
Large language models (LLMs) like Qwen3 are revolutionizing the AI landscape with their impressive capabilities in coding, reasoning, and natural language understanding. Developed by the Qwen team at Alibaba, Qwen3 offers quantized models that enable efficient local deployment, making it accessible for developers, researchers, and enthusiasts to run these powerful models on their own hardware. Whether you're using Ollama, LM Studio, or vLLM, this guide will walk you through the process of setting up and running Qwen3 quantized models locally.
In this technical guide, we’ll explore the setup process, model selection, deployment methods, and API integration. Let’s get started.
What Are Qwen3 Quantized Models?
Qwen3 is the latest generation of LLMs from Alibaba, designed for high performance across tasks like coding, math, and general reasoning. Quantized models, such as those in BF16, FP8, GGUF, AWQ, and GPTQ formats, reduce the computational and memory requirements, making them ideal for local deployment on consumer-grade hardware.
The Qwen3 family includes various models:
- Qwen3-235B-A22B (MoE): A mixture-of-experts model with BF16, FP8, GGUF, and GPTQ-int4 formats.
- Qwen3-30B-A3B (MoE): Another MoE variant with similar quantization options.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Dense models available in BF16, FP8, GGUF, AWQ, and GPTQ-int8 formats.
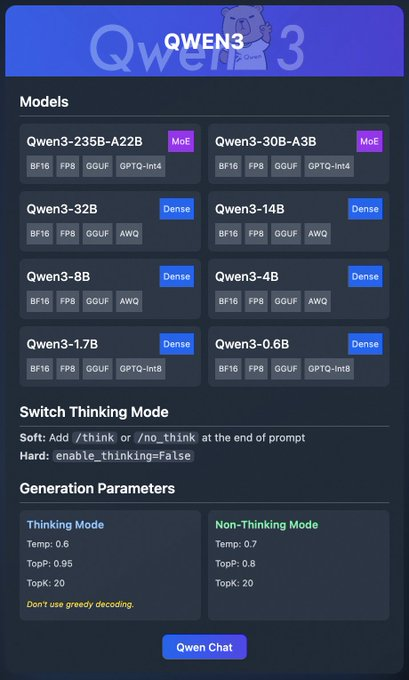
These models support flexible deployment through platforms like Ollama, LM Studio, and vLLM, which we’ll cover in detail. Additionally, Qwen3 offers features like "thinking mode," which can be toggled for better reasoning, and generation parameters to fine-tune output quality.
Now that we understand the basics, let’s move on to the prerequisites for running Qwen3 locally.
Prerequisites for Running Qwen3 Locally
Before deploying Qwen3 quantized models, ensure your system meets the following requirements:
Hardware:
- A modern CPU or GPU (NVIDIA GPUs are recommended for vLLM).
- At least 16GB of RAM for smaller models like Qwen3-4B; 32GB or more for larger models like Qwen3-32B.
- Sufficient storage (e.g., Qwen3-235B-A22B GGUF may require ~150GB).
Software:
- A compatible operating system (Windows, macOS, or Linux).
- Python 3.8+ for vLLM and API interactions.
- Docker (optional, for vLLM).
- Git for cloning repositories.
Dependencies:
- Install required libraries like
torch,transformers, andvllm(for vLLM). - Download Ollama or LM Studio binaries from their official websites.
With these prerequisites in place, let’s proceed to download the Qwen3 quantized models.
Step 1: Download Qwen3 Quantized Models
First, you need to download the quantized models from trusted sources. The Qwen team provides Qwen3 models on Hugging Face and ModelScope
- Hugging Face: Qwen3 Collection
- ModelScope: Qwen3 Collection
How to Download from Hugging Face
- Visit the Hugging Face Qwen3 collection.
- Select a model, such as Qwen3-4B in GGUF format for lightweight deployment.
- Click the "Download" button or use the
git clonecommand to fetch the model files:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Store the model files in a directory, such as
/models/qwen3-4b-gguf.
How to Download from ModelScope
- Navigate to the ModelScope Qwen3 collection.
- Choose your desired model and quantization format (e.g., AWQ or GPTQ).
- Download the files manually or use their API for programmatic access.
Once the models are downloaded, let’s explore how to deploy them using Ollama.
Step 2: Deploy Qwen3 Using Ollama
Ollama provides a user-friendly way to run LLMs locally with minimal setup. It supports Qwen3’s GGUF format, making it ideal for beginners.
Install Ollama
- Visit the official Ollama website and download the binary for your operating system.
