
Developers increasingly seek robust tools to incorporate real-time web search capabilities into their AI-driven applications. The Perplexity Search API stands out as a powerful solution, offering access to an extensive index of web content with high accuracy and speed. This API enables seamless integration of search functionalities that rival leading answer engines, allowing you to build sophisticated systems without managing complex infrastructure.
Furthermore, understanding the Perplexity Search API requires a grasp of its core components, from authentication to advanced querying. Engineers value its AI-first design, which prioritizes relevance and efficiency. Consequently, this guide provides a step-by-step approach, drawing from official documentation and technical insights. You will find detailed explanations, code snippets, and practical tips to implement it effectively. However, before proceeding, consider the API's evolution—launched to democratize access to internet-scale knowledge, it addresses gaps in traditional search APIs by focusing on AI compatibility.
What Is the Perplexity Search API?
The Perplexity Search API delivers raw web search results, empowering developers to perform hybrid searches that combine semantic understanding with lexical matching. It accesses an index encompassing hundreds of billions of webpages, processing updates at a rate of tens of thousands per second to ensure freshness. Unlike conventional search tools, this API emphasizes AI workloads, providing structured responses with individually scored document units for precise snippet ranking.
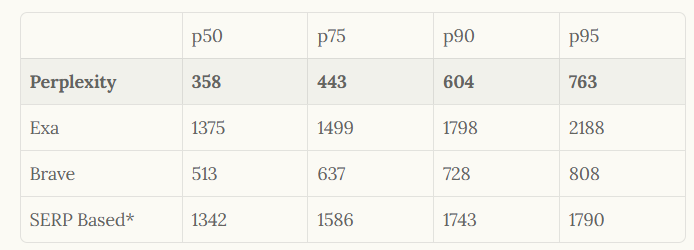
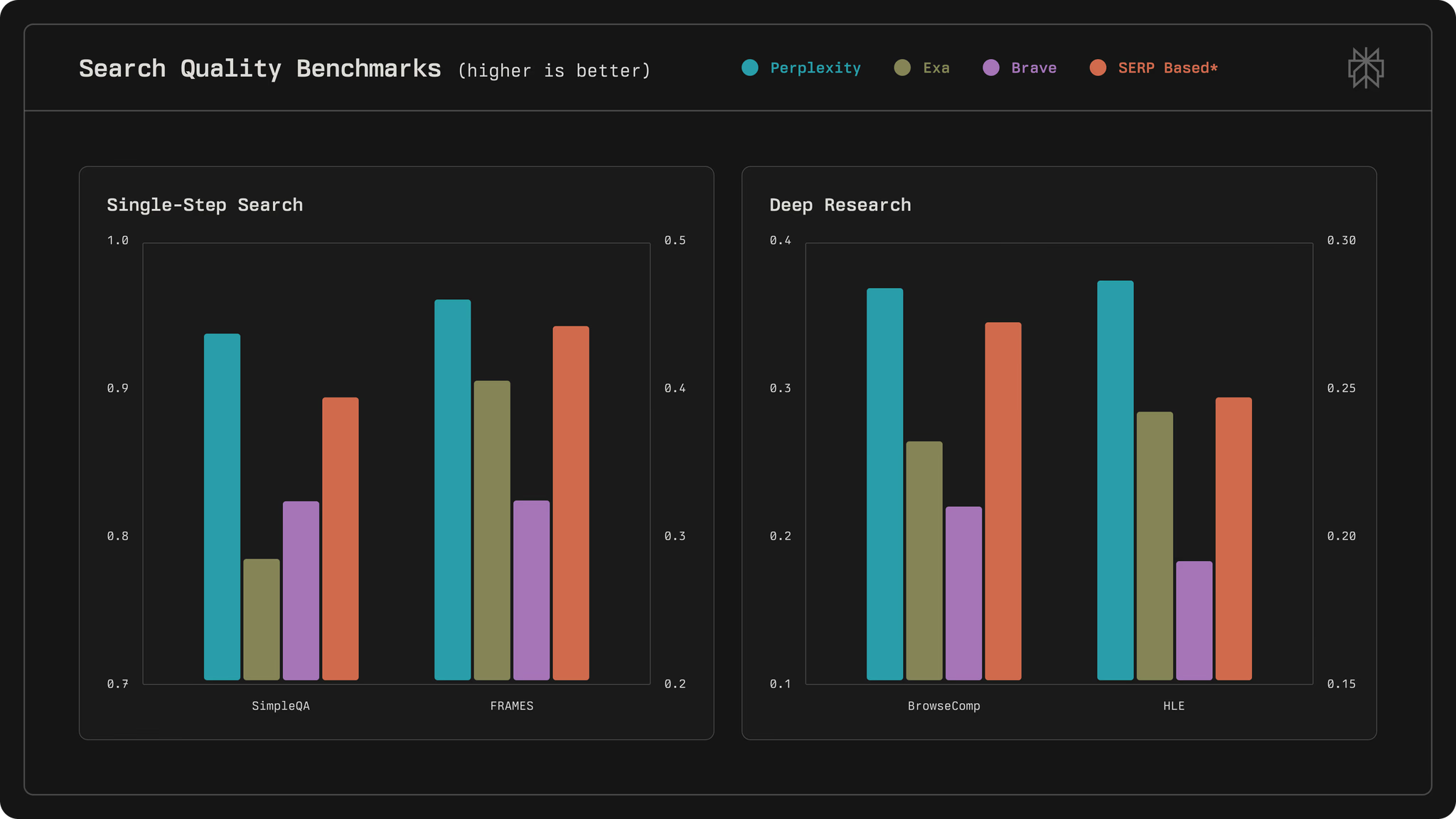
Perplexity engineers designed the API to sit at the forefront of relevance and speed, outperforming competitors in latency and quality metrics. For example, it achieves a median latency of 358 milliseconds, far below alternatives like Exa at 1375 milliseconds. Additionally, the API incorporates human feedback loops and LLM ranking to refine results, making it ideal for applications requiring trustworthy information retrieval.
