Timeline View is where the magic happens. As the AI model streams its responses, the Timeline view dynamically updates, displaying each fragment of the response in real time. This view allows you to track the evolution of the AI’s thought process, giving you valuable insight into how it’s generating the final output.
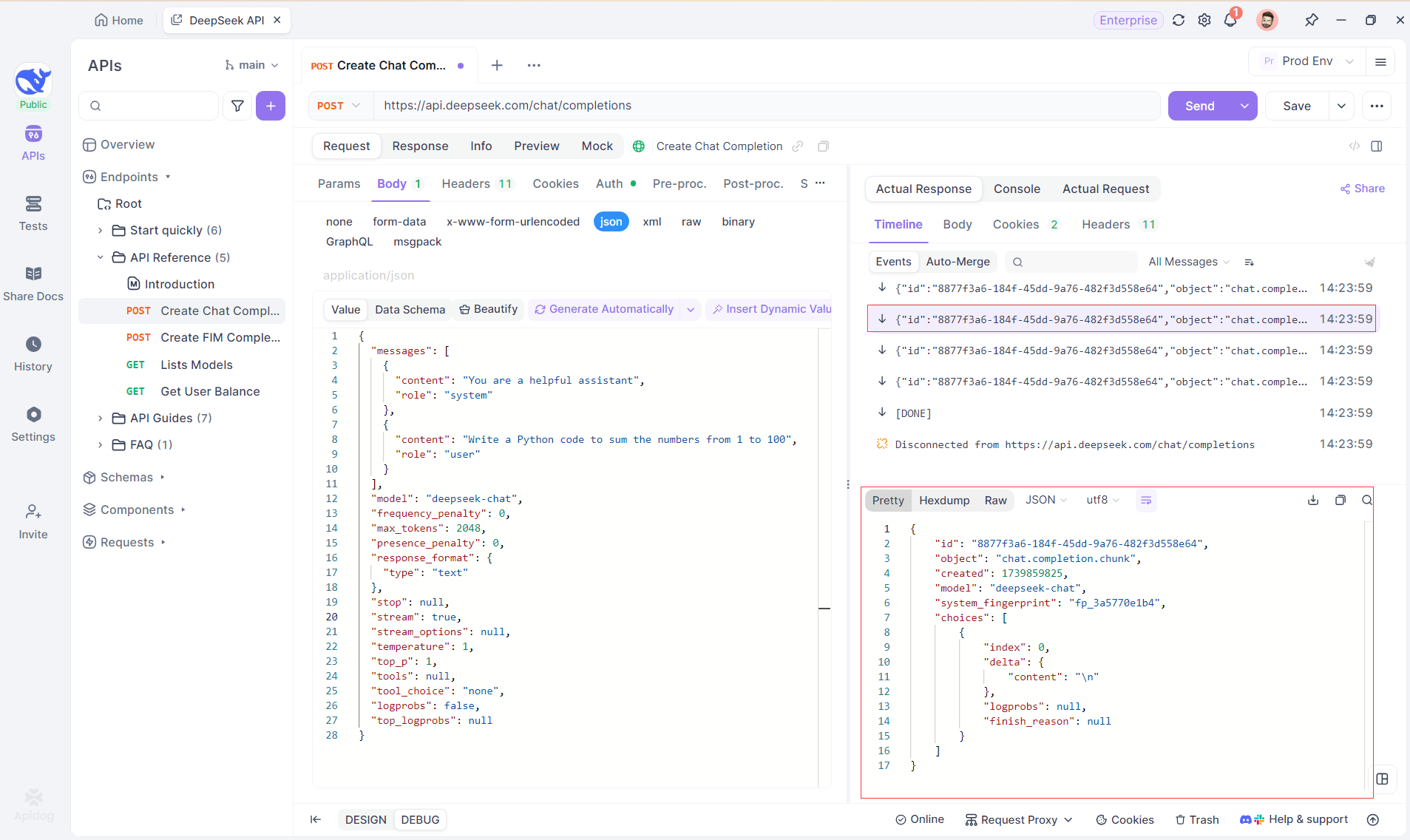
