
Running large language models (LLMs) locally used to be the domain of hardcore CLI users and system tinkerers. But that’s changing fast. Ollama, known for its simple command-line interface for running open-source LLMs on local machines, just released native desktop apps for macOS and Windows.
And they’re not just basic wrappers. These apps bring powerful features that make chatting with models, analyzing documents, writing documentation, and even working with images drastically easier for developers.
In this article, we’ll explore how the new desktop experience improves the developer workflow, what features stand out, and where these tools actually shine in daily coding life.
Why Local LLMs Still Matter
While cloud-based tools like ChatGPT, Claude, and Gemini dominate headlines, there’s a growing movement toward local-first AI development. Developers want tools that are:
- Private - Your code and documents stay on your machine.
- Customizable - You choose the models, memory limits, and hardware.
- Offline-friendly - No dependency on external APIs or uptime.
- Fast - No network latency or server bottlenecks.
Ollama taps directly into this trend, letting you run models like LLaMA, Mistral, Gemma, Codellama, Mixtral, and others natively on your machine - now with a much smoother experience.
Step 1: Download Ollama for Desktop
Go to ollama.com and download the latest version for your system:
- macOS (Apple Silicon or Intel)
- Windows 10/11 (x64)
Install it like a regular desktop app. No command-line setup is required to get started.
Step 2: Launch and Pick a Model
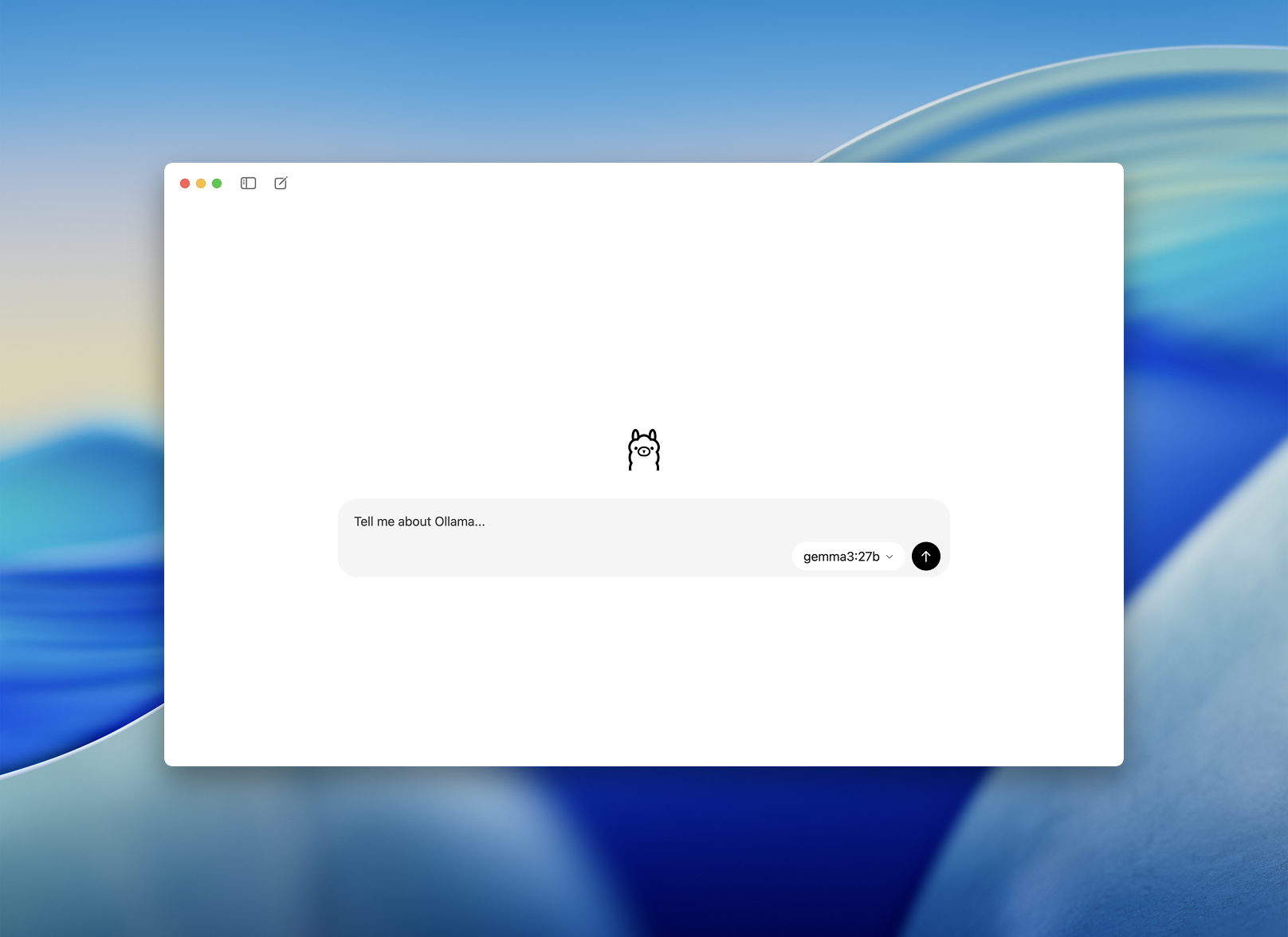
Once installed, open the Ollama desktop app. The interface is clean and looks like a simple chat window.
You’ll be prompted to choose a model to download and run. Some options include:
