
Audio processing has rapidly gained importance in artificial intelligence, powering applications like virtual assistants, transcription tools, and voice-driven interfaces. OpenAI, a pioneer in AI innovation, recently unveiled its next-generation audio models, setting a new standard for speech-to-text and text-to-speech capabilities. These models namely gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-mini-tts deliver exceptional performance, enabling developers to create more accurate and responsive voice-based solutions. In this blog post, we’ll dive into how you can access these models through OpenAI’s API, offering a detailed, technical roadmap to get you started.
Let’s proceed by exploring what these new models offer.
What Are OpenAI’s New Audio Models?
OpenAI’s latest audio models tackle real-world challenges in audio processing, such as noisy environments and diverse speech patterns. To effectively use the API, you first need to understand each model’s capabilities.

Here’s a breakdown.
Gpt-4o-transcribe: Precision Speech-to-Text
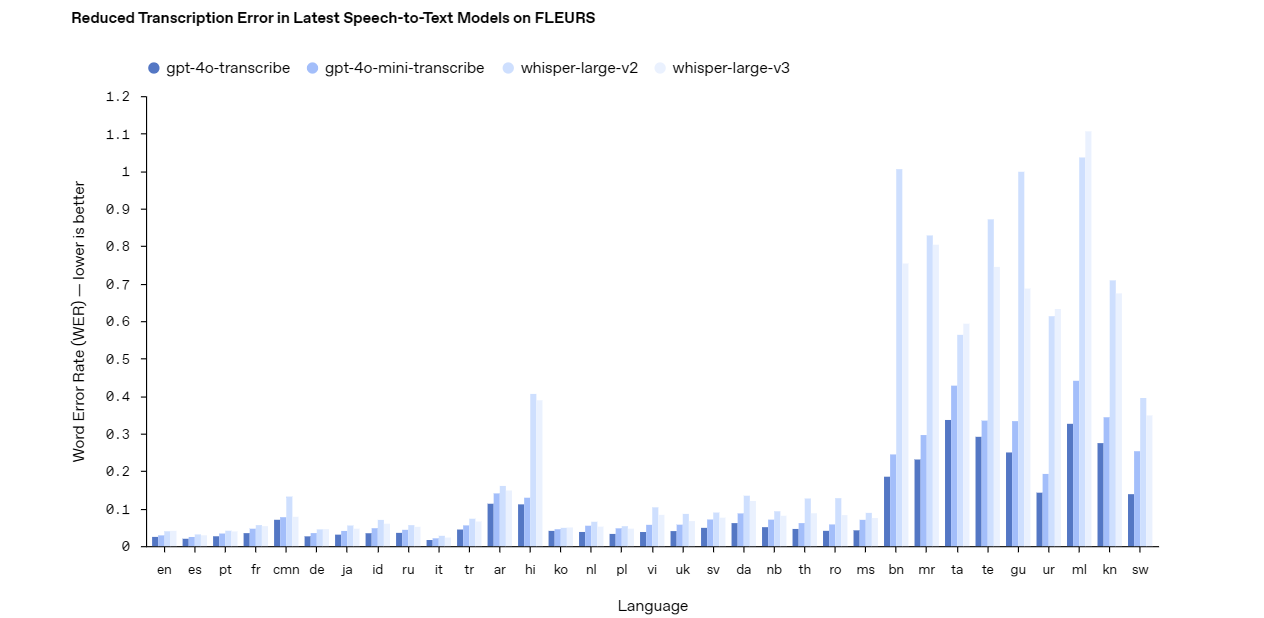
The gpt-4o-transcribe model excels as a robust speech-to-text solution. It delivers high accuracy, even in tough conditions like background noise or rapid speech. Developers can rely on this model for applications requiring precise transcription, such as live captioning, voice command systems, or audio analysis tools. Its advanced design makes it a top choice for complex, high-stakes projects.