Moreover, the Perplexity Search API distinguishes itself through privacy commitments—no user data trains underlying LLMs—and affordability, with leading pricing for search requests. Developers employ it in diverse scenarios, from simple Q&A bots to complex research agents. Therefore, it serves as a foundational layer for building AI agents that conduct deep investigations across the web.
Key Features and Benefits of the Perplexity Search API
The Perplexity Search API boasts several standout features that enhance its utility for technical implementations. First, it offers fine-grained content understanding, segmenting documents into sub-units for targeted retrieval. This approach reduces preprocessing needs and accelerates integration into AI pipelines. Furthermore, the API supports advanced filtering, allowing you to specify parameters for real-time data and exclude irrelevant content.
Another critical feature involves its hybrid retrieval system, which merges lexical and semantic signals to generate comprehensive candidate sets. Engineers appreciate this because it ensures completeness while maintaining low latency. In addition, the API provides structured outputs, including scored snippets and citations, which foster trust in the results.
The benefits extend beyond technical prowess. Developers save costs with its pricing model—$5 per 1,000 requests for raw searches—making it more economical than peers. Moreover, it scales effortlessly, handling up to 200 million daily queries without compromising performance. As a result, startups and enterprises alike adopt it to innovate rapidly, prototyping products in under an hour using the associated SDK.
However, the true advantage lies in its ongoing improvements. Perplexity integrates user signals from millions of interactions to iteratively enhance the API, ensuring it evolves with web content dynamics. Consequently, you gain access to a tool that not only meets current needs but anticipates future demands in AI search.
Understanding the Architecture of the Perplexity Search API
Perplexity architects the Search API with a focus on scalability and intelligence. At its core, the system employs a multi-tier storage setup, including over 400 petabytes in hot storage, to manage billions of documents efficiently. Machine learning models prioritize crawling and indexing, predicting URL importance based on factors like update frequency.
