
The artificial intelligence landscape has been fundamentally transformed with Meta's release of Llama 4—not merely through incremental improvements, but via architectural breakthroughs that redefine performance-to-cost ratios across the industry. These new models represent the convergence of three critical innovations: native multimodality through early fusion techniques, sparse mixture-of-experts (MoE) architectures that radically improve parameter efficiency, and context window expansions that extend to an unprecedented 10 million tokens.
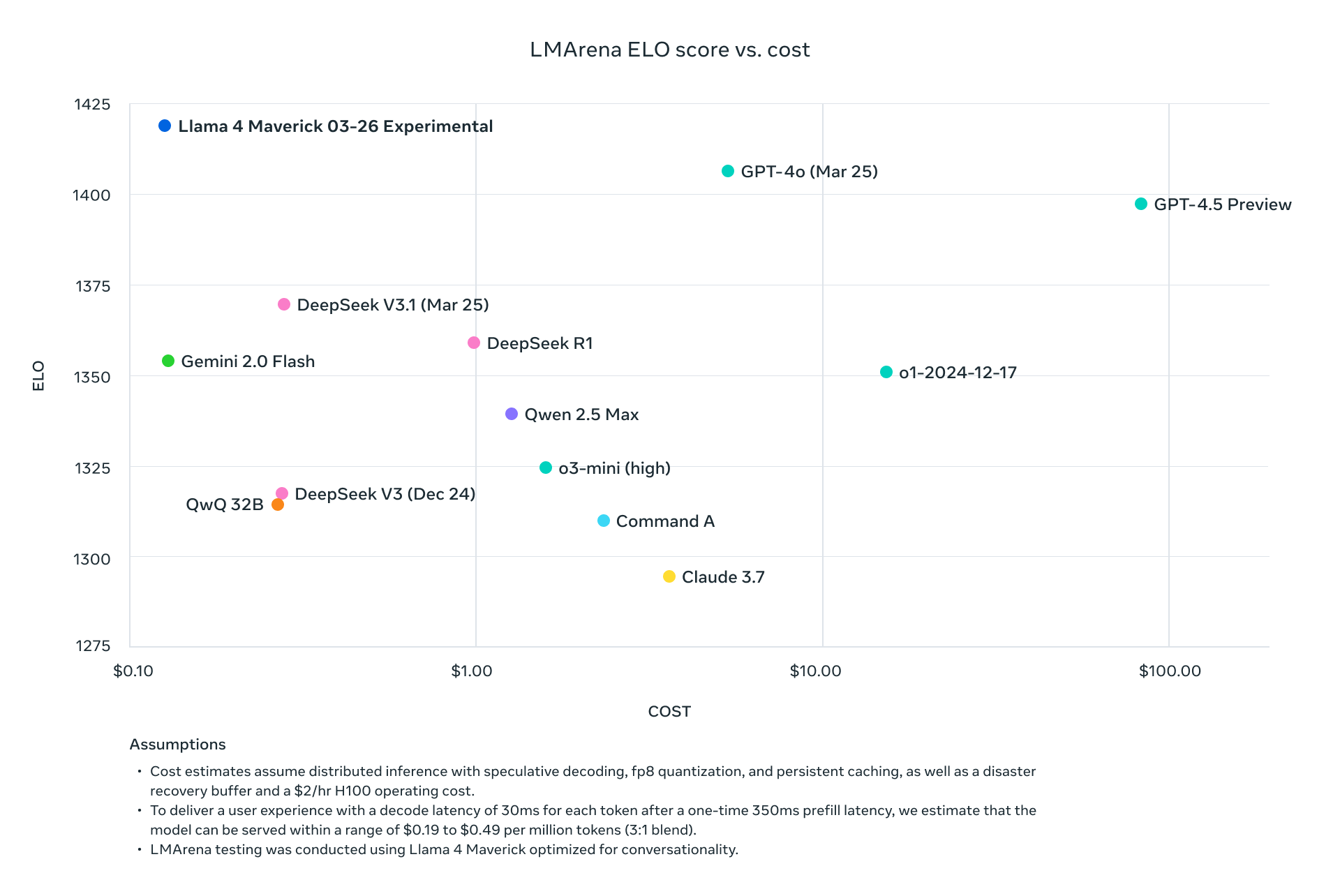
Llama 4 Scout and Maverick don't just compete with current industry leaders—they systematically outperform them across standard benchmarks while dramatically reducing computational requirements. With Maverick achieving better results than GPT-4o at approximately one-ninth the cost per token, and Scout fitting on a single H100 GPU while maintaining superior performance to models requiring multiple GPUs, Meta has fundamentally altered the economics of advanced AI deployment.
