Cogito models, launched by DeepCogito, have quickly gained attention in the AI community for their remarkable ability to outperform established models like LLaMA and DeepSeek across various scales. These open-source models, ranging from 3B to 70B parameters, provide developers with a powerful tool to explore general superintelligence directly on their local machines.
What You Need to Know About Cogito and Ollama
Cogito represents a series of open-source AI models developed by the DeepCogito team, with a clear focus on achieving general superintelligence. These models leverage a technique called iterated distillation and amplification (IDA), which iteratively enhances the model’s reasoning capabilities by using more computation to arrive at better solutions and then distilling that process into the model’s parameters. Available in sizes such as 3B, 8B, 14B, 32B, and 70B, Cogito models are set to expand further with upcoming releases of 109B and 400B parameter models.

On the other hand, Ollama is a versatile framework that enables developers to run LLMs locally on their machines, eliminating the need for cloud-based APIs. Supporting multiple platforms like MacOS, Windows, and Linux, Ollama ensures accessibility for a wide range of users. By running Cogito locally with Ollama, you can experiment with advanced AI models on-device, which not only saves costs but also enhances data privacy for sensitive applications.

Why Run Cogito Locally?
Running Cogito locally offers several advantages for developers. First, it eliminates the dependency on external APIs, which reduces latency and ensures that your data remains private. This is particularly important for applications where data security is a priority. Moreover, Cogito models have demonstrated superior performance compared to competitors like LLaMA 4 Scout, even at smaller scales, making them an excellent choice for high-performance tasks.

Local execution is also ideal for developers working in resource-constrained environments or areas with limited internet access, as it allows for seamless operation without connectivity. Additionally, Ollama’s straightforward command-line interface simplifies the process of managing and running multiple models, including Cogito. Finally, a local setup enables faster iteration during development, especially when testing API integrations, which can be efficiently managed using tools like Apidog to design and debug your endpoints.
Prerequisites for Running Cogito with Ollama
Before diving into the setup process, ensure that your system meets the necessary requirements. For smaller models like the 3B or 8B parameter versions, your machine should have at least 16GB of RAM, while larger models like the 70B may require 64GB or more to run smoothly. A compatible GPU, such as an NVIDIA card with CUDA support, is highly recommended as it significantly accelerates model inference.
You’ll also need to install Python 3.8 or higher, as it’s a dependency for Ollama’s Python library and other related tools.
Next, download and install Ollama from its official website or GitHub repository, following the instructions specific to your operating system. Storage is another critical factor—Cogito models can range from a few gigabytes for the 3B model to over 100GB for the 70B model, so ensure your system has sufficient space. Lastly, if you plan to integrate Cogito with APIs, having Apidog installed will help you design and test your API endpoints efficiently, ensuring a smooth development experience.
Step 1: Install Ollama on Your Machine
The first step in running Cogito locally is to install Ollama on your machine. Start by visiting the Ollama website or GitHub page to download the installer for your operating system. For MacOS and Windows users, simply run the installer and follow the on-screen prompts to complete the setup. If you’re using Linux, you can install Ollama directly by executing the command :
curl -fsSL https://ollama.com/install.sh | sh in your terminal.
Once the installation is complete, open a terminal and type ollama --version to confirm that Ollama has been installed correctly.

To ensure Ollama is running, execute ollama serve, which starts the local server for model management. This step also sets up Ollama’s command-line interface, which you’ll use to pull and run models like Cogito in the following steps.
Step 2: Pull the Cogito Model from Ollama’s Library
With Ollama installed, the next step is to download the Cogito model. Open your terminal and run the command ollama pull cogito to fetch the Cogito model from Ollama’s library.