Gpt-4o-mini-transcribe: Lightweight Transcription
In contrast, the gpt-4o-mini-transcribe model offers a lighter, more efficient alternative. While it sacrifices some accuracy compared to gpt-4o-transcribe, it consumes fewer resources, making it ideal for simpler tasks. Use this model for applications like casual voice memos or basic command recognition where speed and efficiency outweigh the need for perfect precision.

Gpt-4o-mini-tts: Customizable Text-to-Speech
Shifting to text-to-speech, the gpt-4o-mini-tts model shines with its natural-sounding output. Unlike traditional text-to-speech systems, this model allows customization of tone, style, and emotion through instructions. This flexibility suits projects like personalized voice agents, audiobook narration, or customer service bots that need a tailored voice experience.
With these models in mind, let’s move on to understanding the pricing structure before accessing them via the API.
Pricing for OpenAI’s Audio Models API
Before integrating OpenAI’s audio models into your projects, it’s crucial to understand the associated costs. OpenAI offers a usage-based pricing model for its audio APIs, which varies depending on the specific model and the volume of usage. Below, we outline the key pricing details for gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-mini-tts.
Speech-to-Text Models: gpt-4o-transcribe and gpt-4o-mini-transcribe
For speech-to-text services, OpenAI charges based on the duration of the audio processed. The rates differ between the full gpt-4o-transcribe model and the lightweight gpt-4o-mini-transcribe:
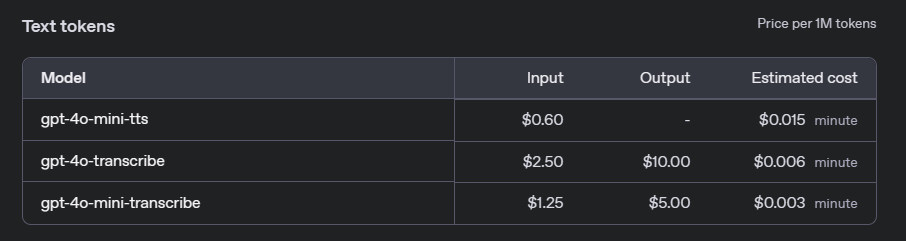
- gpt-4o-transcribe: $0.006 per minute of audio.
- gpt-4o-mini-transcribe: $0.003 per minute of audio.
These rates make gpt-4o-mini-transcribe a cost-effective option for applications where extreme accuracy is not critical, while gpt-4o-transcribe is better suited for high-precision tasks.
Text-to-Speech Model: gpt-4o-mini-tts
For text-to-speech, pricing is based on the number of characters in the input text:
- gpt-4o-mini-tts: $0.015 per character.
This pricing allows for flexibility, especially for applications that generate varying lengths of audio output, such as interactive voice responses or audiobook generation.
Free Tier and Usage Limits
OpenAI provides a free tier for developers to experiment with the audio models before committing to paid usage. New users receive $5 in free credits, which can be applied to any API services, including the audio models. Additionally, usage is subject to rate limits to ensure fair access. For example, the speech-to-text API has a limit of 100 requests per minute, while the text-to-speech API allows up to 50 requests per minute.
Understanding these costs will help you budget effectively as you integrate the audio models into your applications. Now, let’s move on to accessing these models via the API.
How to Access OpenAI’s Audio Models API: Step-by-Step
Accessing OpenAI’s API requires a structured approach. Follow these steps to integrate the audio models into your projects.
Step 1: Secure an API Key
First, obtain an API key from OpenAI. Visit the OpenAI platform, create an account if you haven’t already, and generate a key in the developer dashboard. Store this key securely—it’s your gateway to the API and must remain confidential.

Step 2: Install the OpenAI Python Library
Next, install the OpenAI Python library to simplify API interactions. Open your terminal and run this command:
pip install openai
This library provides a clean interface for sending requests, saving you from manual HTTP calls.
