Alibaba's Qwen series continues to push boundaries in large language models, and Qwen3-Next-80B-A3B stands out as a prime example of efficiency meeting high performance. Engineers and developers seek models that deliver robust reasoning without the computational overhead of dense giants. This model addresses that demand head-on, boasting 80 billion parameters yet activating just 3 billion per token. Consequently, teams achieve faster inference speeds and reduced training expenses, making it ideal for real-world deployments.
In this post, you explore the core components of Qwen3-Next-80B-A3B, dissect its innovative architecture, review empirical performance data, and master its API through practical steps. Moreover, you integrate tools like Apidog to enhance your workflow. By the end, you possess the knowledge to deploy this model effectively in your applications.
What Defines Qwen3-Next-80B-A3B? Core Features and Innovations
Qwen3-Next-80B-A3B emerges from Alibaba's Qwen family as a sparse Mixture of Experts (MoE) model optimized for both speed and capability. Developers activate only a fraction of its parameters during inference, which translates to substantial resource savings. Specifically, this model employs an ultra-sparse MoE setup with 512 experts, routing to 10 per token alongside one shared expert. As a result, it rivals the performance of denser counterparts like Qwen3-32B while consuming far less power.
Furthermore, the model supports multi-token prediction, a technique that accelerates speculative decoding. This feature allows the model to generate multiple tokens simultaneously, boosting throughput in decoding stages. Builders appreciate this for applications requiring rapid responses, such as chatbots or real-time analytics tools.
The series includes variants tailored to specific needs: the base model for general pretraining, the instruct version for fine-tuned conversational tasks, and the thinking variant for advanced reasoning chains. For instance, Qwen3-Next-80B-A3B-Thinking excels in complex problem-solving, outperforming models like Gemini-2.5-Flash-Thinking on benchmarks. Additionally, it handles 119 languages, enabling multilingual deployments without retraining.
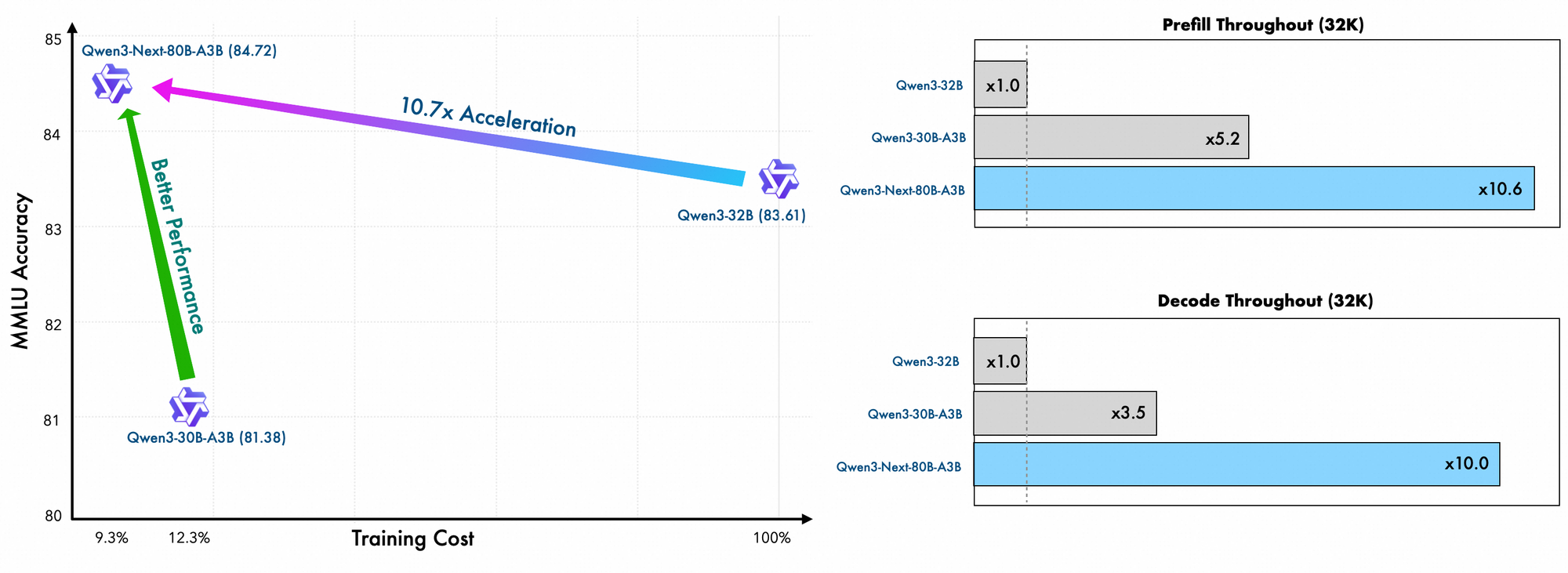
Training details reveal further efficiencies. Alibaba engineers pretrain this model using scaling-efficient methods, incurring only 10% of the cost compared to Qwen3-32B. They leverage a hybrid layout across 48 layers with a 2048 hidden dimension, ensuring balanced computation distribution. Consequently, the model demonstrates superior long-context understanding, maintaining accuracy beyond 32K tokens where others falter.