- Install Ollama by running the installer or following the command-line instructions:
curl -fsSL https://ollama.com/install.sh | sh
- Verify the installation:
ollama --version
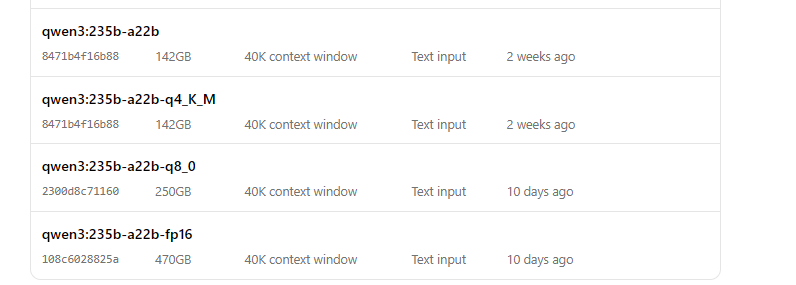
Run Qwen3 with Ollama
- Start the model:
ollama run qwen3:235b-a22b-q8_0- Once the model is running, you can interact with it via the command line:
>>> Hello, how can I assist you today?
Ollama also provides a local API endpoint (typically http://localhost:11434) for programmatic access, which we’ll test later using Apidog.
Next, let’s explore how to use LM Studio for running Qwen3.
Step 3: Deploy Qwen3 Using LM Studio
LM Studio is another popular tool for running LLMs locally, offering a graphical interface for model management.
Install LM Studio
- Download LM Studio from its official website.
- Install the application by following the on-screen instructions.
- Launch LM Studio and ensure it’s running.
Load Qwen3 in LM Studio
In LM Studio, go to the "Local Models" section.
Click "Add Model" and search the model to download it:
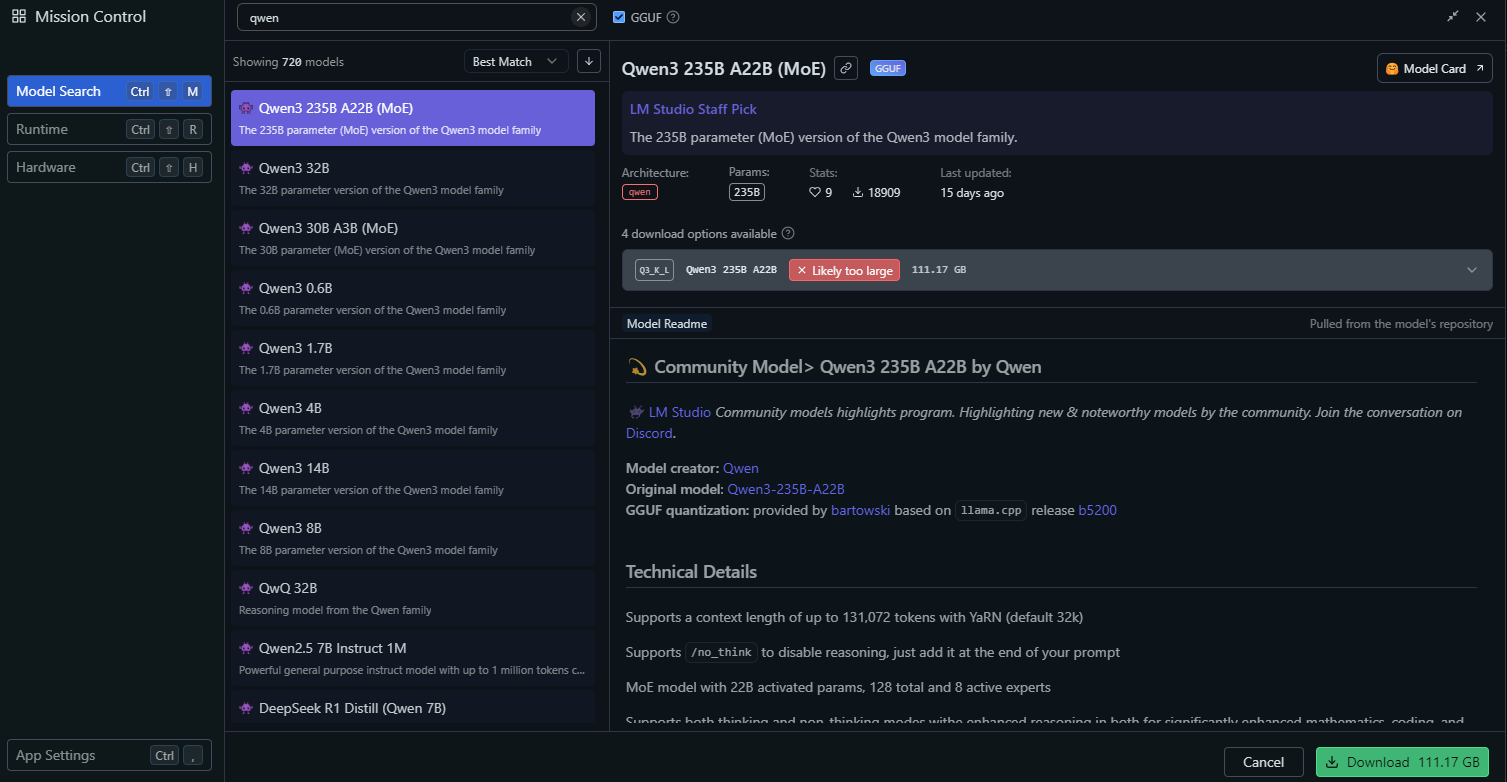
Configure the model settings, such as:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
These settings match Qwen3’s recommended thinking mode parameters.
