Alibaba's Qwen team released Qwen3-Coder-Flash, their latest coding model variant that promises "lightning-fast, accurate code generation" with some impressive technical specifications. However, the real question developers are asking is whether this new model can truly handle enterprise-level coding challenges or if it's just another incremental improvement.
What Makes Qwen3-Coder-Flash Different
Understanding Qwen3-Coder-Flash requires examining its architecture and positioning within Alibaba's expanding model ecosystem. This model features 30.5B total parameters with 3.3B active at any one time, utilizing a Mixture-of-Experts architecture that enables it to run efficiently on 64GB Mac systems or even 32GB systems when quantized.
The naming convention reveals strategic positioning. While the broader Qwen3-Coder family includes massive variants like the 480B parameter model, Qwen3-Coder-Flash specifically targets developers who need fast, efficient code generation without requiring enormous computational resources. This approach makes advanced AI coding accessible to individual developers and smaller teams.
Furthermore, the "Flash" designation emphasizes speed optimization. The model is designed as a "non-thinking model that is specially trained for coding tasks", meaning it focuses on rapid code generation rather than complex reasoning processes that might slow down development workflows.
Technical Architecture Deep Analysis
The Mixture-of-Experts (MoE) architecture represents a significant technical advancement in how coding models operate. Unlike traditional dense models that activate all parameters for every computation, Qwen3-Coder-Flash selectively activates only the most relevant expert networks for specific coding tasks. This selective activation dramatically reduces computational overhead while maintaining high performance levels.
Additionally, the model incorporates several architectural innovations that distinguish it from competitors. The parameter distribution enables specialized expert networks to handle different programming languages and coding paradigms more effectively. Python code generation might activate different expert combinations compared to JavaScript or C++ development tasks.
The training methodology also emphasizes practical coding scenarios. The model leveraged Qwen2.5-Coder to clean and rewrite noisy data, significantly improving overall performance through advanced synthetic data generation techniques. This approach ensures the model understands real-world coding patterns rather than just academic programming examples.

Context Length Capabilities Transform Development Workflows
One of Qwen3-Coder-Flash's most significant advantages lies in its context handling capabilities. The model provides native 256K context support with extension capabilities up to 1M tokens using YaRN (Yet another RoPE extensioN) technology. This extended context window fundamentally changes how developers can interact with AI coding assistants.
Traditional coding models often struggle with large codebases because they cannot maintain sufficient context about project structure, dependencies, and architectural patterns. However, Qwen3-Coder-Flash's extended context enables it to understand entire repositories, complex inheritance hierarchies, and multi-file dependencies simultaneously.
Moreover, the extended context proves particularly valuable for API development workflows. When integrated with tools like Apidog, developers can provide comprehensive API documentation, multiple endpoint specifications, and complex data schemas within a single context window. This capability enables more accurate code generation that properly handles API integration requirements and maintains consistency across different endpoints.
The practical implications extend beyond simple code completion. Developers can now provide entire project specifications, architectural diagrams, and requirement documents as context, enabling the model to generate code that aligns with broader project goals rather than isolated functionality.
Platform Integration and Developer Ecosystem
Qwen3-Coder-Flash has been optimized for platforms like Qwen Code, Cline, Roo Code, and Kilo Code, indicating Alibaba's strategic focus on ecosystem development rather than standalone model deployment. This platform-centric approach recognizes that modern development workflows require integrated toolchains rather than isolated AI capabilities.
The integration strategy extends to function calling and agent workflows. The model features a specially designed function call format that supports agentic coding across multiple platforms. This standardization enables developers to create more sophisticated automation workflows that can interact with multiple development tools and services.
Furthermore, the model's compatibility with popular development environments reduces adoption friction. Developers can integrate Qwen3-Coder-Flash into existing workflows without significant infrastructure changes or learning new interface paradigms. This seamless integration approach contrasts with models that require specialized environments or extensive configuration processes.
The agent workflow capabilities also enable more sophisticated development automation. Teams can create AI agents that handle routine coding tasks, code review processes, and documentation generation while maintaining consistency with project standards and architectural patterns.