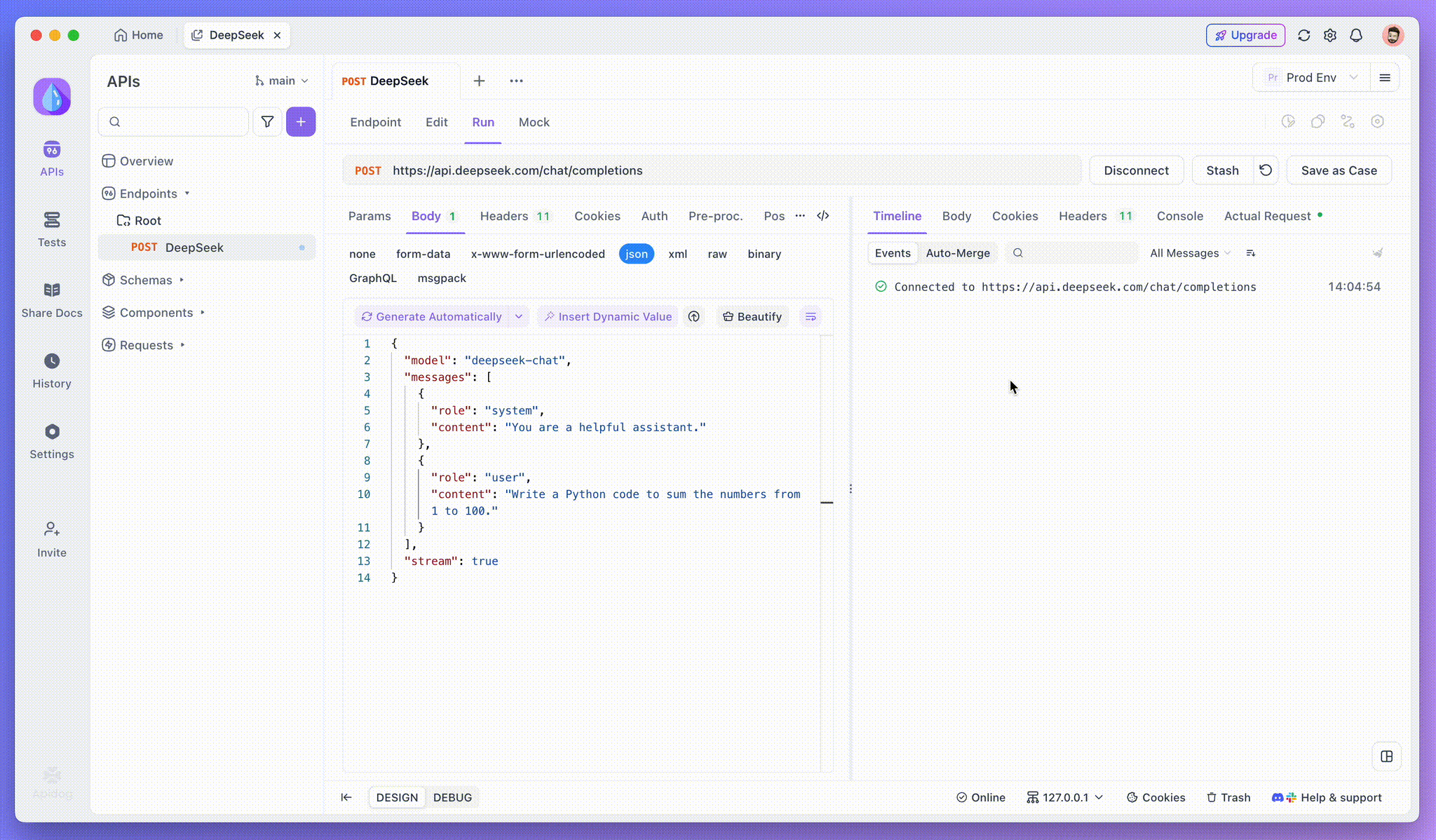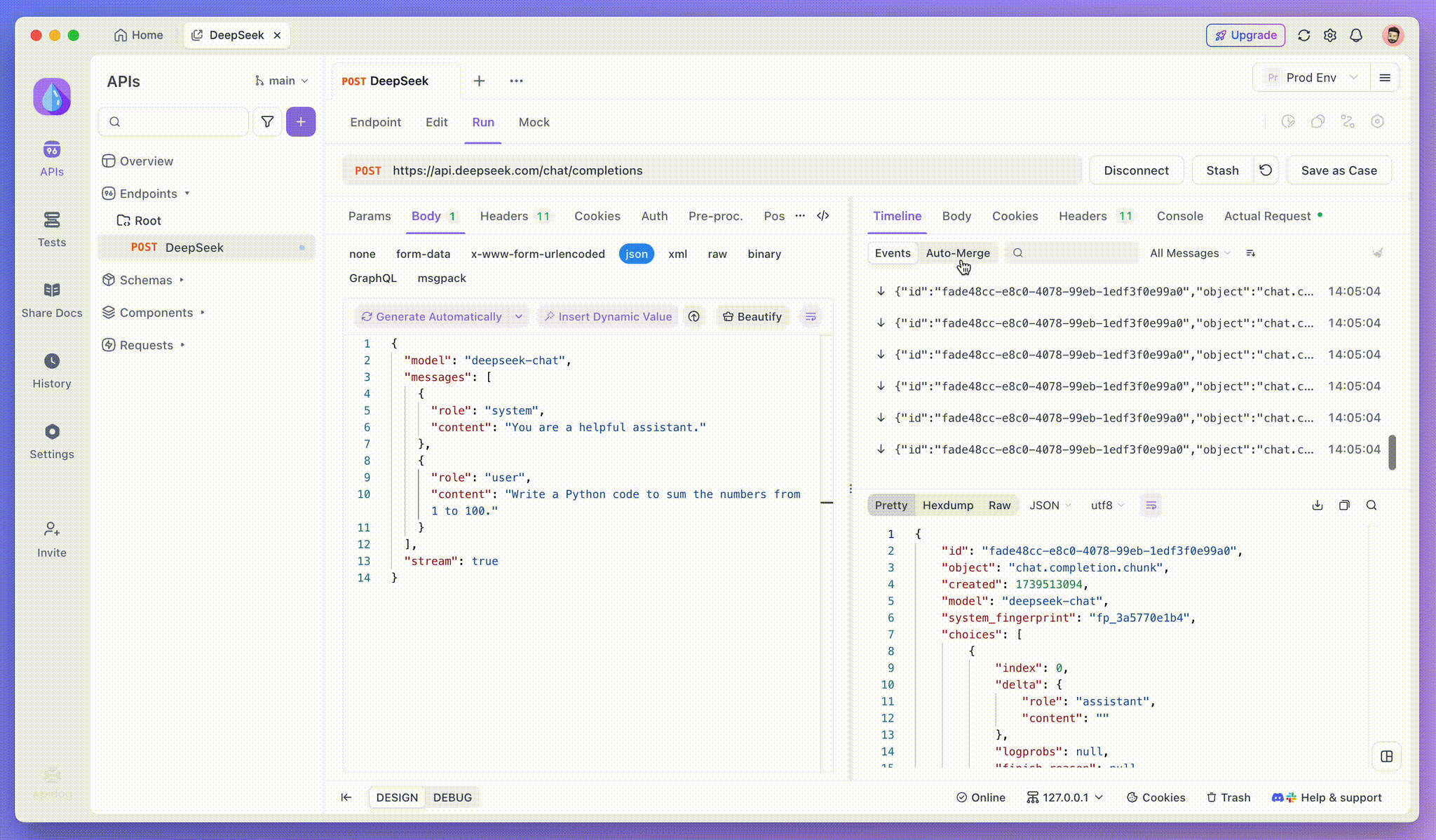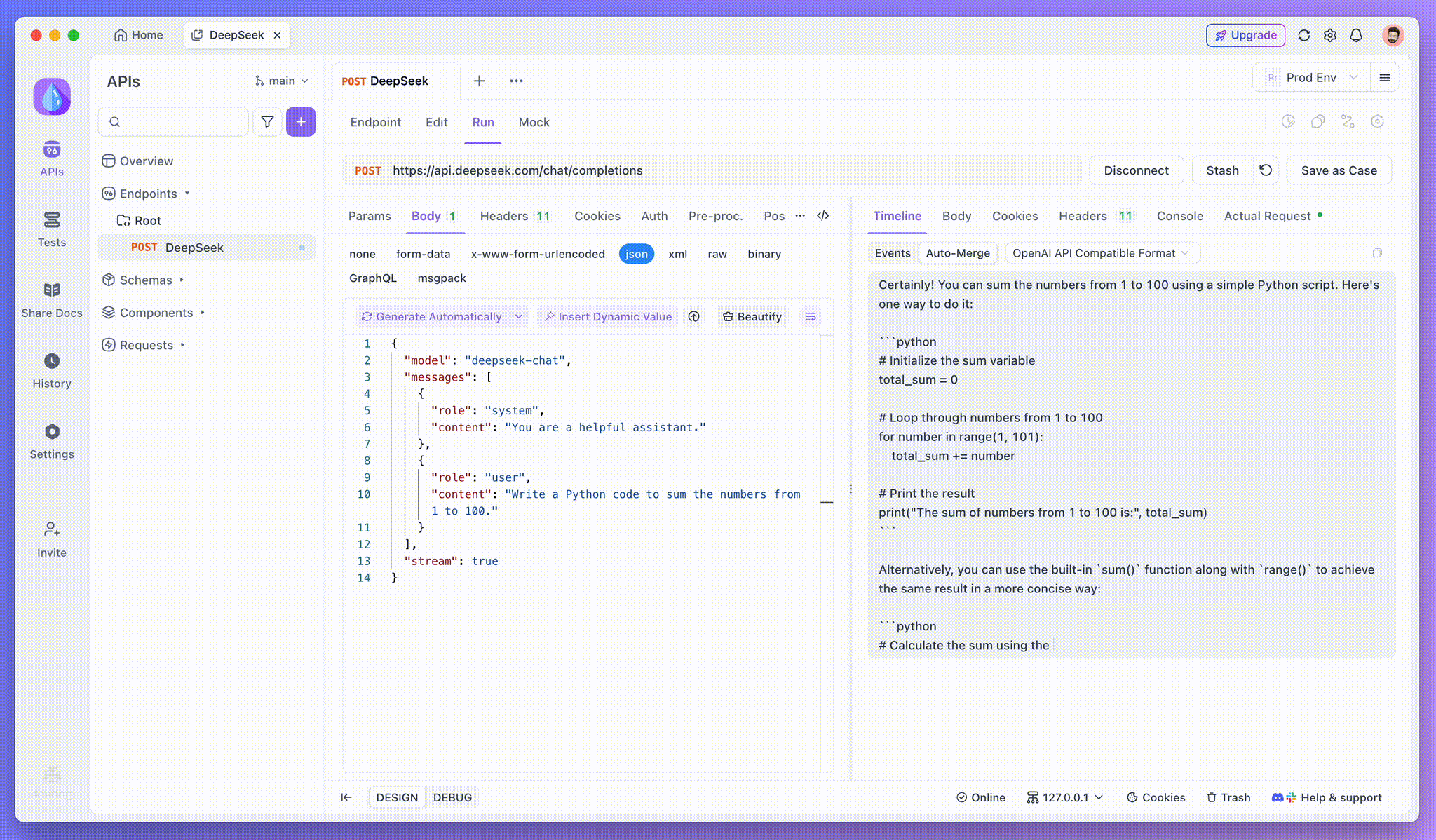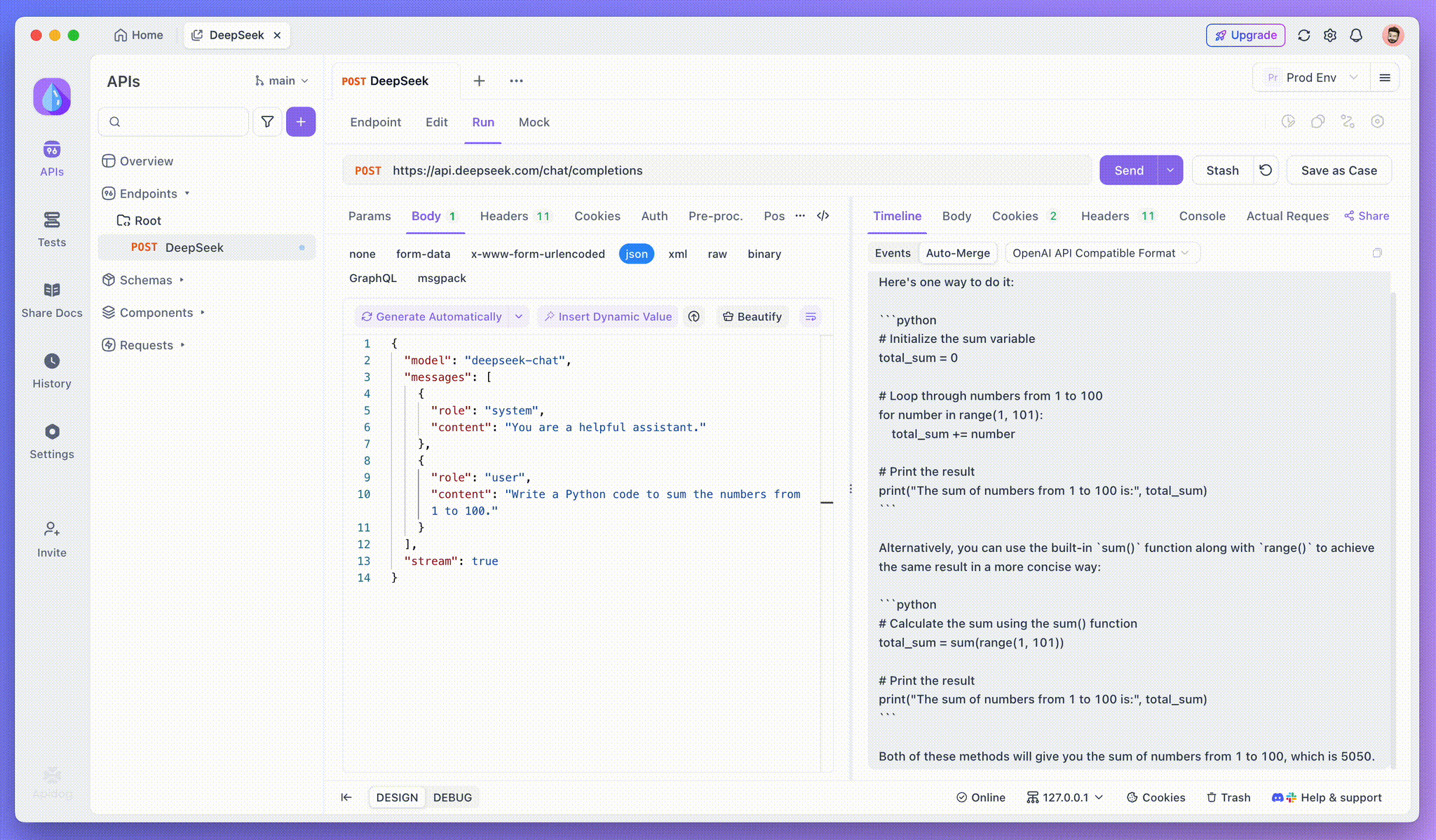
Step 4: Viewing SSE Response in a Complete Reply
While SSE provides a powerful way to stream data, it often requires additional handling to deal with fragmented responses. Apidog's Auto-Merge feature is designed to address this challenge. When streaming AI responses, the data often comes in multiple fragments, especially with models like OpenAI, Gemini, or Claude. Apidog automatically merges these fragments into a unified, complete response.