Step 3: Authenticate Your API Key
Before sending requests, authenticate your script with the API key. Add this code to your Python file:
import openai
openai.api_key = 'your-api-key-here'
Replace 'your-api-key-here' with your actual key. This step ensures your requests are authorized.
Step 4: Send Requests to the Audio Models
Now, let’s make requests to the audio models. Each model uses specific endpoints and parameters. Below are examples for both speech-to-text and text-to-speech.
Speech-to-Text with gpt-4o-transcribe
To transcribe audio using gpt-4o-transcribe, send an audio file to the API. Here’s a sample script:
with open('audio_file.wav', 'rb') as audio_file:
response = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=audio_file
)
print(response['text'])
This code opens an audio file (e.g., audio_file.wav) and prints the transcribed text. Ensure your file is in a supported format like WAV or MP3.
Text-to-Speech with gpt-4o-mini-tts
For text-to-speech with gpt-4o-mini-tts, provide text and optional voice instructions. Try this example:
response = openai.Audio.synthesize(
model="gpt-4o-mini-tts",
text="Welcome to our service! How can I help you?",
voice_instructions="Use a warm, professional tone."
)
with open('output_audio.wav', 'wb') as audio_file:
audio_file.write(response['audio'])
This generates an audio file (output_audio.wav) with a customized voice. Experiment with voice_instructions to adjust the output.
With these steps complete, you’re ready to integrate the models into real-world applications.
Practical Applications of OpenAI’s Audio Models
The OpenAI audio models unlock numerous possibilities. Here are some examples to spark inspiration.
Voice Assistants
Build a voice assistant that listens and responds naturally. Combine gpt-4o-transcribe for command recognition and gpt-4o-mini-tts for spoken replies, creating a seamless user experience.
Transcription Services
Develop a transcription tool for meetings or lectures. Use gpt-4o-transcribe to convert audio to text with high accuracy, then offer users downloadable transcripts.
Accessibility Solutions
Enhance accessibility by converting text to speech for visually impaired users. The gpt-4o-mini-tts model’s customization ensures an engaging, human-like reading experience.
Customer Support Automation
Create an AI-driven support agent. Pair gpt-4o-transcribe to understand inquiries with gpt-4o-mini-tts to respond in a branded voice, improving customer satisfaction.
These examples highlight the versatility of the API. Now, let’s discuss best practices to optimize your implementation.
Best Practices for Using OpenAI’s Audio Models API
To maximize performance, follow these guidelines.
Optimize Audio Quality
Always use high-quality audio inputs. Reduce background noise and choose a clear microphone to improve transcription accuracy with gpt-4o-transcribe or gpt-4o-mini-transcribe.
Select the Right Model
Match the model to your needs. For critical accuracy, pick gpt-4o-transcribe. For lightweight tasks, gpt-4o-mini-transcribe suffices. Evaluate resource constraints before deciding.
Leverage Customization
With gpt-4o-mini-tts, experiment with voice instructions. Tailor the output to your application—whether it’s a cheerful greeting or a calm narration.
Test Thoroughly
Test your integration with diverse audio samples. Verify that gpt-4o-transcribe handles accents and noise, and ensure gpt-4o-mini-tts delivers consistent voice quality.
Why Use Apidog for API Testing?
Speaking of tools, Apidog deserves a closer look. This platform streamlines API development by offering features like request simulation, response validation, and performance monitoring. When working with OpenAI’s API, Apidog lets you test endpoints like gpt-4o-transcribe without writing extensive code. Its intuitive interface saves time, letting you focus on building rather than debugging.

Conclusion
OpenAI’s new audio models—gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-mini-tts—mark a leap forward in audio processing technology. This guide has shown you how to access them via the API, from securing a key to coding practical examples. Whether you’re enhancing accessibility or automating support, these models offer powerful solutions.
To make your journey smoother, use Apidog. Download Apidog for free and simplify your API testing, ensuring your integrations run flawlessly. Start experimenting with OpenAI’s audio models today and unlock their full potential.