Furthermore, the content understanding module uses dynamic parsing logic, powered by frontier LLMs, to adapt to diverse website layouts. This module processes millions of queries hourly, self-improving through evaluation loops to optimize for completeness and quality. Engineers segment documents into sub-units, addressing context limitations in AI models and enabling precise ranking.
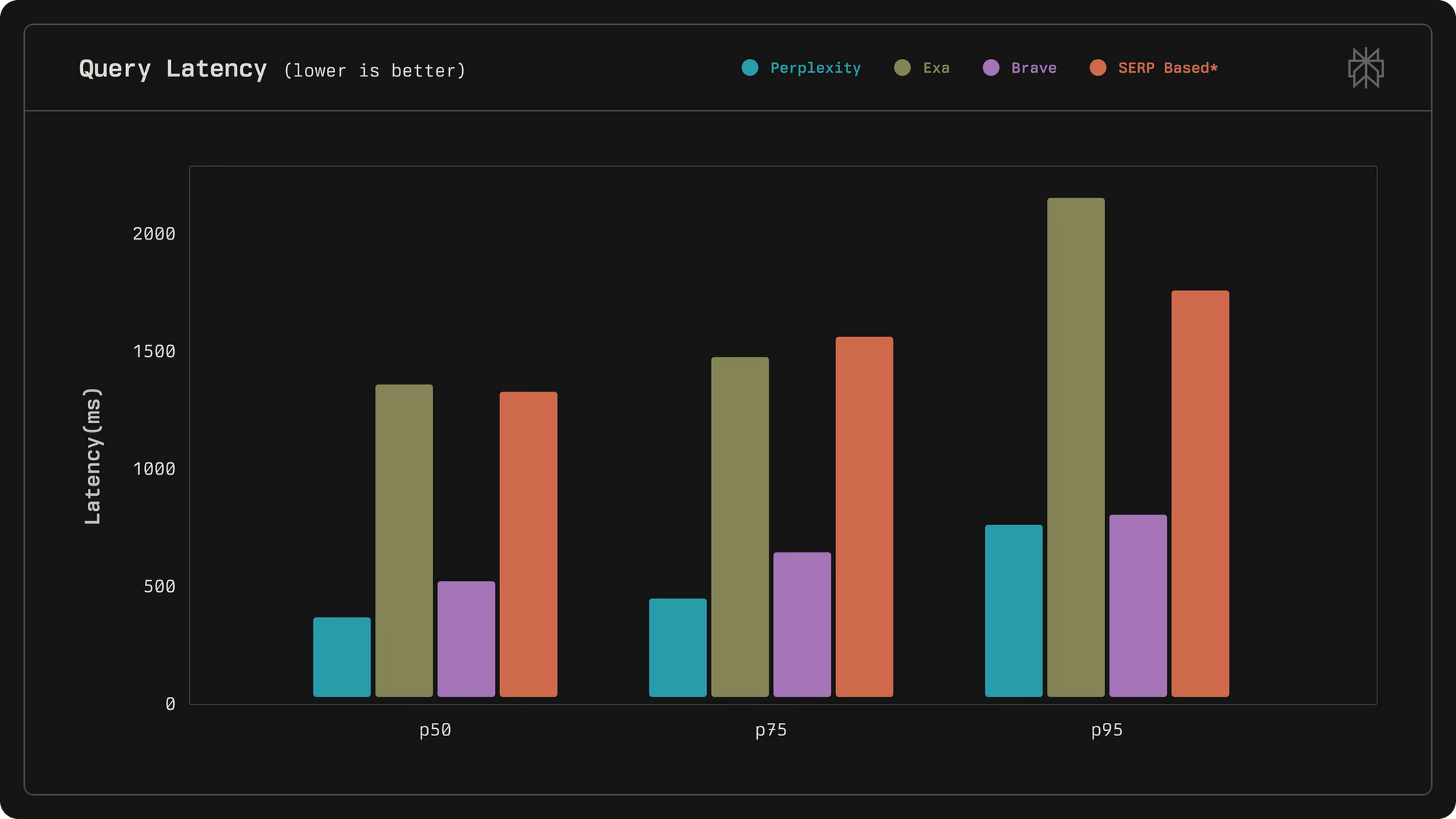
The retrieval pipeline follows a multi-stage process: initial hybrid retrieval generates candidates, prefiltering removes noise, and progressive ranking applies lexical, embedding-based, and cross-encoder models. This design leverages live signals for training, co-developed with Perplexity's products to boost accuracy.
