Developers and AI enthusiasts constantly seek efficient models that perform well without demanding massive resources. Google introduces Gemma 3 270M, a compact language model with 270 million parameters. This model stands out as the smallest in the Gemma 3 family, optimized for on-device tasks. You gain capabilities in text generation, question answering, summarization, and reasoning, all while keeping operations local.
Gemma 3 270M supports a context length of 32,000 tokens, which allows it to handle substantial inputs effectively. Additionally, it incorporates quantization techniques like Q4_0 Quantization Aware Training (QAT), reducing resource needs without sacrificing quality. As a result, you achieve performance close to full-precision models but with lower memory and compute demands.
However, what makes Gemma 3 270M particularly appealing lies in its accessibility. You run it on standard hardware, including laptops or even mobile devices, promoting privacy and low-latency applications. Next, consider how this model fits into broader AI development trends, where efficiency drives innovation.
Understanding the Architecture of Gemma 3 270M
Google builds Gemma 3 270M on a transformer-based architecture, featuring 170 million parameters for embeddings with a 256,000-token vocabulary and 100 million for transformer blocks. This setup enables multilingual support and niche task handling. You benefit from techniques such as INT4 quantization, rotary position embeddings, and group query attention, which enhance inference speed and lightness.
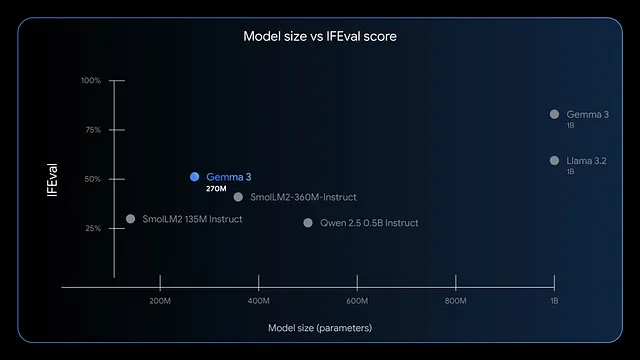
Furthermore, the model excels in instruction-following and data extraction. Benchmarks show high F1 scores on IFEval, indicating strong performance in evaluation tasks. Compared to larger models like GPT-4 or Phi-3 Mini, Gemma 3 270M prioritizes efficiency, using less than 200MB in 4-bit mode on devices like Apple's M4 Max.
Consequently, you deploy it for scenarios demanding quick responses, such as real-time sentiment analysis or healthcare entity extraction. Yet, its small size does not limit creativity; you apply it to creative writing or financial compliance checks. Moving forward, evaluate the advantages of running this model locally.
Benefits of Running Gemma 3 270M Locally
You enhance privacy by keeping data on your device, avoiding cloud transmissions that risk exposure. Gemma 3 270M reduces latency, delivering responses in milliseconds rather than seconds. Moreover, it cuts costs since you avoid subscription fees for cloud-based APIs.
In addition, the model's energy efficiency stands out. It consumes only 0.75% of a Pixel 9 Pro's battery for 25 conversations in INT4-quantized mode. This trait suits mobile and edge computing, where power matters. You also customize the model easily through fine-tuning with tools like LoRA, requiring minimal data.
Nevertheless, local execution empowers small teams or individual developers. You experiment freely, iterating on applications like e-commerce query routing or legal text structuring. As you proceed, check if your system meets the requirements.
System Requirements for Gemma 3 270M Inference
Gemma 3 270M demands modest hardware, making it accessible. For CPU-only inference, you need at least 4GB RAM and a modern processor like Intel Core i5 or equivalent. However, GPU acceleration improves speed; an NVIDIA card with 2GB VRAM suffices for quantized versions.
Specifically, in 4-bit mode, the model fits within 200MB memory, allowing runs on devices with limited resources. Apple silicon users benefit from MLX-LM, achieving over 650 tokens per second on an M4 Max. For fine-tuning, allocate 8GB RAM and a GPU with 4GB VRAM to handle small datasets efficiently.
Importantly, operating systems like Windows, macOS, or Linux work, but ensure Python 3.10+ for library compatibility. Storage requires about 1GB for the model files. With these in place, you install and run without issues. Now, explore installation methods.