In practice, these features empower developers to scale AI solutions cost-effectively. Whether you build enterprise search engines or automated content generators, Qwen3-Next-80B-A3B provides the backbone for innovative applications. Building on this foundation, the next section examines the architectural elements that make such efficiencies possible.
Dissecting the Architecture of Qwen3-Next-80B-A3B: A Technical Blueprint
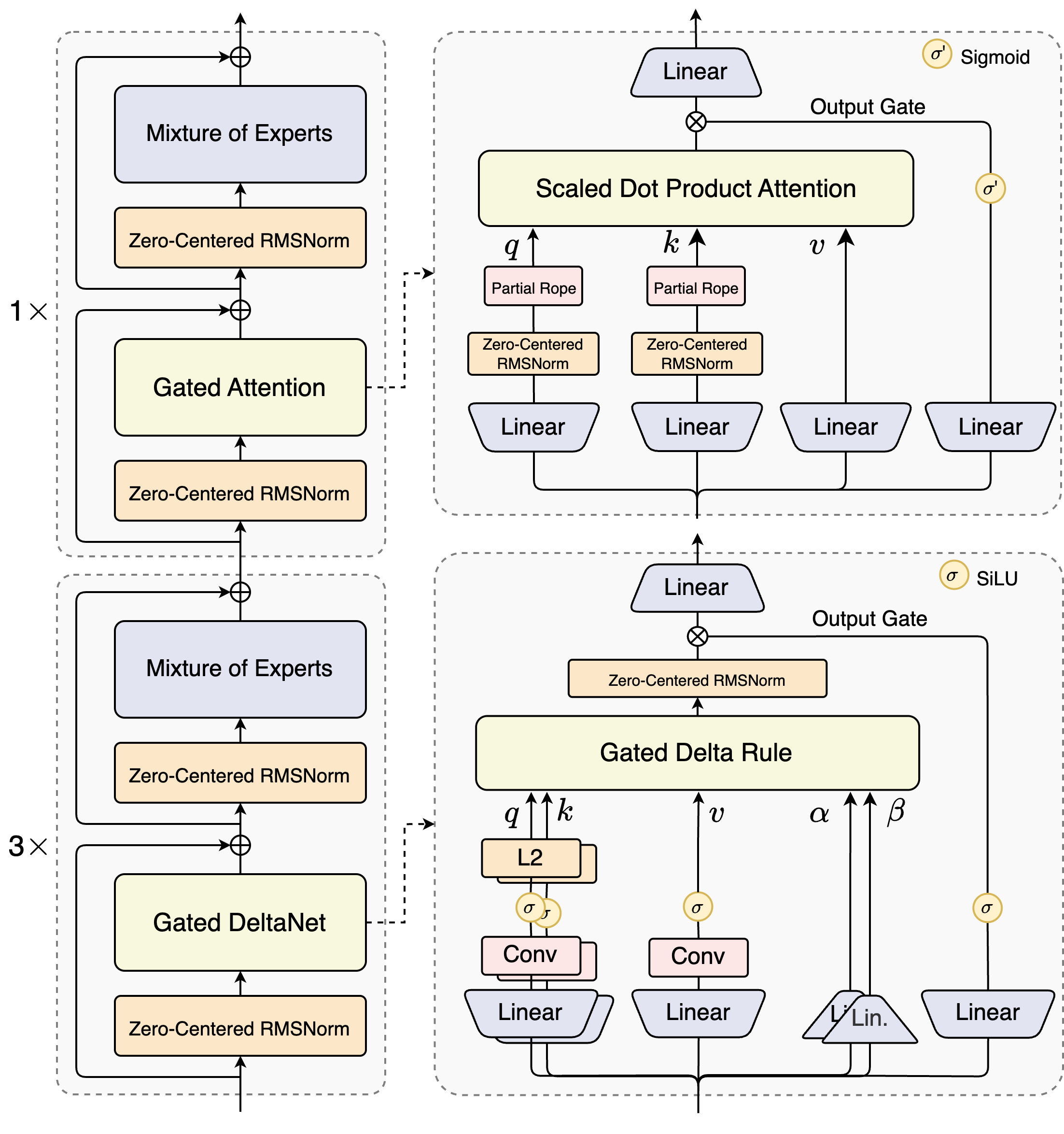
Architects of Qwen3-Next-80B-A3B introduce a hybrid design that combines gated mechanisms with advanced normalization techniques. At its heart lies a Mixture of Experts (MoE) layer, where experts specialize in distinct computational paths. The model routes inputs dynamically, activating a subset to minimize overhead. For example, the gated attention block processes queries, keys, and values through partial RoPE embeddings and zero-centered RMSNorm layers, enhancing stability in long sequences.
