
Developers seek efficient ways to integrate advanced language models into their applications. INTELLECT-3 emerges as a compelling option due to its open-source foundation and strong performance in reasoning tasks. This model, developed by Prime Intellect, stands out for its 106 billion parameter Mixture-of-Experts (MoE) architecture, which enables high efficiency in handling complex computations.
Understanding INTELLECT-3: The Open-Source Powerhouse
Prime Intellect releases INTELLECT-3 as a fully open-source model, which empowers researchers and developers to customize and extend its capabilities without proprietary barriers. This transparency fosters innovation in areas like reinforcement learning (RL) and agentic AI systems. You access the complete package, including model weights, training frameworks, datasets, RL environments, and evaluation tools, directly from Prime Intellect's repositories.

At its core, INTELLECT-3 employs a 106 billion parameter MoE architecture, built upon the GLM-4.5-Air base model. MoE designs route inputs to specialized "expert" sub-networks, which optimizes compute usage and accelerates inference. For instance, during processing, the model activates only a subset of parameters relevant to the query, reducing latency while maintaining accuracy. This setup proves particularly effective for tasks requiring selective expertise, such as mathematical derivations or code generation.
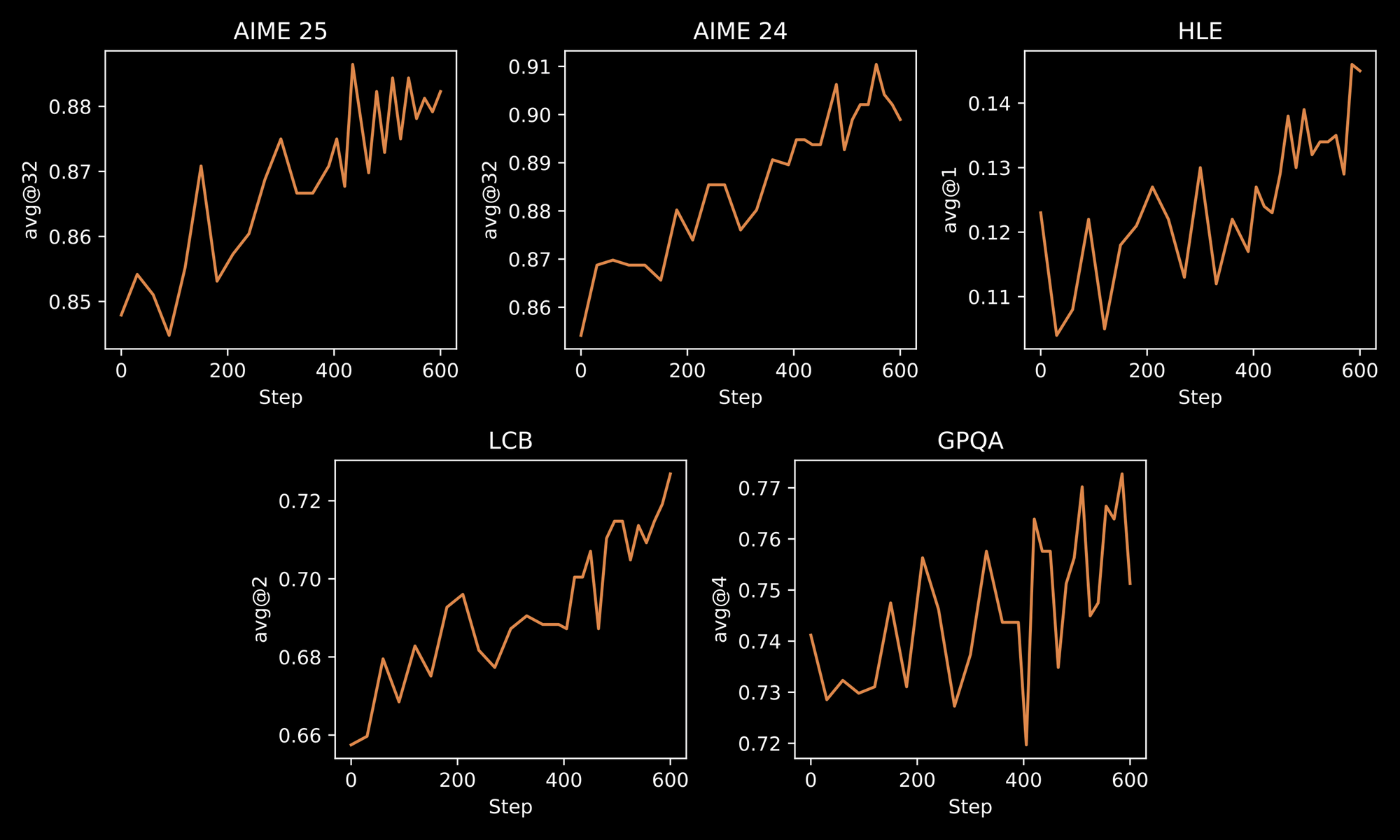
The training process underscores INTELLECT-3's robustness. Engineers apply a two-stage methodology: initial Supervised Fine-Tuning (SFT) on curated datasets, followed by large-scale RL using the custom prime-rl framework. prime-rl operates as an asynchronous off-policy RL system, which handles vast parallel simulations efficiently. You benefit from this through improved model behaviors in dynamic environments, like iterative problem-solving or multi-step planning.
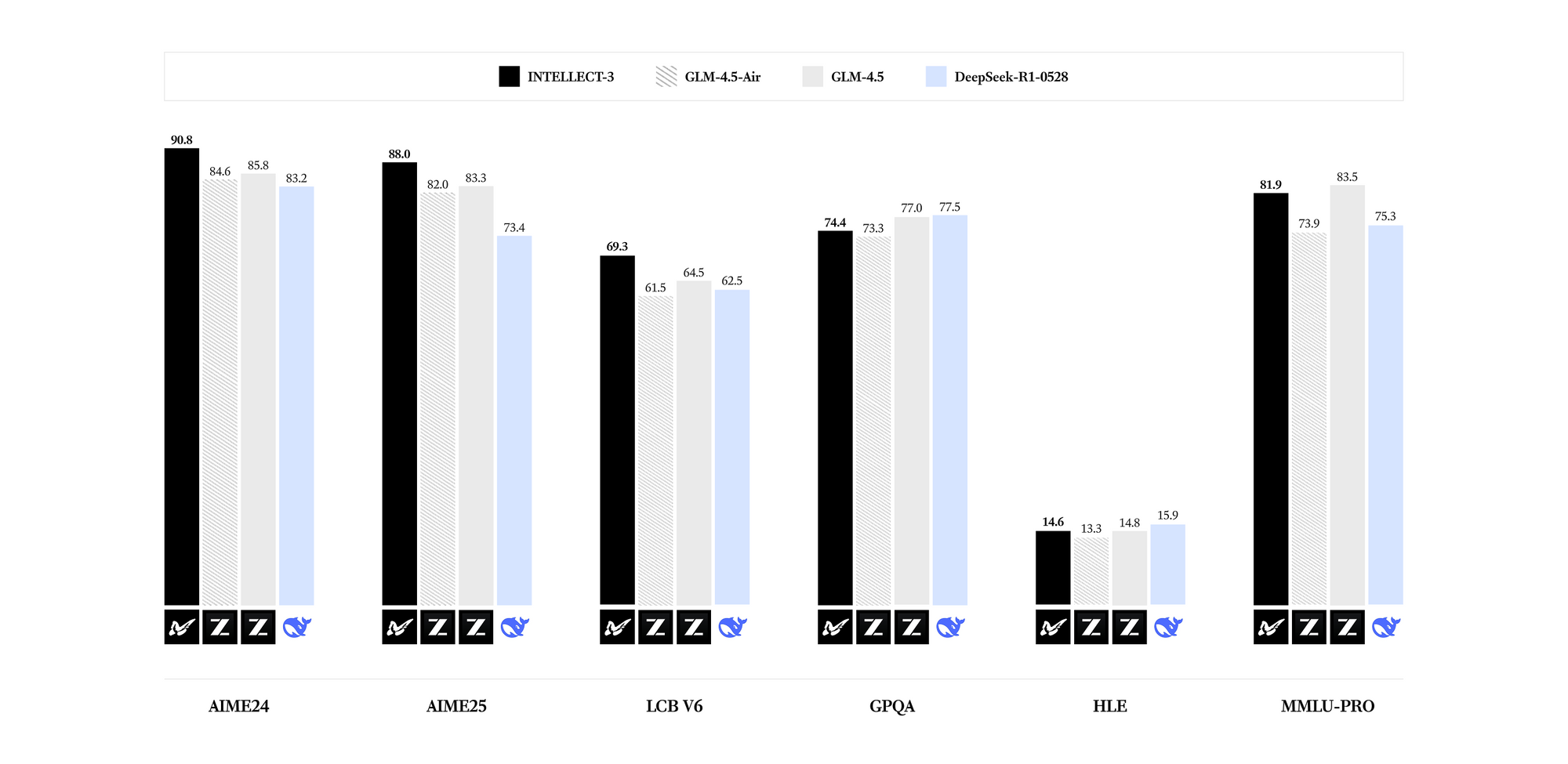
INTELLECT-3 excels in specialized domains. Benchmarks reveal state-of-the-art results for its parameter count across mathematics (e.g., GSM8K scores exceeding 95%), coding (HumanEval pass rates above 85%), science (GPQA accuracy over 60%), and reasoning (MMLU scores nearing 80%). Compared to denser models like Llama 3.1 70B, INTELLECT-3 achieves superior efficiency—up