Challenges in this architecture include balancing freshness with completeness under budget constraints. Perplexity resolves these through ML-driven prioritization and horizontal scaling. As a best practice, the team recommends hybrid signals and rigorous evaluations using their open-source framework, search_evals.
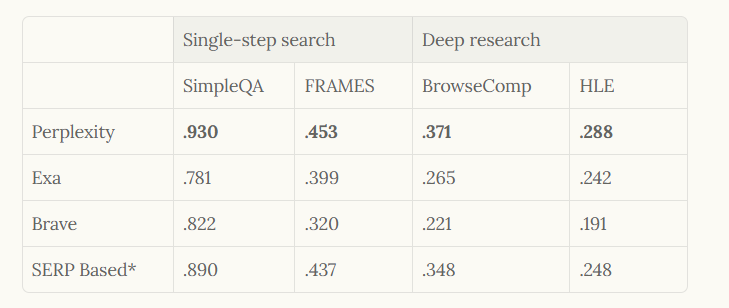
In evaluation, Perplexity employs benchmarks like SimpleQA for single-step searches and BrowseComp for deep research, achieving top scores such as 0.930 in SimpleQA. Therefore, this architecture not only supports high-volume usage but also sets a standard for AI-first search systems.
Pricing and Subscription Plans for the Perplexity Search API
Perplexity structures the Search API pricing to prioritize affordability and transparency. The base cost for raw web search results stands at $5 per 1,000 requests, with no additional token-based fees for this endpoint. This model suits developers who require straightforward search integration without complex billing.
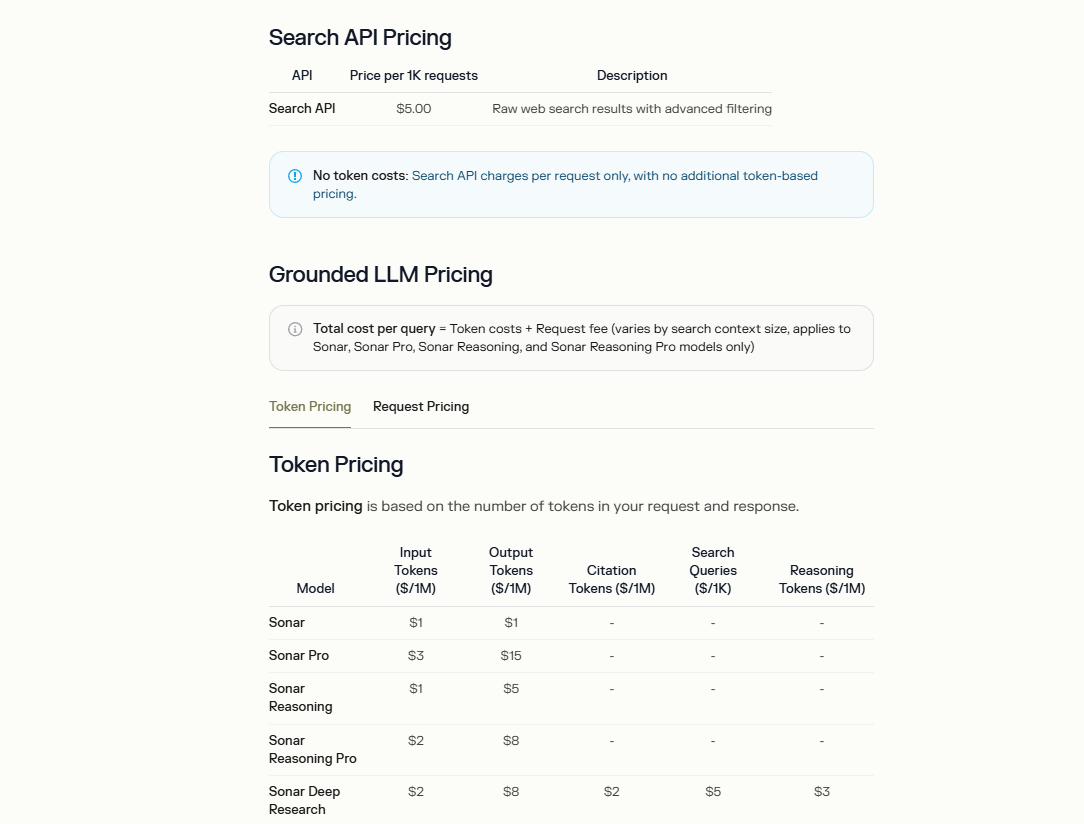
For grounded LLM integrations, pricing incorporates token costs plus a request fee, varying by model. For instance, the Sonar model charges $1 per million input tokens and $1 per million output tokens. Advanced variants like Sonar Pro escalate to $3 per million input and $15 per million output. Additionally, Sonar Deep Research includes charges for citation tokens ($2 per million), search queries ($5 per 1,000), and reasoning tokens ($3 per million).
Usage limits tie directly to these metrics, where one token approximates four characters in English text. Developers monitor consumption via the API portal's admin section, which handles billing and payments. However, the documentation does not outline free tiers for the Search API, emphasizing paid access for production use.
