
Artificial intelligence continues to push the boundaries of what’s possible in large-scale reasoning and long-context understanding. For backend engineers, API developers, and technical leaders seeking to leverage advanced AI in real-world applications, MiniMax-M1 introduces a new era of open-weight, high-capacity models. As the first open-source hybrid-attention reasoning model with an unprecedented 1 million-token input window, MiniMax-M1 empowers teams to tackle complex logic, deep analysis, and robust automation.
Looking to experiment with next-generation AI models? Download Apidog for free to seamlessly integrate and test MiniMax-M1’s capabilities within your API workflows.
What Sets MiniMax-M1 Apart? Key Architecture Insights
MiniMax-M1 is engineered using a hybrid Mixture-of-Experts (MoE) architecture paired with an ultra-efficient attention mechanism. This architectural choice is crucial for developers working with high-throughput, resource-intensive tasks:
- Scale: Built on a foundation of 456 billion parameters (with 45.9 billion activated per token).
- Efficiency: The MoE activates only relevant experts per input, optimizing compute usage.
- Hybrid Lightning Attention: Designed to process long sequences rapidly and retain context effectively.
By selectively engaging expert subnetworks, MiniMax-M1 reduces hardware requirements typically associated with large-scale models. This efficiency is further amplified by the lightning attention mechanism, which delivers consistent throughput even as input length scales.
Efficient Training via Reinforcement Learning: The CISPO Edge
A standout feature of MiniMax-M1 is its cost-effective training, achieved through a novel RL algorithm called CISPO (Clipped Importance Sampling with Policy Optimization):
- Low Training Cost: Achieved state-of-the-art performance at just $534,700, setting a new benchmark for large models.
- Stability: CISPO clips importance sampling weights, not token updates, resulting in smoother and more reliable learning than traditional RL methods.

The model’s hybrid-attention architecture is optimized for RL, overcoming scaling challenges that often hinder open-weight models. This approach allows developers to build and fine-tune high-performing AI even with modest infrastructure.
Benchmarking MiniMax-M1: Real-World Performance
MiniMax-M1 has been rigorously tested against commercial and open-weight models across tasks relevant to engineering and API development:
- Mathematics (AIME): 86.0% accuracy, outperforming Claude 4 Opus and closing the gap with OpenAI o3.
- Code Generation (LiveCodeBench): 65.0%, matching top-tier open models.
- Software Engineering (SW-E Bench): 62.8%, exceeding Qwen3-235B-A22B.
- Tool Use (TAU-bench): 73.4%, surpassing Gemini 2.5 Pro.
- Long-Context Tasks (MRCR): 74.4%, leading in deep-context understanding.
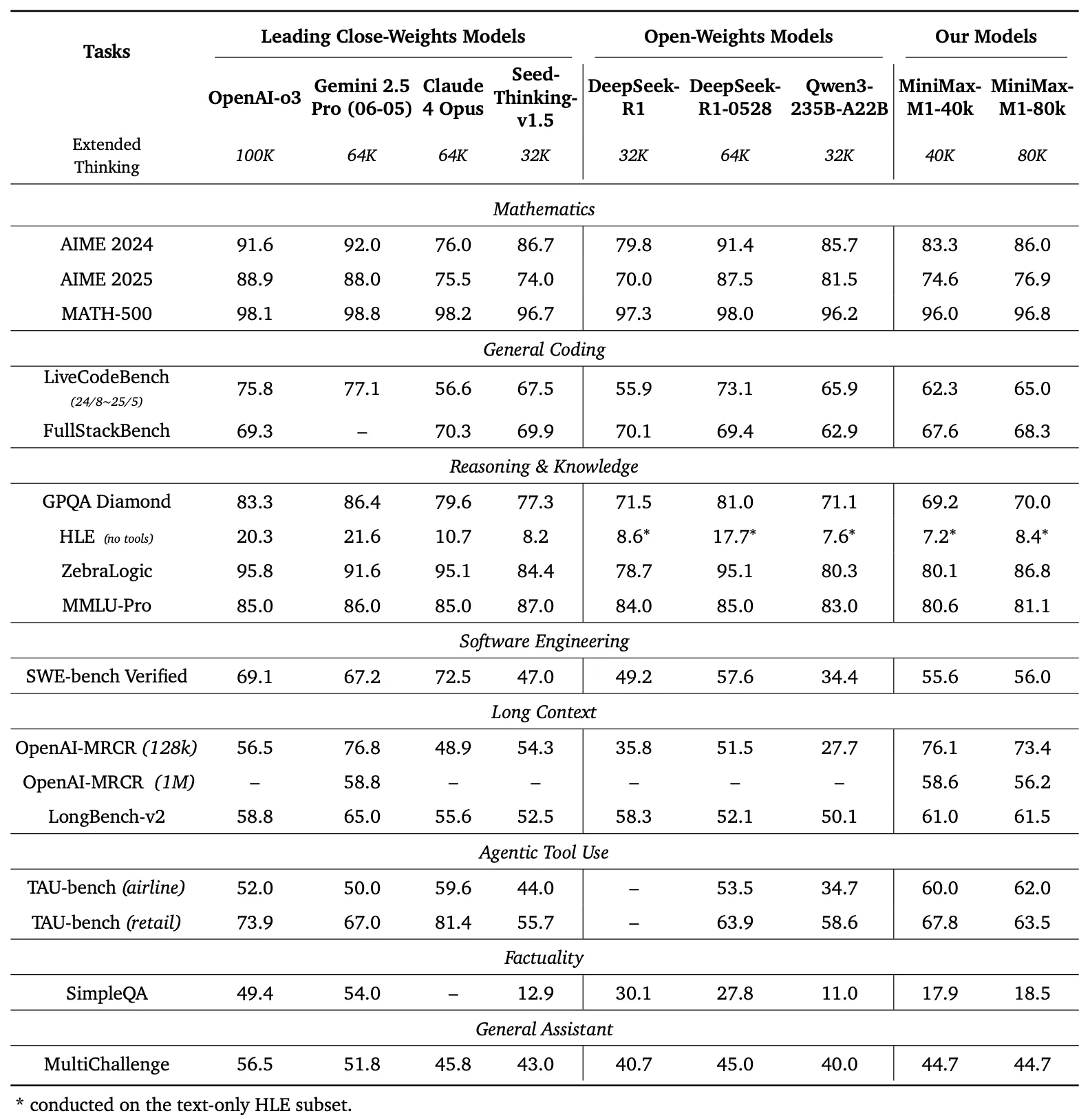
Comparison Highlights