to 2x faster inference on equivalent hardware—due to its sparse activation patterns. Consequently, you deploy it in resource-constrained settings without sacrificing output quality.
Supporting infrastructure enhances its open-source appeal. The Verifiers & Environments Hub provides over 500 RL environments, from simple puzzles to advanced theorem provers.
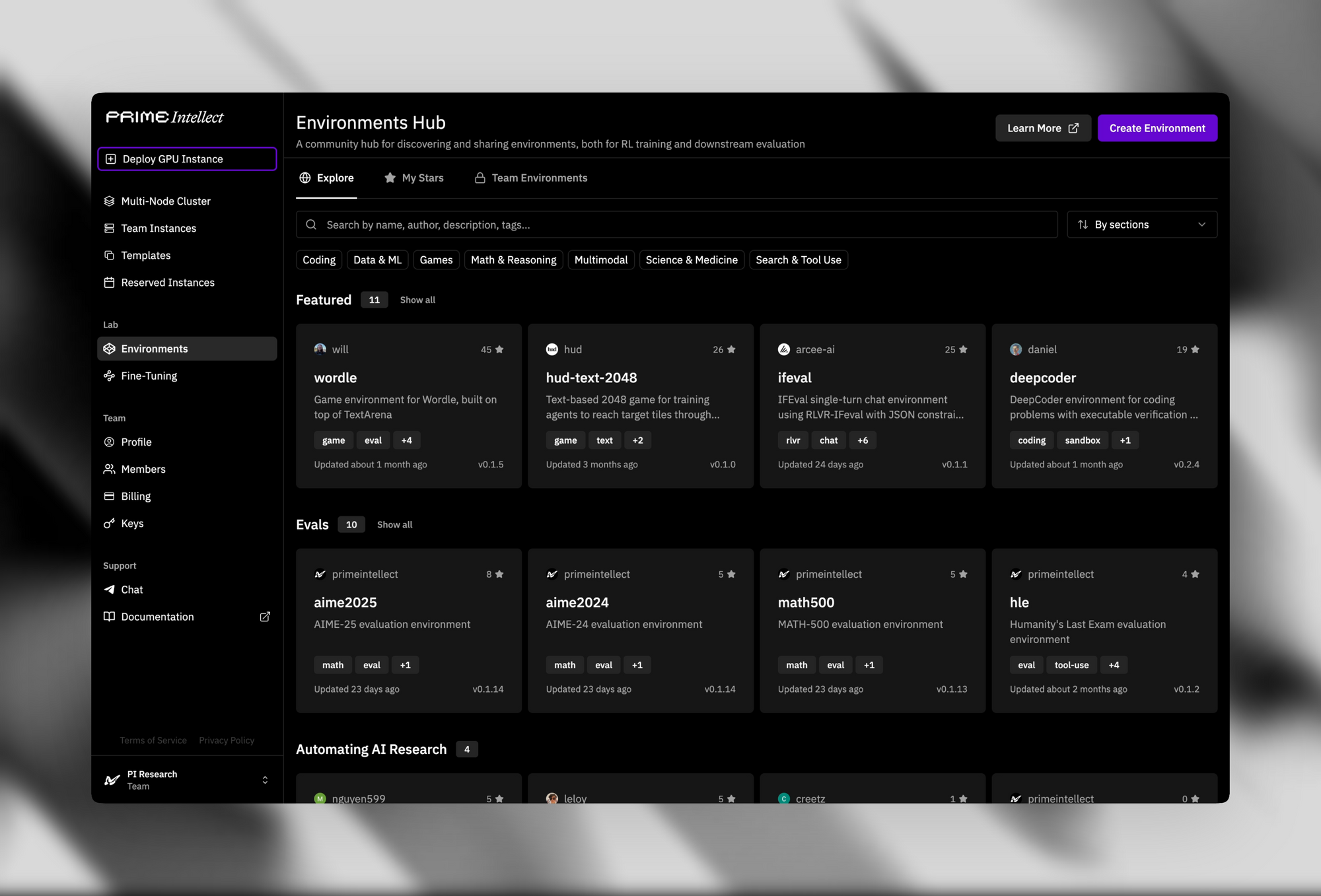
Prime Sandboxes deliver secure, high-throughput code execution, which isolates agent actions during training or inference. Developers leverage these tools to fine-tune INTELLECT-3 for custom applications, such as autonomous agents in software development pipelines.
In practice, you download the model weights via Hugging Face or Prime Intellect's GitHub. Installation requires standard dependencies like PyTorch and Transformers library. A basic script to load the model looks like this:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
This code initializes the model on GPU-enabled hardware. However, for production-scale usage, you transition to hosted APIs, as self-hosting demands significant compute (e.g., multiple A100 GPUs). Thus, open-source access lays the groundwork, but API integration scales your deployments effectively.
Transitioning from local experimentation, you now explore how to access INTELLECT-3 through managed services. This shift ensures reliability and handles the complexities of distributed inference.
Accessing the INTELLECT-3 API: Setup and Authentication
Option 1 – Prime Intellect Native Endpoint (Recommended for maximum performance & lowest latency)
You begin API access by obtaining credentials from Prime Intellect's platform. Visit the Prime Intellect dashboard at app.primeintellect.ai and create an account if necessary.
Once logged in, navigate to the API keys section and generate a new key with Inference permissions enabled. This key authenticates all subsequent requests, ensuring secure access to INTELLECT-3.
Next, configure your environment. Set the API key as an environment variable for seamless integration:
export PRIME_API_KEY="your-api-key-here"
For team-based workflows, include the X-Prime-Team-ID header in requests. This identifier routes usage to the correct billing pool, preventing cross-account charges. You retrieve the team ID from the dashboard under account settings.