Consequently, this pricing enables scalable adoption. Small teams start with basic searches, while enterprises leverage advanced models for comprehensive applications. Always review the latest details in the official portal to align with your project's budget.
Getting Started: Signing Up and Obtaining an API Key
To begin using the Perplexity Search API, navigate to the API Platform. Create an account if you lack one, then access the API Keys tab to generate a new key. This key authenticates all requests, so store it securely.
Next, set the key as an environment variable. In Windows, use the command setx PERPLEXITY_API_KEY "your_api_key_here". For other systems, export it in your shell. This setup allows SDK clients to automatically detect the key, simplifying authentication.
Furthermore, consider using tools like python-dotenv for managing secrets in development environments. Load the .env file in your code to avoid hardcoding sensitive information. Once configured, you can instantiate clients in Python or Node.js seamlessly.
However, verify your setup by making a test request. If issues arise, consult the community forums or documentation for troubleshooting. This initial step ensures smooth progression to implementation.
Installing the Perplexity SDK for Python and Node.js
The Perplexity SDK facilitates interaction with the Search API in Python 3.8+ and Node.js. For Python, install it via pip: pip install perplexityai. This command fetches the package, including type definitions for parameters and responses.
In Node.js, although specific installation details vary, you typically use npm or yarn to add the package. The SDK supports synchronous and asynchronous operations, enhancing flexibility for different application architectures.