- AIME 2024: MiniMax-M1: 86.0%, OpenAI o3: 88.0%, Claude 4 Opus: 80.0%
- LiveCodeBench: MiniMax-M1: 65.0%, DeepSeek-R1-0528: 56.0%, Seed-Thinking v1.5: 65.0%
- SW-E Bench: MiniMax-M1: 62.8%, Qwen3-235B-A22B: 60.0%
- TAU-bench: MiniMax-M1: 73.4%, Gemini 2.5 Pro: 70.0%
- MRCR (4-needle): MiniMax-M1: 74.4%

MiniMax-M1’s FLOPs scale linearly with output length, ensuring efficiency for engineering use cases that require extended responses or analysis.
Million-Token Context: Unlocking Long-Sequence Reasoning
MiniMax-M1’s defining capability is its million-token input and 80,000-token output window—far exceeding even GPT-4’s maximum. For API-focused teams, this means:
- Comprehensive Document Summarization: Analyze entire codebases, legal documents, or multi-part records in a single pass.
- Multi-Turn Dialogue: Maintain consistency and memory across lengthy conversations or support sessions.
- Complex Data Analysis: Process and correlate extensive datasets with retained context.

Two inference modes (40k and 80k “thought budgets”) allow developers to balance speed and context depth to suit specific scenarios.
Agentic Tool Use: Practical Automation and Application Generation
MiniMax-M1 shines in agentic tool use, enabling programmatic interaction with external systems and automated code generation. Example applications include:
- Web App Generation: Instantly produce a typing speed test or a maze generator with A* visualization, ready for deployment.
- API Integration: Orchestrate API calls, automate test case creation, or build backend utilities with minimal manual coding.
- No Plugin Dependency: All functionality is accessible out-of-the-box, streamlining rapid prototyping for API and QA teams.

By integrating MiniMax-M1 into your workflow using tools like Apidog, you can accelerate API testing, documentation, and automation initiatives.
Open-Source Accessibility: Democratizing Advanced AI
Released under the Apache 2.0 license, MiniMax-M1 is accessible on both GitHub and Hugging Face, empowering engineering teams to:
- Modify and Extend: Tailor the model for domain-specific use cases, from NLP to code intelligence.
- Deploy at Scale: Avoid vendor lock-in and build on a transparent, community-driven foundation.
- Collaborate: Leverage detailed documentation and reproducibility notes for peer-reviewed development.
Open-source availability ensures smaller organizations and independent engineers can experiment with state-of-the-art reasoning without prohibitive costs.
Deployment Recommendations: Optimizing MiniMax-M1 for Production
To maximize performance and efficiency in production:
- Use vLLM: The tech report recommends vLLM (Virtual Large Language Model) for scalable, memory-efficient inference.
- Adjust Thought Budget: Select 40k or 80k budgets for optimal balance between latency and context retention.
- Custom Fine-Tuning: Leverage the RL-friendly architecture to adapt MiniMax-M1 for tasks like real-time translation, customer support, or code review.

Tip: Apidog provides a streamlined interface to connect, test, and monitor AI model endpoints, making it easier to deploy MiniMax-M1 in your existing API pipelines.
Conclusion: MiniMax-M1 and the Future of Open-Source AI for Developers
MiniMax-M1 sets a new standard for open-weight, large-scale hybrid-attention models—delivering unmatched context length, efficient training, and strong benchmark results. Its open-source nature levels the playing field, allowing engineers and API teams to innovate rapidly without proprietary restrictions.
Ready to explore the potential of million-token AI models in your stack? Download Apidog and start integrating MiniMax-M1 with your API-driven workflows today.