The API adopts an OpenAI-compatible interface, which simplifies adoption if you already use libraries like openai-python. Specify the base URL as https://api.pinference.ai/api/v1. This endpoint proxies requests to optimized inference providers, including Parasail and Nebius, which host INTELLECT-3 instances. As a result, you achieve low-latency responses without managing underlying clusters.
To verify access, query the models endpoint. This lists available models, confirming INTELLECT-3's presence (typically under a handle like prime-intellect/intellect-3). Use the CLI tool for quick checks:
prime inference models
Alternatively, send a GET request via curl:
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
The response returns a JSON array of model objects, each detailing parameters like id, max_tokens, and context_window. INTELLECT-3 supports a 128K token context, which accommodates long-form reasoning chains.
Authentication extends to rate limiting and quotas. Prime Intellect enforces per-minute and daily limits based on your plan, visible in the dashboard. You monitor usage via the Billing tab, which logs tokens processed and API calls made. If limits bind your workflow, upgrade seamlessly through the platform.
Furthermore, integrate with Apidog for enhanced testing. Import the OpenAI schema into Apidog, then simulate requests to INTELLECT-3 endpoints. This practice identifies issues early, such as malformed JSON payloads. Apidog's free tier suffices for initial setups, bridging local development to production APIs.
With authentication in place, you proceed to crafting requests. The following section outlines precise formats to elicit optimal responses from INTELLECT-3.
Option 2 – OpenRouter (Instant access & unified credits)
Besides self-hosting or using Prime Intellect’s native inference platform, INTELLECT-3 is also officially available on OpenRouter. This gives you an alternative gateway with unified billing, automatic fallback routing, and instant access—no separate Prime Intellect account required if you already use OpenRouter.
- Base URL: https://openrouter.ai/api/v1
- Model name: prime-intellect/intellect-3
- Authentication: Your OpenRouter API key (OPENROUTER_API_KEY)
- Automatic provider routing (currently served by Prime Intellect clusters)
- Pay-as-you-go with OpenRouter credits; slightly higher per-token cost due to platform fee
Both endpoints support identical request/response schemas, streaming, tool calling, and JSON mode.
Making Requests to INTELLECT-3 API: Formats and Examples
You initiate interactions via the /chat/completions endpoint, which handles conversational and task-oriented prompts. Construct requests as JSON objects with fields for model, messages, temperature, and max_tokens. The messages array mimics chat histories, using roles like "system", "user", and "assistant".
Consider a basic example for code generation. You send:
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
This code outputs a recursive Fibonacci implementation with memoization, leveraging INTELLECT-3's coding prowess. The temperature parameter controls creativity—lower values (e.g., 0.2) favor deterministic outputs for factual queries, while higher ones (up to 1.0) encourage diverse reasoning paths.
For mathematical reasoning, you structure prompts to chain thoughts. INTELLECT-3's RL training shines here, as it simulates step-by-step verification. Example:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
The model responds with a rigorous proof, citing axioms and theorems. You parse the output via response.choices[0].message.content, which arrives as a string. For structured data, enable JSON mode by adding "response_format": {"type": "json_object"} to the request, ensuring parseable responses.
Advanced usage involves tool calling, where INTELLECT-3 integrates external functions. Define tools in the request:
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
If the model invokes the tool, it returns arguments in response.choices[0].message.tool_calls. You execute the function externally and feed results back in a follow-up message. This pattern builds agentic workflows, capitalizing on INTELLECT-3's environment-trained behaviors.
Error handling forms a critical part. Common issues include 401 (invalid key), 429 (rate limit), and 400 (malformed request). Implement retries with exponential backoff:
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
Responses include metadata like usage (prompt_tokens, completion_tokens, total_tokens), which you log for optimization. INTELLECT-3 processes up to 4096 tokens per completion, balancing depth and speed.
Streaming responses enhance real-time applications. Add stream=True to the create call; the client yields chunks as Server-Sent Events. Parse them iteratively:
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
This technique suits chatbots or live code assistants, where users expect incremental feedback.
