
Alibaba releases Qwen3-Max, a flagship large language model that pushes boundaries in artificial intelligence capabilities. This model emerges from the Qwen series, known for its advancements in open foundation models aimed at artificial general intelligence. Developers and researchers now access a tool that excels in complex tasks, from coding challenges to multifaceted reasoning. As teams integrate Qwen3-Max through its API for real-world applications, efficient testing becomes essential.
Qwen3-Max scales to over one trillion parameters, trained on 36 trillion tokens—double that of Qwen2.5. It handles agentic tasks and follows instructions precisely. Although it starts without explicit thinking modes, upcoming features will add reasoning enhancements.
The model supports over 100 languages, expanding global use. Alibaba offers API access on its cloud, simplifying deployment.
Technical Specifications of Qwen3-Max
Alibaba designs Qwen3-Max with a focus on scalability and efficiency. The model boasts over one trillion parameters, positioning it among the largest AI models available via API. This immense size allows the system to process vast amounts of data during pre-training, resulting in robust pattern recognition and generation abilities. Engineers train Qwen3-Max on a dataset exceeding 36 trillion tokens, doubling the volume used in prior generations like Qwen2.5.

Qwen3-Max features a context window of 262,144 tokens, with a maximum input of 258,048 tokens and a maximum output of 65,536 tokens. This expansive context enables the model to handle long-form documents, extended conversations, and intricate problem-solving sequences without losing coherence. Developers benefit from this in applications like document analysis or multi-turn dialogues. However, the chat interface may impose apparent limitations, but the underlying model supports full capacity through API calls.
