The relentless march of artificial intelligence is reshaping industries, and software engineering is at the forefront of this transformation. AI-powered tools are no longer futuristic concepts but practical assistants, augmenting developer capabilities and streamlining complex workflows. OpenAI, a prominent name in AI research, has recently unveiled its latest contribution to this evolving landscape: ChatGPT Codex, a cloud-based software engineering agent designed to tackle a multitude of coding tasks in parallel. This new offering, initially available to ChatGPT Pro, Team, and Enterprise users, with Plus and Edu versions on the horizon, promises to redefine how developers interact with their codebases and build software.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!
The Dawn of AI-Powered Software Engineering: Introducing Codex

Imagine a dashboard prompting, "What should we code next?" complete with a prompt box, repository and branch selectors, and a task list, all set against a pastel, code-themed backdrop. This is the gateway to Codex, an agent poised to become an indispensable part of a developer's toolkit. Codex is engineered to handle a diverse range of tasks – from writing new features and answering intricate questions about a codebase to fixing bugs and proposing pull requests for review. Each task is meticulously processed in its own cloud sandbox environment, preloaded with the specific repository, ensuring isolation and focus.
At its core, Codex is powered by codex-1, a specialized version of OpenAI's o3 model, fine-tuned for the nuances of software engineering. This model's prowess stems from rigorous reinforcement learning, where it was trained on real-world coding tasks across various environments. The objective was clear: generate code that not only functions flawlessly but also mirrors human stylistic preferences, adheres precisely to instructions, and can iteratively run tests until a passing result is achieved. The rollout of Codex signifies a major step towards more intelligent and autonomous coding assistance.
Under the Hood: How Codex Operates
Accessing Codex is straightforward for eligible ChatGPT users, with a dedicated section in the sidebar. Developers can assign new coding tasks by typing a prompt and initiating the "Code" command, or pose questions about their codebase using the "Ask" function.
The true power of Codex lies in its parallel processing capabilities. Each task is handled independently within a separate, isolated cloud sandbox. This environment comes preloaded with the relevant codebase, allowing Codex to read and edit files, execute commands (including test harnesses, linters, and type checkers), and operate without interference from other ongoing tasks. Task completion times vary, typically ranging from one to thirty minutes depending on complexity, and users can monitor progress in real time.
A crucial aspect of Codex is its commitment to verifiable work. Once a task is completed, Codex commits its changes within its environment. It doesn't just present the final code; it provides verifiable evidence of its actions through citations of terminal logs and test outputs. This transparency allows developers to trace each step taken during task completion, fostering trust and enabling thorough review. Users can then decide to request further revisions, open a GitHub pull request, or directly integrate the changes into their local development environment. Furthermore, the Codex environment can be configured to closely mirror the user's actual development setup, ensuring compatibility and relevance.
Guiding the Agent: The Role of AGENTS.md and System Directives
To further enhance its effectiveness and tailor its behavior to specific project needs, Codex can be guided by AGENTS.md files placed within a repository. These text files, much like the familiar README.md, serve as a communication channel between human developers and the AI agent. Through AGENTS.md, developers can inform Codex on how to navigate the codebase, which commands to run for testing, and how best to adhere to the project's established coding standards and practices. As with human developers, Codex agents perform optimally when provided with well-configured development environments, reliable testing setups, and clear documentation.
The underlying system message for codex-1 also reveals an explicit set of instructions that govern its behavior. For instance, when modifying files, Codex is instructed not to create new branches, to use git for committing changes (retrying on pre-commit failures), and to ensure the worktree is left in a clean state. It emphasizes that only committed code will be evaluated and that existing commits should not be amended.
The AGENTS.md specification is quite detailed. Its scope is the entire directory tree rooted at its location, and its instructions take precedence based on nesting depth, though direct user prompts can override them. A key directive is that if AGENTS.md includes programmatic checks, Codex must run all of them and strive to validate their success after all code changes, even for seemingly simple modifications like documentation updates. Citation instructions are also rigorous, demanding precise referencing of file paths and terminal outputs for any browsed files or executed commands, ensuring a clear audit trail.