By default, this command pulls the latest version of the Cogito model, but you can specify a particular size by using a tag, such as ollama pull cogito:3b for the 3B parameter model. You can explore the available model sizes on https://ollama.com/library/cogito.
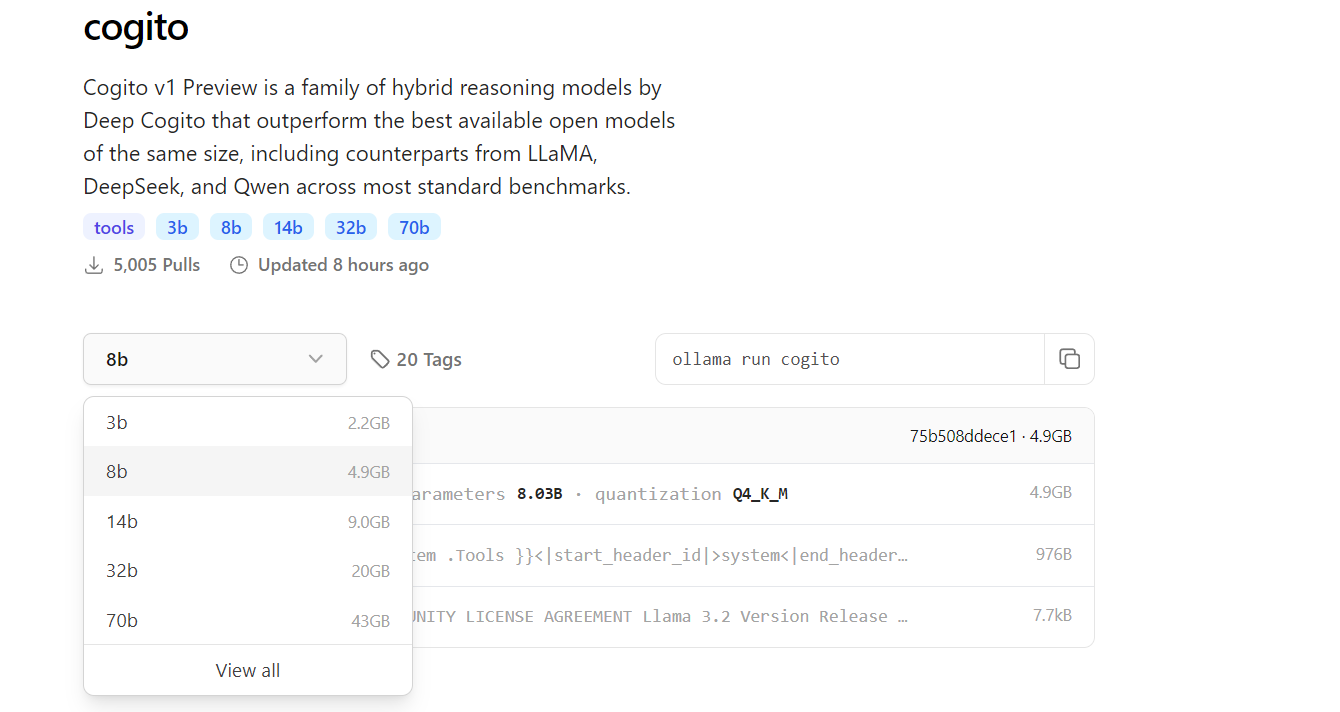
Depending on your internet speed and the model size, the download process may take some time—expect around 2.2GB for the 3B model and up to 43GB for the 70B model. After the download completes, verify that the model is available on your system by running ollama list, which displays all installed models. At this point, Cogito is ready to be run locally, and you can move on to the next step.

Step 3: Run Cogito Locally with Ollama
Now that the model is downloaded, you can start running Cogito on your machine. In your terminal, execute the command ollama run cogito to launch the Cogito model.