Choosing the Right Tool to Run Gemma 3 270M Locally
Several frameworks support Gemma 3 270M, each offering unique strengths. Hugging Face Transformers provides flexibility for Python scripting and integration. LM Studio offers a user-friendly interface for model management.
Additionally, llama.cpp enables efficient C++-based inference, perfect for low-level optimization. For Apple devices, MLX optimizes performance on M-series chips. You select based on your expertise; beginners prefer LM Studio, while developers lean toward Transformers.
Thus, these tools democratize access. In the following sections, follow step-by-step guides for popular methods.
Step-by-Step Guide: Running Gemma 3 270M with Hugging Face Transformers
You start by installing the necessary libraries. Open your terminal and execute:
pip install transformers torch
This command fetches Transformers and PyTorch. Next, import the components in a Python script:
from transformers import AutoTokenizer, AutoModelForCausalLM
Load the model and tokenizer:
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
The device_map="auto" places the model on GPU if available. Prepare your input:
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
Generate output:
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
This produces a coherent explanation. To optimize, add quantization:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Quantization reduces memory usage. You handle errors by ensuring Hugging Face login for gated models:
from huggingface_hub import login
login(token="your_hf_token")
Obtain the token from your Hugging Face account. With this setup, you run inferences repeatedly. However, for non-Python users, consider LM Studio next.
Step-by-Step Guide: Running Gemma 3 270M with LM Studio
LM Studio provides an intuitive interface. Download it from lmstudio.ai and install.
Launch the app, then search for "gemma-3-270m" in the model hub.
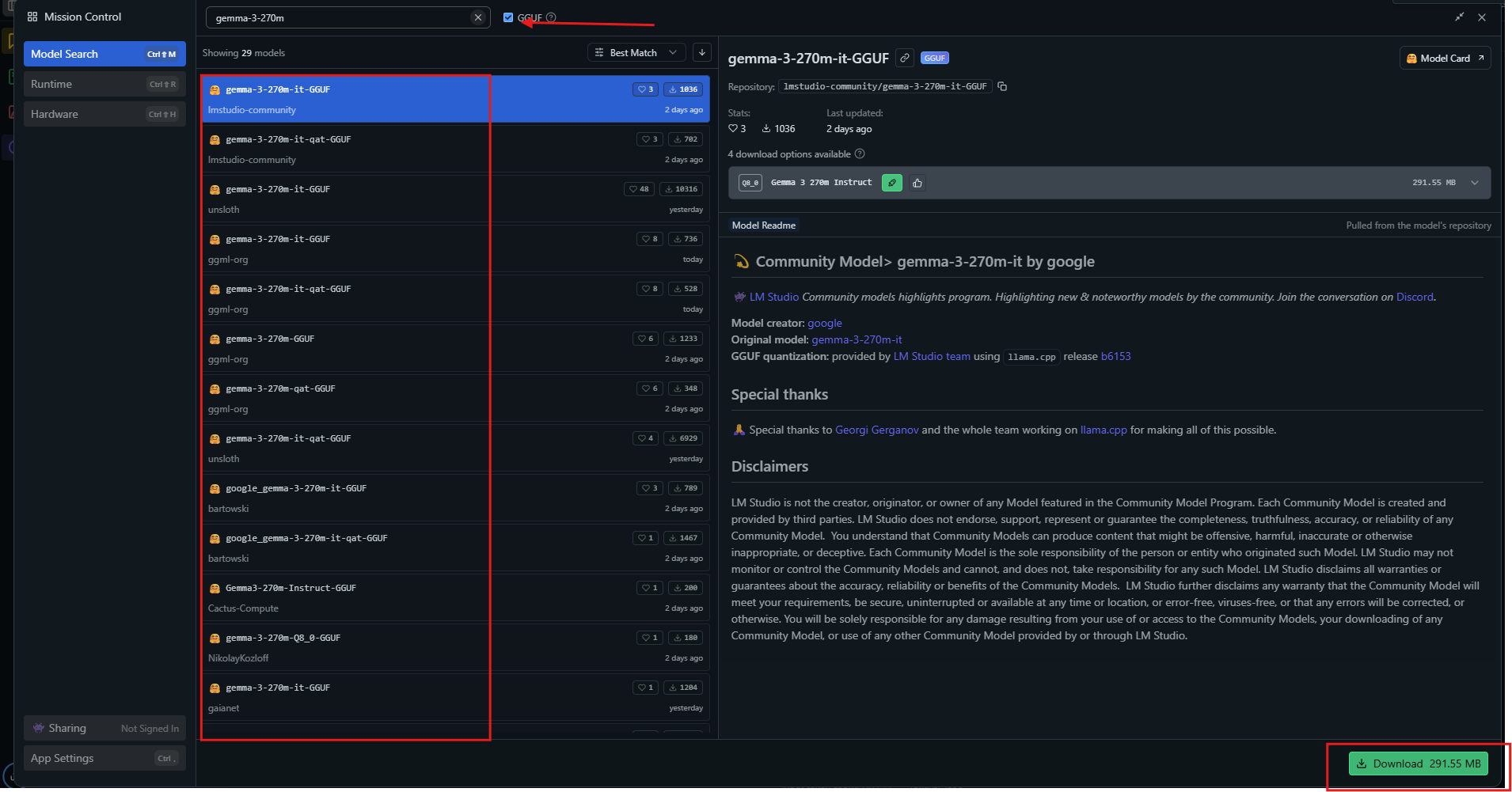
Select a quantized variant like Q4_0 and download. Once ready, load the model from the sidebar. Adjust settings: set context to 32k, temperature to 1.0.
Enter a prompt in the chat window and hit send. LM Studio displays responses with token speeds. Export chats or fine-tune via integrated tools.
For advanced use, enable GPU offloading in settings. LM Studio automatically selects optimal sources, ensuring compatibility. This method suits visual learners. Additionally, explore llama.cpp for performance tweaks.