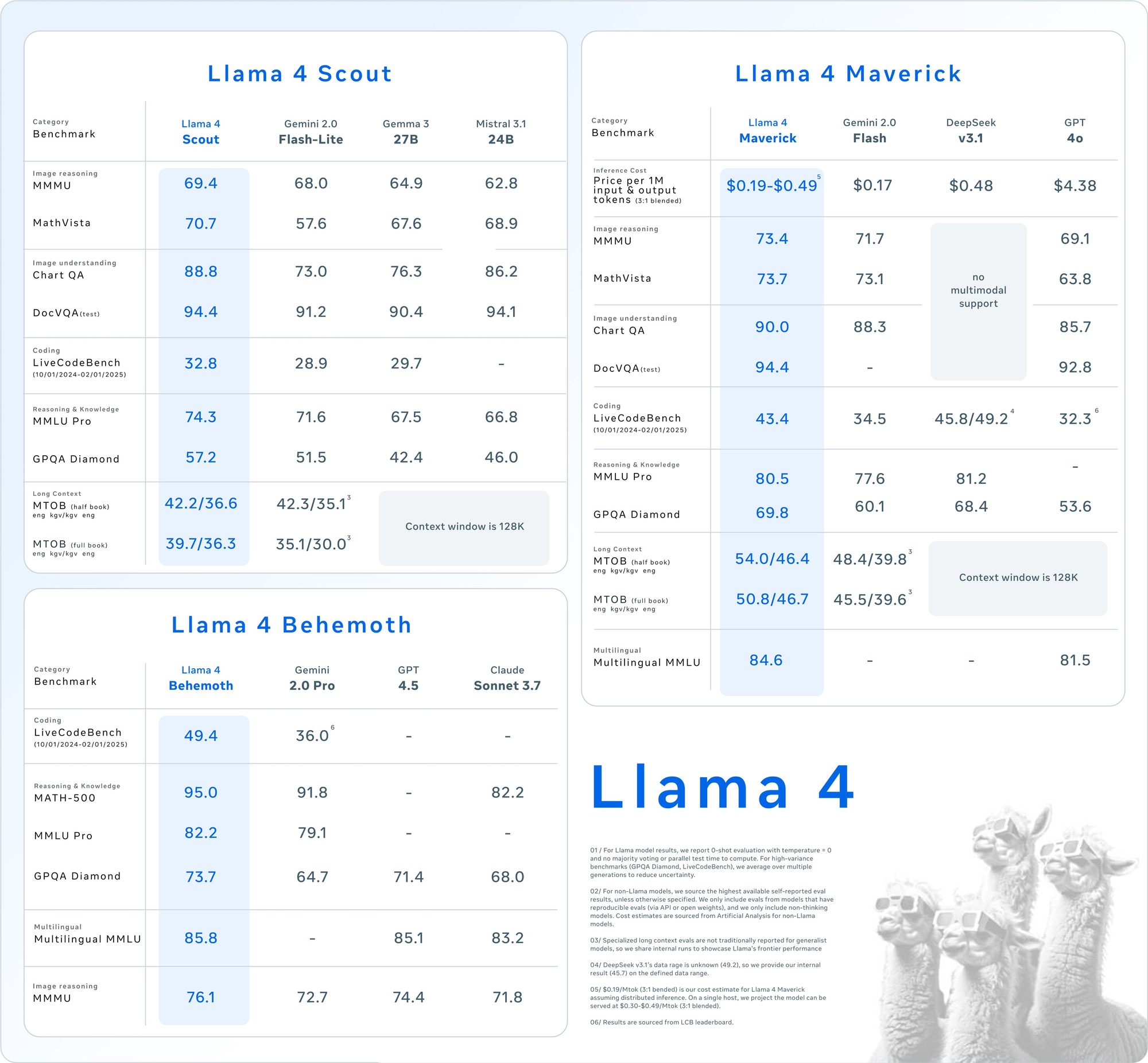
This technical analysis dissects the architectural innovations powering these models, presents comprehensive benchmark data across reasoning, coding, multilingual, and multimodal tasks, and examines the API pricing structures across major providers. For technical decision-makers evaluating AI infrastructure options, we provide detailed performance/cost comparisons and deployment strategies to maximize the efficiency of these groundbreaking models in production environments.