Performance Benchmarks and Real-World Testing
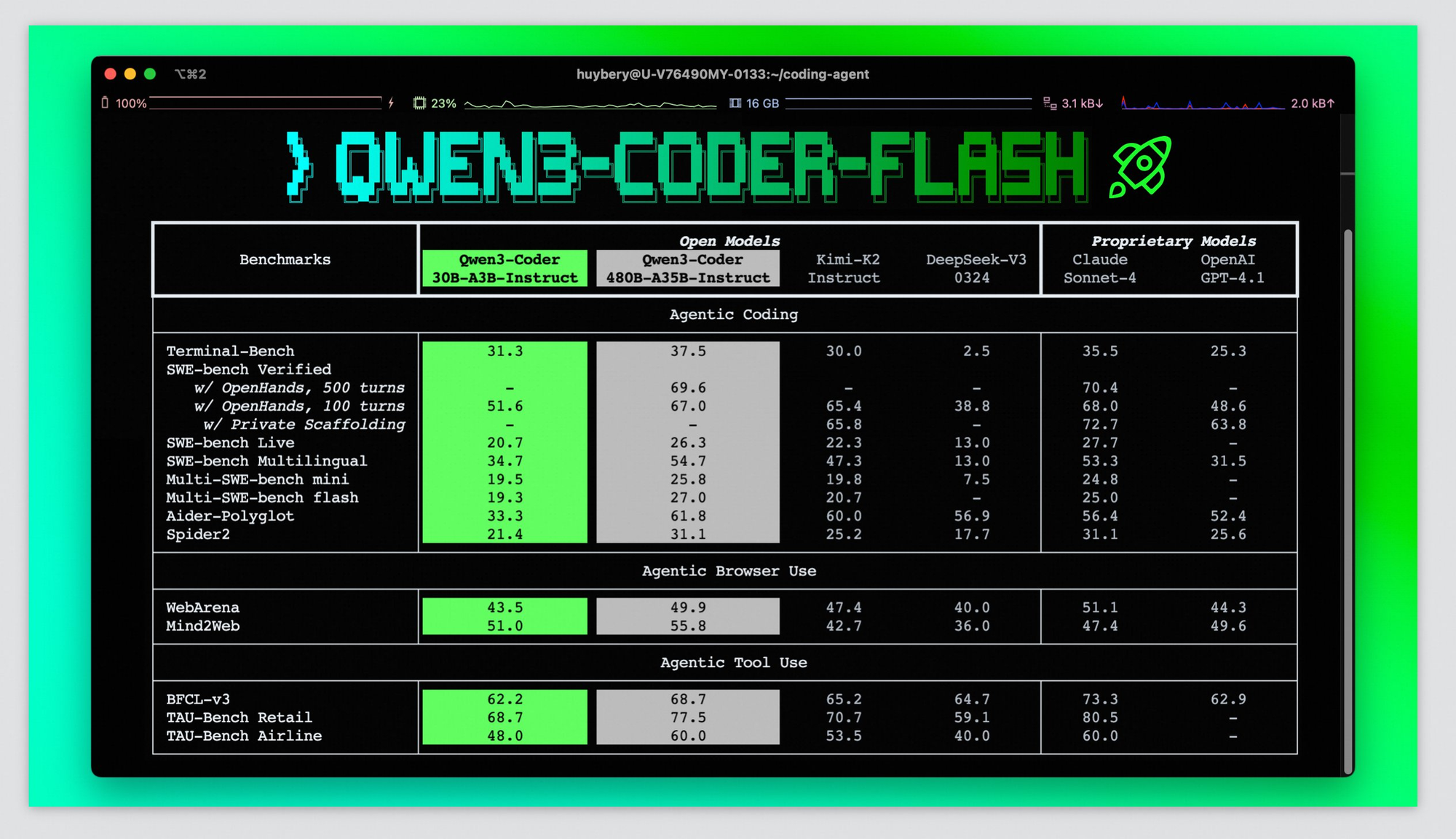
Evaluating Qwen3-Coder-Flash's performance requires examining both synthetic benchmarks and real-world development scenarios. The broader Qwen3-Coder family achieves state-of-the-art coding performance rivaling Claude Sonnet-4, GPT-4.1, and Kimi K2, with 61.8% performance on Aider Polygot benchmarks. While specific benchmarks for the Flash variant aren't yet available, its architectural similarities suggest comparable performance levels.