Having mastered request crafting, you evaluate performance. The next segment introduces benchmarking tools tailored to INTELLECT-3.
Optimizing and Evaluating INTELLECT-3 API Usage
You optimize API calls by tuning parameters empirically. Start with batching multiple messages into one request for throughput gains—up to 10x efficiency in evaluation suites. Prime Intellect's CLI supports this:
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
This command runs 100 GSM8K samples, aggregating accuracy and latency metrics. You analyze results to adjust top_p or frequency_penalty, which mitigate repetition in long generations.
Evaluation extends to custom environments from the Verifiers Hub. Load an RL environment and query INTELLECT-3 as the policy:
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
Rewards quantify improvements, guiding fine-tuning if you host locally. For API-only users, log interactions to a vector database and compute downstream metrics like task success rate.
Security considerations matter too. Sanitize user inputs to prevent prompt injection, and use system prompts to enforce boundaries. INTELLECT-3's RL background reduces hallucinations, but you validate outputs against verifiers for high-stakes applications.
Scaling involves monitoring via the dashboard. Set alerts for token thresholds, and integrate with observability tools like Prometheus, which Prime Intellect exposes for clusters. Thus, you maintain reliability as usage grows.
Now that you handle optimization, consider costs. Pricing transparency ensures sustainable integration.
INTELLECT-3 API Pricing: Transparent Token-Based Model
Prime Intellect structures pricing around token consumption, charging separately for input and output. You pay per 1,000 tokens, with rates varying by model and provider. For INTELLECT-3, expect competitive figures—around $0.50 per million input tokens and $1.50 per million output—though exact values appear in the models endpoint response.
| Provider | Input ($$ /1M tokens) | Output ( $$/1M tokens) | Notes |
|---|---|---|---|
| Prime Intellect Direct | ~$0.45–$0.60 | ~$1.30–$1.80 | Lowest cost, volume discounts |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | Includes OpenRouter platform fee |
Exact rates fluctuate; always check the latest values in your dashboard or via the models endpoint.
Which Should You Choose?
- Choose Prime Intellect direct if you want maximum speed, lowest cost, or plan high-volume usage.
- Choose OpenRouter if you prefer a single API key across 50+ models, need instant onboarding, or want built-in fallback routing.
Both options deliver the same INTELLECT-3 performance. Pick the one that fits your workflow—many teams even use both simultaneously for redundancy.
The rest of this guide (request formats, streaming, tool calling, optimization, etc.) applies equally whether you call Prime Intellect directly or via OpenRouter.
Continue with the full technical implementation details below, and start building with INTELLECT-3 today—via whichever gateway works best for you.
Advanced Integrations with INTELLECT-3 API
You extend INTELLECT-3 into ecosystems like LangChain or LlamaIndex for orchestration. In LangChain:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
This binds the API to retrieval-augmented generation (RAG) pipelines, enhancing accuracy with external knowledge.
For microservices, deploy via FastAPI wrappers that proxy to INTELLECT-3:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
Expose this endpoint securely, rate-limiting with Redis. Such setups power SaaS tools, from content generators to research assistants.
Edge cases demand attention. Handle token overflows by truncating inputs dynamically, and fallback to smaller models if INTELLECT-3 queues. Community forums on Prime Intellect's site offer troubleshooting threads.
Conclusion: Deploy INTELLECT-3 API with Confidence
You now possess a comprehensive toolkit for INTELLECT-3 API usage. From its open-source roots to precise request handling and cost management, this guide equips you for real-world deployments. Experiment with Apidog to refine your workflows, and monitor evolving docs for updates.
Implement these techniques incrementally—start with simple chats, then scale to agents. INTELLECT-3's efficiency and openness position it as a go-to for technical AI projects. Begin coding today, and witness the impact on your applications.