You can download Meta Llama 4 Open Source and Open Weight on Hugging Face, as of today:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

How Llama 4 Archived 10M Context Window?
Mixture-of-Experts (MoE) Implementation
All Llama 4 models employ a sophisticated MoE architecture that fundamentally changes the efficiency equation:
| Model | Active Parameters | Expert Count | Total Parameters | Parameter Activation Method |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | Token-specific routing |
| Llama 4 Maverick | 17B | 128 | 400B | Shared + single routed expert per token |
| Llama 4 Behemoth | 288B | 16 | ~2T | Token-specific routing |
The MoE design in Llama 4 Maverick is particularly sophisticated, using alternating dense and MoE layers. Each token activates the shared expert plus one of 128 routed experts, meaning only approximately 17B out of 400B total parameters are active for processing any given token.
Multimodal Architecture
Llama 4 Multimodal Architecture:
├── Text Tokens
│ └── Native text processing pathway
├── Vision Encoder (Enhanced MetaCLIP)
│ ├── Image processing
│ └── Converts images to token sequences
└── Early Fusion Layer
└── Unifies text and vision tokens in model backbone
This early fusion approach allows pre-training on 30+ trillion tokens of mixed text, image, and video data, resulting in significantly more coherent multimodal capabilities than retrofit approaches.
iRoPE Architecture for Extended Context Windows
Llama 4 Scout's 10M token context window leverages the innovative iRoPE architecture:
# Pseudocode for iRoPE architecture
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Even layers: Interleaved attention without positional embeddings
return attention_no_positional(tokens)
else:
# Odd layers: RoPE (Rotary Position Embeddings)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# Temperature scaling during inference improves length generalization
return scale_attention_scores(tokens, temperature_factor)
This architecture enables Scout to process documents of unprecedented length while maintaining coherence throughout, with a scaling factor approximately 80x greater than previous Llama models' context windows.
Comprehensive Benchmark Analysis
Standard Benchmark Performance Metrics
Detailed benchmark results across major evaluation suites reveal the competitive positioning of Llama 4 models:
| Category | Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Image Reasoning | MMMU | 73.4 | 69.1 | 71.7 | No multimodal support |
| MathVista | 73.7 | 63.8 | 73.1 | No multimodal support | |
| Image Understanding | ChartQA | 90.0 | 85.7 | 88.3 | No multimodal support |
| DocVQA (test) | 94.4 | 92.8 | - | No multimodal support | |
| Coding | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| Reasoning & Knowledge | MMLU Pro | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamond | 69.8 | 53.6 | 60.1 | 68.4 | |
| Multilingual | Multilingual MMLU | 84.6 | 81.5 | - | - |
| Long Context | MTOB (half book) eng→kgv/kgv→eng | 54.0/46.4 | Context limited to 128K | 48.4/39.8 | Context limited to 128K |
| MTOB (full book) eng→kgv/kgv→eng | 50.8/46.7 | Context limited to 128K | 45.5/39.6 | Context limited to 128K |
Technical Analysis of Performance by Category
Multimodal Processing Capabilities
Llama 4 demonstrates superior performance on multimodal tasks, with Maverick scoring 73.4% on MMMU compared to GPT-4o's 69.1% and Gemini 2.0 Flash's 71.7%. The performance gap widens further on MathVista, where Maverick scores 73.7% versus GPT-4o's 63.8%.