Consider the scaled dot-product attention module. It integrates linear projections followed by output gates modulated by sigmoid activations. This setup allows precise control over information flow, preventing dilution in high-dimensional spaces. Moreover, zero-centered RMSNorm precedes and follows these operations, centering activations around zero to mitigate gradient issues during training.
The diagram illustrates two primary blocks: the upper one focuses on gated attention with scaled dot-product attention, while the lower emphasizes gated DeltaNet. In the attention path (1x expansion), inputs flow through a zero-centered RMSNorm, then into the gated attention core. Here, query (q), key (k), and value (v) projections use partial RoPE for positional encoding. Post-attention, another RMSNorm and linear layers feed into the MoE, which employs a sigmoid-gated output.
Transitioning to the DeltaNet path (3x expansion), the architecture employs a gated Delta rule for refined predictions. It features L2 normalization on q and k, convolutional layers for local feature extraction, and SiLU activations for non-linearity. The output gate, combined with a linear projection, ensures coherent multi-token outputs. This block's design supports the model's speculative decoding, where it predicts several tokens ahead, verified in subsequent passes.
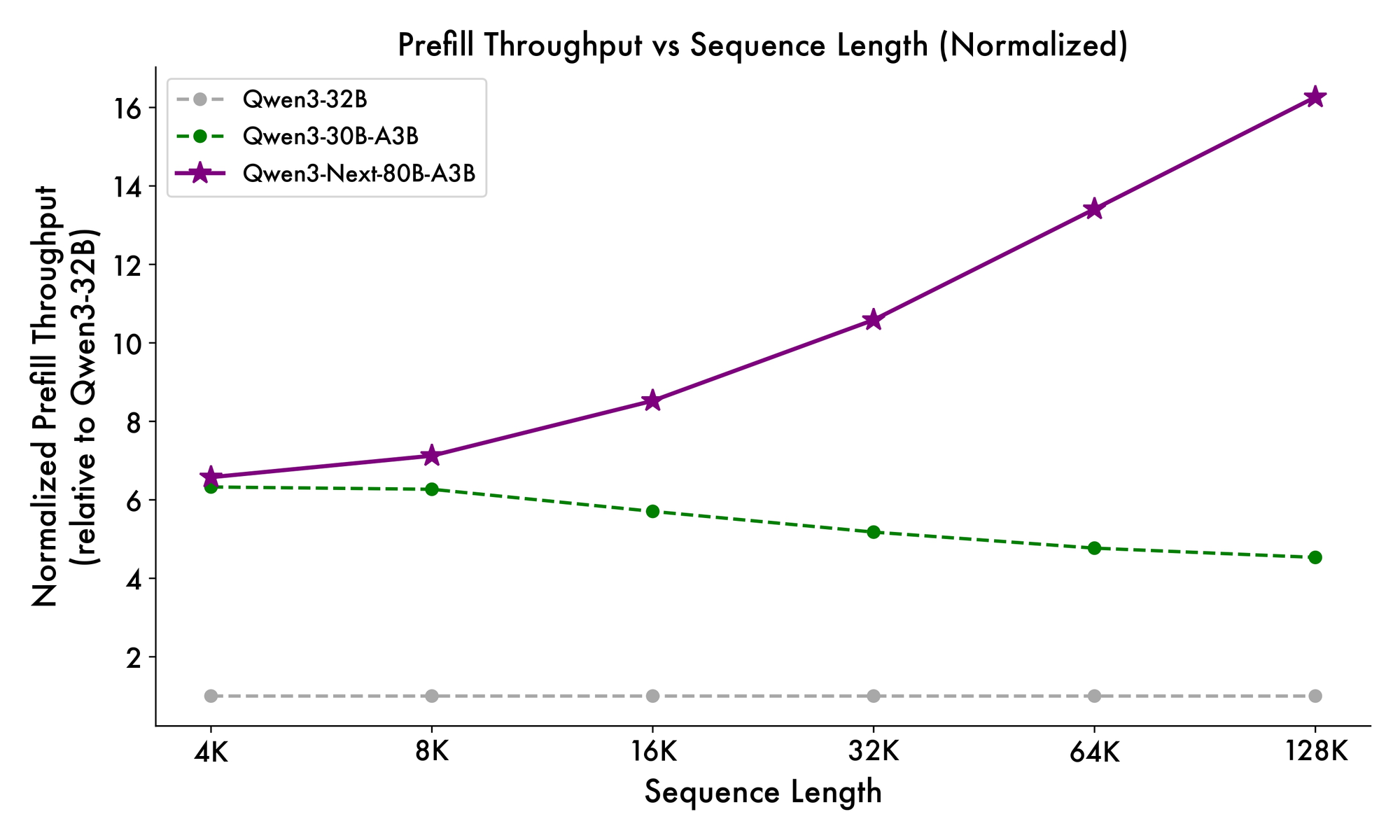
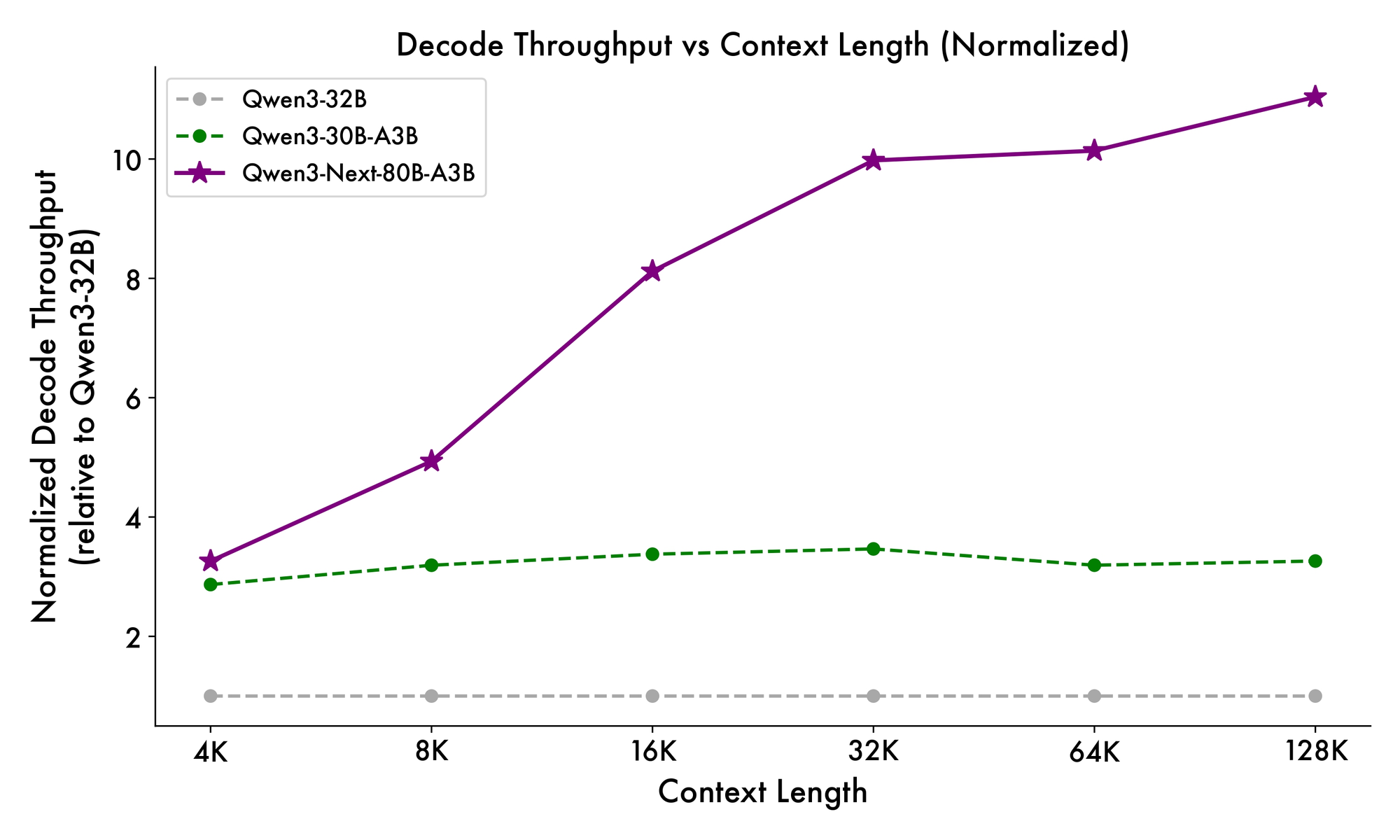
Furthermore, the overall structure incorporates a shared expert in the MoE to handle common patterns across tokens, reducing redundancy. Partial rope embeddings in projections preserve rotational invariance for extended contexts. As evidenced in benchmarks, this configuration yields nearly 7x higher throughput at 4K context lengths compared to Qwen3-32B. Beyond 32K tokens, speeds exceed 10x, making it suitable for document analysis or code generation tasks.
Developers benefit from this modularity when fine-tuning. You can swap experts or adjust routing thresholds to specialize the model for domains like finance or healthcare. In essence, the architecture not only optimizes compute but also fosters adaptability. With these insights, you now turn to how these elements translate into measurable performance gains.
