Looking to experiment with cutting-edge multimodal AI? If you want to test APIs that leverage models like Qwen 2.5 Omni 7B, download Apidog for free. Apidog streamlines API testing and integration, making it easy to work with models at the frontier of AI innovation.
Why Qwen 2.5 Omni 7B Matters for API and AI Developers
The AI landscape is evolving rapidly. With the arrival of Qwen 2.5 Omni 7B from Alibaba Cloud, developers now have access to a unified model capable of handling text, images, audio, and video—both as input and output. For teams building next-generation apps and APIs, this model opens doors to seamless multimodal user experiences and smarter automation.
Below, we break down what makes Qwen 2.5 Omni 7B unique, how its architecture works, and what developers need to know to use it effectively.
What Does “Omni” Mean in Qwen 2.5 Omni 7B?
The name “Omni” isn’t just a label—it's a technical promise. Qwen 2.5 Omni 7B is designed from the ground up for true multimodality:
- Text: Written prompts, code, or documents
- Images: Visual content, screenshots, diagrams
- Audio: Speech, sounds, music clips
- Video: Moving visual and audio content
Unlike most models that specialize in one or two modalities, Qwen 2.5 Omni 7B can accept any of these as input, and respond in text or even natural-sounding speech—streamed in real time.
Voice Chat + Video Chat! Just in Qwen Chat (https://t.co/FmQ0B9tiE7)! You can now chat with Qwen just like making a phone call or making a video call! Check the demo in https://t.co/42iDe4j1HsWhat's more, we opensource the model behind all this, Qwen2.5-Omni-7B, under the… pic.twitter.com/LHQOQrl9Ha
— Qwen (@Alibaba_Qwen) March 26, 2025
This “any-to-any” capability moves AI interaction closer to how humans naturally communicate—across multiple senses, in real time.
Inside the Qwen 2.5 Omni 7B Architecture
The “Thinker-Talker” Model Design
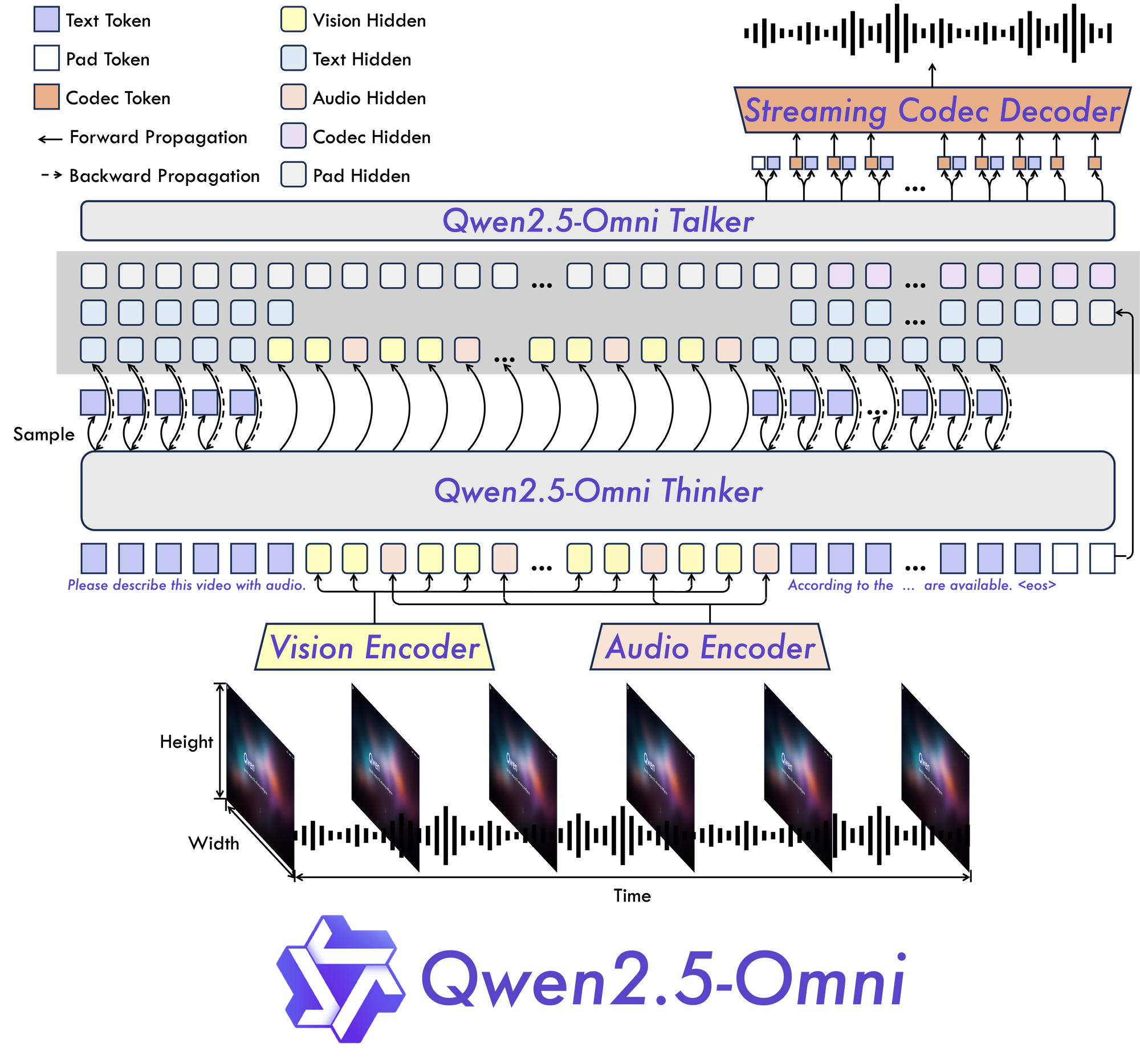
Qwen 2.5 Omni 7B is built on a “Thinker-Talker” architecture—a key innovation for end-to-end multimodal processing:
- Thinker: Handles input understanding and cross-modal reasoning
- Talker: Manages output generation, including both text and natural speech
This separation helps the model manage the complexity of aligning and transforming information across different formats, resulting in more accurate and natural responses.