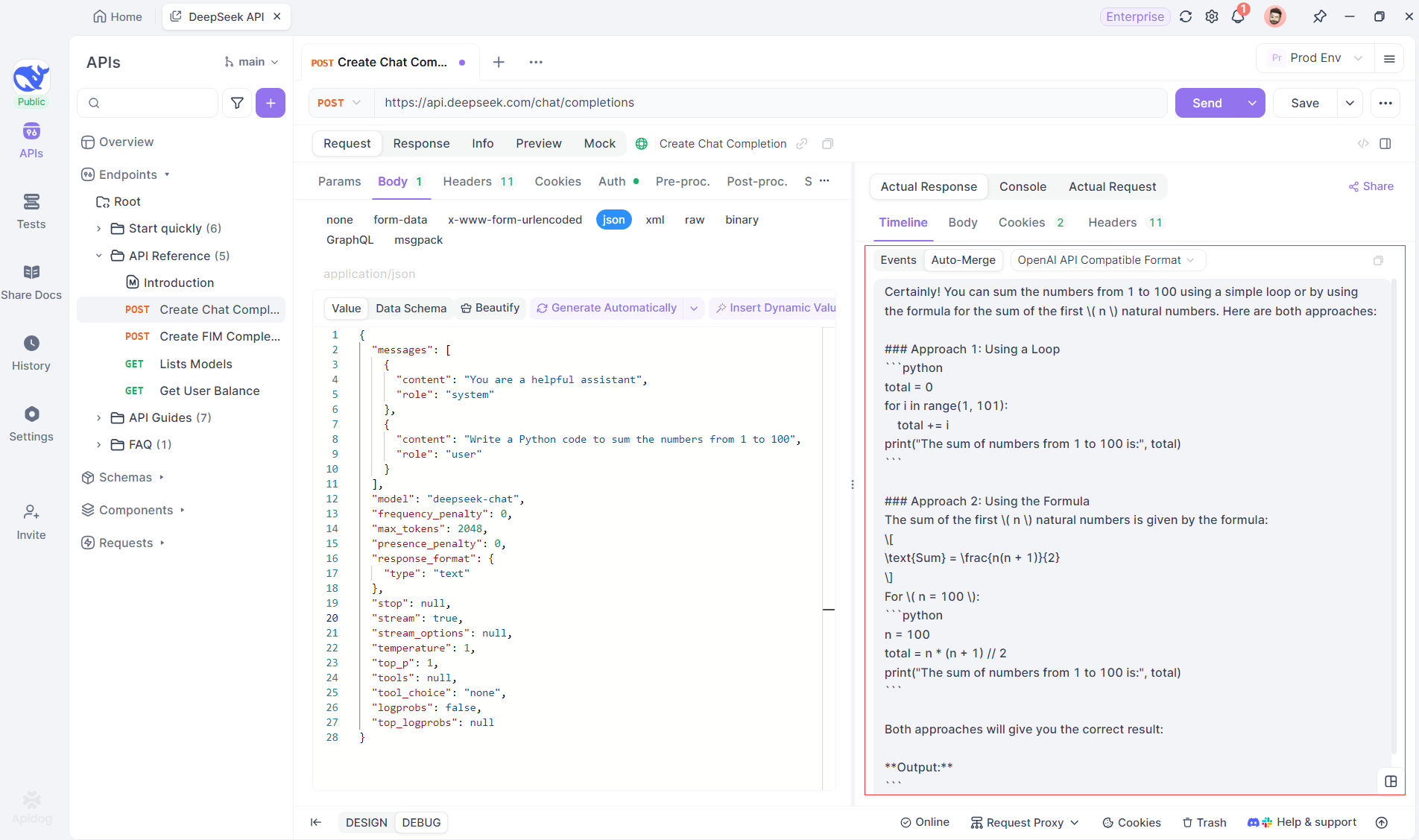
This feature eliminates the need for manual data handling, allowing developers to focus on analyzing the AI’s output instead of dealing with the complexities of merging fragmented messages.