Qwen3-Max operates as a non-thinking instruct model in its initial release, prioritizing direct response generation. Alibaba plans to introduce reasoning features, including tool use and heavy mode deployment, which promise near-perfect benchmark scores. The architecture draws from the Qwen3 series, incorporating improvements in instruction following, reduced hallucinations, and enhanced multilingual support. For deployment, frameworks like vLLM and SGLang facilitate efficient serving, supporting tensor parallelism across multiple GPUs.
In terms of hardware requirements, Qwen3-Max demands substantial compute resources. Running it locally requires high-end setups, but API access mitigates this by leveraging Alibaba's cloud infrastructure. Pricing follows a tiered structure based on token volume: for 0–32K tokens, input costs $1.2 per million, output $6 per million; for 32K–128K, $2.4 and $12; and for 128K–252K, $3 and $15. New users receive a free quota of one million tokens valid for 90 days, encouraging experimentation.
Additionally, Qwen3-Max integrates with OpenAI-compatible APIs, simplifying migration from other providers. This compatibility extends to context caching, which optimizes repeated queries and reduces costs in production environments. Nevertheless, for stable operations, users select between latest and snapshot versions to manage rate limits effectively.
Benchmark Performance Analysis
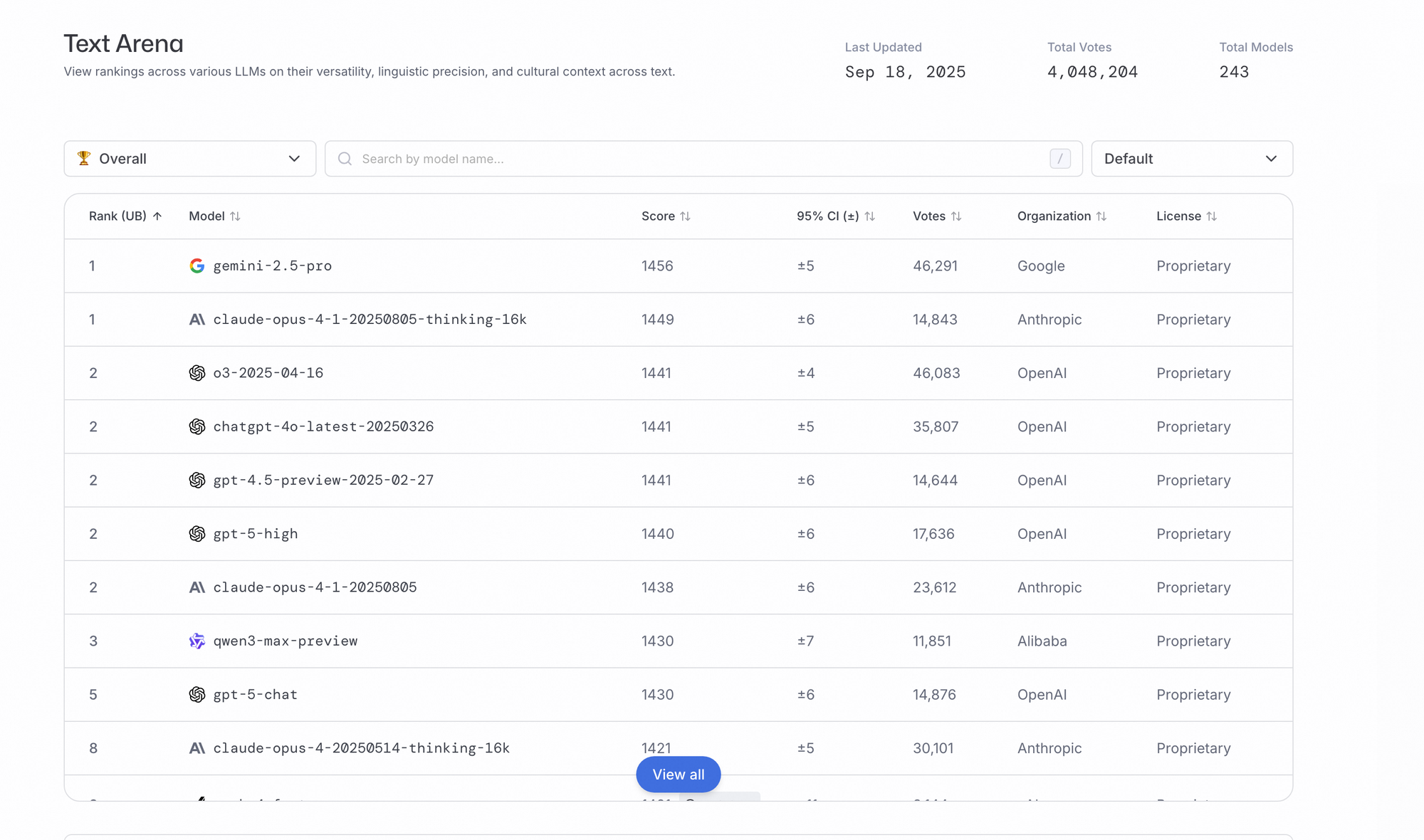
Qwen3-Max demonstrates exceptional results across multiple benchmarks, solidifying its position as a leader in AI performance. Alibaba evaluates the model on rigorous tests focused on coding, mathematics, and general reasoning. For instance, on SuperGPQA, Qwen3-Max-Instruct scores 65.1, surpassing Claude Opus 4 at 56.5 and DeepSeek-V3.1 at 43.9.
