Unlock powerful document search and Q&A capabilities by building your own Retrieval-Augmented Generation (RAG) pipeline for PDFs—entirely on your local machine. In this guide, you'll learn how to leverage DeepSeek R1 and Ollama for fast, private, and cost-effective document intelligence, perfect for API and backend engineers handling technical manuals, specs, or knowledge bases.
Looking for a unified way to manage, test, and mock APIs?
Try Apidog—the all-in-one platform designed for API professionals. Apidog streamlines API creation, testing, and automation, helping teams maintain reliability and accelerate development.
Why Choose DeepSeek R1 with Ollama for Local RAG?
For developers working with confidential docs or seeking faster API prototype feedback, running a local RAG system delivers:
- Zero cost: Both DeepSeek R1 and Ollama are free and open source
- Full privacy: No data leaves your machine
- Low hardware requirements: 16GB RAM is sufficient for the 1.5B model
Cost Breakdown:
| Component | Cost |
|---|---|
| DeepSeek R1 1.5B | Free |
| Ollama | Free |
| 16GB RAM PC | $0 |
DeepSeek R1’s 1.5B parameter model stands out with:
- Efficient retrieval: Only the top 3 document chunks are used per answer
- Strict grounding: Prompts that prevent hallucination (“I don’t know” when unsure)
- Instant response: Local execution means near-zero latency
Prerequisites: What You'll Need
1. Ollama: Run AI Models Locally
Ollama is a lightweight framework for running large language models like DeepSeek R1 on your machine.
- Download: https://ollama.com/
- Install Ollama, then open your terminal and run:
ollama run deepseek-r1 # Runs the 7B model by default
Curious how to run DeepSeek R1 locally and test its API with Apidog?
Check out our step-by-step guide to get started—no cloud dependencies required.
Apidog BlogAshley Innocent

2. DeepSeek R1 Model Variants
DeepSeek R1 is available in sizes from 1.5B to 671B parameters. For most local use cases:
ollama run deepseek-r1:1.5b
- Tip: Larger models (e.g., 70B) offer more advanced reasoning but need more RAM. Start small and scale as needed.

Step-by-Step: Building Your PDF Question-Answering RAG Pipeline
1. Import Required Libraries
We'll use:
- LangChain: For document processing, chunking, and retrieval
- Streamlit: For a simple web interface
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
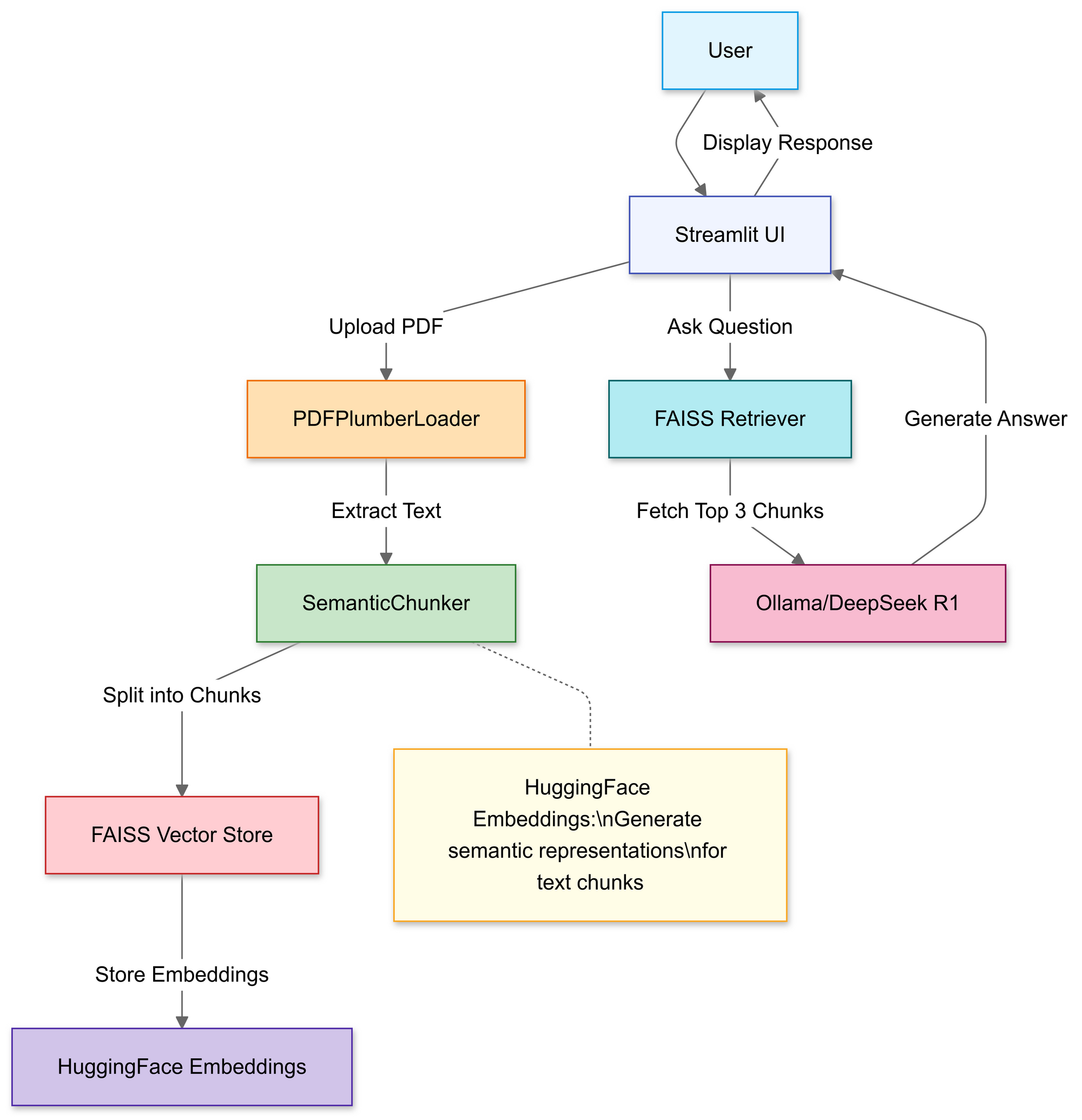
Diagram: LangChain + Streamlit workflow
2. Upload and Process PDF Files