Putting Codex to the Test: Performance and Benchmarks
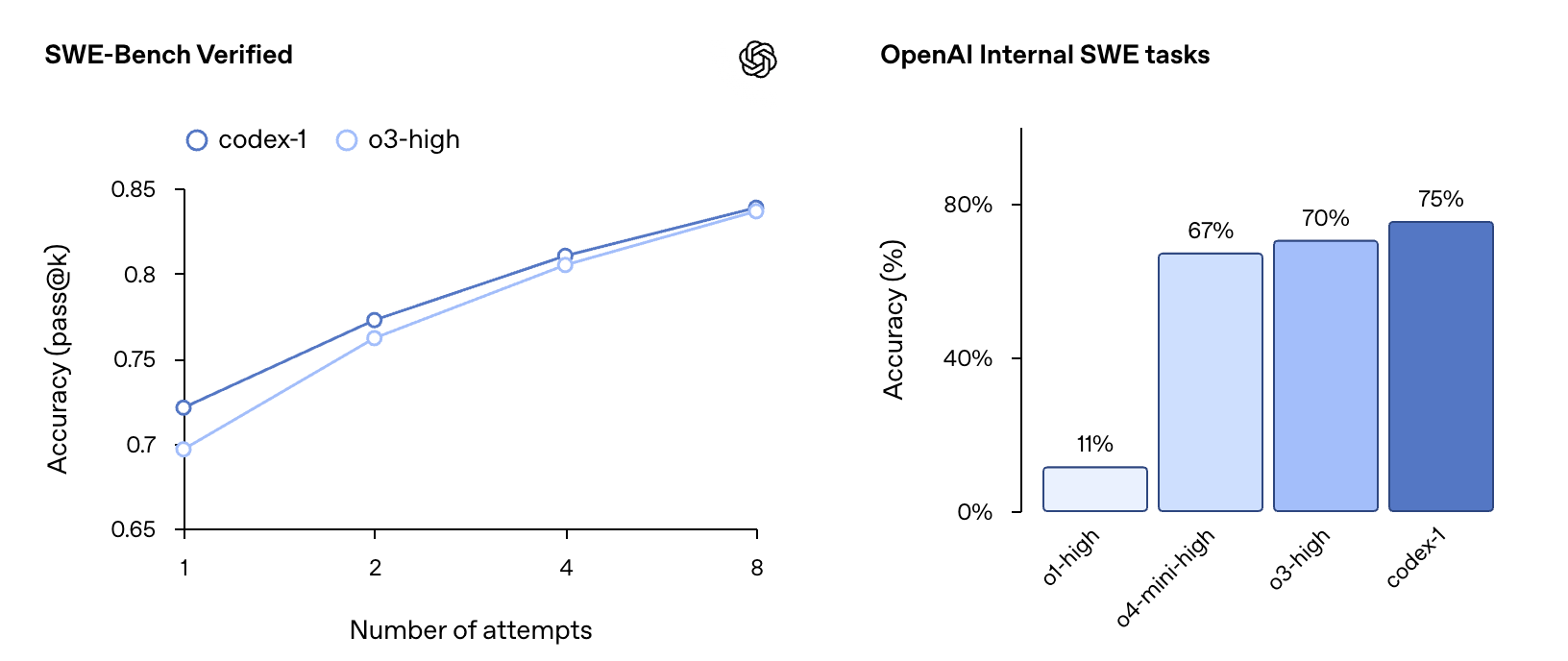
OpenAI reports that codex-1 demonstrates strong performance on coding evaluations and internal benchmarks, even without extensive customization through AGENTS.md files or specific scaffolding. On the SWE-Bench Verified benchmark, codex-1 showed a pass@k accuracy progression from 67% at k=1 to 75% at k=8, outperforming o3-high (which scored 70% at k=8 on a slightly different subset). On OpenAI's internal Software Engineering (SWE) tasks, a curated set of real-world internal challenges, codex-1 achieved an accuracy of 70%, significantly higher than o1-high (25%), o4-mini-high (40%), and o3-high (61%). These tests were conducted with codex-1 at a maximum context length of 192k tokens and a medium 'reasoning effort', reflecting the settings available in the product.