Step-by-Step Guide: Running Gemma 3 270M with llama.cpp
llama.cpp offers high-efficiency inference. Clone the repository:
git clone https://github.com/ggerganov/llama.cpp
Build it:
make -j
Download GGUF files from Hugging Face:
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
Run inference:
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
Specify parameters like --n-gpu-layers 999 for full GPU use. llama.cpp supports quantization levels, balancing speed and accuracy. You compile with CUDA for NVIDIA GPUs:
make GGML_CUDA=1
This accelerates processing. llama.cpp excels in embedded systems. Now, apply the model in practical examples.
Practical Examples of Using Gemma 3 270M Locally
You create a sentiment analyzer. Input customer reviews, and the model classifies them as positive or negative. Script it in Python:
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M outputs "Positive." Extend to summarization:
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
It condenses content effectively. For question answering, query:
"What causes climate change?"
The model explains greenhouse gases. In healthcare, extract entities from notes. These uses demonstrate versatility. Furthermore, fine-tune for specialization.
Fine-Tuning Gemma 3 270M Locally
Fine-tuning adapts the model. Use Hugging Face's PEFT library:
pip install peft
Load with LoRA config:
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
Prepare a dataset, then train:
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA requires little data, finishing quickly on modest hardware. Save and reload the adapter. This boosts performance on custom tasks like chess move prediction. However, monitor overfitting.
Performance Optimization Tips for Gemma 3 270M
You maximize speed by quantizing to 4-bit or 8-bit. Use batching for multiple inferences. Set temperature to 1.0, top_k=64, top_p=0.95 as recommended.
On GPUs, enable mixed precision. For long contexts, manage KV cache carefully. Monitor VRAM with tools like nvidia-smi. Update libraries regularly for optimizations.
Consequently, these tweaks yield over 130 tokens per second on suitable hardware. Avoid common pitfalls like double BOS tokens in prompts. With practice, you achieve efficient runs.
Conclusion
You now possess the knowledge to run Gemma 3 270M locally. From setup to optimization, each step builds capability. Experiment, fine-tune, and deploy to realize its potential. Small models like this make big impacts in AI accessibility.