
In the rapidly evolving landscape of large language models, NVIDIA's Llama Nemotron Ultra 253B stands out as a powerhouse for enterprises seeking advanced reasoning capabilities. This comprehensive guide examines the model's impressive benchmarks, compares it to other leading open-source models, and provides clear steps for implementing its API in your applications.
llama-3.1-nemotron-ultra-253b Benchmark
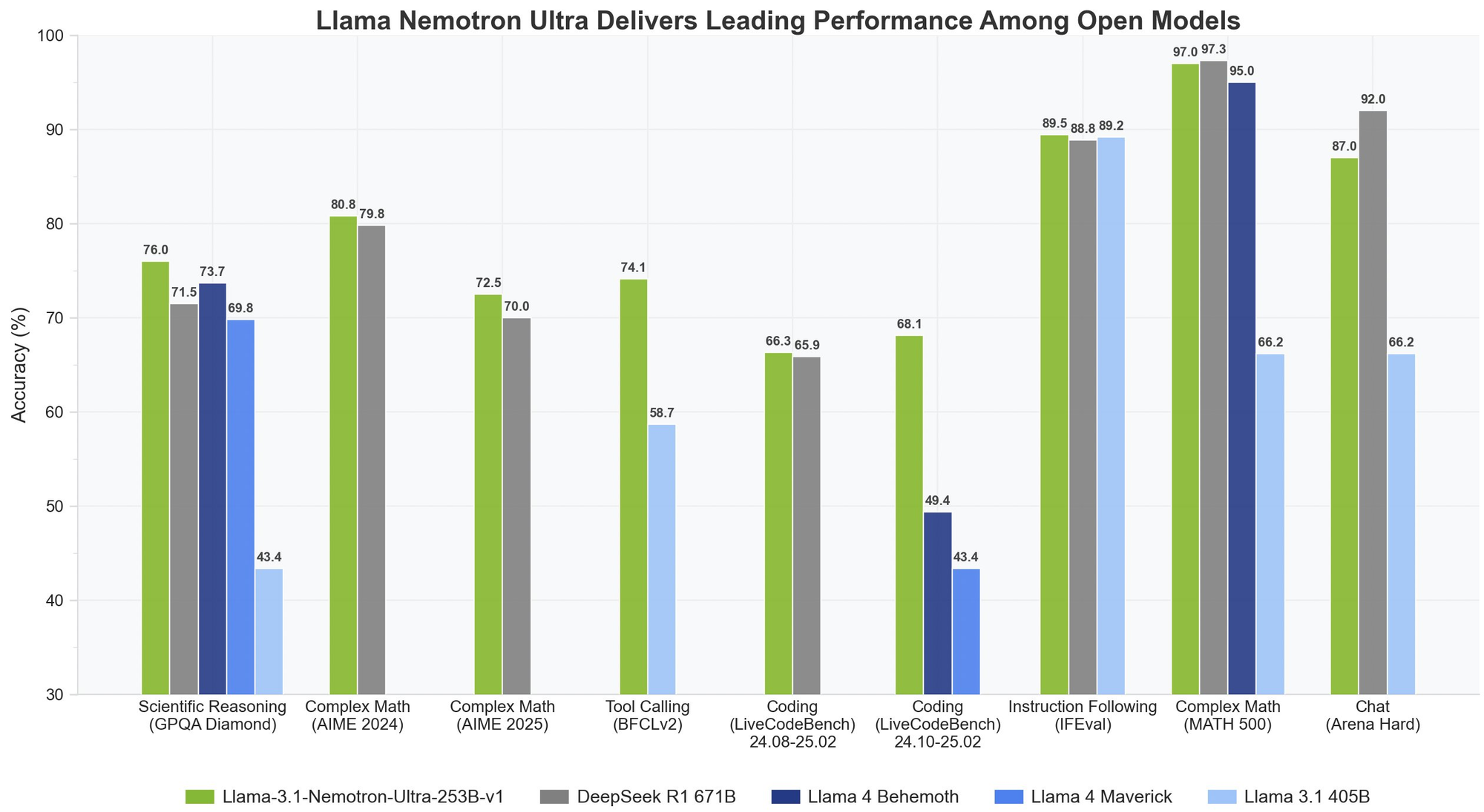
The Llama Nemotron Ultra 253B delivers exceptional results across critical reasoning and agentic benchmarks, with its unique "Reasoning ON/OFF" capability showing dramatic performance differences:
Mathematical Reasoning
The Llama Nemotron Ultra 253B truly shines in mathematical reasoning tasks:
- MATH500
- Reasoning OFF: 80.4% pass@1
- Reasoning ON: 97.0% pass@1
At 97% accuracy with Reasoning ON, the Llama Nemotron Ultra 253B nearly perfects this challenging mathematical benchmark.
- AIME25 (American Invitational Mathematics Examination)
- Reasoning OFF: 16.7% pass@1
- Reasoning ON: 72.50% pass@1
This remarkable 56-point improvement demonstrates how the Llama Nemotron Ultra 253B's reasoning capabilities transform its performance on complex mathematics problems.