llama3– general-purpose assistantcodellama– great for code generation and refactoringmistral– fast, small, and accurategemma– Google-backed, open-weight model
Choose one and the app will automatically download and load it.
A Smoother Onboarding for Developers - An Easier Way to Chat with Models
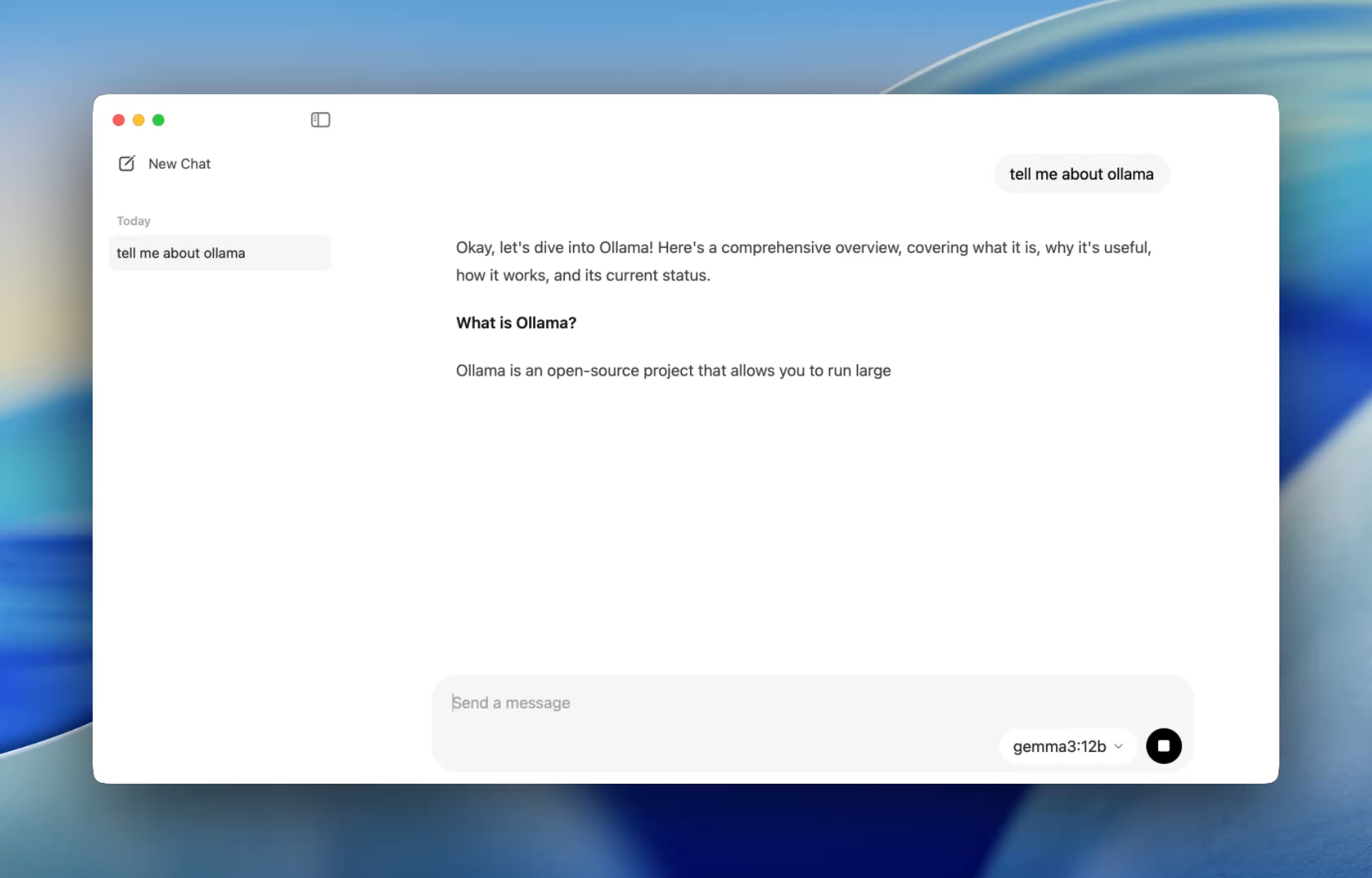
Previously, using Ollama meant firing up a terminal and issuing ollama run commands to start a model session. Now, the desktop app opens like any native application, offering a simple and clean chat interface.
You can now talk to models the same way you would in ChatGPT — but entirely offline. This is perfect for:
- Code review assistance
- Test generation
- Refactoring tips
- Learning new APIs or languages
The app gives you immediate access to local models like codellama or mistral with no setup beyond a simple installation.
