
The world of large language models (LLMs) is advancing at breakneck speed, but challenges in efficiency and real-time adaptability persist. On September 10, 2025, Moonshot AI—the innovative force behind the Kimi series—launched checkpoint-engine, an open-source middleware that redefines weight updates in LLM inference engines. Tailored for reinforcement learning (RL), this lightweight tool can refresh a 1-trillion-parameter behemoth like Kimi-K2 across thousands of GPUs in a mere 20 seconds, slashing downtime and boosting scalability.
This piece delves into checkpoint-engine's mechanics, from its architecture to benchmarks, while highlighting its RL implications and broader ecosystem fit. By open-sourcing this gem, Moonshot AI empowers the community to push LLM boundaries further. Let's unpack this innovation layer by layer.
Understanding Checkpoint-Engine: Core Concepts and Architecture
What is Checkpoint-Engine?
At its heart, checkpoint-engine is a middleware that facilitates seamless, in-place weight updates for LLMs during inference. This is pivotal in RL, where models evolve through iterative feedback without full retrains. Traditional methods bog down systems with lengthy reloads; checkpoint-engine counters this with a streamlined, low-overhead approach.
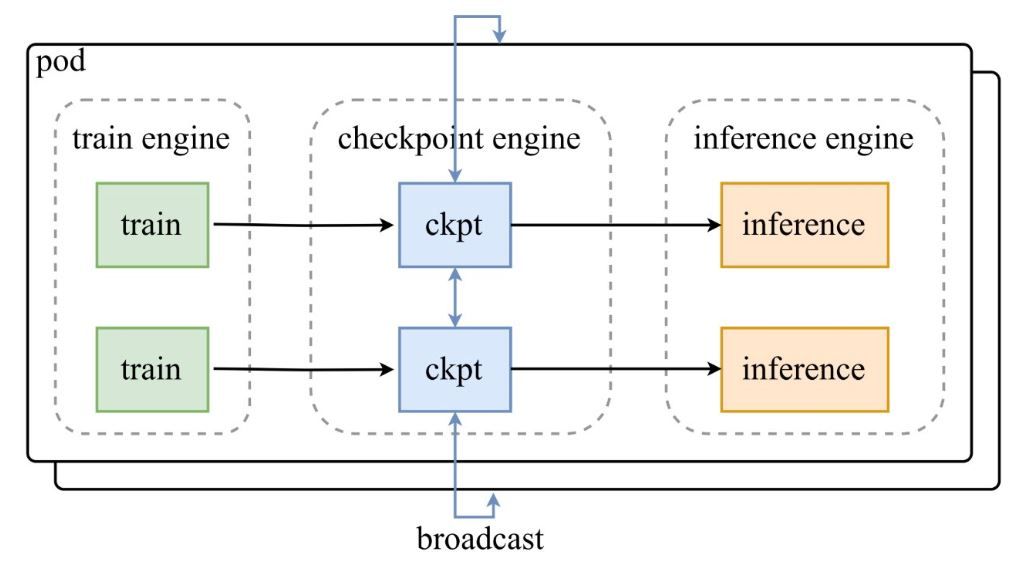
As shown in the architecture diagram from Moonshot AI's announcement tweet, a pod of train engines feeds checkpoints to the central checkpoint-engine, which then broadcasts updates to inference engines. The GitHub repo dives deep into the code, spotlighting the ParameterServer class as the update orchestrator.
Architectural Components
- Train Engine: Produces fresh weights from ongoing RL training, capturing policy refinements in dynamic environments.
- Checkpoint Engine: The middleware core, colocated with inference for minimal latency. It handles metadata gathering and executes updates via Broadcast or P2P modes.
- Inference Engine: Integrates updates on-the-fly, maintaining service continuity across distributed GPU clusters.