However, benchmark performance only tells part of the story. Real-world development involves complex scenarios that standard benchmarks don't capture: debugging legacy code, integrating with poorly documented APIs, handling edge cases in production systems, and maintaining code quality across large teams.
Early developer feedback suggests Qwen3-Coder-Flash excels in rapid prototyping scenarios where speed matters more than perfect optimization. The model generates functional code quickly, enabling developers to iterate rapidly during exploration phases. However, production deployment often requires additional review and optimization that the model cannot automatically provide.
The model's performance also varies significantly across different programming languages and frameworks. While it demonstrates strong capabilities with popular languages like Python and JavaScript, performance with specialized languages or emerging frameworks may be less consistent.
Integration with API Development Tools
The synergy between Qwen3-Coder-Flash and API development platforms like Apidog creates powerful development workflows that streamline the entire API lifecycle. When developers use Apidog's comprehensive API design and testing capabilities alongside Qwen3-Coder-Flash's code generation features, they can rapidly prototype, implement, and test API endpoints with unprecedented efficiency.
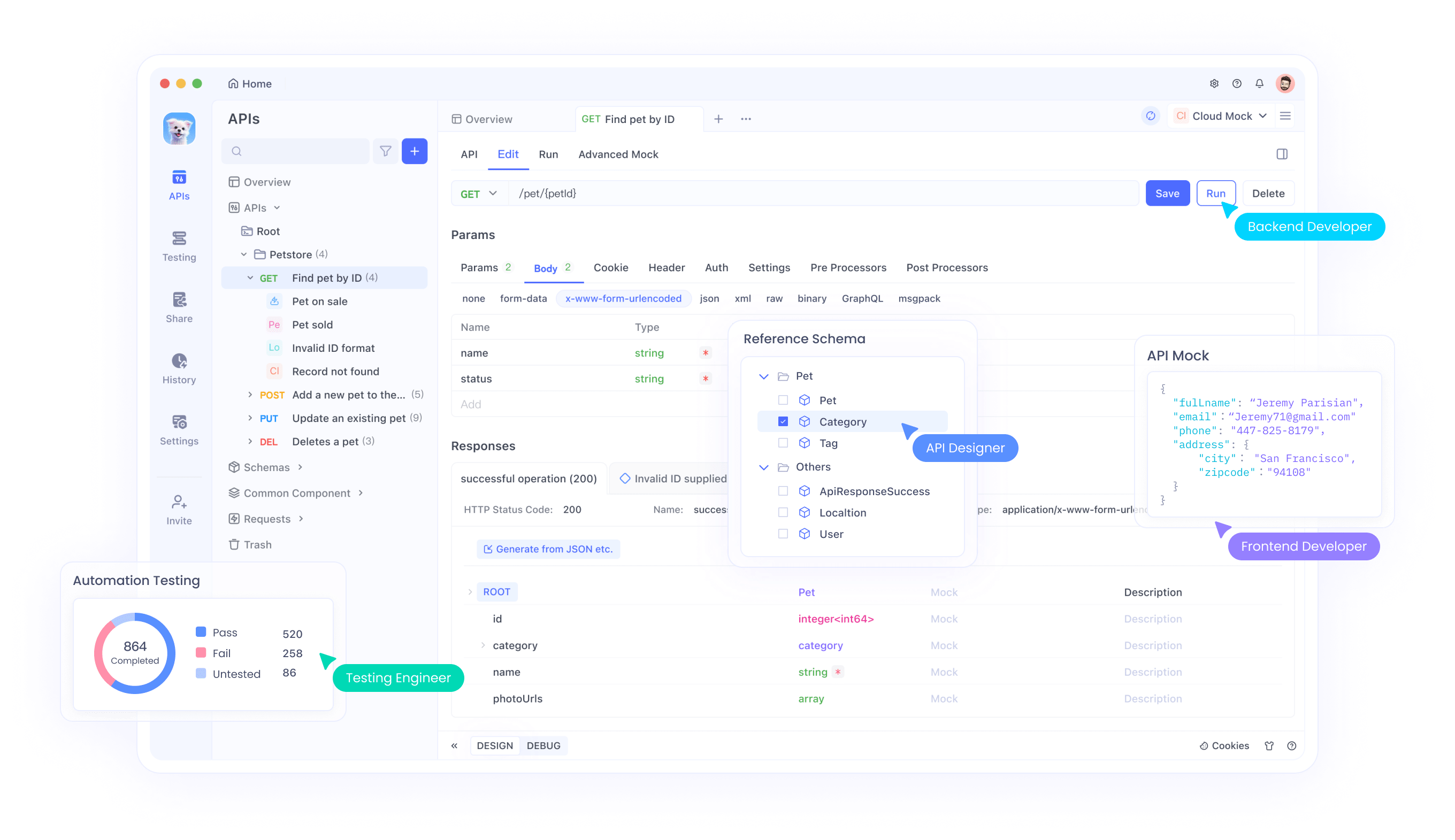
Specifically, Apidog's visual API designer can generate comprehensive specifications that Qwen3-Coder-Flash can then convert into functional code implementations. The model's extended context window enables it to understand complex API schemas, authentication requirements, and data validation rules simultaneously, producing code that properly handles all specified requirements.
Additionally, the integration enables automated testing workflows where Qwen3-Coder-Flash generates test cases based on API specifications, while Apidog executes these tests and provides detailed feedback about implementation correctness. This closed-loop development process significantly reduces the time between API design and functional implementation.
The collaborative potential extends to team development scenarios where multiple developers work on different API components. Qwen3-Coder-Flash can maintain consistency across different endpoint implementations by understanding the broader API architecture through Apidog's centralized specification management.
Limitations and Considerations
Despite its impressive capabilities, Qwen3-Coder-Flash faces several limitations that developers must consider. The model's focus on speed sometimes comes at the expense of code optimization and best practices. Generated code may be functionally correct but lack the efficiency optimizations that experienced developers would implement.
