
💡Ready to take your API development to the next level? Download Apidog for free today and streamline your workflow! 
Run OlympicCoder 32B Locally: Step-by-Step Guide for Developers
OlympicCoder 32B is changing the way developers approach local AI-assisted coding. As a 32-billion parameter open-source language model, it’s engineered for efficient code generation, debugging, and natural language understanding—right on your own hardware. Running OlympicCoder 32B locally gives you full control over your code, better privacy, and flexibility to tailor the model to your workflow. In this tutorial, you’ll learn how to set up OlympicCoder 32B on your machine using Ollama, a tool designed for smooth deployment of large language models.
For API developers and backend engineers seeking robust coding support alongside their existing API tools, OlympicCoder 32B offers an opportunity to bring powerful AI in-house—complementing tools like Apidog to further accelerate your API design, testing, and documentation workflows.
What is OlympicCoder 32B?
OlympicCoder 32B is a large language model built for developers. Its architecture is tailored for:
- Coding tasks: Code completion, bug fixing, and code documentation
- Natural language workflows: Technical Q&A, summarization, and explanation
With 32B parameters, it provides a strong balance between advanced capabilities and manageable resource requirements, making it suitable for local deployment on modern workstations.
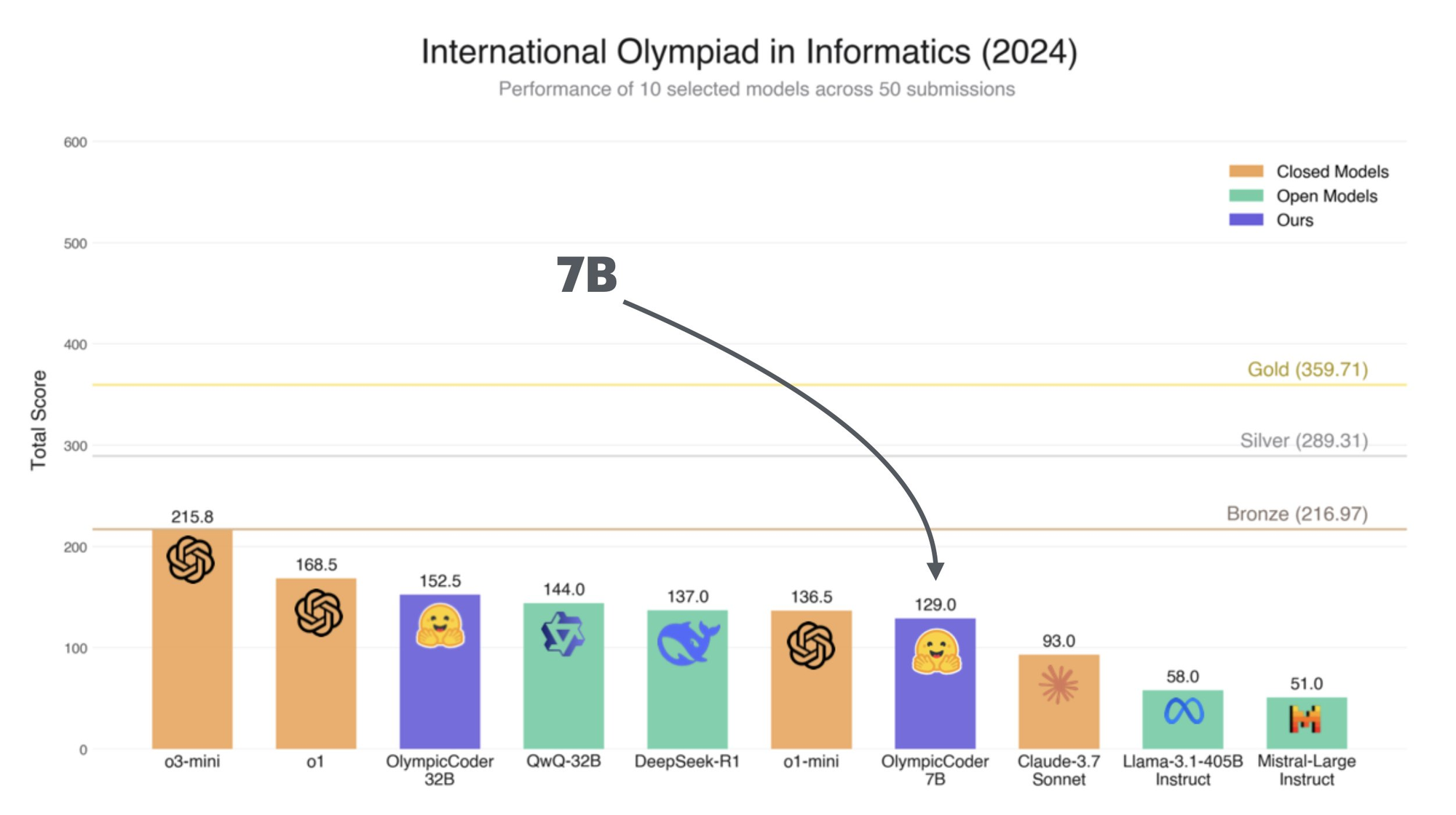
OlympicCoder 32B Benchmarks: Performance in Real Coding Tasks
[ ]
]
How does OlympicCoder 32B compare to other leading models like Claude 3.7 Sonnet? Here are benchmark highlights:
Coding Tasks
- Code Completion: 85% accuracy on Python snippets
- Bug Fixing: Corrects bugs in 78% of test cases
- Documentation Generation: Produces clear, context-aware documentation
Natural Language Understanding
- Question Answering: 82% on the TruthfulQA benchmark
- Summarization: Delivers concise summaries for technical docs
System Performance
- Inference Speed: ~20 tokens/sec on high-end GPUs (NVIDIA RTX 3090)
- VRAM Requirement: ~16GB for smooth local operation
These results make OlympicCoder 32B a versatile choice for developers who want reliable, private AI coding assistance—especially when working with sensitive or proprietary code.