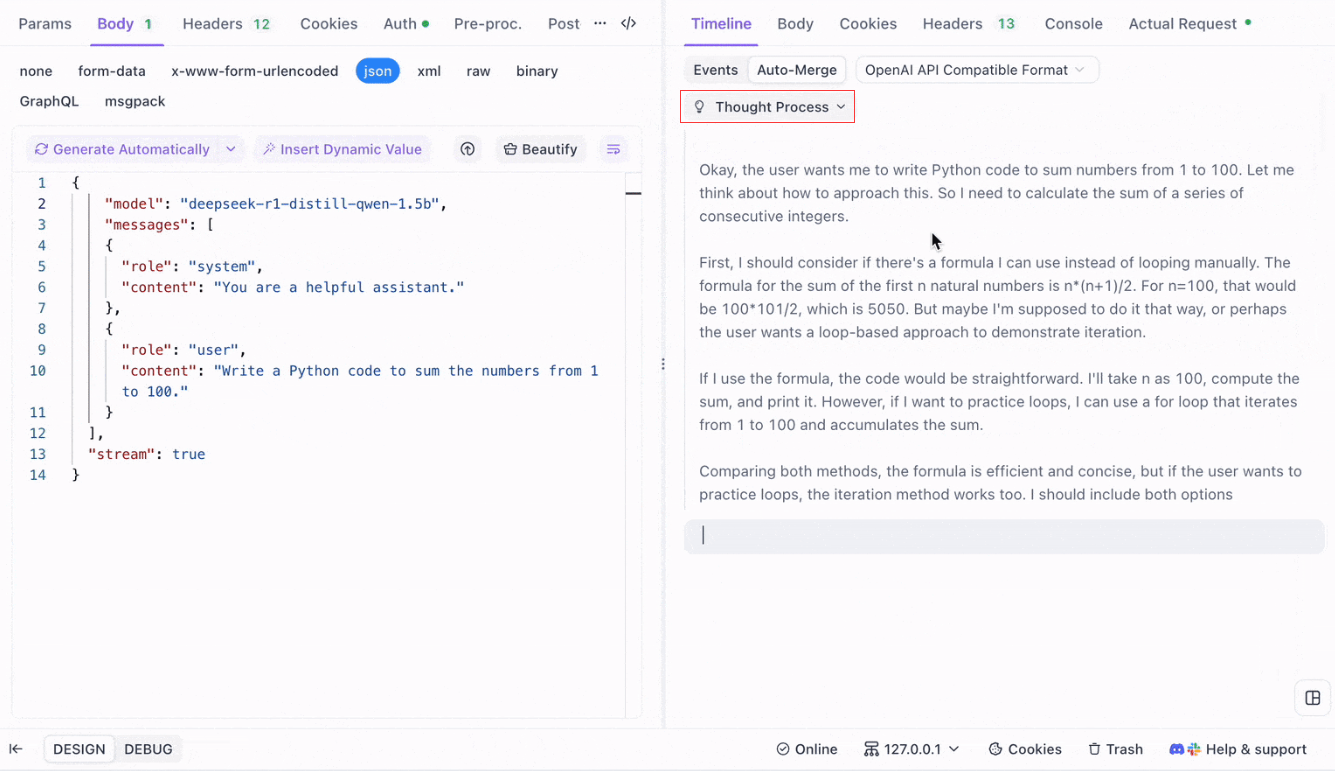
Visualizing the Thought Process of Reasoning Models: One of the standout features when working with reasoning models like DeepSeek R1 is Apidog’s ability to display the model’s thought process directly in the Timeline view.