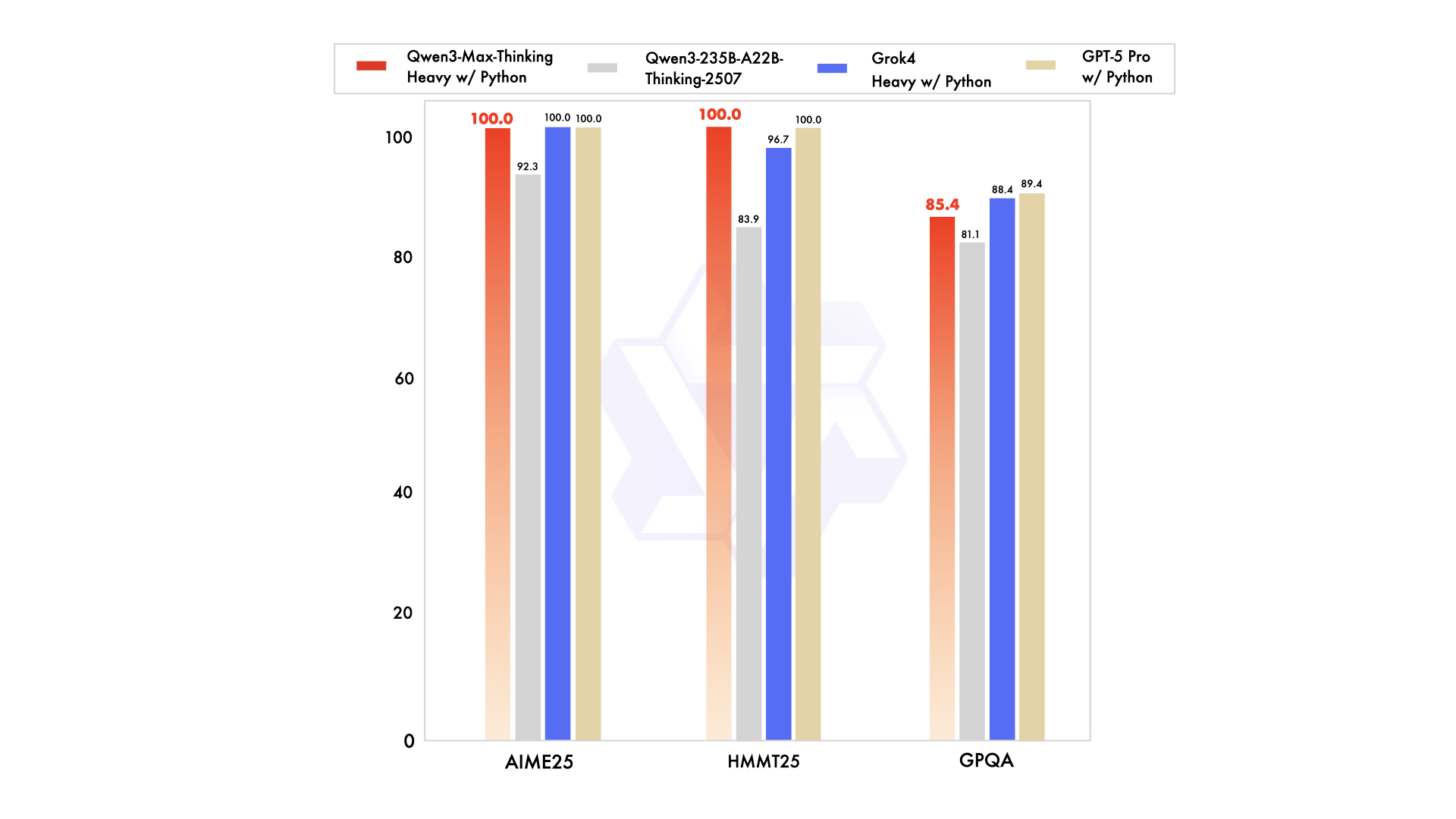
Moreover, in AIME25, a challenging math benchmark, Qwen3-Max achieves 81.6, significantly ahead of Qwen3-235B-A22B at 70.3 and others. This highlights its prowess in solving advanced mathematical problems, where precision and logical deduction prove critical. Transitioning to coding evaluations, LiveCodeBench v6 yields a score of 74.8 for Qwen3-Max, outperforming competitors like Non-thinking at 52.3.
Furthermore, Tau2-Bench (Verified) sees Qwen3-Max at 69.6, while SWE-Bench Verified records 72.5, both leading the pack. These scores stem from real-world coding challenges, where the model resolves issues from GitHub repositories effectively. Alibaba attributes this to relentless compute scaling and massive pre-training data.
In addition, Qwen3-Max excels in agentic benchmarks like Arena-Hard v2 and LiveBench, consistently ranking above Claude Opus 4 and DeepSeek-V3.1. Community tests reveal anecdotal evidence of reasoning-like behavior in harder tasks, producing structured responses despite its non-reasoning base. However, formal benchmarks confirm its reliability, with 100% success rates in areas like hallucinations, general knowledge, and ethics.
Analysts note that increasing thinking budgets, when enabled, boosts performance in math, coding, and science domains. This user-controlled feature, accessible in the Qwen app, provides granular control over reasoning depth. Overall, these metrics underscore Qwen3-Max's efficiency, ranking in the 63rd percentile for speed and 34th for pricing among peers.