Allow users to upload a PDF file through Streamlit:
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
This extracts text from your PDF, preparing it for semantic chunking.
3. Chunk Documents for Accurate Retrieval
Why semantic chunking?
Effective chunking keeps related information together and avoids fragmenting tables or diagrams. This increases answer relevance and reduces hallucination.
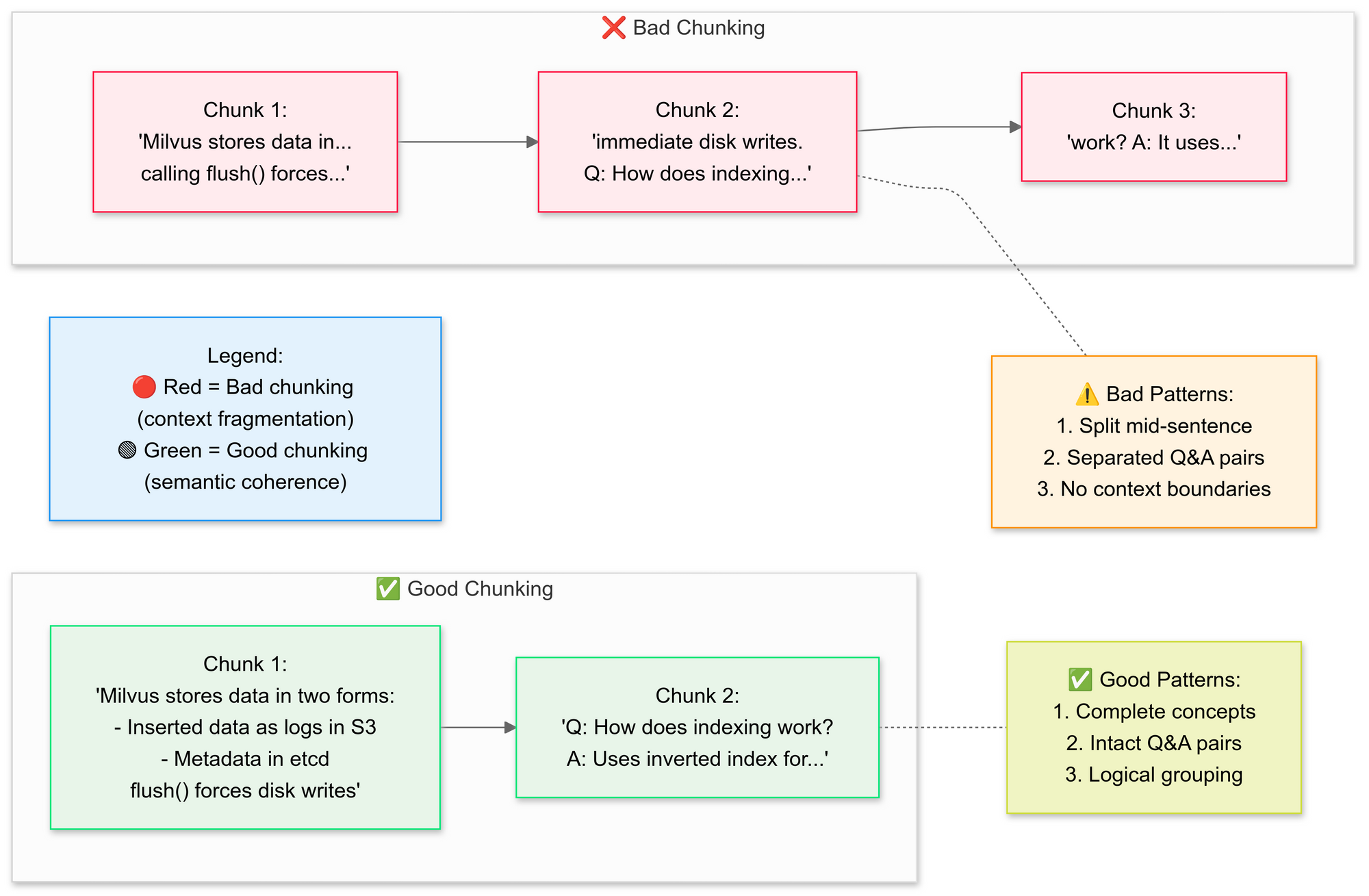
Visual: Bad vs. good chunking comparison
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
- Groups related sentences (e.g., "How Milvus stores data" remains intact)
- Preserves context by overlapping chunks slightly
4. Create a Searchable Vector Knowledge Base
Convert document chunks to vector embeddings and store them in a FAISS index:
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Top 3 chunks
This enables efficient similarity search—critical for question-answering.
5. Configure DeepSeek R1 as Your Local LLM
Integrate DeepSeek R1 with LangChain’s RetrievalQA chain:
llm = Ollama(model="deepseek-r1:1.5b")
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don’t know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
This prompt template keeps answers grounded in your PDF’s content.