As the AI generates responses, Apidog not only shows the response data but also provides a visual representation of how the model arrived at its conclusions. This offers a more intuitive way to debug and understand the reasoning behind the AI’s responses.
Supported Formats for Auto-Merge
Apidog can automatically recognize and merge responses from several popular AI model formats:
- OpenAI API Format
- Gemini API Format
- Claude API Format
When the response from the AI model matches any of these formats, Apidog seamlessly merges the fragments into a complete reply. This makes debugging SSE responses more efficient, as the developer doesn’t need to manually stitch the pieces together.
Why Use Auto-Merge for LLM Debugging?
- Time Efficiency: Developers can avoid the tedious task of manually merging response fragments.
- Improved Debugging: A unified, complete response allows for a clearer analysis of the AI’s behavior.
- Enhanced Insight: Visualizing the model’s thought process adds an extra layer of understanding, particularly for complex models like DeepSeek R1.
Customizing SSE Debugging Rules in Apidog
In some cases, the built-in Auto-Merge feature might not work as expected, particularly when dealing with custom AI models or non-standard formats. Apidog allows you to customize the way responses are handled using JSONPath Extraction Rules or Post-Processor Scripts.
Configuring JSONPath Extraction Rules
If the SSE response is in JSON format but does not conform to the built-in recognition rules for formats like OpenAI, Claude or Gemini, you can configure JSONPath to extract the necessary content.
For example, consider the following raw SSE response:
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"H"},"logprobs":null,"finish_reason":"stop"}]}
data: {"choices":[{"index":0,"message":{"role":"assistant","content":"i"},"logprobs":null,"finish_reason":"stop"}]}To extract the content of the message.content field, you would configure JSONPath as follows: $.choices[0].message.content
This configuration will pull the content: Hi
By using JSONPath, you can customize how Apidog handles responses, ensuring that you always extract the correct data.
Using Post-Processor Scripts for Non-JSON SSE
For non-JSON responses, Apidog provides the ability to use Post-Processor Scripts to manipulate and extract data from the SSE stream. This allows you to write custom scripts that handle specific data formats that don’t conform to traditional JSON structures.
If you're dealing with an unsupported model format, you can also contact Apidog’s technical support to request that the format be added for built-in support.
Best Practices for Streaming LLM Responses with SSE
When streaming LLM responses using SSE, there are several best practices to keep in mind to ensure smooth and efficient debugging:
- Handle Fragmentation Gracefully: Always anticipate that AI model responses may come in multiple fragments, and use the
Auto-Mergefeature to streamline this process. - Test with Different AI Models: Use models like OpenAI, Gemini, and DeepSeek R1 to explore the behavior of different formats and ensure your setup can handle multiple response types.
- Use Timeline View for Debugging: Leverage Apidog’s Timeline view to get a real-time, step-by-step breakdown of how responses evolve, especially for complex AI models.
- Customize for Non-Standard Formats: If necessary, use JSONPath or Post-Processor Scripts to handle non-standard SSE formats or to fine-tune the data extraction process.
Conclusion: Enhancing LLM Streaming with SSE
Server-sent events provide a powerful mechanism for streaming real-time responses from AI models, particularly when dealing with large and complex LLMs. By using Apidog’s SSE debugging tools, including the Auto-Merge feature and enhanced visualization, developers can simplify the process of handling fragmented responses and gain deeper insights into the model’s behavior. Whether you're debugging responses from popular models like OpenAI or working with custom AI solutions, Apidog ensures that you can easily track, merge, and analyze SSE data in a way that’s efficient and insightful.