Comparisons with Leading AI Models
Qwen3-Max competes directly with top models like GPT-5, Claude 4 Opus, and DeepSeek-V3.1. In coding tasks, Qwen3-Max outscores DeepSeek-V3.1 in frontend development and Java conversions, though Python improvements remain modest. Community feedback on platforms like Reddit highlights its potential to match or exceed GPT-5 Pro before year-end.
Additionally, against Claude Opus 4, Qwen3-Max leads in SuperGPQA and AIME25, demonstrating stronger math and general capabilities. The model's trillion-parameter scale provides an edge in long-tail knowledge coverage, reducing hallucinations compared to predecessors. However, Claude's reasoning modes offer advantages in certain scenarios, which Qwen3-Max addresses with upcoming updates.
In multilingual tasks, Qwen3-Max supports over 100 languages, rivaling Gemini-2.5-Pro and Grok-3. Benchmarks show competitive results against these, particularly in instruction-following and tool use. Pricing-wise, Qwen3-Max proves more cost-effective, with tiered rates undercutting premium options from OpenAI and Anthropic.
Furthermore, compared to open-weight models like Qwen3-235B-A22B, the Max variant enhances agentic skills without deep thinking, achieving higher scores in SWE-Bench and Tau2-Bench. This positions it as a hybrid between open and closed-source strengths, though its closed-source nature sparks debates on accessibility.
Key Features and Capabilities
Qwen3-Max excels in instruction following for chatbots and writing. Reduced hallucinations ensure reliability in classification and ethics.
Agentic features handle multi-step processes via Qwen-Agent tool calling. Fast responses suit real-time apps.
It supports OpenAI-compatible function calling. Long context aids data analysis; parameters enhance creativity.
As non-reasoning, it adapts to structured thinking. Future thinking budgets tune domain performance.
API Integration and Usage with Apidog
Developers access Qwen3-Max primarily through Alibaba Cloud's API, which supports OpenAI-compatible endpoints. This setup enables straightforward integration into applications using standard libraries. For instance, users call the API with prompts like "Why is the sky blue?" to generate responses.
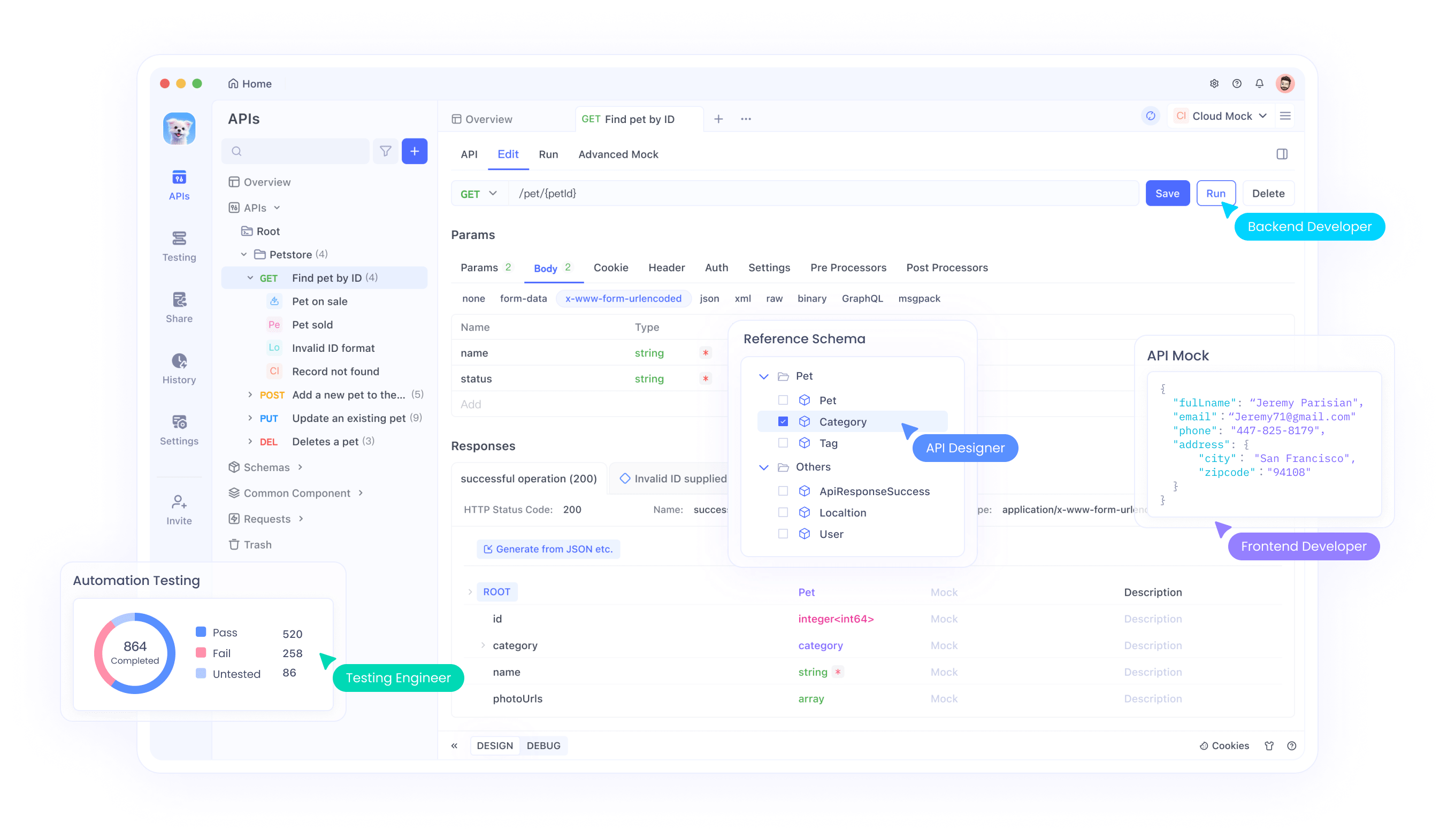