And for developers who love customization, the CLI still works behind the scenes letting you toggle context length, system prompts, and model versions via terminal if needed.
Drag. Drop. Ask Questions.
Chat with Files
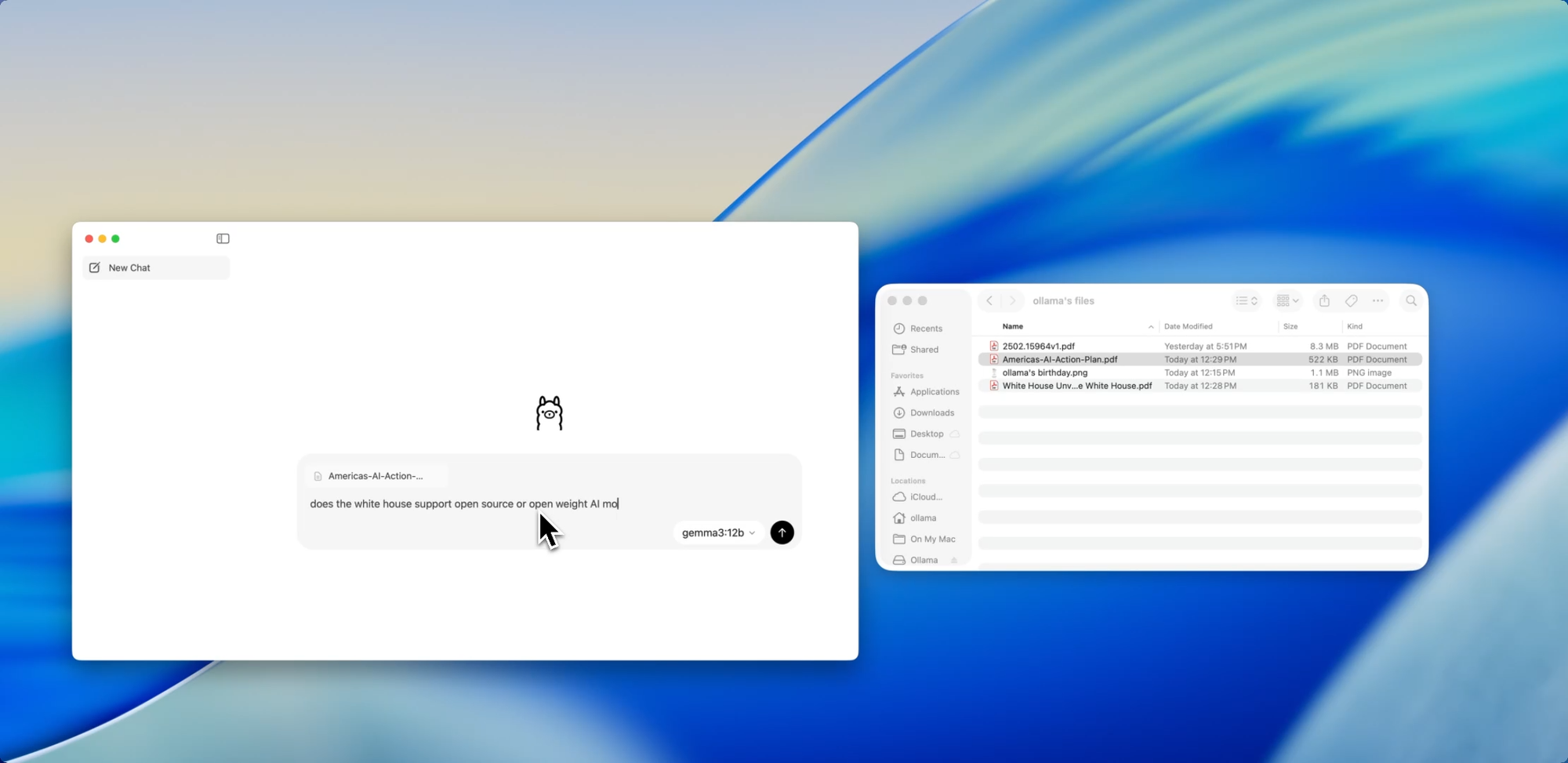
One of the most developer-friendly features in the new app is file ingestion. Just drag a file into the chat window whether it’s a .pdf, .md, or .txt and the model will read its contents.
Need to understand a 60-page design doc? Want to extract TODOs from a messy README? Or summarize a client’s product brief? Drop it in and ask natural language questions like:
- “What are the main features discussed in this doc?”
- “Summarize this in one paragraph.”
- “Are there any missing sections or inconsistencies?”
This feature can dramatically cut down time spent scanning documentation, reviewing specs, or onboarding into new projects.