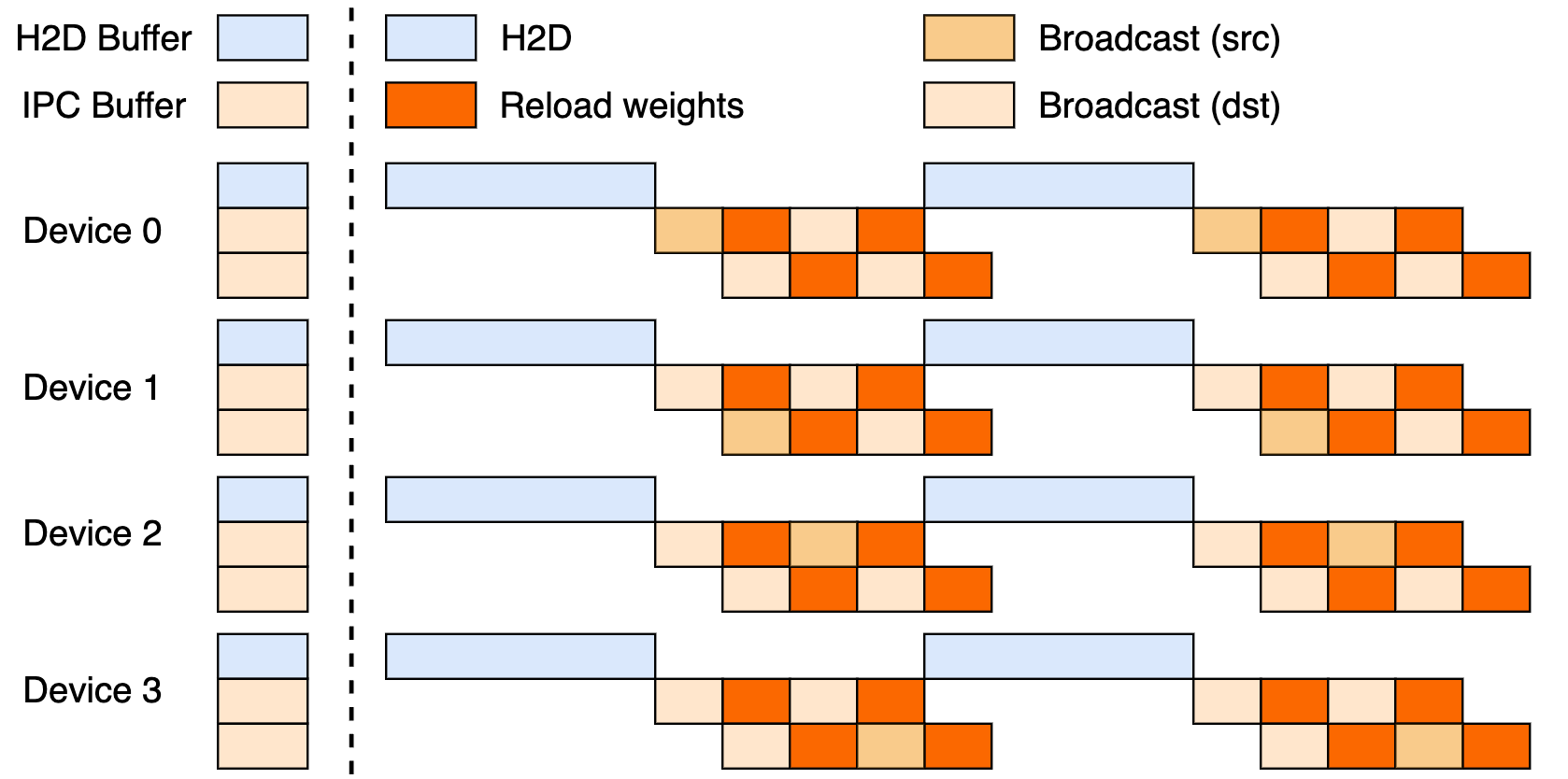
This setup leverages a three-stage pipeline: Host-to-Device (H2D) transfers, inter-worker broadcasts using CUDA IPC, and targeted reloads. By overlapping these, it maximizes GPU utilization and curbs transfer bottlenecks.
Broadcast vs. P2P Updates
Broadcast shines in synchronous, cluster-wide updates—its default mode for peak speed, bucketing data for optimal flow. P2P, meanwhile, excels in elastic scenarios, like scaling out during peaks, by using RDMA via mooncake-transfer-engine to sidestep disruptions. This duality makes checkpoint-engine versatile for both stable and fluid deployments.