Apidog plays a crucial role here, providing an intuitive platform for API testing and management. Engineers use Apidog to simulate requests, monitor responses, and debug integrations with Qwen3-Max. The tool's features, such as request chaining and environment variables, streamline workflows when handling large token volumes.
Furthermore, Apidog supports collaboration, allowing teams to share API collections for Qwen3-Max projects. To get started, download Apidog for free and import the Qwen API specs from Alibaba's documentation. This ensures efficient testing of features like context caching, which reduces latency in repetitive tasks.
Additionally, integrations with providers like OpenRouter and Vercel AI Gateway expand options. Apidog facilitates switching between these, ensuring compatibility and performance monitoring across ecosystems.
Use Cases for Qwen3-Max
Organizations apply Qwen3-Max in diverse scenarios, leveraging its capabilities for innovation. In software development, the model assists in code generation and debugging, resolving GitHub issues with high accuracy on SWE-Bench. Developers integrate it via API to automate pull requests or refactor legacy code.
Moreover, in education, Qwen3-Max solves advanced math problems, aiding tutors in explaining concepts from AIME25 benchmarks. Its multilingual support enables global learning platforms to deliver content in native languages.
In enterprise settings, agentic features power automation tools, such as chatbots for customer service or data analysis pipelines. Healthcare providers use it for ethical decision support, benefiting from perfect scores in ethics benchmarks.
Furthermore, creative industries employ Qwen3-Max for writing and content generation, where reduced hallucinations ensure quality outputs. E-commerce platforms integrate it for personalized recommendations, processing long contexts from user histories.
However, in research, scientists explore its reasoning potential for simulations and hypothesis testing, anticipating thinking mode enhancements.
Conclusion
Qwen3-Max transforms AI landscapes with its trillion-parameter might and benchmark dominance. Developers harness its power through APIs, enhanced by tools like Apidog for efficient integration. As Alibaba refines the model, it promises even greater innovations in coding, reasoning, and beyond. Teams adopt Qwen3-Max today to stay competitive in an evolving field.