Benchmarking Qwen3-Next-80B-A3B: Performance Metrics That Matter
Empirical evaluations position Qwen3-Next-80B-A3B as a leader in efficiency-driven AI. On standard benchmarks like MMLU and HumanEval, the base model surpasses Qwen3-32B despite using one-tenth the active parameters. Specifically, it achieves 78.5% on MMLU for general knowledge, edging out competitors by 2-3 points in reasoning subsets.
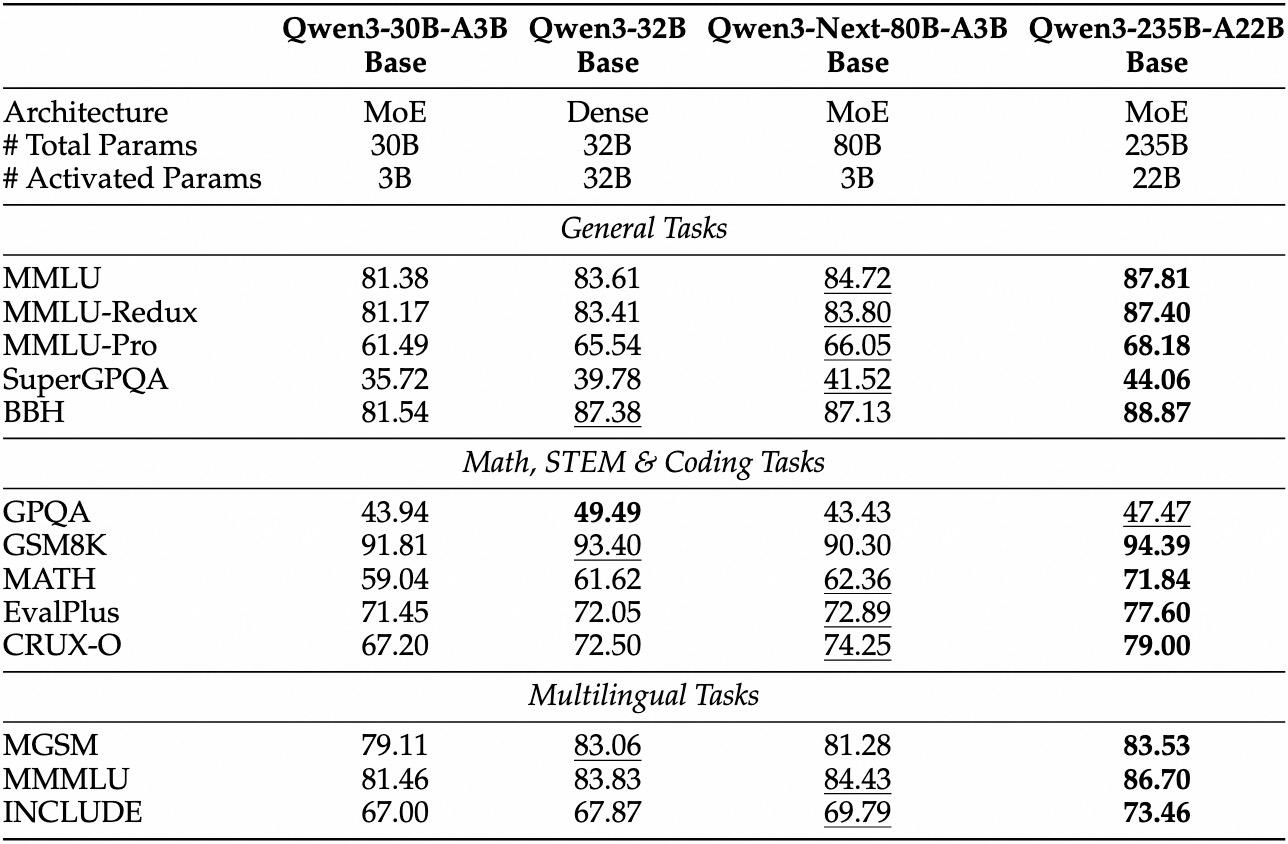
For the instruct variant, conversational tasks reveal strengths in instruction following. It scores 85% on MT-Bench, demonstrating coherent multi-turn dialogues. Meanwhile, the thinking model shines in chain-of-thought scenarios, attaining 92% on GSM8K for math problems—outperforming Qwen3-30B-A3B-Thinking by 4%.
Inference speed forms a cornerstone of its appeal. At 4K context, decode throughput reaches 4x that of Qwen3-32B, scaling to 10x at longer lengths. Prefill stages, critical for prompt processing, show 7x improvements, thanks to the sparse MoE. Power consumption drops accordingly, with training costs at 10% of denser models.