Go Beyond Text
Multimodal Support
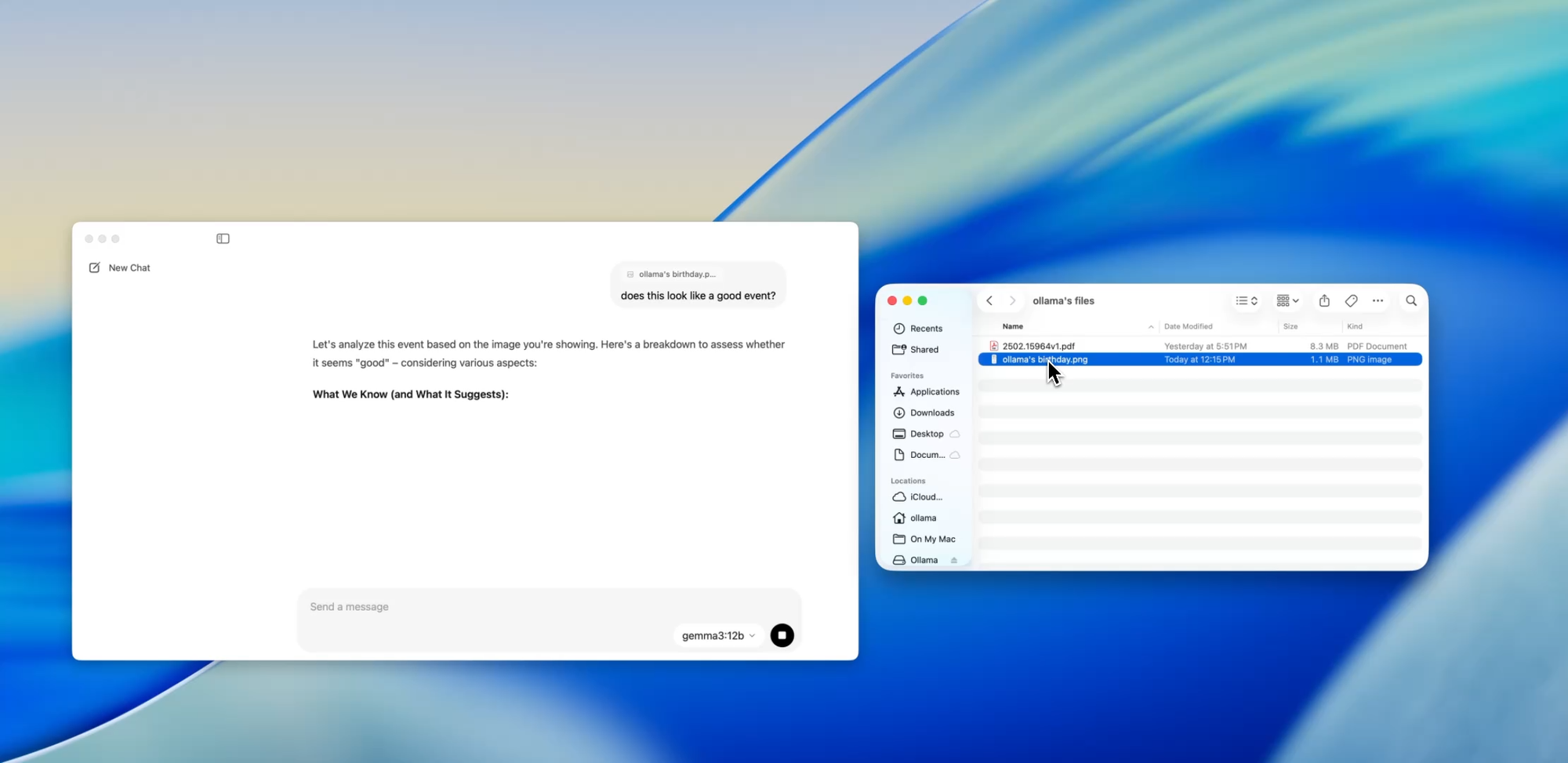
Select models within Ollama (such as Llava-based ones) now support image input. That means you can upload an image, and the model will interpret and respond to it.
Some use cases include:
- Reading diagrams or charts from a screenshot
- Describing UI mockups
- Reviewing scanned handwritten notes
- Analyzing simple infographics
While this is still early-stage compared to tools like GPT-4 Vision, having multimodal support baked into a local-first app is a big step for developers building multi-input systems or testing AI interfaces.