This advantage stems from the native multimodal architecture that allows for:
- Joint attention mechanisms across text and image tokens
- Early-fusion integration of modalities during pre-training
- Enhanced MetaCLIP vision encoder specifically tuned for LLM integration
Code Generation Analysis
LiveCodeBench Performance Breakdown (10/01/2024-02/01/2025):
├── Llama 4 Maverick: 43.4%
├── Llama 4 Scout: 38.1%
├── GPT-4o: 32.3%
├── Gemini 2.0 Flash: 34.5%
└── DeepSeek v3.1: 45.8%/49.2%
DeepSeek v3.1 marginally outperforms Llama 4 Maverick on code generation, but Maverick achieves this performance with only 17B active parameters compared to DeepSeek's significantly larger parameter count, demonstrating the efficiency of the MoE architecture.
Long Context Performance
The 10M token context window in Llama 4 Scout enables unprecedented performance on long-context tasks. In the MTOB benchmark (Machine Translation of Books), Scout and Maverick maintain coherence and accuracy across full books, while competitors with 128K context windows cannot process the complete texts.
Technical performance on MTOB benchmark for full book translation:
- Llama 4 Maverick: 50.8%/46.7% (eng→kgv/kgv→eng)
- Gemini 2.0 Flash: 45.5%/39.6% (eng→kgv/kgv→eng)
- GPT-4o: Unable to process full book due to context limitations
- DeepSeek v3.1: Unable to process full book due to context limitations
Llama 4 API Pricing
This API tool lets you test and debug your model’s endpoints effortlessly. Download Apidog for free today and streamline your workflow as you explore Mistral Small 3.1’s capabilities!

Official and Third-Party API Pricing Comparison
The Llama 4 models are available through multiple API providers with varying pricing structures. Below is a comprehensive pricing comparison across major providers:
Together.ai Official Pricing
| Model | Input (per 1M tokens) | Output (per 1M tokens) | 3:1 Blended Rate |
|---|---|---|---|
| Llama 4 Maverick | $0.27 | $0.85 | 0.19-0.49 |
| Llama 4 Scout | $0.18 | $0.59 | - |
Comparative Model Pricing (per 1M tokens, 3:1 blended)
| Model | API Provider | Cost per 1M tokens | Relative Cost vs. Maverick |
|---|---|---|---|
| Llama 4 Maverick | Meta/Together | 0.19-0.49 | 1x |
| GPT-4o | OpenAI | $4.38 | 9x-23x |
| Gemini 2.0 Flash | $0.17 | 0.9x-0.35x | |
| DeepSeek v3.1 | DeepSeek | $0.48 | 1x-2.5x |
Hardware Requirements and Deployment Costs
| Model | GPU Requirements | Quantization | Deployment Options |
|---|---|---|---|
| Llama 4 Scout | Single H100 GPU | Int4 | Self-hosted, Dedicated endpoints |
| Llama 4 Maverick | Single H100 DGX host | Int8/Int4 | Self-hosted, Dedicated endpoints |
| GPT-4o | Not self-hostable | - | API only |
| DeepSeek v3.1 | Multiple GPUs | - | Self-hosted, API |
Computational Efficiency Metrics
The MoE architecture provides significant computational advantages over dense models:
Inference Throughput (tokens/second/GPU):
├── Llama 4 Maverick (Int8): 45-65 tokens/sec on H100
├── Llama 4 Scout (Int4): 120-150 tokens/sec on H100
├── GPT-4o: Not available for direct comparison
└── DeepSeek v3.1: 25-30 tokens/sec on H100
For dedicated endpoints using Together.ai's infrastructure, the costs break down as follows:
| Hardware | Cost per minute | Cost per hour | Suitable for |
|---|---|---|---|
| 1x RTX-6000 48GB | $0.025 | $1.49 | Llama 4 Scout (quantized) |
| 1x L40 48GB | $0.025 | $1.49 | Llama 4 Scout (quantized) |
| 1x H100 80GB | $0.056 | $3.36 | Llama 4 Maverick (optimized) |
| 1x H200 141GB | $0.083 | $4.99 | Llama 4 Maverick (full precision) |
Pre-training Technical Specifications of Llama 4
Meta employed several technical innovations in the pre-training phase:
- MetaP technique: Automatic hyperparameter optimization for per-layer learning rates and initialization scales