Building with Confidence: Safety, Trust, and Ethical Considerations


Codex is being released as a research preview, aligning with OpenAI's strategy of iterative deployment. This approach allows for learning and refinement based on real-world usage. Security and transparency were paramount in Codex's design. The ability for users to verify outputs through citations, terminal logs, and test results is a cornerstone of this philosophy—a safeguard that becomes increasingly vital as AI models handle more complex coding tasks independently.
When faced with uncertainty or test failures, the Codex agent is designed to explicitly communicate these issues, enabling users to make informed decisions. However, OpenAI underscores that it remains essential for users to manually review and validate all agent-generated code before integration and execution.
Addressing the potential for misuse, particularly in areas like malware development, is a critical concern. Codex has been trained to identify and precisely refuse requests aimed at creating malicious software, while still distinguishing and supporting legitimate, advanced tasks that might involve similar techniques (e.g., low-level kernel engineering). Enhanced policy frameworks and rigorous safety evaluations, detailed in an addendum to the o3 System Card, reinforce these boundaries.
The agent operates entirely within a secure, isolated container in the cloud. During task execution, internet access is disabled, restricting interactions solely to the code explicitly provided via GitHub repositories and user-configured pre-installed dependencies. This means the agent cannot access external websites, APIs, or other services, significantly mitigating security risks.
A Human Touch: Aligning with Developer Preferences and Workflows
A primary goal during the training of codex-1 was to align its outputs closely with human coding preferences and standards. Compared to the general-purpose OpenAI o3, codex-1 consistently produces cleaner patches that are more readily reviewable by humans and easier to integrate into standard workflows. This is demonstrated through several examples of fixes applied to popular open-source projects:
Project: Astropy (Python Astronomy Library)
- The Bug: The
separability_matrixfunction incorrectly computed separability for nestedCompoundModelinstances. For example, if a compound model likem.Linear1D(10) & m.Linear1D(5)was nested within another, the resulting matrix erroneously indicated dependencies where none existed. - Codex's Solution:
- A targeted modification was made to the
_cstackfunction inastropy/modeling/separable.py. - This change correctly handled the dimensions and values of the right-hand side matrix when it represented a pre-computed array (i.e., a nested model).
- Testing: A precise regression test was added to
test_separable.pyto confirm the fix, ensuring the output was the expected block-diagonal separability matrix for nested models. - Comparison: This fix was noted as more direct and less verbose than a potential alternative from
o3, which had included extensive explanatory comments.
Project: Matplotlib (Python Plotting Library)
- The Bug: An issue in
mlab._spectral_helpercaused incorrect window correction due to an unnecessarynp.abs()call. This led to inaccurate results for windows with negative values (e.g., theflattopwindow). - Codex's Solution:
- The
np.abs()calls were removed from(np.abs(window)**2).sum()andnp.abs(window).sum()**2. - These were changed to
(window.conjugate() * window).sum()andwindow.sum()**2respectively. - This modification ensures that scaling uses the window's actual values, accurately preserving power.
- Testing: A new test,
test_psd_windowarray_negative, was added tolib/matplotlib/tests/test_mlab.pyto specifically verify this correction using a window containing negative values.
Project: Django (Python Web Framework)
- The Bug: Duration-only expressions (e.g.,
F('estimated_time') + datetime.timedelta(1)) failed on SQLite and MySQL, raising adecimal.InvalidOperationerror. This was due to issues in how duration values were converted. - Codex's Solution:
- The
convert_durationfield_valuemethod indjango/db/backends/base/operations.pywas refined to robustly handle various input types for duration (such asNone,timedelta,string, andint). - The compilation of sides for
DurationExpressionindjango/db/models/expressions.pywas adjusted, ensuringformat_for_duration_arithmeticis applied more selectively, primarily when combined with date/time types. - Testing: A new test,
test_durationfield_only_expression, was added intests/expressions/tests.pyto validate this fix. - Comparison: The
o3solution for this Django issue was described as more extensive in its type checking and parsing logic withinconvert_durationfield_value, offering a very detailed approach to handling different string and numeric representations of durations.