System Requirements: Can You Run OlympicCoder 32B Locally?
Before you begin, make sure your system meets these requirements:
Hardware
- GPU: NVIDIA, minimum 16GB VRAM (e.g., RTX 3090, A100)
- RAM: 32GB or more
- Storage: At least 50GB free
Software
- OS: Linux (Ubuntu 20.04+ recommended) or macOS (M1/M2 or Intel)
- Dependencies:
- Python 3.8+
- CUDA Toolkit (for NVIDIA GPUs)
- Ollama (see install instructions below)
How to Install and Run OlympicCoder 32B Using Ollama
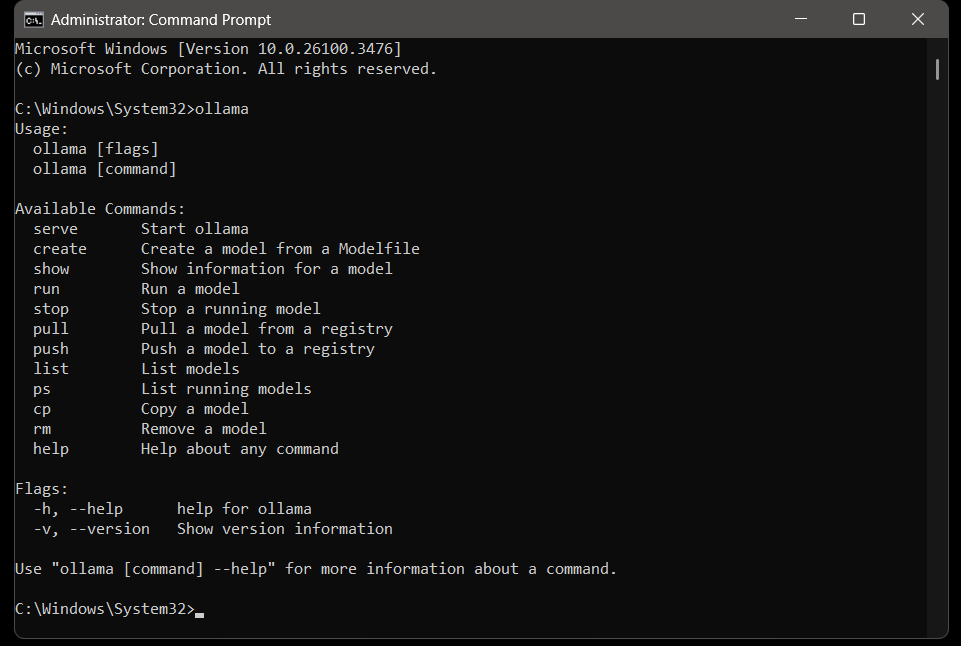
Step 1: Install Ollama
[ ]
]
Ollama simplifies model management and local inference. To install:
On Linux:
curl -fsSL <https://ollama.ai/install.sh> | sh
On macOS:
brew install ollama
To verify the installation:
ollama --version
You should see the version number.