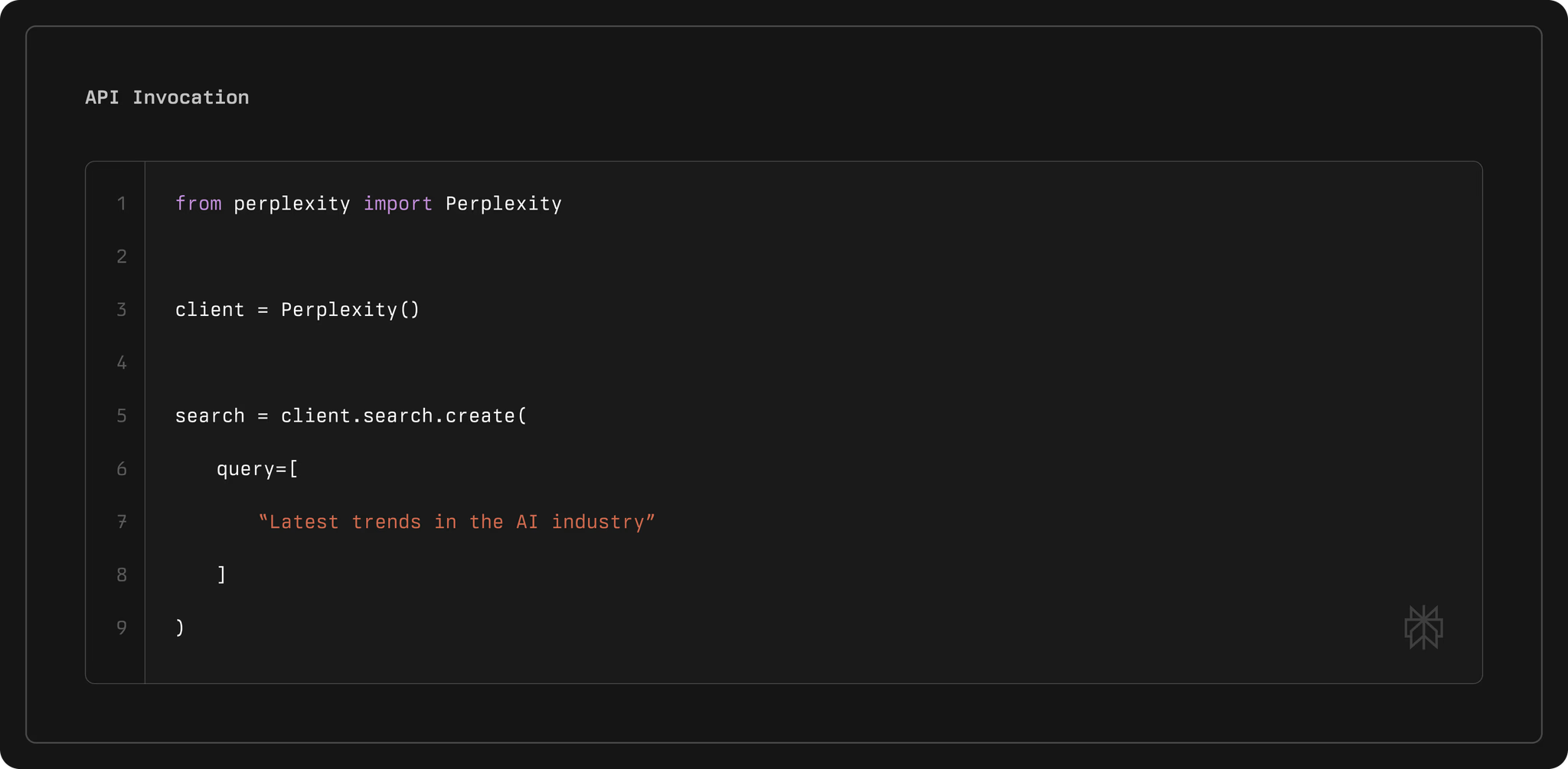
After installation, import the library. In Python, use from perplexity import Perplexity and create a client: client = Perplexity(). This client pulls the API key from environment variables automatically.
Moreover, the SDK provides comprehensive support for all API endpoints, ensuring you handle requests efficiently. Test the installation by importing without errors, confirming readiness for coding.
Making Your First Search Request with the Perplexity Search API
With the SDK installed, initiate your first request. In Python, use the client's search method with a query parameter. For example:
import os
from perplexity import Perplexity
client = Perplexity()
response = client.search("example query")
print(response)
This code sends a basic search and prints the structured response, including results and scores.