TMRoPE: Solving Temporal Synchronization
A standout feature is TMRoPE (Time-aligned Multimodal Rotary Positional Encoding). This mechanism enables the model to align data streams that unfold over time—like syncing lip movements in a video with spoken audio.
For example:
- Video + Audio: Qwen 2.5 Omni 7B can process both streams, match them temporally, and generate coherent outputs (e.g., accurate video subtitles or real-time dubbing).
- API Use Case: Developers can harness this for applications where time-aligned multimodal data is critical, such as automated meeting transcriptions with context-aware summaries.
Built for Real-Time, Low-Latency Use
The architecture supports chunked streaming input and fast output. This makes Qwen 2.5 Omni 7B suitable for:
- Voice assistants that react instantly to commands
- Live video analysis with text or speech feedback
- Real-time translation tools
Qwen 2.5 Omni 7B: Benchmark Results for Developers
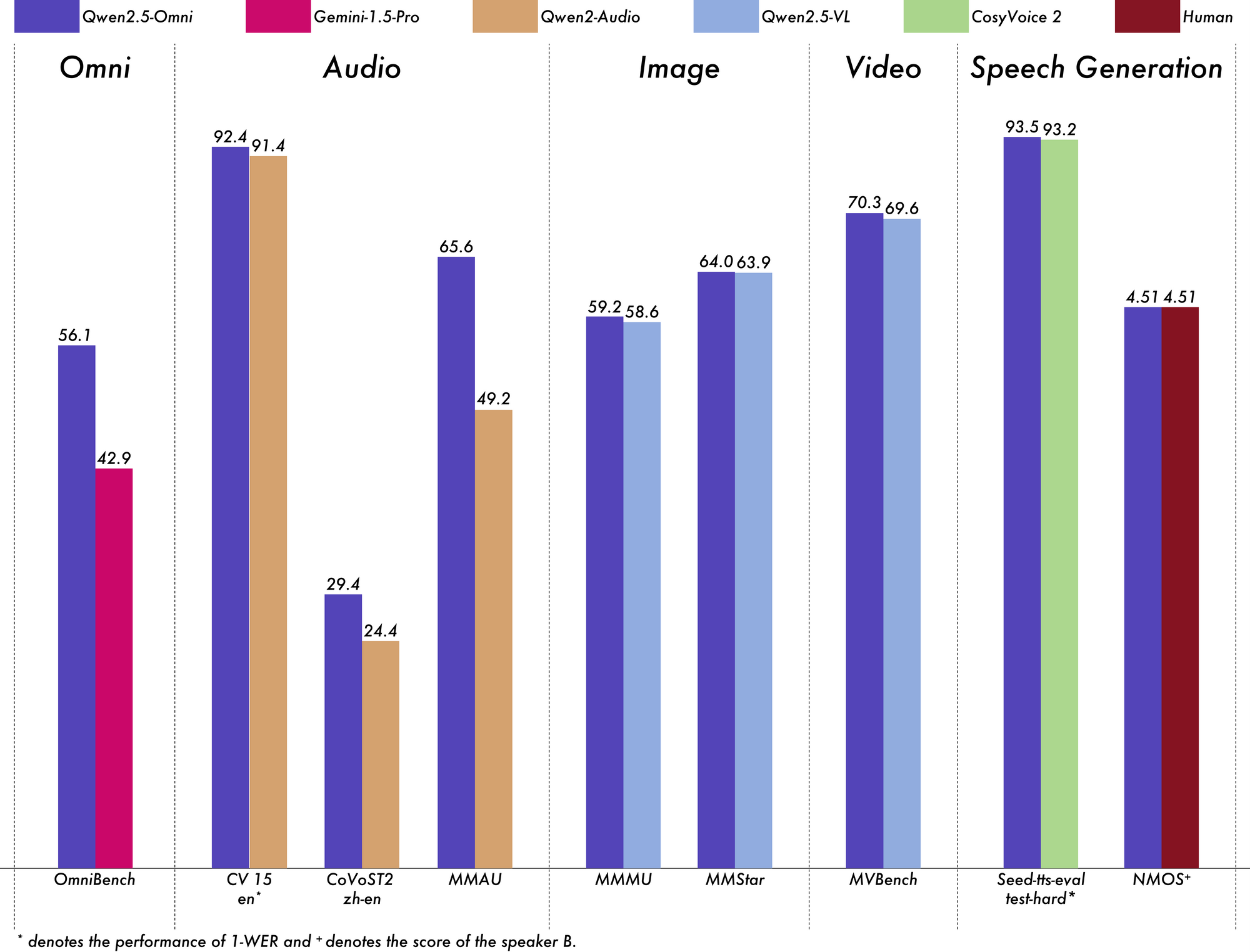
When assessing a model for production, performance on standardized benchmarks is key. Qwen 2.5 Omni 7B stands out across multiple domains:
Multimodal Understanding
- OmniBench average: 56.13% (vs. Gemini-1.5-Pro’s 42.91%)
- Speech tasks: 55.25%
- Sound Event: 60.00%
- Music: 52.83%
Audio Processing
- ASR (Librispeech): WER of 1.6%–3.5% (on par with Whisper-large-v3)
- Sound Event Recognition (Meld): 0.570 (best-in-class)
- Music Tempo (GiantSteps): 0.88
Visual Understanding
- Image-to-text (MMMU): 59.2 (very close to GPT-4o-mini’s 60.0)
- RefCOCO Grounding: 90.5% (outperforms Gemini 1.5 Pro’s 73.2%)
Video Comprehension
- Video-MME (no subtitles): 64.3
- Video-MME (with subtitles): 72.4
Speech Generation
- Speaker similarity: 0.754–0.752 (matches dedicated TTS models like Seed-TTS_RL)
- Output: Natural speech that preserves original speaker characteristics
Text-Only Performance
- Math (GSM8K): 88.7% (slightly below text-only Qwen2.5-7B at 91.6%)
- Code generation: Maintains strong results
Qwen 2.5 Omni is NUTS!I can't believe a 7B modelcan take text, images, audio, video as inputgive text and audio as outputand work so well!Open source Apache 2.0Try it, link below!You really cooked @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
— Jeff Boudier 🤗 (@jeffboudier) March 26, 2025
Real-World Use Cases: Unlocking Multimodal AI with Qwen 2.5 Omni 7B
1. Smarter Communication Interfaces
- Context-aware chatbots: Process voice, video, and text in customer support.
- Virtual meeting assistants: Transcribe, summarize, and respond with speech or text.
2. Automated Content Analysis
- Media content review: Extract insights from video, audio, and documents in a single pipeline.