Private, Local Docs — at Your Command
Documentation Writing
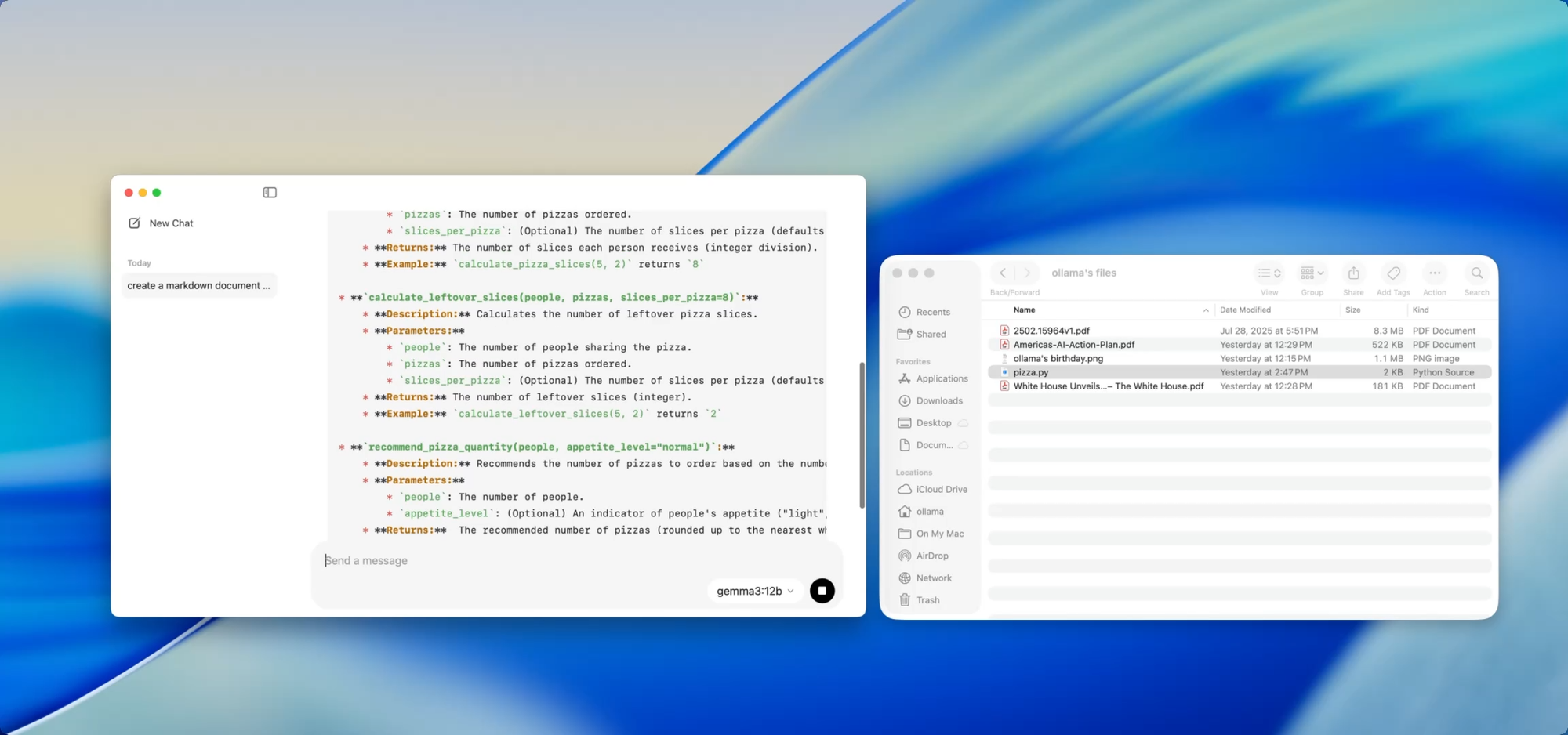
If you're maintaining a growing codebase, you know the pain of documentation drift. With Ollama, you can use local models to help generate or update documentation without ever pushing sensitive code to the cloud.
Just drag a file — say utils.py — into the app and ask:
- “Write docstrings for these functions.”
- “Create a Markdown overview of what this file does.”
- “What dependencies does this module use?”
This becomes even more powerful when paired with tools like [Deepdocs] that automate documentation workflows using AI. You can pre-load your project’s README or schema files, then ask follow-up questions or generate change logs, migration notes, or update guides — all locally.
Performance Tuning Under the Hood
With this new release, Ollama also improved performance across the board:
- GPU acceleration is better optimized for Apple Silicon and modern Nvidia/AMD cards.