Project: Expensify (ReportUtils.ts - TypeScript)
- The Issue: Members' room names were not updating in the Left Hand Navigator (LHN) after clearing the cache.
- Codex's Proposed Solution (based on provided diffs related to report name caching):
- The "Codex" diff modified the
getCacheKeyfunction to includepolicyName. This change could make cache keys more specific, potentially preventing staleness if policy names influence room titles. - Alternative
OpenAI o3Proposal: - The "OpenAI o3" diff suggested a more structural solution to cache invalidation: ensuring the
reportNameCacheis cleared wheneverONYXKEYS.COLLECTION.POLICYupdates. This directly addresses stale data by proactively refreshing the cache when underlying policy information (which can affect room names) changes. - Insight: This example highlights how AI can propose different strategies—from refining cache keys to implementing broader invalidation mechanisms—to tackle such issues.
These examples collectively illustrate Codex's capacity to understand complex issues and implement targeted, effective solutions, frequently including the necessary test cases to ensure correctness.
Extending Reach: Updates to the Codex CLI
Complementing the cloud-based agent, OpenAI has also updated Codex CLI, a lightweight, open-source coding agent that runs directly in the terminal. A new, smaller version of codex-1, named codex-mini-latest (a specialized version of o4-mini), is now the default model in Codex CLI. It's optimized for low-latency code Q&A and editing, retaining strong instruction-following and style capabilities.
Connecting a developer account to Codex CLI has also been simplified. Instead of manual API token generation, users can now sign in with their ChatGPT account and select their API organization, with the CLI handling automatic API key configuration. Plus and Pro users signing in this way can also redeem free API credits.
Access, Affordability, and Aspirations: Availability, Pricing, and Limitations
Codex is currently rolling out to ChatGPT Pro, Enterprise, and Team users globally, with Plus and Edu support anticipated soon. Initial access will be generous and at no additional cost for several weeks, allowing users to explore its capabilities. Subsequently, OpenAI will introduce rate-limited access and flexible pricing options for on-demand usage. For developers using codex-mini-latest via the API, it is priced at $1.50 per 1M input tokens and $6 per 1M output tokens, with a 75% prompt caching discount.
As a research preview, Codex has limitations. It currently lacks features like image inputs for frontend development and the ability to course-correct the agent mid-task. Delegating tasks to a remote agent also introduces a latency compared to interactive editing, which may require some adjustment in workflow. OpenAI envisions that interacting with Codex agents will increasingly resemble asynchronous collaboration with human colleagues.
The Road Ahead: The Future of AI in Software Engineering with Codex
OpenAI imagines a future where developers drive the work they want to own and delegate the rest to highly capable AI agents, leading to increased speed and productivity. To realize this, they are building a suite of Codex tools supporting both real-time collaboration and asynchronous delegation. While AI pairing tools like Codex CLI are becoming industry norms, the asynchronous, multi-agent workflow introduced by Codex in ChatGPT is seen as the future de facto standard for producing high-quality code.
Ultimately, these two interaction modes—real-time pairing and task delegation—are expected to converge. Developers will collaborate with AI agents across their IDEs and everyday tools for Q&A, suggestions, and offloading longer tasks in a unified workflow. Future plans include more interactive and flexible agent workflows, allowing developers to provide guidance mid-task, collaborate on implementation strategies, and receive proactive progress updates. Deeper integrations are also planned across tools like GitHub, Codex CLI, ChatGPT Desktop, issue trackers, and CI systems.
Software engineering is one of the first industries to witness significant AI-driven productivity gains, opening new possibilities for individuals and small teams. While optimistic about these advancements, OpenAI is also collaborating with partners to understand the broader implications of widespread agent adoption on developer workflows and skill development across diverse populations.
The launch of ChatGPT Codex is more than just a new tool; it's a glimpse into a future where human ingenuity and artificial intelligence collaborate more seamlessly than ever before to build the next generation of software. This is just the beginning, and the potential for what developers can build with Codex is vast and exciting.