Step 4: Enhance API Testing with Apidog
Cogito excels at generating API code, but testing those APIs is crucial. Apidog simplifies this process:
Install Apidog:
Download and install Apidog from its official site.
Test the Generated API:
Take the Flask endpoint from earlier. In Apidog:
- Create a new request.
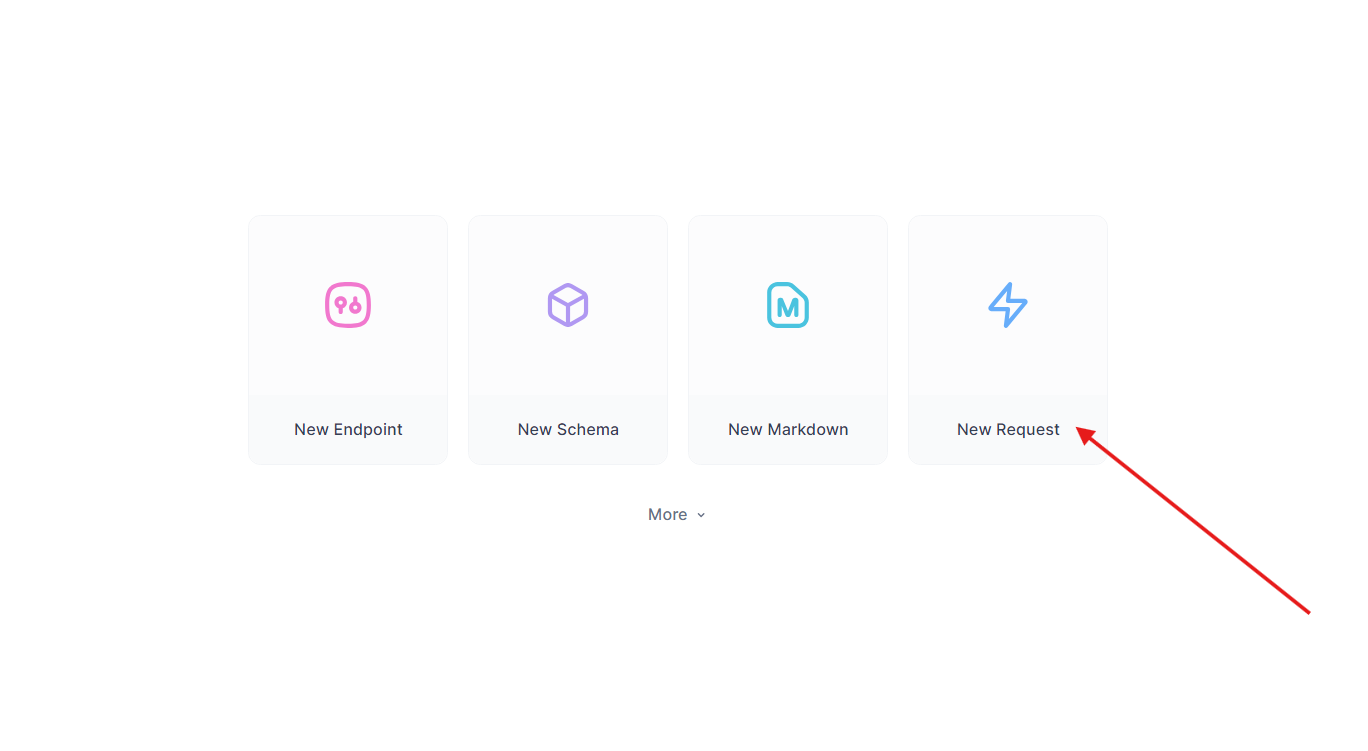
- Set the URL to
http://localhost:5000/api/dataand Send a GET request.
- Verify the response:
{"message": "Hello, World!"}.
Automate Testing:
Use Apidog’s scripting to automate validation, ensuring DeepCoder’s output meets expectations.
Apidog bridges the gap between code generation and deployment, enhancing productivity.
Troubleshooting Common Issues
Running Cogito locally may occasionally present challenges, but most issues can be resolved with a few checks. If Ollama fails to start, verify that no other process is using port 11434—you can either kill the conflicting process or change the port in Ollama’s configuration. For “out of memory” errors, consider reducing the model size or increasing your system’s swap space to accommodate larger models. If the model doesn’t respond, ensure that you’ve pulled it correctly using ollama pull cogito and that it appears in the ollama list output. Slow inference times often indicate that you’re running on CPU-only—check GPU support by running nvidia-smi to confirm that CUDA is active.
When using Apidog for API integration, errors may arise from incorrect JSON payloads, so double-check your schema in Apidog’s editor. For more detailed diagnostics, review Ollama’s logs at ~/.ollama/logs to identify and resolve issues quickly.
Conclusion
Running Cogito locally with Ollama opens up a world of possibilities for developers looking to explore general superintelligence. By following the steps outlined in this guide, you can set up Cogito on your machine, optimize its performance, and even integrate it into larger applications using APIs managed with Apidog. Whether you’re building a RAG system, a coding assistant, or a web application, Cogito’s advanced capabilities make it a powerful tool for innovation. As the DeepCogito team continues to release larger models and refine their techniques, the potential for local AI development will only grow, empowering developers to create groundbreaking solutions.