- FP8 precision training: Achieved 390 TFLOPs/GPU on 32K GPUs during Behemoth training
- Data scale: 30+ trillion tokens (>2x Llama 3), including text, image, and video data
- Multilingual corpus: 200 languages, with >100 languages having >1B tokens each
Post-training Pipeline Architecture of Llama 4
Post-training Pipeline:
1. Lightweight SFT
└── Data filtering: Removed >50% of "easy" examples using Llama-based difficulty assessment
2. Online Reinforcement Learning
└── Continuous strategy with adaptive difficulty:
├── Model training
└── Prompt filtering to retain only medium-to-hard difficulty examples
3. Lightweight DPO
└── Targeted optimization for response quality and edge cases
For Behemoth (2T parameters), the pipeline was further optimized:
- 95% SFT data pruning (vs. 50% for smaller models)
- Fully asynchronous online RL training framework
- Flexible GPU allocation across multiple models based on computational requirements
- ~10x improvement in training efficiency over previous generations
Developer Integration and API Usage
API Integration Examples
For developers looking to integrate Llama 4 models via the Together.ai API, here's a technical implementation example:
import requests
import json
API_KEY = "your_api_key_here"
API_URL = "https://api.together.xyz/inference"
def generate_with_llama4(prompt, model="meta-llama/Llama-4-Maverick", max_tokens=1024):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"model": model,
"prompt": prompt,
"max_tokens": max_tokens,
"temperature": 0.7,
"top_p": 0.9,
"repetition_penalty": 1.1
}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
return response.json()
# Example usage
result = generate_with_llama4("Explain the architecture of Llama 4 Maverick")
print(result["output"]["text"])
Multimodal Integration
For multimodal inputs using Llama 4 Maverick:
import requests
import json
import base64
def encode_image(image_path):
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode("utf-8")
def multimodal_query(image_path, prompt, model="meta-llama/Llama-4-Maverick"):
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
base64_image = encode_image(image_path)
payload = {
"model": model,
"prompt": prompt,
"max_tokens": 1024,
"temperature": 0.7,
"images": [{"data": base64_image, "format": "jpeg"}]
}
response = requests.post(API_URL, headers=headers, data=json.dumps(payload))
return response.json()
Conclusion
Meta's Llama 4 models represent a significant technical achievement in the AI landscape, combining state-of-the-art performance with unprecedented efficiency. The MoE architecture enables Llama 4 Maverick to achieve performance comparable to or exceeding much larger models like GPT-4o at a fraction of the computational cost.
The pricing data indicates that Llama 4 Maverick offers approximately 9-23x better price-performance ratio compared to GPT-4o, while maintaining comparable or better performance on most benchmarks. For organizations seeking to deploy advanced AI capabilities at scale, this represents a compelling value proposition.
The native multimodal capabilities, 10M token context window, and flexible deployment options (from self-hosting to managed APIs) position Llama 4 as a versatile platform for a wide range of AI applications.
As API providers continue to optimize their offerings and as more organizations adopt these models, we can expect further improvements in both performance and cost-efficiency. The open-source nature of the Llama ecosystem also ensures ongoing community contributions and innovations, further enhancing the value proposition of these models.
For developers and organizations evaluating AI solutions, Llama 4 represents a technically superior option that balances advanced capabilities with practical deployment considerations and cost constraints.