Scientific Reasoning
- GPQA (Graduate-level Physics Questions and Answers)
- Reasoning OFF: 56.6% pass@1
- Reasoning ON: 76.01% pass@1
The significant improvement showcases how the Llama Nemotron Ultra 253B can tackle graduate-level physics problems through methodical analysis when reasoning is activated.
Programming and Tool Use
- LiveCodeBench (20240801-20250201)
- Reasoning OFF: 29.03% pass@1
- Reasoning ON: 66.31% pass@1
The Llama Nemotron Ultra 253B more than doubles its coding performance with reasoning activated.
- BFCL V2 Live (Function Calling)
- Reasoning OFF: 73.62 score
- Reasoning ON: 74.10 score
This benchmark demonstrates the model's strong tool-using capabilities in both modes, critical for building effective AI agents.
Instruction Following
- IFEval (Instruction Following Evaluation)
- Reasoning OFF: 88.85% strict accuracy
- Reasoning ON: 89.45% strict accuracy
Both modes perform excellently, showing that the Llama Nemotron Ultra 253B maintains strong instruction-following abilities regardless of reasoning mode.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1 has been the gold standard for open-source reasoning models, but Llama Nemotron Ultra 253B matches or exceeds its performance on key reasoning benchmarks:
- On GPQA, Llama Nemotron Ultra 253B achieves 76.01% accuracy, competing with DeepSeek-R1's top-tier performance
- The Llama Nemotron Ultra 253B offers dual reasoning modes, unlike DeepSeek-R1's fixed reasoning approach
- Llama Nemotron Ultra 253B provides superior function calling capabilities, making it more versatile for agentic applications
Llama Nemotron Ultra 253B vs. Llama 4
When compared to the upcoming Llama 4 Behemoth and Maverick models:
- Llama Nemotron Ultra 253B demonstrates superior performance on scientific and complex mathematical reasoning benchmarks
- The explicit reasoning switch in Llama Nemotron Ultra 253B offers more flexibility than standard Llama 4 models
- Llama Nemotron Ultra 253B is specifically optimized for NVIDIA hardware, providing better inference efficiency
Let's Test Llama Nemotron Ultra 253B via API
Implementing the Llama Nemotron Ultra 253B in your applications requires following specific steps to ensure optimal performance:
Step 1: Obtain API Access
To access the Llama Nemotron Ultra 253B:
- Visit the NVIDIA API portal at https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Register for an API key if you don't already have one
- If running within NVIDIA's NGC environment, the API key configuration may be simplified
Step 2: Set Up Your Development Environment
Before making API calls:
- Install the OpenAI Python package using
pip install openai - Import the necessary library:
from openai import OpenAI - Configure your environment to securely store the API key
Step 3: Configure the API Client
Initialize the OpenAI client with NVIDIA's endpoints:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- Unlike Postman, Apidog offers a more integrated experience with built-in API documentation, automated testing, and mock servers specifically optimized for AI model endpoints.
- Apidog's intuitive interface makes it easier to configure the complex parameter sets needed for API testing, and its response visualization features are particularly helpful for analyzing the model's streaming outputs.
- While Postman remains a popular general-purpose API testing tool, Apidog's AI-focused features and streamlined workflow can significantly accelerate your development process.

Step 4: Determine the Appropriate Reasoning Mode
The Llama Nemotron Ultra 253B offers two distinct operation modes:
- Reasoning ON: Best for complex problems requiring step-by-step thinking (math, physics, coding)
- Reasoning OFF: Optimal for straightforward instruction following and general chat
Step 5: Craft Your System and User Prompts
For Reasoning ON mode:
- Set the system prompt to
"detailed thinking on" - Place all instructions in the user message
- Consider using specific templates for benchmarked tasks (like math problems)
For Reasoning OFF mode:
- Remove the reasoning system prompt
- Use concise, clear instructions in the user message
Step 6: Configure Generation Parameters
For optimal results:
- Reasoning ON: Set temperature=0.6 and top_p=0.95 as recommended by NVIDIA
- Reasoning OFF: Use greedy decoding with temperature=0
- Set appropriate
max_tokensbased on expected response length - Consider enabling streaming for real-time responses
Step 7: Make the API Request and Handle Responses
Create your completion request with all parameters configured:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Step 8: Process and Display the Response
If using streaming:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
For non-streaming responses, simply access completion.choices[0].message.content.
Conclusion
The Llama Nemotron Ultra 253B represents a significant advancement in open-source reasoning models, delivering state-of-the-art performance across a wide range of benchmarks. Its unique dual reasoning modes, combined with exceptional function calling capabilities and a massive context window, make it an ideal choice for enterprise AI applications requiring advanced reasoning capabilities.
With the step-by-step API implementation guide outlined in this article, developers can harness the full potential of Llama Nemotron Ultra 253B to build sophisticated AI systems that tackle complex problems with human-like reasoning. Whether building AI agents, enhancing RAG systems, or developing specialized applications, the Llama Nemotron Ultra 253B provides a powerful foundation for next-generation AI capabilities in a commercially friendly, open-source package.