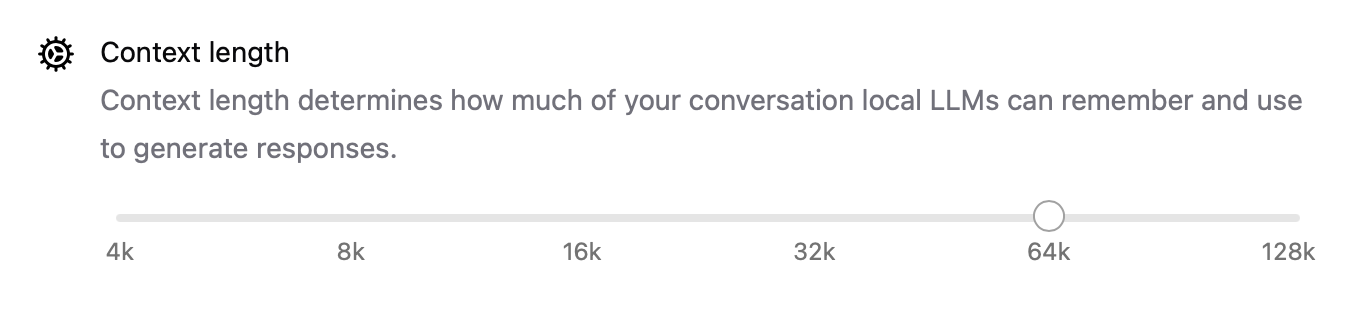
- Context length is now configurable with settings like
num_ctx=8192, so you can handle longer inputs. - Network mode allows Ollama to run as a local API server you can call from other apps or devices on your LAN.
- You can now change the storage location for downloaded models — perfect if you’re working from an external drive or want to isolate models per project.
These upgrades make the app flexible for everything from local agents to dev tools to personal research assistants.
CLI and GUI: Best of Both Worlds
The best part? The new desktop app doesn’t replace the terminal — it complements it.
You can still:
ollama pull codellama
ollama run codellama
Or expose the model server:
ollama serve --host 0.0.0.0
So if you're building a custom AI interface, agent, or plugin that relies on a local LLM, you can now build on top of Ollama’s API and use the GUI for direct interaction or testing.
Test Ollama’s API Locally with Apidog
Want to integrate Ollama into your AI app or test its local API endpoints? You can spin up Ollama's REST API using:
bash tollama serve
Then, use Apidog to test, debug, and document your local LLM endpoints.

Why use Apidog with Ollama:
- Visual interface to send POST requests to your local
http://localhost:11434server - Supports AI-assisted request generation and response validation
- Perfect for self-hosted AI apps, agent frameworks, or internal tools
- Works seamlessly with local LLM workflows and custom model servers
Developer Use Cases That Actually Work
Here’s where the new Ollama app shines in real developer workflows:
| Use Case | How Ollama Helps |
|---|---|
| Code Review Assistant | Run codellama locally for refactor feedback |
| Documentation Updates | Ask models to rewrite, summarize, or fix doc files |
| Local Dev Chatbot | Embed into your app as a context-aware assistant |
| Offline Research Tool | Load PDFs or whitepapers and ask key questions |
| Personal LLM Playground | Experiment with prompt engineering & fine-tuning |
For teams worried about data privacy or model hallucinations, local-first LLM workflows offer an increasingly compelling alternative.
Final Thoughts
The desktop version of Ollama makes local LLMs feel less like a hacky science experiment and more like a polished developer tool.
With support for file interaction, multimodal inputs, document writing, and native performance, it’s a serious option for developers who care about speed, flexibility, and control.
No cloud API keys. No background tracking. No per-token billing. Just fast, local inference with the choice of whatever open model suits your needs.
If you’ve been curious about running LLMs on your machine, or if you're already using Ollama and want a smoother experience, now’s the time to try it again.