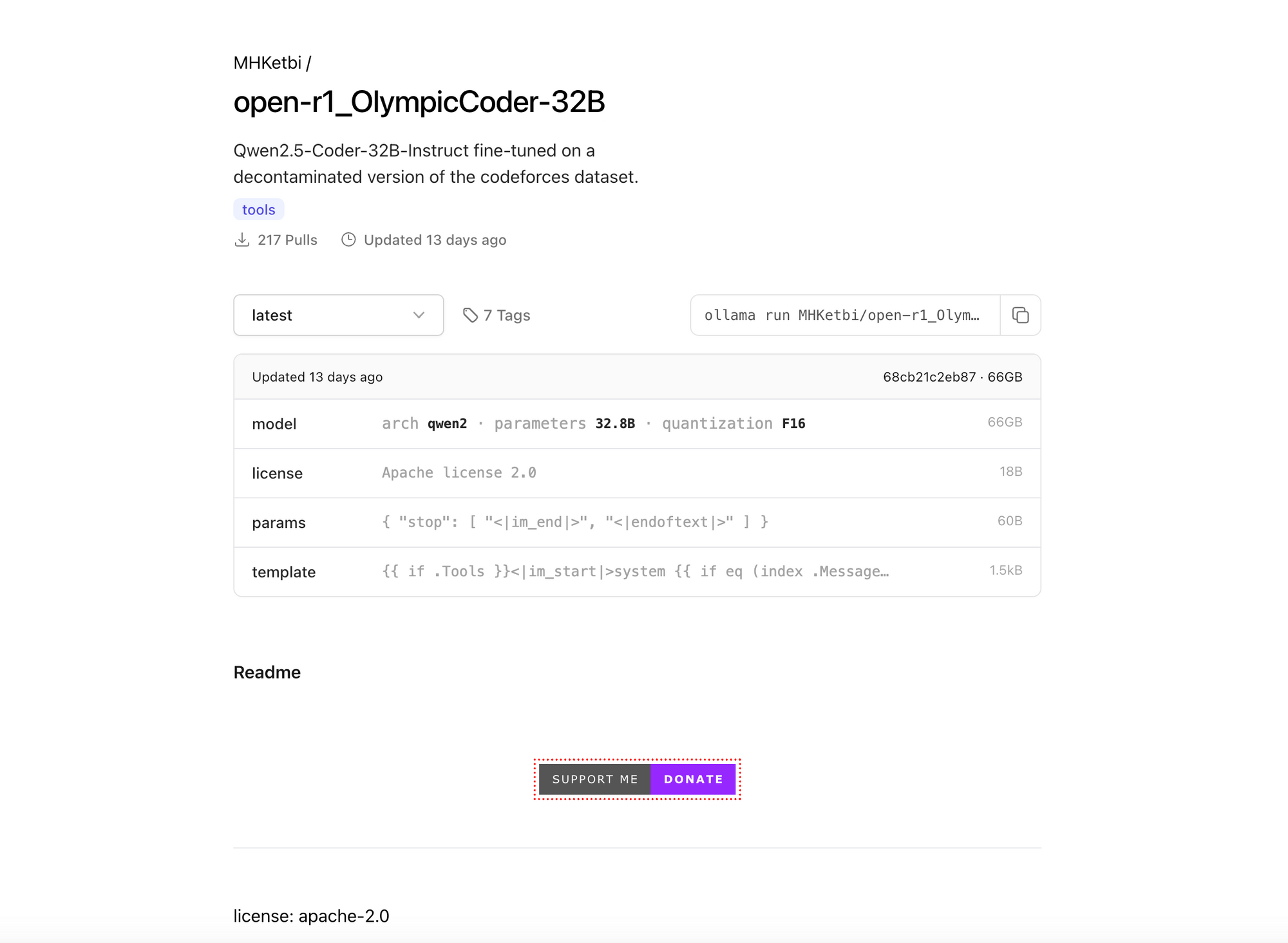
Step 2: Download OlympicCoder 32B Model
Download Olympic Coder 32B from Ollama.com
[ ]
]
Use Ollama to pull the model:
ollama pull MHKetbi/open-r1_OlympicCoder-32B
Downloading may take some time depending on your connection.
Step 3: Configure Ollama for Best Performance
-
GPU Selection: Ensure your NVIDIA GPU and CUDA drivers are installed. Ollama will auto-detect and use your GPU.
-
Check GPU Usage:
nvidia-smiConfirm Ollama is utilizing the GPU.
-
Optional: Limit VRAM Usage
If you face memory issues, set a VRAM cap:export OLLAMA_GPU_MEMORY_LIMIT=16000
Step 4: Run OlympicCoder 32B Locally
Start the model with:
ollama run MHKetbi/open-r1_OlympicCoder-32B
This opens an interactive session for code generation, debugging, and more.
Step 5: Sample Use Cases
Code Generation
Generate a Python function to calculate the factorial of a number.
Debugging
Fix the following Python code: [paste your code here]
Documentation
Explain the purpose of the following function: [paste function here]
The model responds in real time, providing context-aware, developer-centric answers.
Troubleshooting Guide
Common Issues & Solutions
-
Model Not Downloading:
Check your internet connection and view logs withjournalctl -u ollama -f -
GPU Not Detected:
Verify CUDA installation withnvcc --versionReinstall Ollama if needed.
-
Out of Memory Errors:
Lower VRAM usage or upgrade your hardware.
Enhancing Your API Workflow
Running OlympicCoder 32B locally lets you keep sensitive code in-house while boosting productivity. Pairing it with tools like Apidog allows you to automate API design, mock testing, and documentation—combining the best of AI code assistance with streamlined API development.
Conclusion
OlympicCoder 32B, deployed with Ollama, empowers developers to bring advanced coding AI onto their own machines. With robust benchmarks and flexible customization, it’s a valuable asset for anyone building, testing, or documenting code—especially when integrated with leading API tools like Apidog.
Happy coding!
💡Ready to take your API development to the next level? Download Apidog for free today and discover how it can improve your workflow!