Security considerations also require careful attention. While the model generates syntactically correct code, it may not always implement proper security measures like input validation, SQL injection prevention, or proper authentication handling. Developers must still perform security reviews and implement appropriate safeguards.
Furthermore, the model's training data limitations mean it may struggle with cutting-edge frameworks, newly released language features, or highly specialized domain knowledge. Developers working with emerging technologies should expect to provide additional context and guidance to achieve optimal results.
The cost and infrastructure requirements also present practical challenges. While more efficient than larger models, Qwen3-Coder-Flash still requires significant computational resources for optimal performance. Organizations must balance the productivity benefits against infrastructure costs and complexity.
Implementation Strategies for Development Teams
Successfully implementing Qwen3-Coder-Flash requires strategic planning that considers both technical requirements and team dynamics. Organizations should start with pilot projects that leverage the model's strengths while minimizing exposure to its limitations.
Initial implementation should focus on use cases where rapid code generation provides clear value: API endpoint creation, test case generation, documentation automation, and prototype development. These scenarios allow teams to gain experience with the model while delivering tangible productivity improvements.
Training and change management also require careful attention. Development teams need guidance on effective prompt engineering, understanding model limitations, and integrating AI-generated code into existing quality assurance processes. Without proper training, teams may either under-utilize the model's capabilities or over-rely on its output without appropriate validation.
Integration with existing development tools should be gradual and measured. Rather than replacing established workflows entirely, organizations should identify specific pain points where Qwen3-Coder-Flash can provide immediate improvements while maintaining overall workflow stability.
Conclusion
Qwen3-Coder-Flash represents a significant advancement in accessible AI coding assistance, offering enterprise-grade capabilities in a more efficient and cost-effective package. Its extended context capabilities, MoE architecture, and platform integrations create powerful opportunities for development teams seeking to accelerate their coding workflows.
However, success with Qwen3-Coder-Flash requires realistic expectations and strategic implementation. The model excels at rapid code generation and prototyping but cannot replace human expertise in architecture design, security implementation, and code optimization. Organizations that understand these boundaries and implement appropriate processes will realize significant productivity gains.