Performance Benchmarks: How Fast is Fast Enough?
Updating a Trillion-Parameter Model in 20 Seconds
Checkpoint-engine's headline feat? Updating Kimi-K2's 1T parameters over thousands of GPUs in ~20 seconds. This stems from smart pipelining: metadata planning sets efficient bucket sizes, ZeroMQ sockets coordinate transfers, and overlapped H2D/broadcast stages hide latencies.
Contrast this with legacy techniques, which might idle systems for minutes amid massive data shuffles. Checkpoint-engine's in-place ethos keeps inference humming, ideal for RL's need for swift adaptations.
Benchmark Analysis
The benchmark table reveals stellar results across models and setups, tested with vLLM v0.10.2rc1:
| Model | Device Info | GatherMetas | Update (Broadcast) | Update (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Replicate these via the repo's examples/update.py. FP8 runs need vLLM patches, underscoring efficiency at scale.
Implications for Reinforcement Learning
RL thrives on rapid iterations; checkpoint-engine's sub-20-second cycles enable continuous learning loops, outpacing batch methods. This unlocks responsive apps—from adaptive agents to evolving chatbots—where every second counts in policy tuning.
Technical Implementation: Diving into the Codebase
Open-Source Accessibility
Moonshot AI's GitHub drop democratizes elite RL tools. The ParameterServer anchors updates, offering Broadcast (fast CUDA IPC sharing) and P2P (RDMA for newcomers). Examples like update.py and tests (test_update.py) ease onboarding.
Compatibility starts with vLLM (via worker extensions), with hooks for SGLang eyed next. The partial three-stage pipeline hints at untapped potential.
Optimization Techniques
Key smarts include:
- Pipelined Overlaps: Communication and copies run concurrently, slashing effective time.
- Bucket Optimization: Metadata-driven sizing tunes to sharding and nets.
- ZeroMQ Control: Low-latency signaling to inference engines.
These tackle trillion-param hurdles, from PCIe clashes to memory squeezes (falling back to serial if needed).
Current Limitations
P2P's rank-0 funnel can choke at scale, and the full pipeline awaits polish. vLLM focus limits breadth, but patches bridge FP8 gaps for models like DeepSeek-V3.1. Watch the repo for evolutions.
Integration with Existing Frameworks: vLLM and Beyond
Collaboration with vLLM
Checkpoint-engine pairs natively with vLLM's PagedAttention for buttery RL inference. This duo hits 20-second syncs on 1T models, as teased in vLLM's updates— a nod to open collab amplifying throughput.
Potential Extensions to Claude and Apidog
Extending to Anthropic's Claude could infuse RL dynamism into its safety-focused chats, enabling live fine-tunes. Apidog fits perfectly for endpoint mocking during ZeroMQ tweaks—download Apidog for free to prototype these bridges effortlessly.
Broader Ecosystem Impact
Plugging into Ollama or LM Studio could localize trillion-param power, leveling the field for indie devs. This ripple effect fosters a more inclusive AI landscape.
Future Prospects: What Lies Ahead for Checkpoint-Engine?
Scalability and Performance Enhancements
Full pipeline rollout could shave seconds more, while P2P decentralization nixes bottlenecks for true elasticity. RDMA tweaks promise cloud-native prowess.
Community Contributions
Open-source invites fixes and ports—think SGLang merges or PCIe-agnostic modes. Early replies on the tweet buzz with excitement, fueling momentum.
Industry Applications
From real-time translation to self-driving RL, checkpoint-engine suits flux-heavy domains. Its speed keeps models fresh, edging out rivals in agility.
A New Era for LLM Inference?
Checkpoint-engine heralds agile LLM futures, tackling weight woes with open-source flair. That 20-second 1T refresh, backed by clever architecture and benchmarks, cements its RL throne—limitations notwithstanding.
Pair it with Apidog for dev flows or Claude for hybrid smarts, and innovation soars. Track the GitHub, snag Apidog free, and join the revolution reshaping inference today!