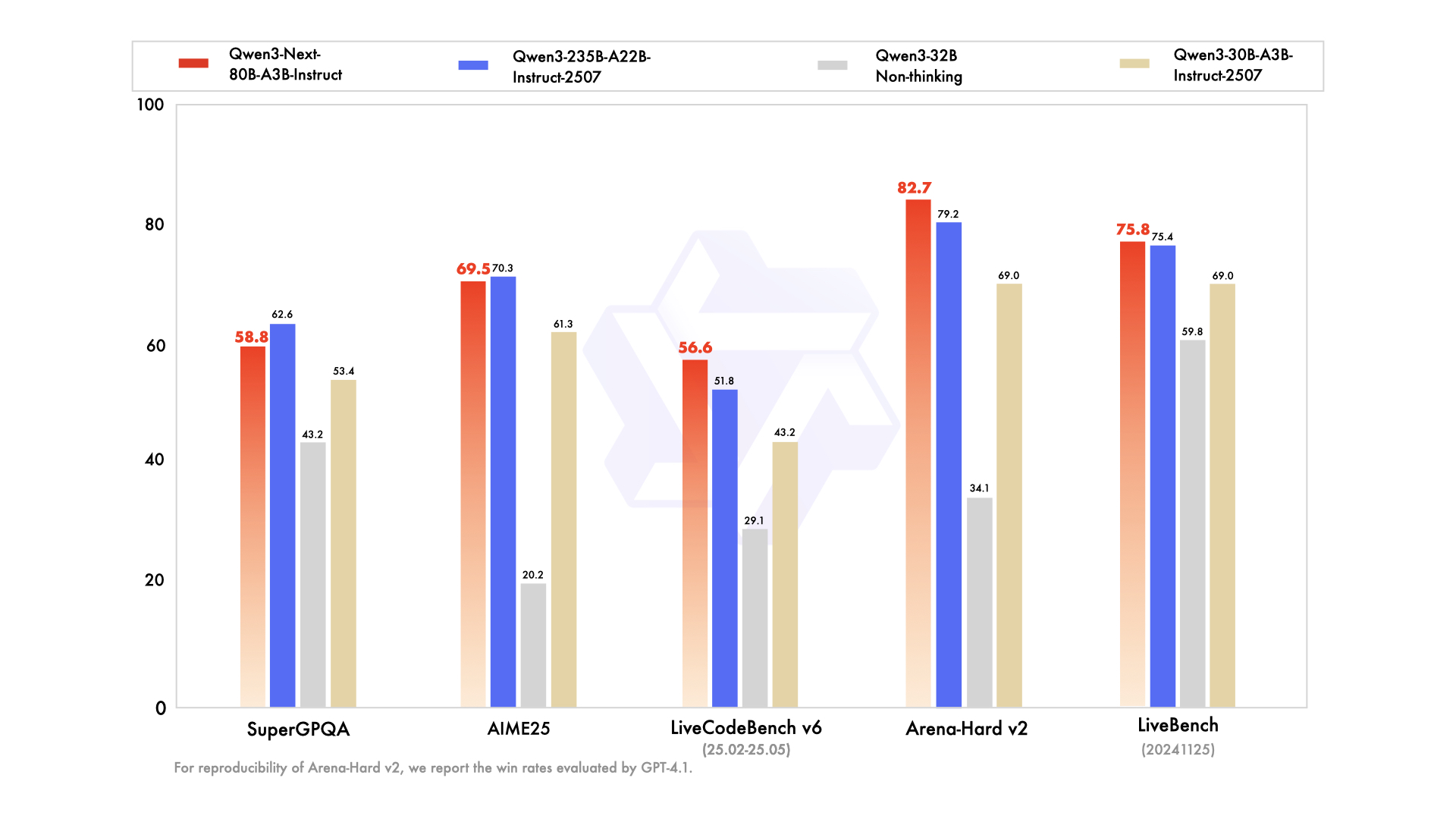
Comparisons to rivals highlight its edge. Against Llama 3.1-70B, Qwen3-Next-80B-A3B-Thinking leads in RULER (long-context recall) by 15%, recalling details from 128K tokens accurately. Versus DeepSeek-V2, it offers better multilingual support without sacrificing speed.

| Benchmark | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruct) | 81.9% | 83.5% |
This table underscores consistent outperformance. As a result, organizations adopt it for production, balancing quality and cost. Transitioning from theory to practice, you now equip yourself with API access tools.
Setting Up Access to the Qwen3-Next-80B-A3B API: Prerequisites and Authentication
Alibaba provides the Qwen API through DashScope, their cloud platform, ensuring seamless integration. First, create an Alibaba Cloud account and navigate to the Model Studio console. Select Qwen3-Next-80B-A3B from the model list—available in base, instruct, and thinking modes.
Obtain your API key from the dashboard under "API Keys." This key authenticates requests, with rate limits based on your tier (free tier offers 1M tokens/month). For OpenAI-compatible calls, set the base URL to https://dashscope.aliyuncs.com/compatible-mode/v1. Native DashScope endpoints use https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Install the Python SDK via pip: pip install dashscope. This library handles serialization, retries, and error parsing. Alternatively, use HTTP clients like requests for custom implementations.
Security best practices dictate storing keys in environment variables: export DASHSCOPE_API_KEY='your_key_here'. Consequently, your code remains portable across environments. With setup complete, you proceed to crafting your first API call.
Hands-On Guide: Using the Qwen3-Next-80B-A3B API with Python and DashScope
DashScope simplifies interactions with Qwen3-Next-80B-A3B. Begin with a basic generation request using the instruct variant for chat-like responses.
