
Introduction
The integration of advanced reasoning models and lightweight frameworks is transforming how AI systems retrieve, process, and present information. In this guide, we will build a Retrieval-Augmented Generation (RAG) system using DeepSeek R1, a high-performance reasoning model, and SmolAgents, a minimalist agent framework from Hugging Face. This system will enable efficient document processing, intelligent search, and human-like reasoning—ideal for research, customer support, and knowledge management applications.
System Requirments to Run the Setup
The AI agent will perform four core tasks:
- Load and Process PDFs: Convert documents into searchable text chunks.
- Create a Vector Database: Store embeddings for fast semantic search.
- Retrieve and Reason: Use DeepSeek R1 to analyze retrieved data and generate answers.
- Interact with Users: Provide a conversational interface for seamless interaction.
Step 1: Loading and Processing PDF Documents
Tools and Libraries
- LangChain: For document loading and text splitting.
- ChromaDB: A lightweight vector database for storing embeddings.
- Hugging Face Embeddings: To convert text into vector representations.
Implementation
1.1 Load PDF Files
Use LangChain's DirectoryLoader to load all PDFs from a directory. Each PDF is split into pages for processing.
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_and_process_pdfs(data_dir: str):
loader = DirectoryLoader(
data_dir,
glob="**/*.pdf",
loader_cls=PyPDFLoader
)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
return text_splitter.split_documents(documents)
1.2 Create a Vector Store
Convert text chunks into embeddings and store them in ChromaDB for efficient retrieval.
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
import os
import shutil
def create_vector_store(chunks, persist_directory: str):
if os.path.exists(persist_directory):
shutil.rmtree(persist_directory)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={'device': 'cpu'}
)
vectordb = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=persist_directory
)
return vectordb
Key Considerations
- Chunk Size: 1000 characters with 200-character overlap balances context retention and search efficiency.
- Embedding Model:
all-mpnet-base-v2provides high-quality sentence embeddings.
Step 2: Implementing the Reasoning Agent with DeepSeek R1
Why DeepSeek R1?
DeepSeek R1 specializes in multi-step reasoning, enabling it to break down complex queries, infer relationships, and generate structured answers.
Initialize the Reasoning Model
Configure DeepSeek R1 via Ollama for local inference:
from smolagents import OpenAIServerModel, CodeAgent
reasoning_model_id = "deepseek-r1:7b"
def get_model(model_id):
return OpenAIServerModel(
model_id=model_id,
api_base="http://localhost:11434/v1",
api_key="ollama"
)
reasoning_model = get_model(reasoning_model_id)
reasoner = CodeAgent(
tools=[],
model=reasoning_model,
add_base_tools=False,
max_steps=2 # Limit reasoning iterations for efficiency
)
Step 3: Building the Retrieval-Augmented Generation (RAG) Pipeline
Tool Design
Create a RAG tool that combines document retrieval with DeepSeek R1’s reasoning capabilities.
from smolagents import tool
@tool
def rag_with_reasoner(user_query: str) -> str:
# Retrieve relevant documents
docs = vectordb.similarity_search(user_query, k=3)
context = "\n\n".join(doc.page_content for doc in docs)
# Generate a reasoning prompt
prompt = f"""
Based on the following context, answer the user's question concisely.
If the information is insufficient, suggest a refined query.
Context:
{context}
Question: {user_query}
Answer:
"""
return reasoner.run(prompt, reset=False)
Key Features
- Contextual Prompts: Inject retrieved documents into the prompt for grounded responses.
- Fallback Mechanism: The model suggests better queries when data is insufficient.