- API Example: Use Apidog to build and test endpoints that take both images and audio as input, returning context-aware summaries.
3. Accessible Voice and Video Interfaces
- Hands-free controls: Enable voice or video-based instructions for users with accessibility needs.
- Education apps: Generate spoken explanations from diagrams or videos in real time.
4. Creative Content Generation
- Dynamic narration: Auto-generate voiceovers for videos or multimedia presentations.
- Interactive learning: Build educational tools that respond to spoken or visual queries.
5. Multichannel Customer Service
- Unified API backend: Handle written, spoken, or video queries from users in a single workflow, with seamless switching between modalities.
Practical Considerations for API Teams
Hardware Demands
- Memory: Short (15s) video in FP32 needs ~93.56 GB GPU RAM; 60s video (BF16) still requires ~60 GB.
- Optimization: Features like Flash Attention 2 can reduce load, but high-end hardware is recommended for production.
Voice Output Options
- Voice choices: “Chelsie” (female, warm), “Ethan” (male, upbeat)
- Customization: Enables tailored user experiences for different applications.
Integration Details
- Prompting: Special patterns required for audio responses.
- Consistent parameters: Use
use_audio_in_videosettings for multi-turn conversations. - Video URL support: Requires torchvision ≥ 0.19.0 for HTTPS.
- API hosting: Not yet supported on Hugging Face Inference API due to “any-to-any” model limitations.
Apidog: Accelerate Your Qwen 2.5 Omni 7B API Development
For API developers and backend teams, integrating, testing, and iterating on advanced models can be complex. Apidog provides a robust, developer-friendly environment to:
- Prototype multimodal endpoints quickly
- Test streaming and chunked responses
- Validate input/output for text, image, audio, and video
- Streamline error handling and automation
By leveraging Apidog, you can focus on building intelligent API workflows while reducing integration headaches—especially with complex models like Qwen 2.5 Omni 7B.
Conclusion
Qwen 2.5 Omni 7B is a leap forward for developers seeking to build truly multimodal applications and APIs. Its unique architecture, superior benchmark results, and real-world flexibility make it a compelling choice for teams at the cutting edge of AI integration.
While hardware costs and integration details require planning, the potential for unified, human-like AI interaction is within reach. Tools like Apidog empower developers to harness the full power of models like Qwen 2.5 Omni 7B—enabling rapid testing, deployment, and iteration in modern API-driven environments.