Here's a starter script:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
This code sends a prompt and retrieves up to 200 tokens. The model responds with a concise explanation, highlighting efficiency gains. For thinking mode, switch to 'qwen3-next-80b-a3b-thinking' and append reasoning instructions: "Think step-by-step before answering."
Advanced parameters enhance control. Set top_p=0.9 for nucleus sampling, or repetition_penalty=1.1 to avoid loops. For long contexts, specify max_context_length=131072 to leverage the model's 128K capability.
Handle streaming for real-time apps:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
This yields token-by-token output, ideal for UI integrations. Error handling includes checking response.code for quota issues (e.g., 10402 for insufficient balance).
Furthermore, function calling extends utility. Define tools in JSON schema:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
The model parses the intent and returns a tool call, which you execute externally. This pattern powers agentic workflows. With these examples, you build robust pipelines. Next, incorporate Apidog to test and refine these calls without coding every time.
Enhancing Your Workflow: Integrate Apidog for Qwen3-Next-80B-A3B API Testing
Apidog transforms API development into a streamlined process, particularly for AI endpoints like Qwen3-Next-80B-A3B. This platform combines design, mocking, testing, and documentation in one interface, powered by AI for intelligent automation.
Start by importing the DashScope schema into Apidog. Create a new project, add the endpoint POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation, and paste your API key as a header: X-DashScope-API-Key: your_key.
Design requests visually: Set the model parameter to 'qwen3-next-80b-a3b-instruct', input a prompt in the body as JSON {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}}. Apidog's AI suggests test cases, generating variations like edge-case prompts or high-temperature samples.
Run collections of tests sequentially. For instance, benchmark latency across temperatures:
- Test 1: Temperature 0.1, prompt length 100 tokens.
- Test 2: Temperature 1.0, context 10K tokens.
The tool tracks metrics—response time, token usage, error rates—and visualizes trends in dashboards. Mock responses for offline development: Apidog simulates Qwen outputs based on historical data, accelerating frontend builds.
Documentation generates automatically from your collections. Export OpenAPI specs with examples, including Qwen3-Next-80B-A3B specifics like MoE routing notes. Collaboration features allow teams to share environments, ensuring consistent testing.
In one scenario, a developer tests multilingual prompts. Apidog's AI detects inconsistencies, suggesting fixes like adding language hints. As a result, integration time drops by 40%, per user reports. For AI-specific testing, leverage its intelligent data generation: Input a schema, and it crafts realistic prompts mimicking production traffic.
Moreover, Apidog supports CI/CD hooks, running API tests in pipelines. Connect to GitHub Actions for automated validation post-deployment. This closed-loop approach minimizes bugs in Qwen-powered apps.
Advanced Strategies: Optimizing Qwen3-Next-80B-A3B API Calls for Production
Optimization elevates basic usage to enterprise-grade reliability. First, batch requests where possible—DashScope supports up to 10 prompts per call, reducing overhead for parallel tasks like summarization farms.
Monitor token economics: The model charges per active parameter, so concise prompts yield savings. Use the API's result_format='message' for structured outputs, parsing JSON directly to avoid post-processing.
For high availability, implement retries with exponential backoff:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
This handles transient errors like 429 rate limits. Scale horizontally by distributing calls across regions—DashScope offers Singapore and US endpoints.
Security considerations include input sanitization to prevent prompt injection. Validate user inputs against whitelists before forwarding to the API. Additionally, log responses anonymized for auditing, complying with GDPR.
In edge cases, like ultra-long contexts, chunk inputs and chain predictions. The thinking variant aids here: Prompt with "Step 1: Analyze section A; Step 2: Synthesize with B." This maintains coherence over 100K+ tokens.
Developers also explore fine-tuning via Alibaba's platform, though API users stick to prompt engineering. Consequently, these tactics ensure scalable, secure deployments.
Wrapping Up: Why Qwen3-Next-80B-A3B Deserves Your Attention
Qwen3-Next-80B-A3B redefines efficient AI with its sparse MoE, hybrid gates, and superior benchmarks. Developers harness its API via DashScope for rapid prototyping, enhanced by tools like Apidog for testing rigor.
You now hold the blueprint: from architectural nuances to production optimizations. Implement these insights to build faster, smarter systems. Experiment today— the future of scalable intelligence awaits.