Furthermore, customize the request by adding filters, such as date ranges or domains, to refine outputs. The API returns JSON with document units, snippets, and relevance scores, ready for parsing in your application.
However, handle errors gracefully. Implement try-except blocks to catch authentication issues or rate limits. As you experiment, log responses to understand the output format deeply.
Consequently, this simple request demonstrates the API's ease of use, paving the way for more complex integrations.
Advanced Usage: Parameters, Filtering, and Customization
The Perplexity Search API supports extensive parameters for tailored searches. Specify query as the primary input, then add filter for media types or since/until for time-based restrictions. For instance, include geocode for location-specific results, though use it sparingly due to geo-tagging limitations.
Additionally, leverage advanced operators like exact phrases or exclusions to enhance precision. The hybrid system automatically applies semantic ranking, but you can influence it via model selection in grounded calls.
In code, extend the basic request:
response = client.search(
query="AI search APIs",
filter="news",
since="2025-01-01"
)
This fetches recent news articles, scored for relevance.
Moreover, for deep research, integrate with Sonar Deep Research models, incurring additional token costs but enabling step-by-step reasoning. Adjust reasoning_effort to control query depth.
Therefore, mastering these parameters allows you to optimize for specific use cases, from quick lookups to exhaustive analyses.
Integrating the Perplexity Search API into Your Applications
Developers integrate the Perplexity Search API into web apps, chatbots, and AI agents effortlessly. For a Node.js backend, use the SDK to handle asynchronous requests, feeding results into frontend components.
For example, in a research tool, query the API on user input, parse responses, and display cited snippets. Ensure compliance with rate limits by implementing caching or queuing.
Furthermore, combine it with other services. Pair with natural language processing libraries to preprocess queries, enhancing accuracy.
However, consider scalability. Monitor usage to avoid exceeding budgets, and use webhooks if available for updates.
