
Alibaba's Qwen team has once again pushed the boundaries of artificial intelligence with the release of the Qwen2.5-VL-32B-Instruct model, a groundbreaking vision-language model (VLM) that promises to be both smarter and lighter.
Announced on March 24, 2025, this 32-billion-parameter model strikes an optimal balance between performance and efficiency, making it an ideal choice for developers and researchers. Building on the success of the Qwen2.5-VL series, this new iteration introduces significant advancements in mathematical reasoning, human preference alignment, and vision tasks, all while maintaining a manageable size for local deployment.
For developers eager to integrate this powerful model into their projects, exploring robust API tools is essential. That's why we recommend downloading Apidog for free — a user-friendly API development platform that simplifies testing and integrating models like Qwen into your applications. With Apidog, you can seamlessly interact with the Qwen API, streamline workflows, and unlock the full potential of this innovative VLM. Download Apidog today and start building smarter applications!
This API tool lets you test and debug your model’s endpoints effortlessly. Download Apidog for free today and streamline your workflow as you explore Mistral Small 3.1’s capabilities!
Qwen2.5-VL-32B: A Smarter Vision-Language Model
What Makes Qwen2.5-VL-32B Unique?
Qwen2.5-VL-32B stands out as a 32-billion-parameter vision-language model designed to address the limitations of both larger and smaller models in the Qwen family. While 72-billion-parameter models like Qwen2.5-VL-72B offer robust capabilities, they often require significant computational resources, making them impractical for local deployment. Conversely, 7-billion-parameter models, though lighter, may lack the depth required for complex tasks. Qwen2.5-VL-32B fills this gap by delivering high performance with a more manageable footprint.
This model builds on the Qwen2.5-VL series, which gained widespread acclaim for its multimodal capabilities. However, Qwen2.5-VL-32B introduces critical enhancements, including optimization through reinforcement learning (RL). This approach improves the model's alignment with human preferences, ensuring more detailed, user-friendly outputs. Additionally, the model demonstrates superior mathematical reasoning, a vital feature for tasks involving complex problem-solving and data analysis.

Key Technical Enhancements
Qwen2.5-VL-32B leverages reinforcement learning to refine its output style, making responses more coherent, detailed, and formatted for better human interaction. Furthermore, its mathematical reasoning capabilities have seen significant improvements, as evidenced by its performance on benchmarks like MathVista and MMMU. These enhancements stem from fine-tuned training processes that prioritize accuracy and logical deduction, particularly in multimodal contexts where text and visual data intersect.
The model also excels in fine-grained image understanding and reasoning, enabling precise analysis of visual content, such as charts, graphs, and documents. This capability positions Qwen2.5-VL-32B as a top contender for applications requiring advanced visual logic deduction and content recognition.
Qwen2.5-VL-32B Performance Benchmarks: Outperforming Larger Models
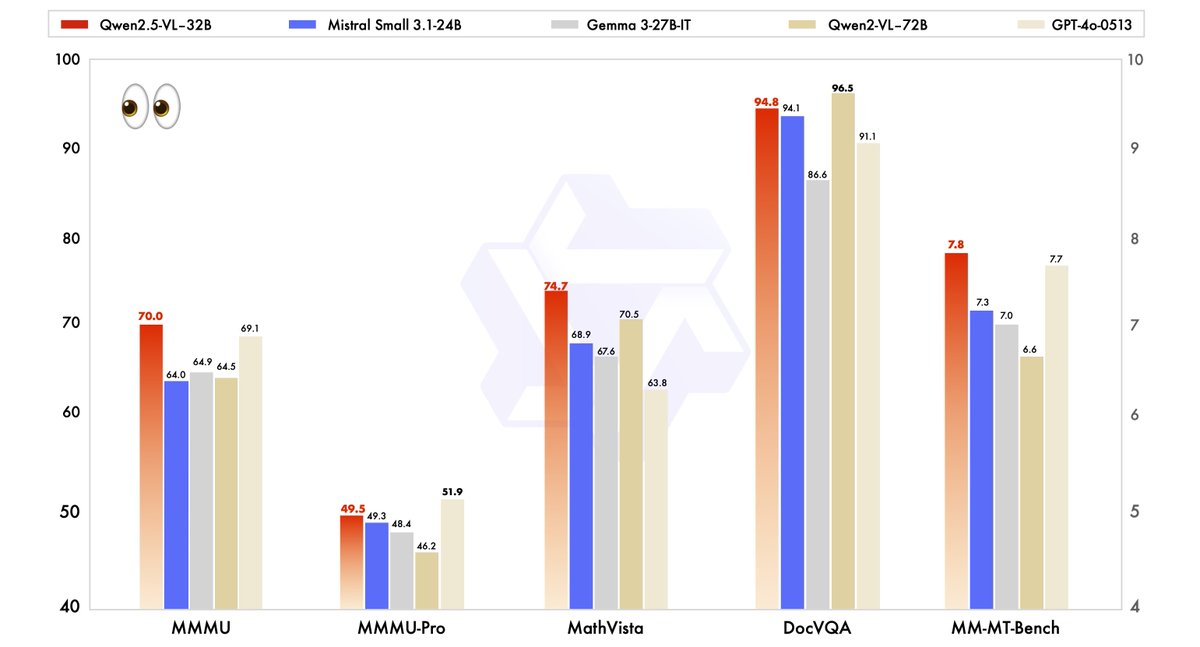
Qwen2.5-VL-32B's performance has been rigorously evaluated against state-of-the-art models, including its larger sibling, Qwen2.5-VL-72B, as well as competitors like Mistral-Small-3.1–24B and Gemma-3–27B-IT. The results highlight the model's superiority in several key areas.
- MMMU (Massive Multitask Language Understanding): Qwen2.5-VL-32B achieves a score of 70.0, surpassing Qwen2.5-VL-72B's 64.5. This benchmark tests complex, multi-step reasoning across diverse tasks, demonstrating the model's enhanced cognitive capabilities.
- MathVista: With a score of 74.7, Qwen2.5-VL-32B outperforms Qwen2.5-VL-72B's 70.5, underscoring its strength in mathematical and visual reasoning tasks.
- MM-MT-Bench: This subjective user experience evaluation benchmark shows Qwen2.5-VL-32B leading its predecessor by a significant margin, reflecting improved human preference alignment.
- Text-Based Tasks (e.g., MMLU, MATH, HumanEval): The model competes effectively with larger models like GPT-4o-Mini, achieving scores of 78.4 on MMLU, 82.2 on MATH, and 91.5 on HumanEval, despite its smaller parameter count.
These benchmarks illustrate that Qwen2.5-VL-32B not only matches but often exceeds the performance of larger models, all while requiring fewer computational resources. This balance of power and efficiency makes it an attractive option for developers and researchers working with limited hardware.
Why Size Matters: The 32B Advantage
The 32-billion-parameter size of Qwen2.5-VL-32B strikes a sweet spot for local deployment. Unlike 72B models, which demand extensive GPU resources, this lighter model integrates seamlessly with inference engines like SGLang and vLLM, as noted in related web results. This compatibility ensures faster deployment and lower memory usage, making it accessible for a broader range of users, from startups to large enterprises.
Moreover, the model's optimization for speed and efficiency doesn't compromise its capabilities. Its ability to handle multimodal tasks — such as recognizing objects, analyzing charts, and processing structured outputs like invoices and tables — remains robust, positioning it as a versatile tool for real-world applications.