6. Assemble the Retrieval-Augmented Generation (RAG) Pipeline
Tie everything together for seamless Q&A:
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
7. Build an Interactive Web Interface
Let users interactively ask questions about their PDF:
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)
- Users type questions
- The pipeline retrieves relevant chunks and generates an answer, grounded in the document
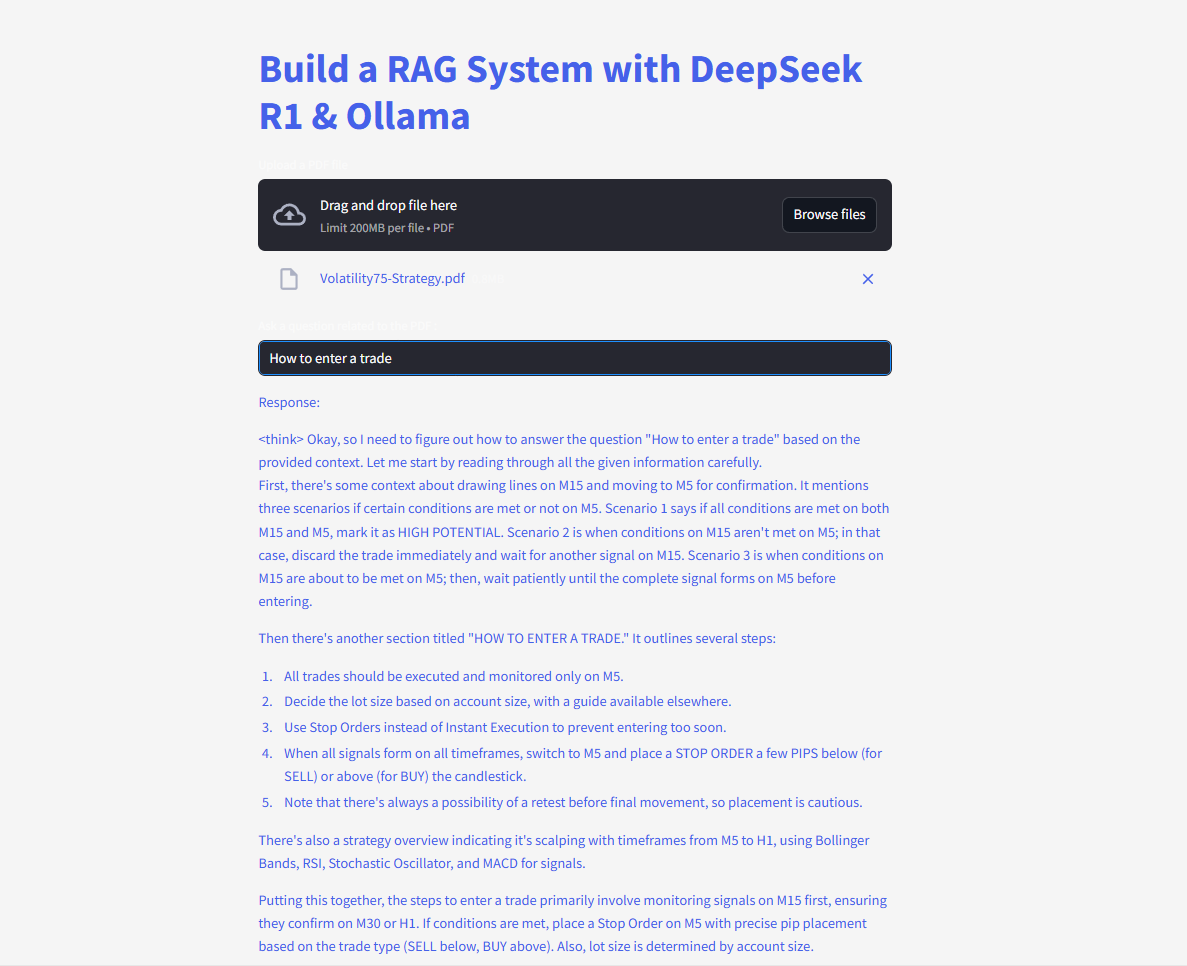
Complete Example Code
You can assemble the above steps into a single Streamlit app for instant PDF Q&A.
Future Directions: Advanced RAG with DeepSeek
DeepSeek R1 is evolving rapidly with self-verification and multi-hop reasoning on the horizon. This means even more trustworthy and nuanced answers for technical documentation and API references.
Tip for API Teams:
Automating knowledge retrieval from internal docs makes onboarding, QA, and support much smoother. Combine this RAG pipeline with Apidog’s workflow automation to maximize productivity—manage your APIs and documentation queries all in one place.