Start the model server by clicking "Start Server." LM Studio will provide a local API endpoint (e.g., http://localhost:1234).
Interact with Qwen3 in LM Studio
- Use LM Studio’s built-in chat interface to test the model.
- Alternatively, access the model via its API endpoint, which we’ll explore in the API testing section.
With LM Studio set up, let’s move on to a more advanced deployment method using vLLM.
Step 4: Deploy Qwen3 Using vLLM
vLLM is a high-performance serving solution optimized for LLMs, supporting Qwen3’s FP8 and AWQ quantized models. It’s ideal for developers building robust applications.
Install vLLM
- Ensure Python 3.8+ is installed on your system.
- Install vLLM using pip:
pip install vllm
- Verify the installation:
python -c "import vllm; print(vllm.__version__)"
Run Qwen3 with vLLM
Start a vLLM server with your Qwen3 model
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"The --enable-thinking=False flag disables Qwen3’s thinking mode.
Once the server starts, it will provide an API endpoint at http://localhost:8000.
Configure vLLM for Optimal Performance
vLLM supports advanced configurations, such as:
- Tensor Parallelism: Adjust
--tensor-parallel-sizebased on your GPU setup. - Context Length: Qwen3 supports up to 32,768 tokens, which can be set via
--max-model-len 32768. - Generation Parameters: Use the API to set
temperature,top_p, andtop_k(e.g., 0.7, 0.8, 20 for non-thinking mode).
With vLLM running, let’s test the API endpoint using Apidog.
Step 5: Test Qwen3 API with Apidog
Apidog is a powerful tool for testing API endpoints, making it perfect for interacting with your locally deployed Qwen3 model.
Set Up Apidog
- Download and install Apidog from the official website.
- Launch Apidog and create a new project.
Test Ollama API
- Create a new API request in Apidog.
- Set the endpoint to
http://localhost:11434/api/generate. - Configure the request:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Send the request and verify the response.
Test vLLM API
- Create another API request in Apidog.
- Set the endpoint to
http://localhost:8000/v1/completions. - Configure the request:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Send the request and check the output.
Apidog makes it easy to validate your Qwen3 deployment and ensure the API is functioning correctly. Now, let’s fine-tune the model’s performance.
Step 6: Fine-Tune Qwen3 Performance
To optimize Qwen3’s performance, adjust the following settings based on your use case:
Thinking Mode
Qwen3 supports a "thinking mode" for enhanced reasoning, as highlighted in the X post image. You can control it in two ways:
- Soft Switch: Add
/thinkor/no_thinkto your prompt.
- Example:
Solve this math problem /think.
- Hard Switch: Disable thinking entirely in vLLM with
--enable-thinking=False.
Generation Parameters
Fine-tune the generation parameters for better output quality:
- Temperature: Use 0.6 for thinking mode or 0.7 for non-thinking mode.
- Top-P: Set to 0.95 (thinking) or 0.8 (non-thinking).
- Top-K: Use 20 for both modes.
- Avoid greedy decoding, as recommended by the Qwen team.
Experiment with these settings to achieve the desired balance between creativity and accuracy.
Troubleshooting Common Issues
While deploying Qwen3, you may encounter some issues. Here are solutions to common problems:
Model Fails to Load in Ollama:
- Ensure the GGUF file path in the
Modelfileis correct. - Check if your system has enough memory to load the model.
vLLM Tensor Parallelism Error:
- If you see an error like "output_size is not divisible by weight quantization block_n," reduce the
--tensor-parallel-size(e.g., to 4).
API Request Fails in Apidog:
- Verify that the server (Ollama, LM Studio, or vLLM) is running.
- Double-check the endpoint URL and request payload.
By addressing these issues, you can ensure a smooth deployment experience.
Conclusion
Running Qwen3 quantized models locally is a straightforward process with tools like Ollama, LM Studio, and vLLM. Whether you’re a developer building applications or a researcher experimenting with LLMs, Qwen3 offers the flexibility and performance you need. By following this guide, you’ve learned how to download models from Hugging Face and ModelScope, deploy them using various frameworks, and test their API endpoints with Apidog.
Start exploring Qwen3 today and unlock the power of local LLMs for your projects!