Running Qwen2.5-VL-32B Locally with MLX
To run this powerful model locally on your Mac with Apple Silicon, follow these steps:
System Requirements
- A Mac with Apple Silicon (M1, M2, or M3 chip)
- At least 32GB of RAM (64GB recommended)
- 60GB+ free storage space
- macOS Sonoma or newer
Installation Steps
- Install Python dependencies
pip install mlx mlx-llm transformers pillow
- Download the model
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Convert the model to MLX format
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Create a simple script to interact with the model
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Load the model
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Load an image
image = Image.open("path/to/your/image.jpg")
# Create a prompt with the image
prompt = "What do you see in this image?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Practical Applications: Leveraging Qwen2.5-VL-32B
Vision Tasks and Beyond
Qwen2.5-VL-32B's advanced visual capabilities open doors to a wide array of applications. For instance, it can serve as a visual agent, dynamically interacting with computer or phone interfaces to perform tasks like navigation or data extraction. Its ability to understand long videos (up to one hour) and pinpoint relevant segments further enhances its utility in video analysis and temporal localization.
In document parsing, the model excels at processing multi-scene, multilingual content, including handwritten text, tables, charts, and chemical formulas. This makes it invaluable for industries like finance, education, and healthcare, where accurate extraction of structured data is critical.
Text and Mathematical Reasoning
Beyond vision tasks, Qwen2.5-VL-32B shines in text-based applications, particularly those involving mathematical reasoning and coding. Its high scores on benchmarks like MATH and HumanEval indicate its proficiency in solving complex algebraic problems, interpreting function graphs, and generating accurate code snippets. This dual proficiency in vision and text positions Qwen2.5-VL-32B as a holistic solution for multimodal AI challenges.

Where You Can Use Qwen2.5-VL-32B
Open-Source and API Access
Qwen2.5-VL-32B is available under the Apache 2.0 license, making it open-source and accessible to developers worldwide. You can access the model through several platforms:
- Hugging Face: The model is hosted on Hugging Face, where you can download it for local use or integrate it via the Transformers library.
- ModelScope: Alibaba's ModelScope platform provides another avenue for accessing and deploying the model.
For seamless integration, developers can use the Qwen API, which simplifies interaction with the model. Whether you're building a custom application or experimenting with multimodal tasks, the Qwen API ensures efficient connectivity and robust performance.
Deployment with Inference Engines
Qwen2.5-VL-32B supports deployment with inference engines like SGLang and vLLM. These tools optimize the model for fast inference, reducing latency and memory usage. By leveraging these engines, developers can deploy the model on local hardware or cloud platforms, tailoring it to specific use cases.
To get started, install the required libraries (e.g., transformers, vllm) and follow the instructions on the Qwen GitHub page or Hugging Face documentation. This process ensures a smooth integration, allowing you to harness the model's full potential.
Optimizing Local Performance
When running Qwen2.5-VL-32B locally, consider these optimization tips:
- Quantization: Add the
--quantizeflag during conversion to reduce memory requirements - Manage context length: Limit input tokens for faster responses
- Close resource-heavy applications when running the model
- Batch processing: For multiple images, process them in batches rather than individually
Conclusion: Why Qwen2.5-VL-32B Matters
Qwen2.5-VL-32B represents a significant milestone in the evolution of vision-language models. By combining smarter reasoning, lighter resource requirements, and robust performance, this 32-billion-parameter model addresses the needs of developers and researchers alike. Its advancements in mathematical reasoning, human preference alignment, and vision tasks position it as a top choice for local deployment and real-world applications.
Whether you're building educational tools, business intelligence systems, or customer support solutions, Qwen2.5-VL-32B offers the versatility and efficiency you need. With access through open-source platforms and the Qwen API, integrating this model into your projects is easier than ever. As the Qwen team continues to innovate, we can expect even more exciting developments in the future of multimodal AI.
This API tool lets you test and debug your model’s endpoints effortlessly. Download Apidog for free today and streamline your workflow as you explore Mistral Small 3.1’s capabilities!