As a result, this integration transforms static apps into dynamic, knowledge-driven systems.
Testing and Debugging with Apidog
Apidog serves as an all-in-one platform for API development, enabling you to design, debug, mock, and test endpoints like the Perplexity Search API. It streamlines workflows by simulating real-world scenarios and catching bugs early.
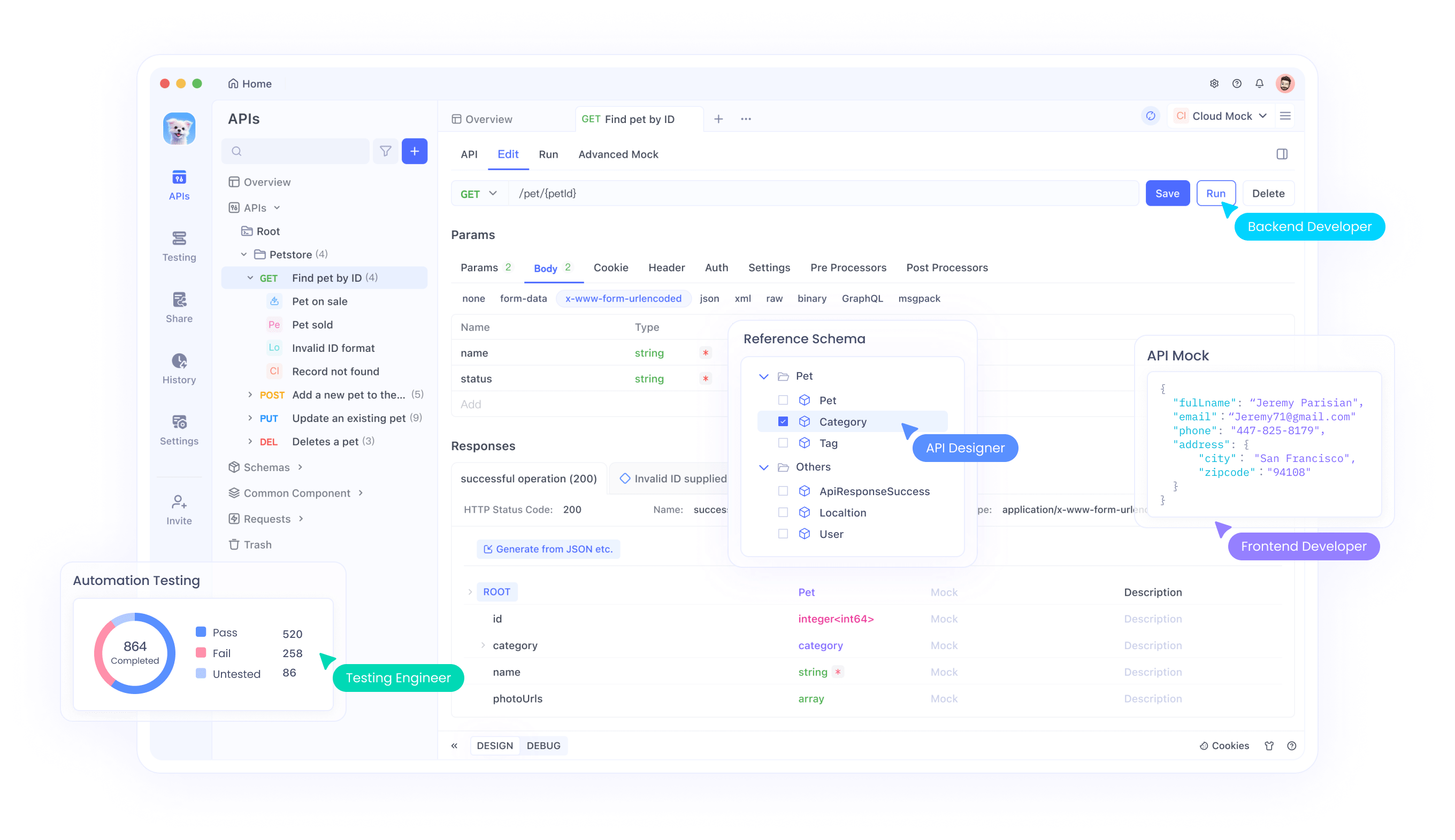
To use Apidog with the Perplexity Search API, import the API spec into Apidog's interface. Create test cases for various queries, validating responses against expected structures. Apidog's AI features automate documentation and testing, reducing manual effort.
Furthermore, mock the API for offline development, ensuring your app handles edge cases. Generate references and reports to maintain quality.
Consequently, Apidog accelerates debugging, making it indispensable for robust integrations.
Best Practices for Evaluating and Optimizing Performance
Evaluate the Perplexity Search API using the open-source search_evals framework, benchmarking against suites like FRAMES and HLE. This tool assesses latency and quality neutrally.
Implement hybrid retrieval in your pipelines for balanced results. Regularly update parsing logic to adapt to web changes.
Moreover, incorporate user feedback to fine-tune queries, mirroring Perplexity's approach.
However, avoid over-reliance on defaults; customize parameters for your domain.
Therefore, these practices ensure optimal performance and reliability.
Common Challenges and Troubleshooting Tips
Users encounter authentication errors; double-check environment variables. For latency issues, optimize query complexity.
Furthermore, handle rate limits with exponential backoff in code.
If results lack relevance, refine filters or use advanced models.
As a result, proactive troubleshooting maintains smooth operations.
Future Developments and Community Resources
Perplexity continues enhancing the API with research-driven updates. Join the developer community for insights and events.
Furthermore, explore open-source contributions to stay ahead.
Conclusion
The Perplexity Search API empowers developers to harness advanced search in AI applications. By following this guide, you implement it effectively, leveraging tools like Apidog for efficiency. Continue experimenting to unlock its full potential.