Step 4: Deploying the Primary AI Agent
Orchestrating the Workflow
The primary agent, powered by Llama 3.2, manages user interactions and invokes the RAG tool as needed:
from smolagents import ToolCallingAgent, GradioUI
tool_model = get_model("llama3.2")
primary_agent = ToolCallingAgent(
tools=[rag_with_reasoner],
model=tool_model,
add_base_tools=False,
max_steps=3
)
def main():
GradioUI(primary_agent).launch()
if __name__ == "__main__":
main()
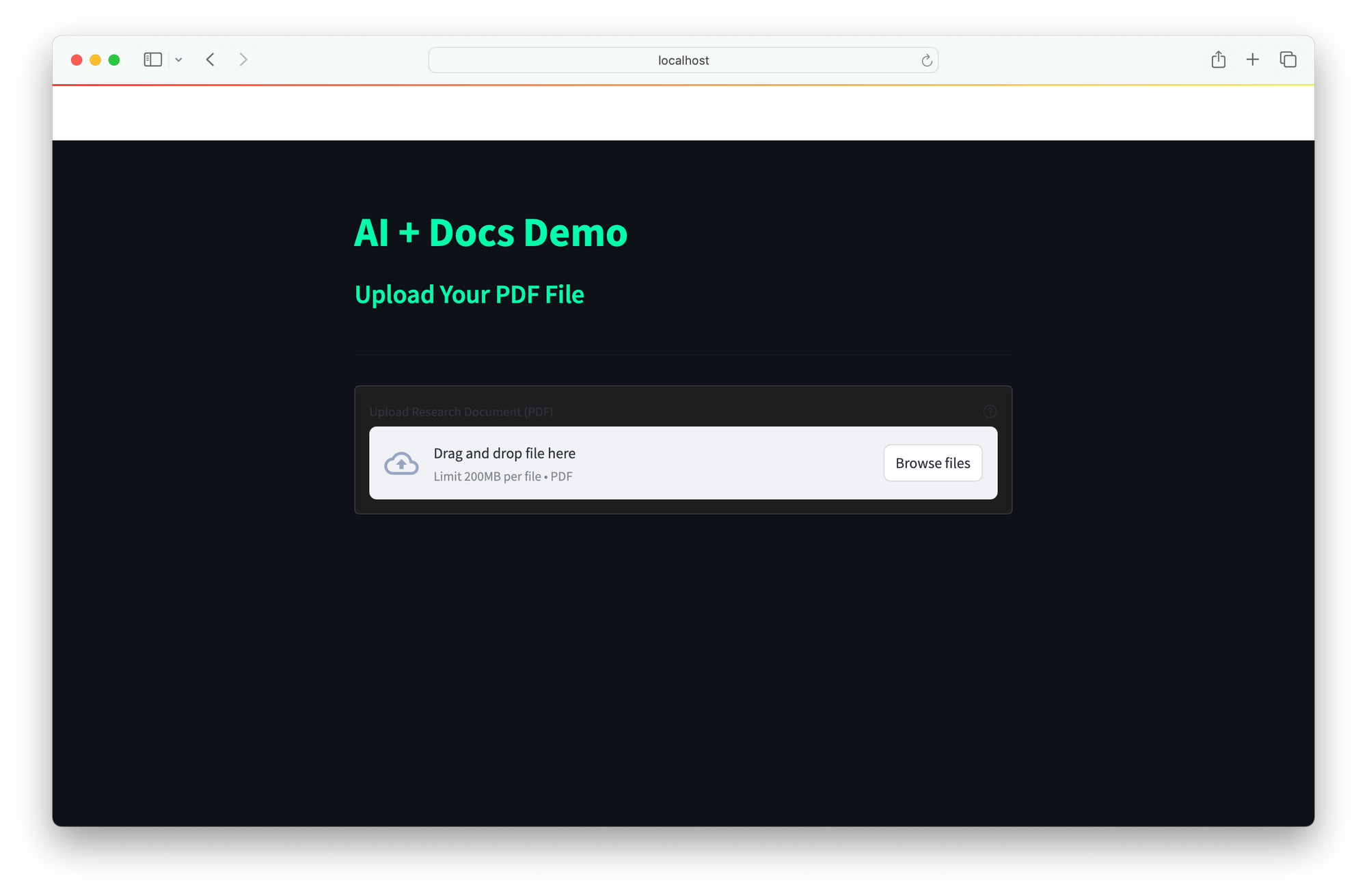
User Interface
The UI provides a simple web interface for real-time interaction:
- Users input queries.
- The agent retrieves documents, reasons with DeepSeek R1, and returns answers.
The integration of DeepSeek R1 and SmolAgents delivers a powerful AI solution that combines enhanced reasoning for dissecting complex queries, efficient retrieval via ChromaDB’s fast semantic search, and cost-effective local deployment to bypass reliance on costly cloud APIs. Its scalable architecture allows seamless integration of new tools, making it ideal for applications like research (analyzing technical documents), customer support (resolving FAQs), and knowledge management (transforming static resources into interactive systems).
Future enhancements could expand document support to include Word, HTML, and markdown, integrate real-time web search for broader context, and implement feedback loops to refine answer accuracy over time. This framework offers a versatile foundation for building intelligent, adaptive AI assistants tailored to diverse needs.


